


HunyuanOCR的表现不及预期 - 指南
前天,腾讯发布了 HunyuanOCR 这个OCR模型。
前不久,百度刚发布PaddleOCR-VL这个模型,在OmniDocBench内容集上刷到了SOTA。
结果腾讯一出手,立刻又把数值刷高了2个点。
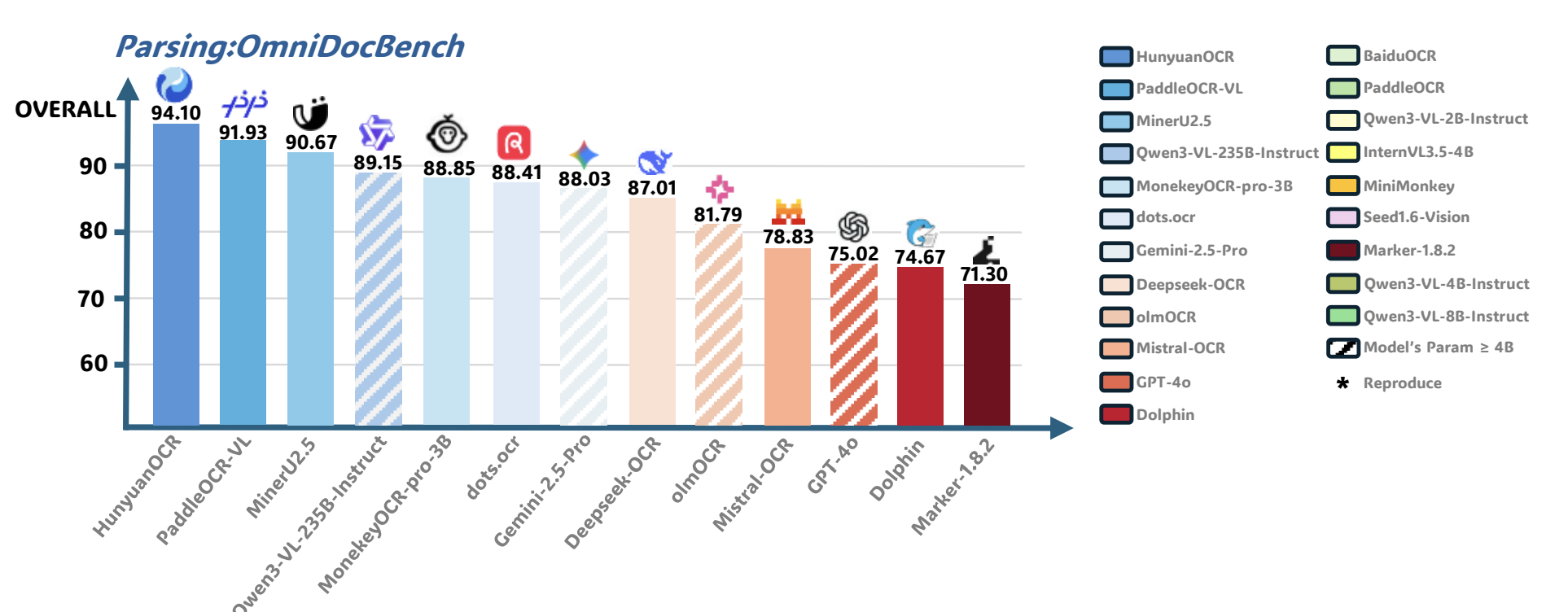
目前,腾讯公开了该工作的推理代码[1]和模型权重[2],整个模型参数量为1B该数量级,和行业平均水准较为接近。
快速体验
通过如果要飞快体验这款模型,能够直接用官方在huggingface上部署的demo[3]进行测试。
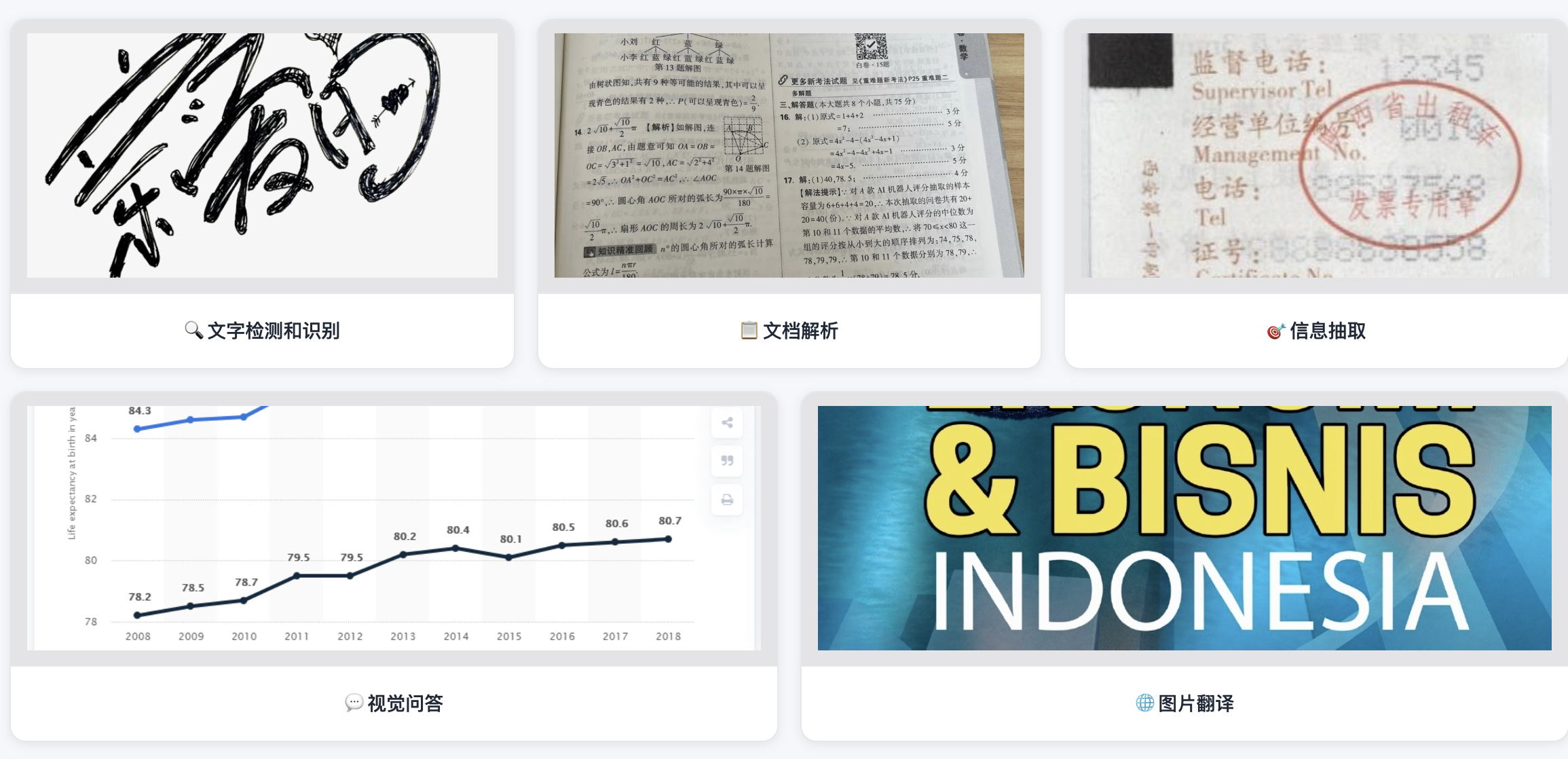
值得注意的是,该模型不仅仅局限于文档解析,可以处理以下多个应用场景的任务,官方给了五个示例。
但是,官方没有提供文件上传的接口,目前仅支撑jpg/png格式的图片上传。
官方给的示例肯定是精挑细选取最优的放出来的,为了客观评价这款模型能力,下面上传一张我自己的图片进行测试。
测试内容很简单,我上传了一张我做的APP界面截图,要求它把里面的文字识别出来。
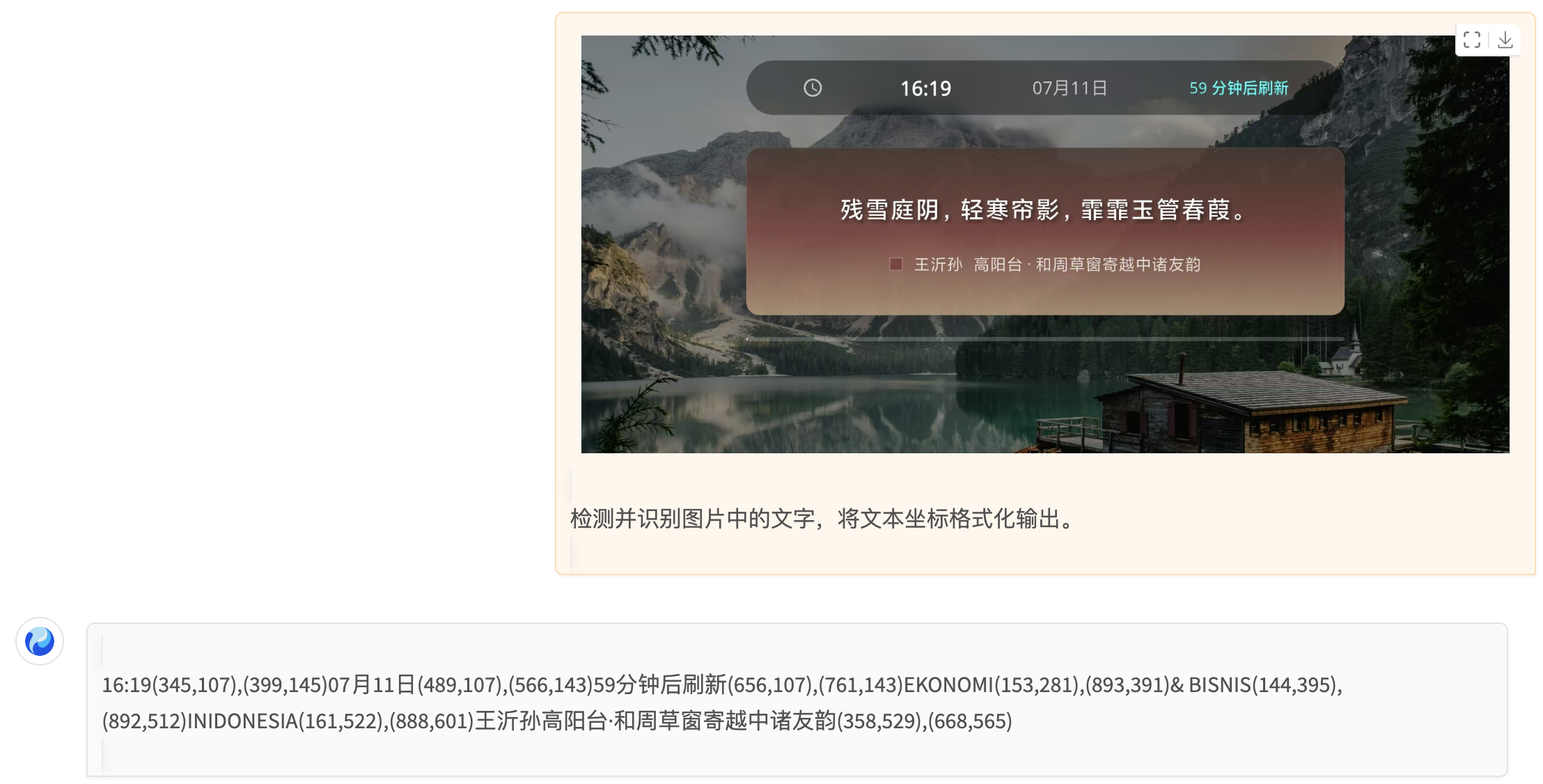
不过令人诧异的是,中间最明显的诗词这一句,它竟然漏掉了。
为了进行对比,我拿MinerU的在线网站测试了一下,结果符合预期。
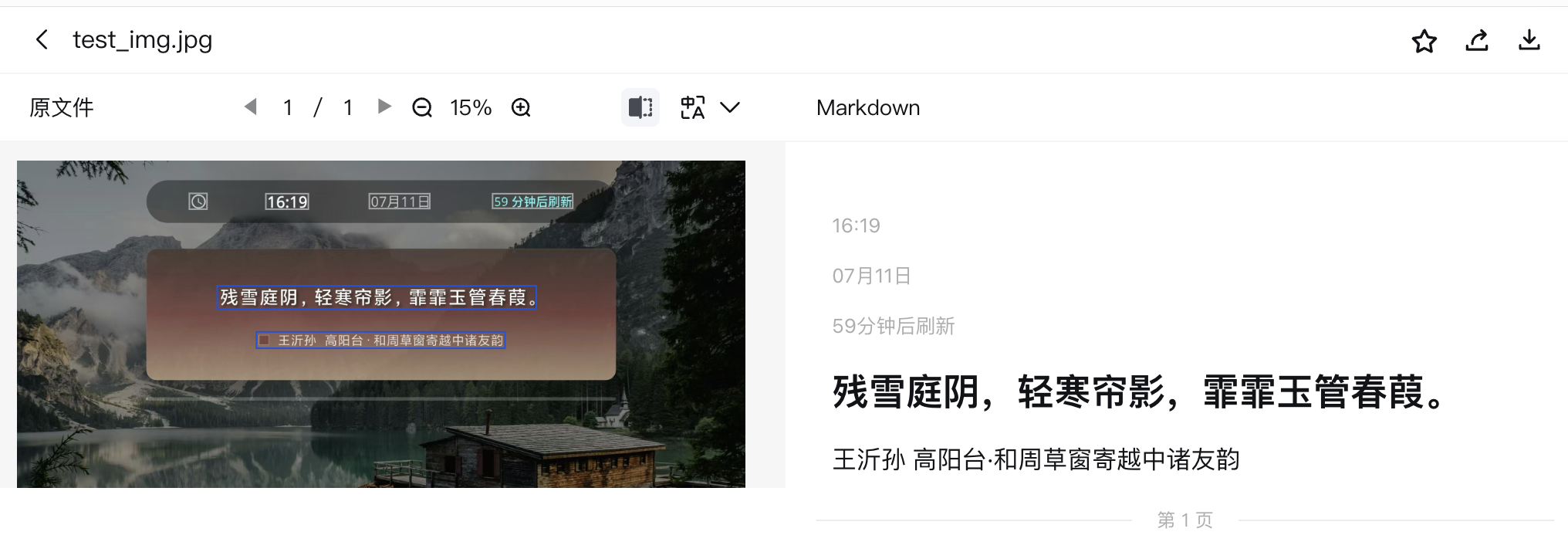
这样容易的任务,对一个通用型的模型应该没难度,HunyuanOCR的表现说明,它的泛化性还有待提升。
本地部署
参考官方仓库的说明,本地部署官方推荐采用vllm+24GB的N卡进行部署。
推理代码:就是同时也支持用transformers做容易推理,以下
from transformers import AutoProcessor
from transformers import HunYuanVLForConditionalGeneration
from PIL import Image
import torch
model_name_or_path = "tencent/HunyuanOCR"
processor = AutoProcessor.from_pretrained(model_name_or_path, use_fast=False)
img_path = "test_img.jpg"
image_inputs = Image.open(img_path)
messages1 = [
{"role": "system", "content": ""},
{
"role": "user",
"content": [
{"type": "image", "image": img_path},
{"type": "text", "text": (
"检测并识别图片中的文字,将文本坐标格式化输出。"
)},
],
}
]
messages = [messages1]
texts = [
processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True)
for msg in messages
]
inputs = processor(
text=texts,
images=image_inputs,
padding=True,
return_tensors="pt",
)
model = HunYuanVLForConditionalGeneration.from_pretrained(
model_name_or_path,
attn_implementation="eager",
dtype=torch.bfloat16,
device_map="auto"
)
with torch.no_grad():
device = next(model.parameters()).device
inputs = inputs.to(device)
generated_ids = model.generate(**inputs, max_new_tokens=16384, do_sample=False)
if "input_ids" in inputs:
input_ids = inputs.input_ids
else:
print("inputs: # fallback", inputs)
input_ids = inputs.inputs
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(input_ids, generated_ids)
]
output_texts = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_texts)我在Mac上跑了一下这段代码,发现这段代码默认似乎没有调用到mps进行加速,而是直接用CPU在进行计算,处理速度很慢。
跑完之后,结果仅输出了一个字,和官方的demo也不太相符,可能还存在一定问题。
模型结构
技术报告[4]中披露了该模型的具体结构。

端到端的架构,主要包含三个模块:就是这款模型总体
- 视觉编码器:Hunyuan-ViT,基于 SigLIP-v2-400M 预训练模型构建
- MLP:用来连接视觉token和语言token
- 语言模型:采用Dense架构的Hunyuan-0.5B模型
该模型支持五种任务:
- 定位(Spotting)
- 解析(Parsing)
- 信息提取(IE)
- 视觉问答(VQA)
- 图像翻译(Image Translation)
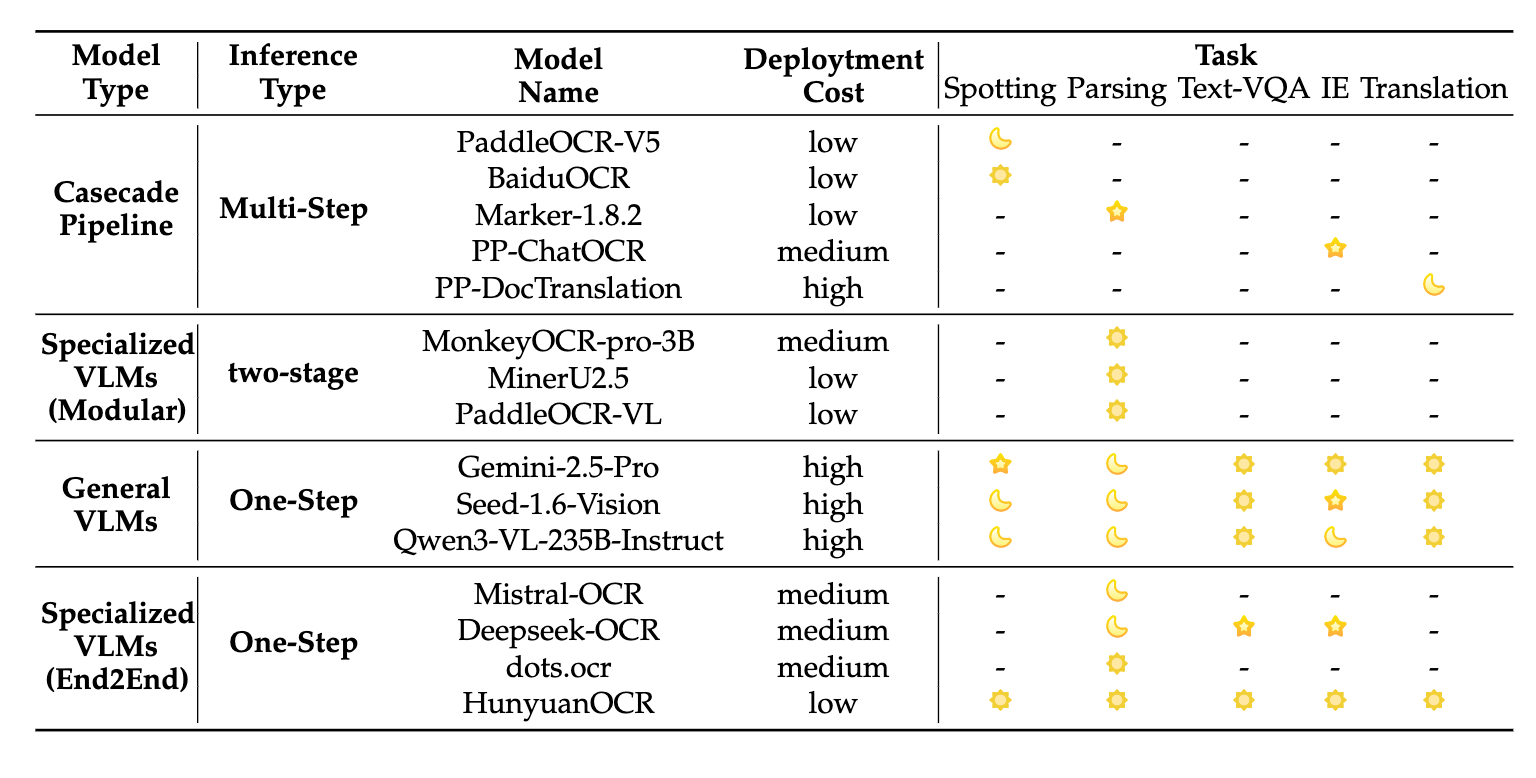
这个模型结构相对来说是比较简洁清晰的,属于一步类型的端到端模型,和其他模型的技术路线对比如下表所示。
训练策略
该模型的预训练阶段采用四个阶段的训练方法。
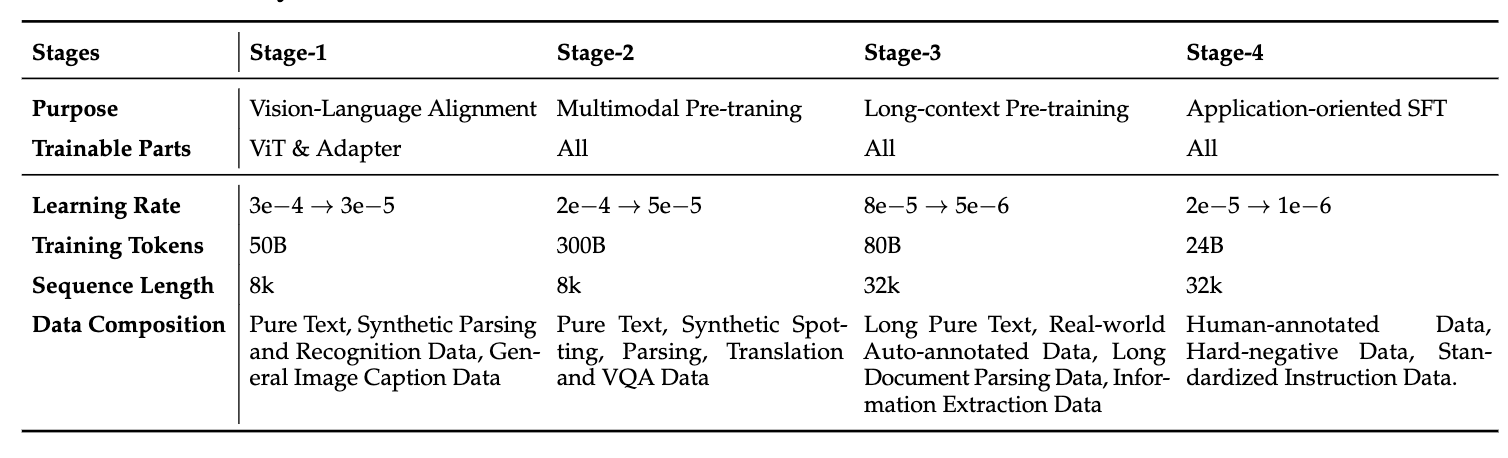
- 阶段一:冻结语言模型,仅训练ViT和MLP,让视觉信息和文本信息对齐
- 阶段二:解冻所有模型参数,进行端到端视觉-语言联合学习,重点增强模型对文档、表格、图表等结构化内容的深度理解和认知推理能力。
- 阶段三:拓展上下文窗口,进行长文本的预训练
- 阶段四:使用真实标注数据+高质量合成数据进行SFT训练。
在预训练结束之后,采用强化学习进行优化,对不同任务设置单独的奖励,并用GRPO算法进行优化。
总结
整体来看,该模型的创新点不多,基本上都是一些比较常见的方法思路。
实验性质的刷榜工作。就是从实际表现看,该模型不及预期,属于
参考
[1] https://github.com/Tencent-Hunyuan/HunyuanOCR
[2] https://huggingface.co/tencent/HunyuanOCR
[3] https://huggingface.co/spaces/tencent/HunyuanOCR
[4] https://arxiv.org/pdf/2511.19575

 浙公网安备 33010602011771号
浙公网安备 33010602011771号