


DeepSeek系列模型/项目介绍(二):Coder、Prover、Math、ESFT - 指南
概述
DeepSeek-Coder
代码大模型系列,旨在通过AI技术来理解和生成代码,提升开发效率。
特性:
- 核心定位:开源代码智能模型,促进研究和商业应用
- 模型规模:从1.3B到236B等多种参数,V2采用MoE架构
- 训练数据:从零开始训练,使用2万亿高质量代码和自然语言Token
- 关键特色:项目级代码理解、填充空白任务、支持超长上下文(最高128K)、宽松许可证
- 性能表现:在多项基准测试中超越Codex和GPT-3.5等闭源模型
技术创新
- 高质量训练数据:从头开始训练,训包含2万亿个Token,87%代码,13%中英文自然语言。以代码为主的数据构成,为模型的专业能力奠定基础;
- 项目级代码理解:与仅理解单文件的模型不同,在项目级代码语料库上进行预训练;能更好地理解整个代码库上下文和文件间的关联;
- 填充空白任务:采用
填充空白的创新训练任务。能在代码末尾追加内容,在代码中间智能地补全或修复代码,增强代码编辑灵活性; - 支持超长上下文:支持16K上下文窗口,V2扩展到128K,使模型可处理和分析非常长的代码文件或整个项目片段。
版本号:
- 1:支持89种编程语言
- 2:支持338种编程语言
V1
V2
- V2-Base:236B参数
- V2-Instruct:236B参数
- V2-Lite-Base:16B参数
- V2-Lite-Instruct:16B参数
- V2-Instruct-0724:236B参数
实战
广泛应用于各种开发场景:
- 智能代码生成与补全:可根据自然语言描述生成完整的代码片段、函数、脚本;
- 代码调试与优化:帮助开发者分析并修复代码中的错误,还能建议性能优化方案;如将循环替换为列表推导式以提升执行效率;
- 自动化重复任务:可自动生成技术文档、单元测试用例和进行代码审查,使开发者从繁琐重复的任务中解放出来。
示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/deepseek-coder-6.7b-base"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))最佳实践
- 有效的提示词工程:
- 使用结构化提示,清晰定义:角色、任务和约束条件等;
- 对于复杂需求,采用分步生成的策略,将大任务拆解成多个子任务。
- IDE:可集成到VS Code等主流IDE中,提供实时的代码补全和建议。
- 处理局限性:
- 对于复杂业务逻辑,模型准确率可能下降,建议提供详细的业务规则文档作为上下文输入,并对关键逻辑进行人工审核;
- 模型对某些新兴技术栈的支持可能仍在完善中,建议关注官方更新日志。
DeepSeek-Prover
一个专注于形式化数学定理证明的系列模型,能够生成在Lean4这类证明助手中可被验证的、逻辑严谨的数学证明。核心用途是让AI能够像数学家一样进行严谨的数学推理,并输出机器可验证的证明过程。
| 主要用途 | 具体描述 |
|---|---|
| 自动定理证明 | 针对复杂的数学定理(如费马大定理),模型可将其分解为一系列更简单子目标,并生成完整的Lean4形式化证明代码 |
| 数学教育与研究 | 模型已集成到新东方、猿辅导等智能教辅系统中。能提供详细的带有自然语言解释的推理过程,帮助学习者理解数学证明 |
| 工业级验证 | 在芯片设计、密码学等需要高度逻辑严谨的科研领域,可用于进行形式化验证,确保设计正确性 |
| 推动AI推理前沿 | 探索非正式推理(像人类一样思考)与形式化验证(机器可检查的证明)的结合,是迈向更高级AGI的关键一步 |
解决AI在数学推理领域的一些核心挑战:
- 填补两种推理之间的鸿沟:传统的AI模型可能能用自然语言说出答案,但无法给出严谨证明;而有些模型生成的证明又过于僵化。创新性地融合非正式推理(生成易于理解的自然语言推理链)和形式化验证(生成可执行的Lean4代码),兼顾可理解性和100%的逻辑严谨性;
- 分解-求解的高效策略:面对复杂问题,采用双引擎系统。首先由一个大型模型(如671B参数版本)将难题分解成可管理的子目标链,然后使用更小模型(如7B参数版本)并行处理这些子目标。不仅大幅提升计算效率,也使得证明过程更加可靠;
- 卓越的性能表现:最强版本DeepSeek-Prover-V2-671B在
MiniF2F-test数据集上达到88.9%的形式化证明通过率,相比前代提升47%。解决PutnamBench(一个高难度数学竞赛题集)中的49道难题,远超同类模型的23道。
版本如下:
- 1:论文,数据集,7B参数模型;
- 1.5:论文,GitHub,7B参数模型包括:V1.5-RL、V1.5-SFT、V1.5-Base;
- 2:模型包括:GitHub,V2-7B、V2-671B;ProverBench数据集
DeepSeek-Math
论文,专注于数学推理的LLM,旨在解决传统大模型在处理数学符号、逻辑链推导和复杂问题求解时的性能瓶颈。
| 特点维度 | 具体说明 |
|---|---|
| 核心定位 | 提升开放语言模型在数学问题上的推理能力,覆盖从基础算术到竞赛级数学题 |
| 技术架构 | 基于DeepSeek-Coder代码模型初始化,部分版本采用混合专家架构 |
| 训练数据 | 使用从Common Crawl提取的1200亿高质量数学相关Token进行继续预训练 |
| 突出性能 | 以70亿参数在竞赛级MATH基准测试达到51.7%准确率,逼近GPT-4水平 |
技术创新
- 代码模型初始化:与从通用模型初始化相比,使用
DeepSeek-Coder-Base-v1.5 7B作为基础进行初始化,能获得更好的数学能力。表明代码和数学推理所需的逻辑思维能力存在共通之处; - 高质量训练数据:通过精心设计的数据选择管道,从海量网络数据中筛选出1200亿高质量的数学相关Token构成训练数据集。是开源数据集OpenWebMath的9倍,为模型性能提供坚实基础;
- 创新的强化学习:在训练中引入GRPO方法,在增强数学推理能力的同时,优化PPO内存使用;
- 混合推理策略:融合思维链(CoT) 和程序辅助(PAL) 两种推理策略。思维链通过自然语言逐步推导,而程序辅助则将问题转化为可执行代码,利用Python解释器安全执行计算,大幅提升解题准确率。
GitHub,系列模型包括:
示例:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-math-7b-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "The integral of x^2 from 0 to 2 is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)应用前景:
- 教育领域:可作为智能辅导系统,帮助学生解决数学问题,提供详细的解题步骤和解释,或用于自动批改数学作业;
- 科研领域:辅助研究人员进行复杂的数学推导和计算,例如在理论物理、量子化学等领域加速研究进程;
- 工业领域:应用于优化问题和控制系统设计,如在物流路径规划中解决TSP问题,或在金融工程中进行风险价值计算优化。
ESFT
论文,Expert-Specialized Fine-Tuning缩写,专家级微调,通过选择性训练MoE架构中与任务相关的专家模块,彻底改变模型微调方式。与微调整个模型不同,ESFT识别并调整与特定任务最相关的专家,在保持或提升性能的同时显著提高效率。
关键优势:
- 参数效率:仅训练总参数的5-10%
- 任务专业化:每个专家专注于特定领域
- 资源优化:降低内存和计算需求
- 模块化架构:易于组合专业专家处理多任务场景
基于DeepSeek MoE架构构建,采用精密的专家选择和训练流程: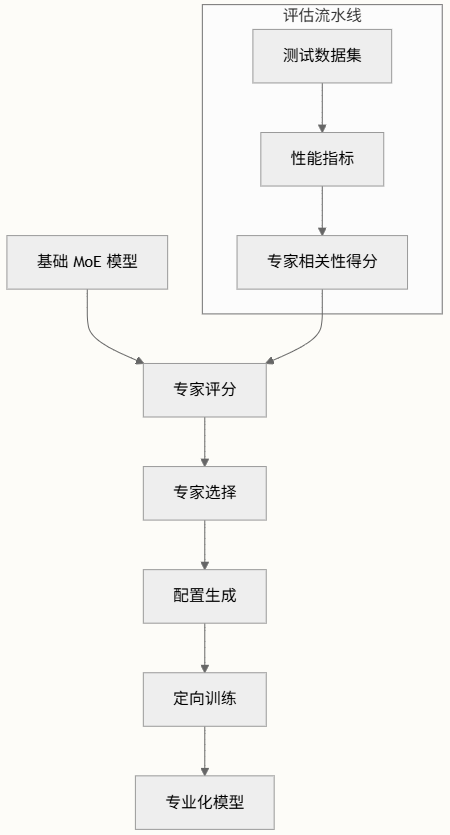
核心流程:
- 专家评分:使用评分函数评估每个专家与特定任务的相关性
- 选择性训练:将无关专家转换为不可训练的缓冲区,同时保留相关专家作为参数
- 配置管理:为定向微调生成专家特定配置
系列模型分两类,Token和Gate,每一类各6种任务,包括:
- Vanilla-Lite,16B参数的基础模型;
- Token-Law-Lite,1B参数
- Token-Summary-Lite,1B参数
- Token-Code-Lite,2B参数
- Token-Intent-Lite,2B参数
- Token-Translation-Lite,0.9B参数
- Token-Math-Lite,1B参数
- Gate-Law-Lite,2B参数
- Gate-Summary-Lite,2B参数
- Gate-Translation-Lite,1B参数
- Gate-Code-Lite,2B参数
- Gate-Intent-Lite,2B参数
- Gate-Math-Lite,2B参数
GitHub用于存放脚本、数据集、配置文件、结果等。
数据集包括训练和评估两类,4种任务:
数据集解读
| 任务 | 数据集 | 描述 | 使用场景 |
|---|---|---|---|
| 意图识别 | intent.jsonl | 分类用户意图 | 聊天机器人、虚拟助手 |
| 法律处理 | law.jsonl | 法律文档分析 | 法律AI、合同分析 |
| 文本摘要 | summary.jsonl | 生成简洁摘要 | 内容创作、文档处理 |
| 翻译 | translation.jsonl | 跨语言翻译 | 多语言应用 |
支持两种主要训练方法:
| 脚本 | 用途 | GPU支持 | 关键特性 |
|---|---|---|---|
train.py | 基础微调 | 单GPU | 设置简单,适合实验 |
train_ep.py | 专家并行训练 | 多GPU | 针对大规模训练优化,专家分布 |
评估系统包含评估模型性能的综合工具:
- 多GPU评估:跨多个设备扩展评估,
eval_multigpu.py - 专家评分:分析专家相关性和性能,
scripts/expert/get_expert_scores.py - 配置生成:创建最优专家配置,
scripts/expert/generate_expert_config.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号