


Transformer架构 - 详解
若有误请不吝指教!
Transformer 由 Encoderblock和 Decoderblock两个部分组成。
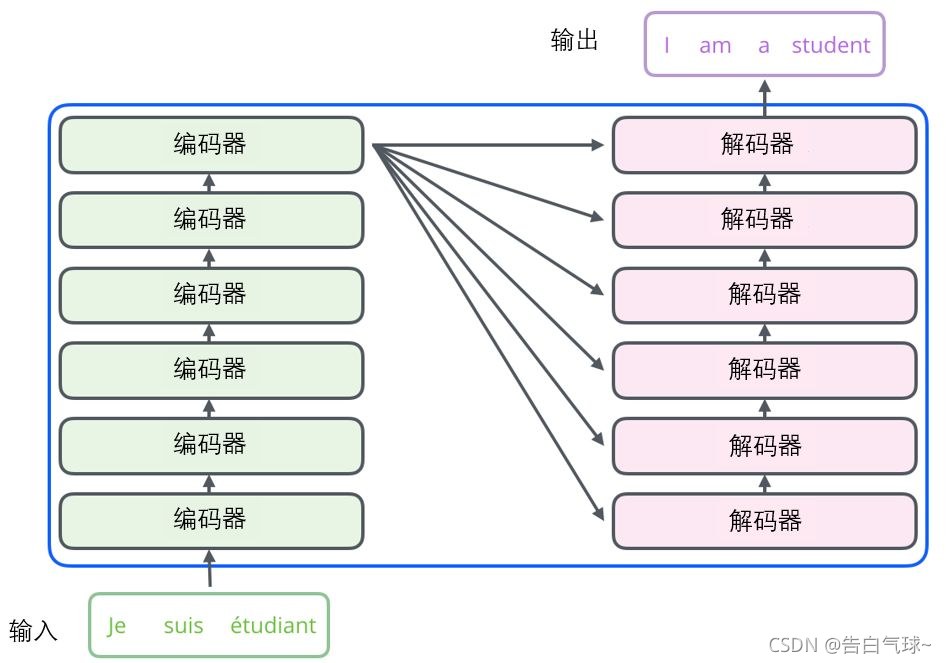
图中的一个框代表的是一个encoder的内部结构,一个Encoder是由Multi-Head Attention和全连接神经网络Feed Forward Network构成,所有的编码器在结构上是相同的,但是它们之间并没有共享参数。
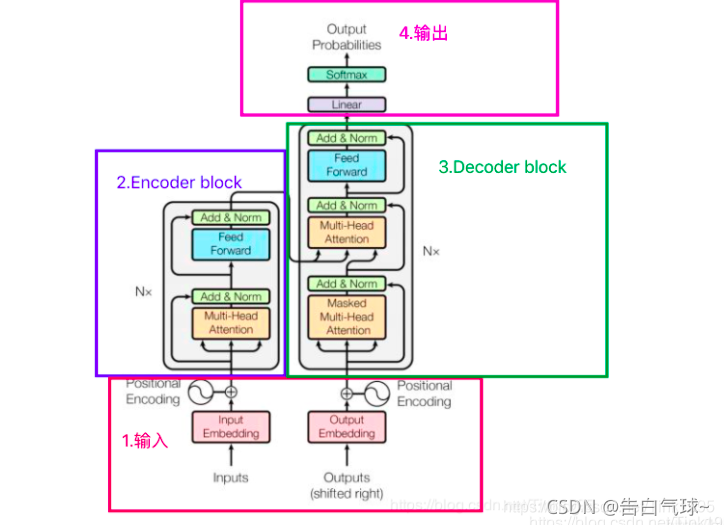
架构示意图:
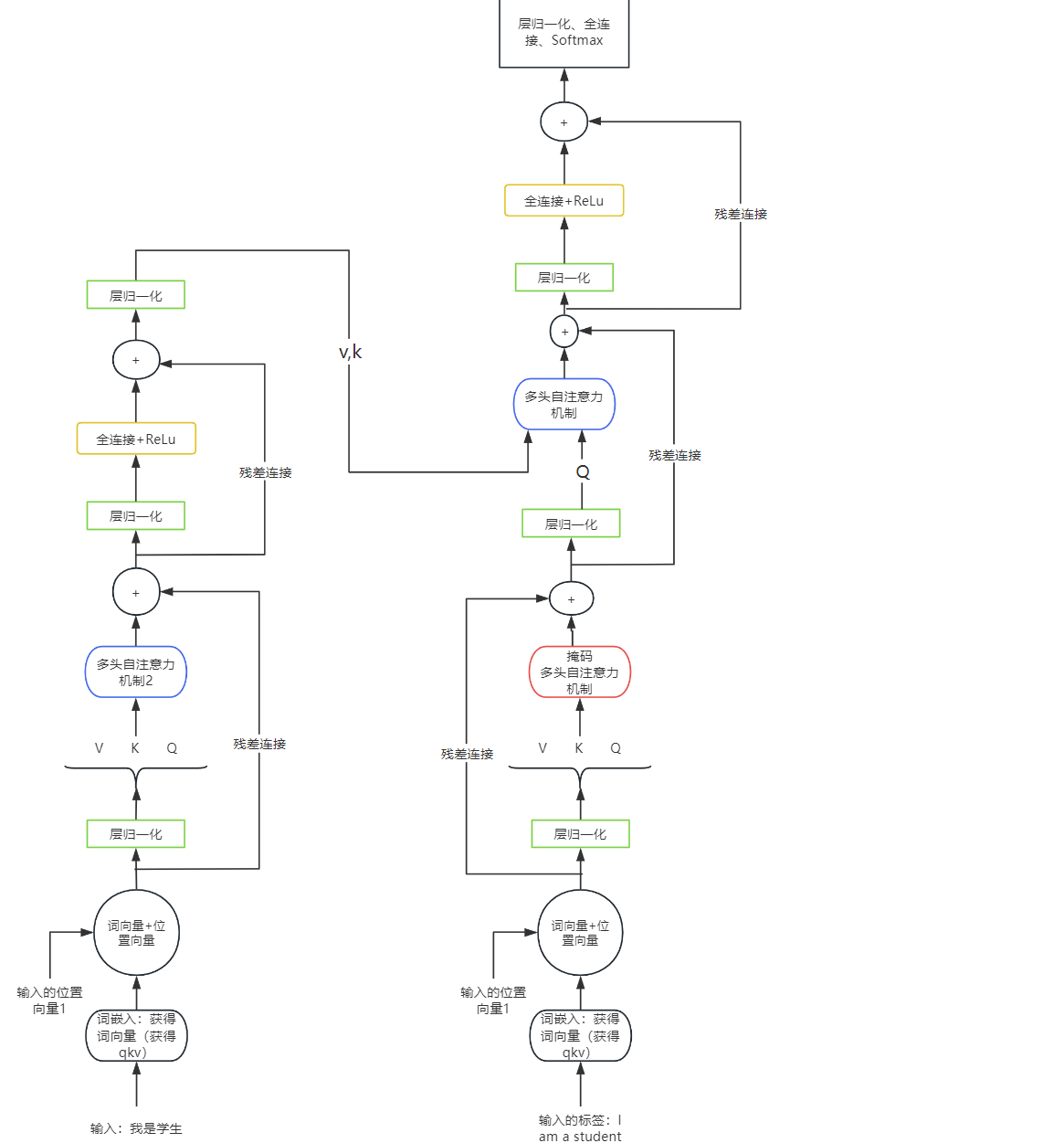
Encoder输入:我是学生
Input Embedding:词编码行利用Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。获得单个词的编码后与K-矩阵、Q-矩阵、V-矩阵分别相乘得到该词的K、Q、V
(注意:这里的K-矩阵、Q-矩阵、V-矩阵随机产生且数值较小)
累加:获得我是学生四个字的位置向量+词向量;即我的位置向量+我的词向量、是的位置向量+是的词向量
不同的)就是(原因:同一个词在一句话的不同位置对下一个词预测的贡献度显然
位置向量的获取方法:

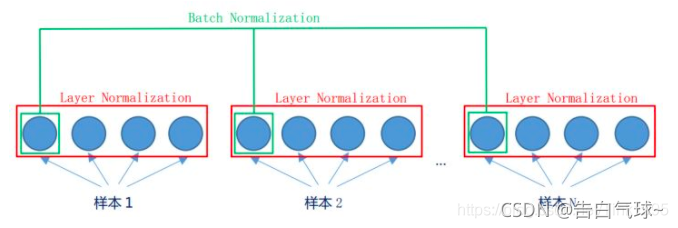
层归一化:使用到的归一化途径是Layer Normalization。LN是在同一个样本中不同神经元之间进行归一化。使得稳定训练过程,防止数值过大或过小(类似"调音量"到合适范围)
多头自注意力机制:多头+自注意力机制
自注意力机制:关注更重要的信息+融合其他向量的信息。比如一群人朝你走来你一下子看到了最好看的那个人的脸,在根据旁边人背着书包推测这个那个人大概率是个学生。(这些特征是分批分轮一次次优化才能提取到的)
自注意力机制的公式: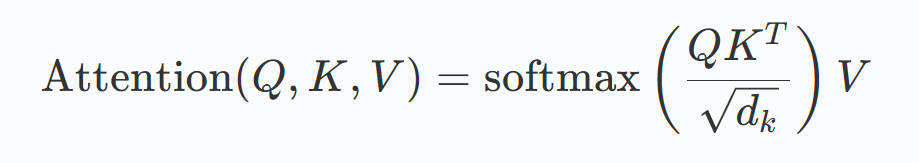
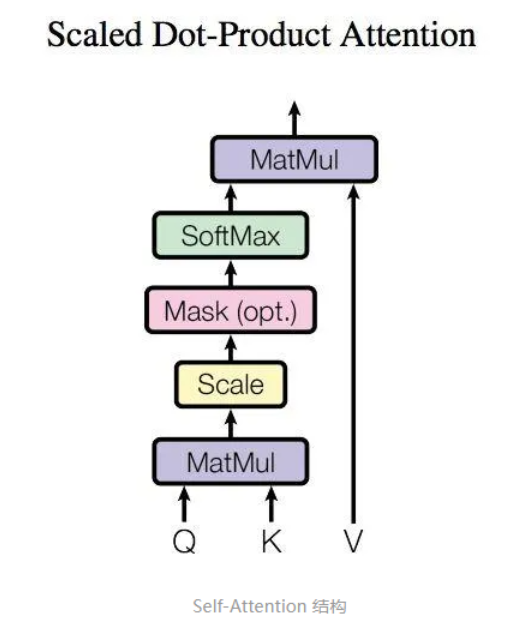
具体的例子:输入: [1,0,1,0],#词向量1 [0,2,0,2],#词向量2 [1,1,1,1]#词向量3
详细过程如图所示:
 注意:线性投影(生成 K/Q/V,含参数)
注意:线性投影(生成 K/Q/V,含参数)
#初始化Q,K,V矩阵求qkv(Q、K、V矩阵在神经网络初始化的过程中,一般都是随机采样完成并且比较小)
(Q,K,V矩阵属于可学习参数,通过学习训练进行更新参数。不同多头自注意力层的Q,K,V矩阵的参数都不相同)
具体代码如下:
import torch
x=[
[1,0,1,0],#词向量1
[0,2,0,2],#词向量2
[1,1,1,1]#词向量3
]
x=torch.tensor(x,dtype=torch.float32)
#初始化Q,K,V矩阵求qkv(Q、K、V矩阵在神经网络初始化的过程中,一般都是随机采样完成并且比较小)
w_key=[
[0,0,1],
[1,1,0],
[0,1,0],
[1,1,0]
]
w_query=[
[1,0,1],
[1,0,0],
[0,0,1],
[0,1,1]
]
w_value=[
[0,2,0],
[0,3,0],
[1,0,3],
[1,1,0]
]
w_key=torch.tensor(w_key,dtype=torch.float32)
w_query=torch.tensor(w_query,dtype=torch.float32)
w_value=torch.tensor(w_value,dtype=torch.float32)
#获得key,query,value
keys=x@w_key#矩阵运算
querys=x@w_query
values=x@w_value
#print("Keys: \n", keys)
# tensor([[0., 1., 1.],词向量1的键值
# [4., 4., 0.],
# [2., 3., 1.]])
#计算注意力分数
attn_scores=querys@keys.T#这里没有除以64
#计算softmax
from torch.nn.functional import softmax
# 当dim=0时, 是对每一个维度相同位置的数值进行softmax运算,和为1
# 当dim=1时, 是对某一维度的列进行softmax运算,和为1
# 当dim=2,-1时, 是对某一维度的行进行softmax运算,和为1
attn_scores_softmax=softmax(attn_scores,dim=-1)
# 为了使得后续方便,这里简略将计算后得到的分数赋予了一个新的值
# For readability, approximate the above as follows
attn_scores_softmax = [
[0.0, 0.5, 0.5],
[0.0, 1.0, 0.0],
[0.0, 0.9, 0.1]
]
attn_scores_softmax=torch.tensor(attn_scores_softmax)
weighted_values=values[:,None]*attn_scores_softmax.T[:,:,None]#None则表示维度扩充,None在哪里那个维度为一weighted_values=values[:,None]*attn_scores_softmax.T[:,:,None]。这里的转置由于None参数。None参数会使矩阵增加维度,None在哪里那种维度变成1。
多头:8头(可改)
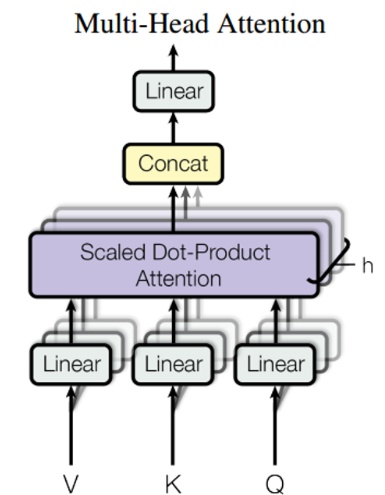
公式:将Q、K、V分别分成八段(这一步没有参数更新),对每一段进行低维投影(在上一步线性变换已经实现了)。通过。不同的分段功能不同: 比如有的头关注语法依赖,有的头关注语义关联。(故每一段的参数不共享,即参数独立)。、
、
(为学习参数,)搭建对该分段的Q、K、V进行低维投影

之后通过Concat将分段合并。用(可学习参数)将低维特征映射到原来的维度上即:512

全连接+ReLu+全连接:全连接将特征维度映射到高维空间,ReLu进行筛选,再全连接特征返回原始维度
Decoder输入:训练和预测时的输入不同。
训练:[<sos>, I, am, a,student] <sos>:表示起始符
预测:[<sos>](掩码Sequence Mask没有作用)
掩码(Sequence Mask):在这个操作后![]() 进行mask掩码执行使得预测时只能看到现在的和以前的值。
进行mask掩码执行使得预测时只能看到现在的和以前的值。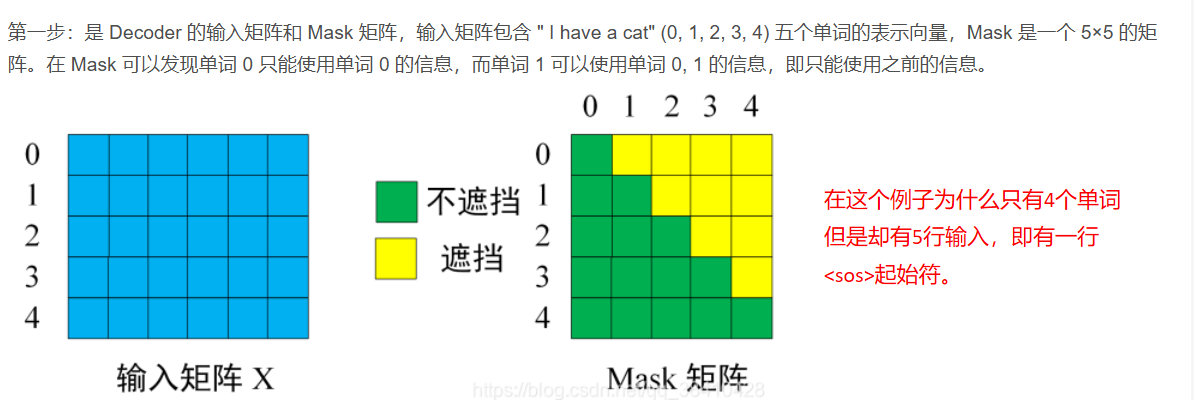
解码第二个多头自注意力机制:编码器给出k、v,解码器提供q
输出:[I, am, a,student,<eos>]
多头注意力机制中可学习参数的总结:输入向量 X → 1. 线性投影(生成 K/Q/V,含参数)→ 2. 多头拆分 → 3. 单头注意力计算 → 4. 多头结果拼接 → 5. 最终投影(含参数)→ 多头输出向量 Z
部分引用:【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客
Transformer模型详解(图解最完整版)-CSDN博客
参考文献:
Attention Is All You Need
Ashish Vaswan et al. |arXiv 1706.03762 | Code - 官方 Tensorflow| NeurIPS 2017 | Google Brain
https://www.bilibili.com/video/BV1pu411o7BE/?share_source=copy_web&vd_source=e46571d631061853c8f9eead71bdb390

 浙公网安备 33010602011771号
浙公网安备 33010602011771号