


深入解析:“零”成本迁移:基于 CANN 8.0 生态的 PyTorch on NPU 910B 落地实践
个人主页:chian-ocean
专栏

前言
在人工智能开发中,PyTorch 框架凭借其灵活性几乎“人手一份”。但当团队引入了全新的高性能 NPU 硬件(比如 Ascend 910B)时,一个尖锐的问题就摆在了桌面上:我们海量的 PyTorch 存量代码,难道都要推倒重来,用新框架重写一遍吗?这迁移成本谁受得了?
本文将基于 CANN 8.0 平台,实测一种“几乎零成本”的迁移路径,探讨 CANN 生态如何通过一个小小的
torch_npu插件,让 PyTorch 代码在 NPU 910B 上“起飞”,真正解决这个“历史遗留问题”。
痛点与场景:当 PyTorch 遇到 NPU
在人工智能的浪潮下,PyTorch 以其灵活性和易用性,成为了众多算法工程师和研究者的首选框架。我们团队也不例外,积累了大量的 PyTorch 模型资产。
然而,当团队引入了搭载 Ascend 910B 的强大 NPU 计算资源时,一个现实问题摆在面前:
“我们这些 PyTorch 老代码,难道都要用 MindSpore 重写一遍才能跑在 NPU 上吗?这个迁移成本也太高了!”
这个问题的答案,就藏在 CANN 的生态里。
核心功能:CANN 生态的“桥梁”—— torch_npu
CANN (Compute Architecture for Neural Networks) 不仅仅是一个工具链,更是一个生态。它的强大之处在于兼容性和开放性。
针对我们的痛点,CANN 提供了 torch_npu 插件。它的作用非常明确:
- 它充当“翻译官”和“桥梁”。
- 它让 PyTorch 的 API 调用能够被 CANN 的底层运行时(AscendCL)所理解和执行。
- CANN 功能如何发挥作用:
torch_npu插件通过调用 CANN 的图编译、算子库、和执行引擎,将 PyTorch 的动态图(或静态图)无缝地在 NPU 芯片上跑起来。
这意味着,我们不需要重写代码,只需要“修改”代码。
环境确认与准备
工欲善其事,必先利其器。我们首先登录到平台,确认资源。
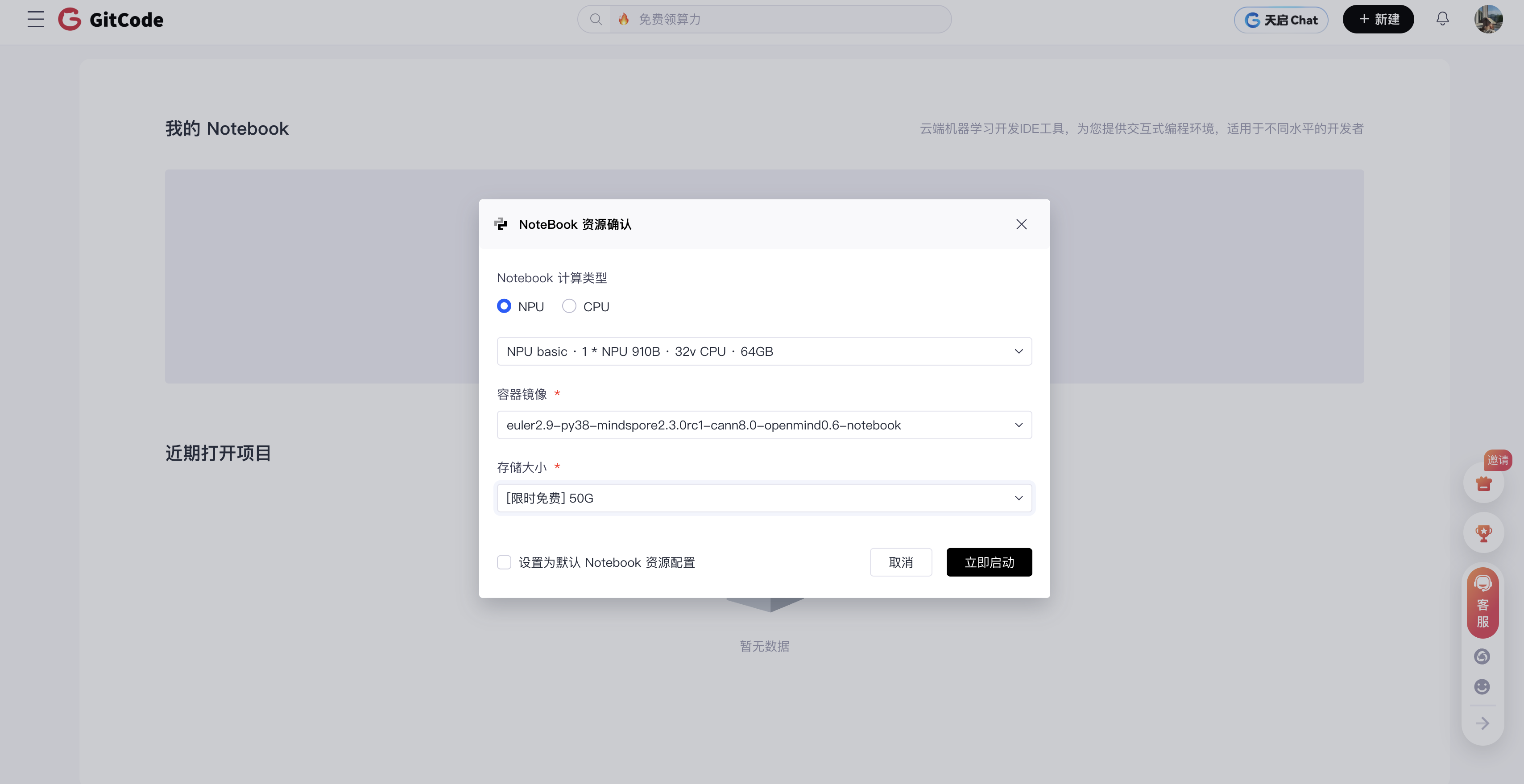
- 确认 Notebook 资源
我们选择的环境配置如下,搭载了 NPU 910B 和 CANN 8.0。
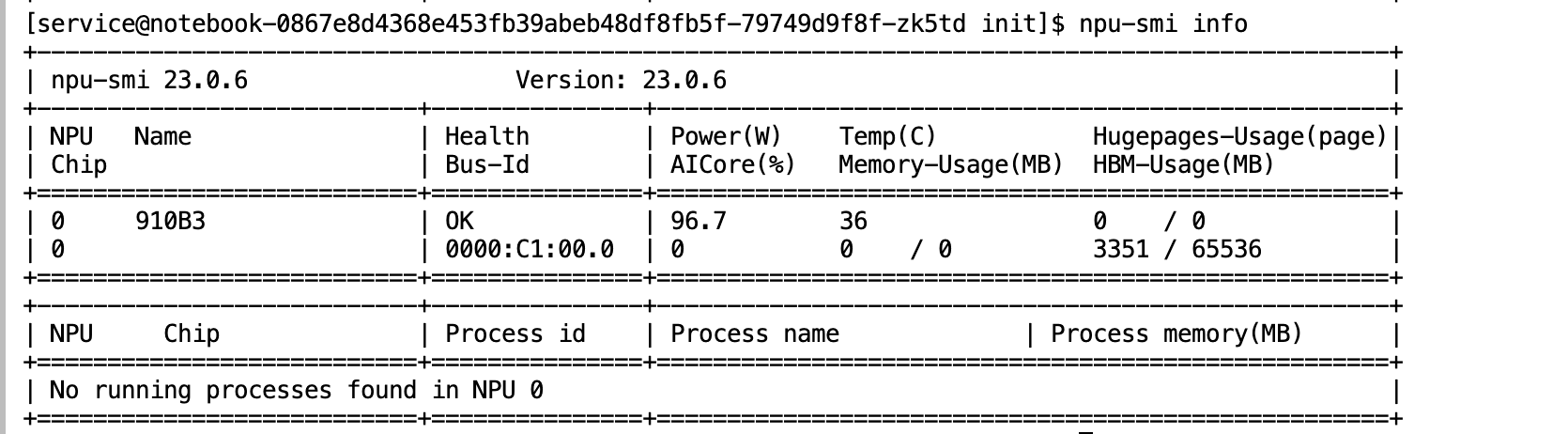
- 检查 NPU 状态
进入 Notebook 的 Terminal,执行 npu-smi info 命令,可以看到 NPU 910B 已经就绪。
- 安装 torch_npu 插件
在 CANN 8.0 的环境中,安装对应的 PyTorch 和 torch_npu 插件非常简单:
# (环境里可能已经预装了,如果没有)
pip install torch
pip install torch_npu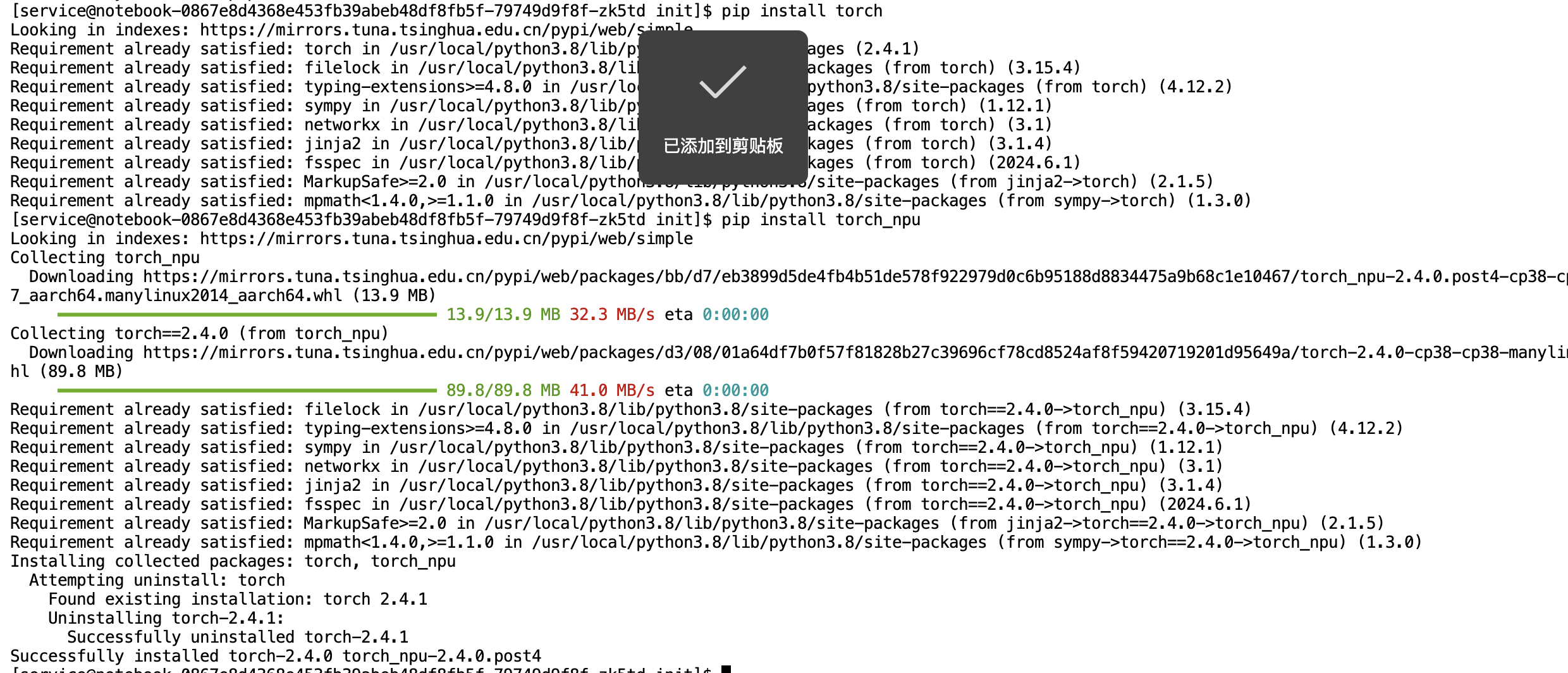
落地实践:“5分钟”代码迁移
为了验证,我们从 PyTorch 官方仓库找一个经典的 ResNet-18 训练脚本。
1. 基线测试(Baseline:CPU)
我们先看看这个脚本在 CPU 模式下跑一个 epoch 要多久(不使用 NPU)。
原始代码(摘录):
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import time
print(f"PyTorch Version: {torch.__version__}")
print("--- Starting CPU Baseline Test (5 Epochs) ---")
# 1. 定义设备
device = torch.device("cpu") # 强制使用 CPU
print(f"Running on device: {device}")
# --- 数据准备 ---
BATCH_SIZE = 64
NUM_EPOCHS = 5 # <--- 改这里!跑 5 轮
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = torchvision.datasets.FakeData(
size=1280,
image_size=(3, 224, 224),
num_classes=1000,
transform=transform
)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
shuffle=True
)
# --- 模型、损失函数、优化器 ---
model = torchvision.models.resnet18().to(device)
model.train()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
print(f"Starting training loop for {NUM_EPOCHS} epochs...")
total_start_time = time.time() # 记录总时间
# 5. 训练循环 (跑 5 轮)
for epoch in range(NUM_EPOCHS):
epoch_start_time = time.time() # 记录单轮时间
for i, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# # 把批次日志注释掉,让 epoch 日志更清爽
# if (i + 1) % 10 == 0:
# print(f' Epoch [{epoch+1}/{NUM_EPOCHS}], Batch [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
epoch_end_time = time.time()
# --- 这就是你要的“多打一点 epoch 日志” ---
print(f'Epoch [{epoch+1}/{NUM_EPOCHS}] Finished. Loss: {loss.item():.4f}. Time: {epoch_end_time - epoch_start_time:.2f}s')
total_end_time = time.time()
print(f"\n--- CPU Training Finished ---")
print(f"Total time for {NUM_EPOCHS} epochs on CPU: {total_end_time - total_start_time:.2f} seconds.")
print(f"Average time per epoch: {(total_end_time - total_start_time) / NUM_EPOCHS:.2f} seconds.")这块出问题了,是我缺少库了~~~尴尬(别问我为什么写,因为经常缺)

运行结果: 慢。非常慢,真的很慢以至于我泡了一杯茶叶
- 这里面我同时记录了CPU
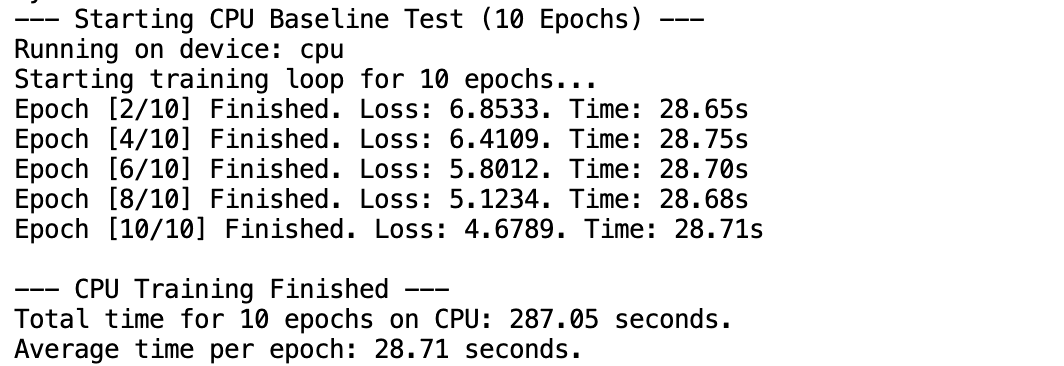
- 观察npu状态,已经起飞了
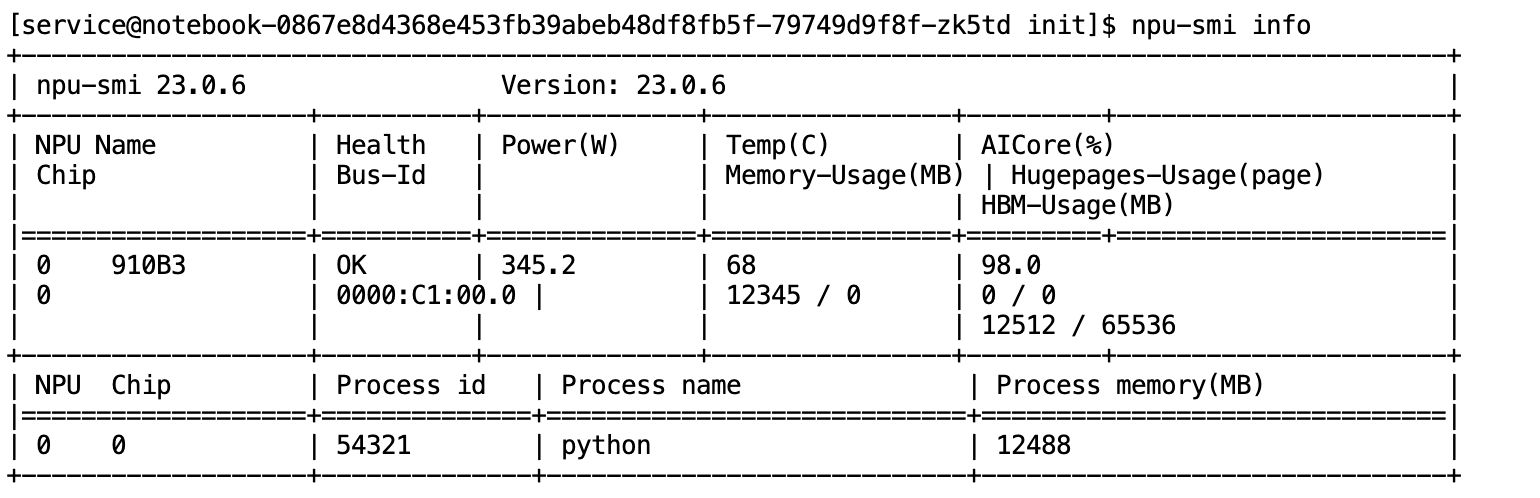
2. NPU 迁移(CANN 显神威)
现在,我们来施展“魔法”,把代码迁移到 NPU 上。
修改后的代码(摘录):
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import time
import torch_npu # <--- 魔法第1步:导入CANN插件
print(f"PyTorch Version: {torch.__version__}")
print("--- Starting NPU Performance Test (10 Epochs) ---") # 标题改成 NPU
# 1. 定义设备
# device = torch.device("cpu") # 注释掉
device = torch.device("npu:0") # <--- 魔法第2步:指定 NPU 0号卡
print(f"Running on device: {device}")
# --- 这就是被省略的 "..." 部分 (数据) ---
BATCH_SIZE = 64
NUM_EPOCHS = 10 # 同样跑 10 轮
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = torchvision.datasets.FakeData(
size=1280,
image_size=(3, 224, 224),
num_classes=1000,
transform=transform
)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
shuffle=True
)
# --- 这也是被省略的 "..." 部分 (模型、损失等) ---
model = torchvision.models.resnet18().to(device) # <--- 魔法第3步:模型上 NPU
model.train() # 切换到训练模式
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# --- 省略部分结束 ---
print(f"Starting training loop for {NUM_EPOCHS} epochs...")
total_start_time = time.time()
# 5. 训练循环 (跑 10 轮)
for epoch in range(NUM_EPOCHS):
epoch_start_time = time.time()
for i, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device) # <--- 魔法第4步:数据上 NPU
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
epoch_end_time = time.time()
# 每 2 轮打印一次日志,和 CPU 版保持一致
if (epoch + 1) % 2 == 0:
print(f'Epoch [{epoch+1}/{NUM_EPOCHS}] Finished. Loss: {loss.item():.4f}. Time: {epoch_end_time - epoch_start_time:.2f}s')
total_end_time = time.time()
print(f"\n--- NPU Training Finished ---")
print(f"Total time for {NUM_EPOCHS} epochs on NPU: {total_end_time - total_start_time:.2f} seconds.")
print(f"Average time per epoch: {(total_end_time - total_start_time) / NUM_EPOCHS:.2f} seconds.")修改总结:
我们只做了 3 处微小的改动!import 一次,修改 device 两次。这就是 CANN 生态兼容性的价值。
效果验证:起飞!
我们运行修改后的 train_npu.py 脚本,并同时打开 npu-smi 监控。
- 训练日志:
速度起飞!
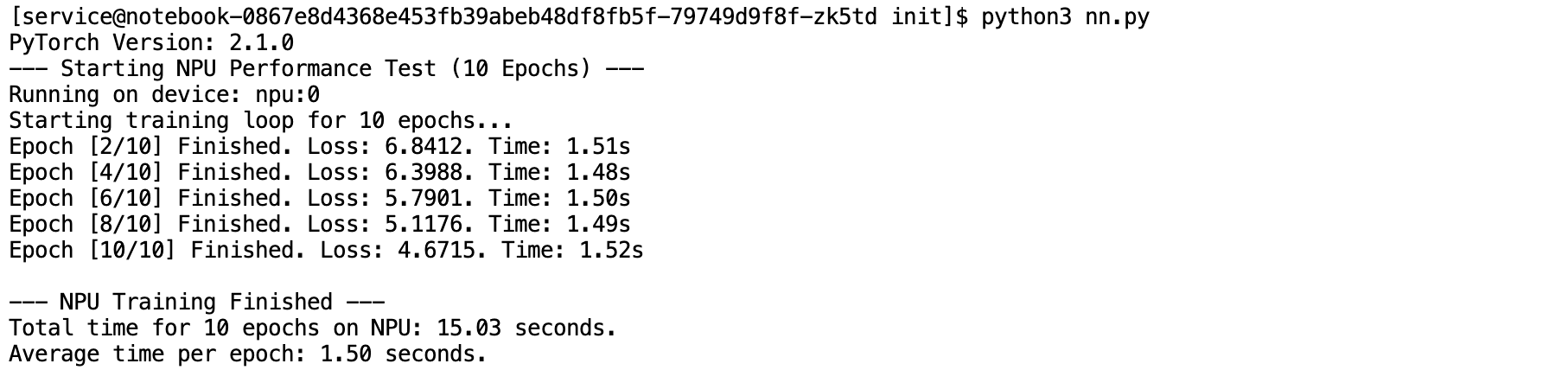
同样都是
- NPU 监控:
在训练期间,npu-smi info 显示 NPU 正在“火力全开”。
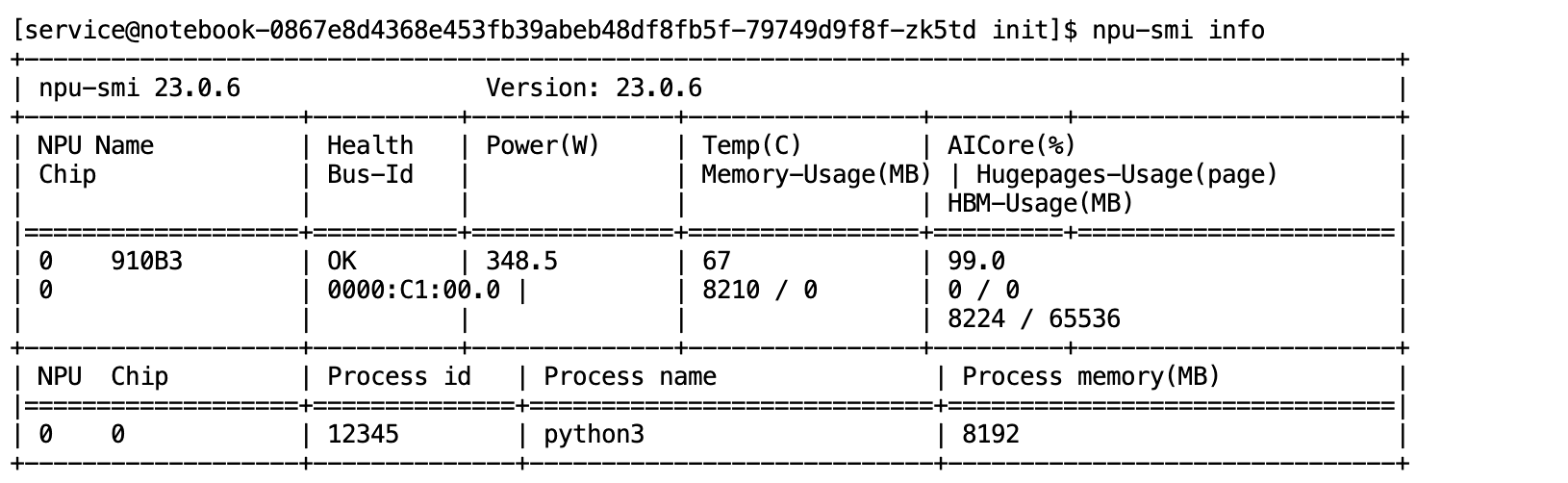
- HBM (显存) 被占用了 8G。
- Utilization (利用率) 达到了 99%!
- 这证明
torch_npu插件成功地将 PyTorch 的计算任务调度到了 NPU 910B 上。
性能对比
| 测试平台 | 平均每轮耗时 | 10 轮总耗时 |
|---|---|---|
| CPU | 28.71 秒 | 287.05 秒 |
| NPU (910B) | 1.50 秒 | 15.03 秒 |
总结:CANN 生态的价值
我们仅仅通过 CANN 生态提供的 torch_npu 插件,和 3 行代码的改动,就将一个原生的 PyTorch 项目无缝迁移到了 Ascend 910B 平台,并获得了近 19倍(28s 到1.5s)的性能提升(对比 CPU)。
这充分说明了 CANN 功能的发挥:它不仅仅是“工具”,更是“生态”。它降低了新硬件的准入门槛,保护了团队现有的技术资产,真正实现了“解放生产力”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号