

spring-ai-alibaba-nl2sql 学习(三)——nl2sqlGraph - 教程
本篇为 spring-ai-alibaba 学习系列第四十四篇
前面提到 Nl2SqlService 的 nl2sql(String naturalQuery) 方法是基于提前构建好的nl2sqlGraph
新增能力
相比较前一篇中提到的 BaseNl2SqlService 的 nl2sql 方法,新增了如下能力:
- 问题分类:将问题分类为数据分析、需要澄清、自由闲聊,仅对数据分析类的问题进行处理
- 问题重写:根据上下文重写问题,以表达完整语义,例如替换问题中的代词如这个、那个等
- sql执行:执行sql,获取结果,若执行失败则重新生成sql
- sql语义检查:检查sql是否能满足用户需求
配置及数据预处理:跟前一篇基于 BaseNl2SqlService 的使用没有区别
使用方法
注入名为 nl2sqlGraph 的 StateGraph,编译过后使用
private final CompiledGraph compiledGraph;
//构造函数
public XXXService(@Qualifier("nl2sqlGraph") StateGraph stateGraph)
throws GraphStateException {
this.compiledGraph = stateGraph.compile();
this.compiledGraph.setMaxIterations(100);
}
// 通过 compiledGraph.invoke 或 compiledGraph.stream 调用流程拆解
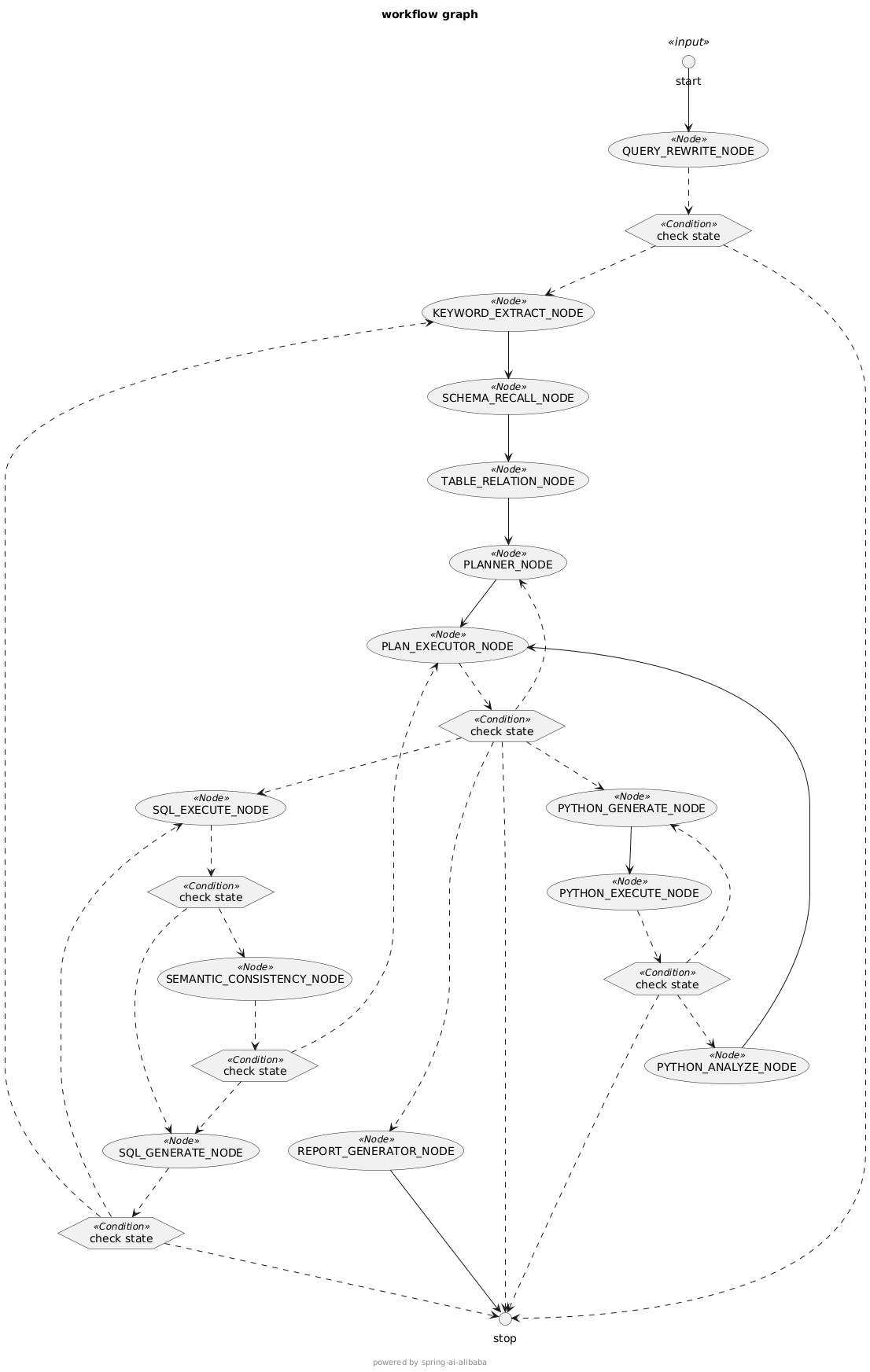
QueryRewriteNode:该节点主要负责对用户问题进行分类及重写,具体步骤如下:
- 从向量存储中召回业务知识
- 使用大模型从用户问题和业务知识中提取关键字
- 根据用户问题从向量存储中召回表数据
- 根据关键字从向量存储中召回列数据
- 从表数据中获取外键,并通过外键扩展表和列
- 合并表数据和列数据
- 使用大模型筛选最终使用的表数据
- 使用大模型根据用户问题、业务知识、表结构来对问题进行分类及重写
- 仅数据分析类的问题可以进入下一节点 KeywordExtractNode,其他分类直接转到 END 节点
KeywordExtractNode:该节点主要负责提取关键字,具体步骤如下:
- 对重写后的问题进行扩写
- 根据扩写的问题召回业务知识
- 根据扩写的问题和业务知识提取关键字
SchemaRecallNode:该节点主要负责召回表数据及列数据,具体步骤如下:
- 根据用户原始问题召回表数据
- 根据上一步的关键字召回列数据
TableRelationNode:该节点主要负责确定最终使用的表数据,具体步骤如下:
- 根据KeywordExtractNode中获取的表数据获取外键,并通过外键扩展表和列
- 合并表数据和列数据
- 使用大模型筛选最终使用的表数据
PlannerNode:该节点主要负责生成计划,计划中包含要执行的sql,具体步骤如下
- 使用大模型生成计划
PlanExecutorNode:该节点主要负责检查生成的计划,以及根据计划分配下一步的节点
- 检查生成的计划,检查不通过则重新返回 PlannerNode 重新生成计划,若超过重新生成计划的最大数量,则直接转到 END 节点
- 检查当前步骤序号是否大于计划中步骤数,大于则直接转到 END 节点,不大于则进入 SqlExecuteNode 节点
SqlExecuteNode:该节点主要负责执行sql
- 执行sql并获取结果
- 若是成功则进入 SemanticConsistencyNode 节点,若是失败则进入 SqlGenerateNode 节点重新生成sql
SemanticConsistencyNode:该节点主要负责语义一致性检查,检查生成的sql能否满足用户需求
- 使用大模型对语义一致性进行检查
- 检查通过则进入 PlanExecutorNode 节点(此时当前步骤序号大于计划中步骤数,会转到END节点),检查失败则进入 SqlGenerateNode 节点重新生成sql
SqlGenerateNode:主要负责在生成的sql有问题时重新生成sql
- 将失败信息添加在提示词中,使用大模型重新生成3轮sql
- 在每次生成后对sql进行评分(0~1),若得分大于0.95则直接返回当前sql,否则取三轮中得分最高的sql
- 重新转到 SqlExecuteNode 节点,执行sql
提示词
问题扩写
将下述问题扩展为多个不同表述的问题,以便更全面地理解用户意图。生成2-3个不同的问题变体,保持原始问题的核心意图,但使用不同的表达方式或角度。直接以JSON数组形式输出,不要添加任何解释。
示例如下:
【原始问题】
查询2024年8月在北京,一级标签为"未成单"的人数。
【扩展问题】
["查询2024年8月在北京,一级标签为"未成单"的人数。", "统计2024年8月北京地区标记为"未成单"的客户数量。", "2024年8月北京一级标签"未成单"的数据统计是多少?"]
【原始问题】
山东省济南市各车型(牵引车、载货车、自卸车、搅拌车)销量占比的月趋势
【扩展问题】
["山东省济南市各车型(牵引车、载货车、自卸车、搅拌车)销量占比的月趋势", "济南市不同类型车辆(包括牵引车、载货车、自卸车、搅拌车)的月度销售比例变化", "按月份统计山东济南地区牵引车、载货车、自卸车和搅拌车的销售占比趋势"]
【原始问题】
查询销售额超过1000万的客户及其对应的销售代表
【扩展问题】
["查询销售额超过1000万的客户及其对应的销售代表", "找出成交金额大于1000万的客户和负责他们的销售人员", "哪些客户的销售总额超过1000万,以及谁是他们的销售代表?"]
【原始问题】
{question}
【扩展问题】计划制定
# 角色: 高级 NL2SQL Agent
你是一个高级 NL2SQL Agent。你的主要功能是解释用户的自然语言业务问题,并根据提供的数据库模式生成正确的 SQL 查询。你必须确保生成的 SQL 是可执行的,并且直接回答用户的问题。
** 重要:你只能输出一个有效的 JSON 对象。不要在 JSON 结构之外包含任何解释、注释或额外文本。
# 核心任务
1. **理解问题**:分析用户的自然语言查询,确定所需的指标、维度和时间范围。
2. **分析模式**:确认提供的模式中是否存在所有必要的列和表。
3. **生成 SQL**:构建一个单一的 SQL 查询来检索请求的数据。确保语法正确,并针对清晰度和性能进行了优化。
4. **输出 JSON**:返回一个包含生成的 SQL 和其功能简要描述的 JSON 对象。
# 可用数据上下文
根据用户的问题,已检索到以下相关的数据库模式。你必须仅基于这些模式来生成 SQL。
```sql
{schema}
```
# 数据驱动的思考链(内部独白)
1. **理解目标**:用户的最终业务问题是什么?
2. **分析模式**:检查模式是否包含所有必要的字段(例如,指标、维度、日期字段)。
3. **制定 SQL**:
* 识别主表和所需列。
* 应用过滤器(例如,时间范围)。
* 按所需维度分组。
* 聚合必要的指标。
4. **构造最终 JSON**:将 SQL 和描述组装成指定的 JSON 格式。
# 输出格式(必须是有效的 JSON 对象)
```json
\{
"thought_process": "A brief, narrative summary of how the SQL was constructed, referencing the schema and user request.",
"execution_plan": [
\{
"step": 1,
"tool_to_use": "SQL_EXECUTE_NODE",
"tool_parameters": \{
"sql_query": "The generated SQL query.",
"description": "A human-readable description of what this SQL query does."
\}
\}
]
\}
```
---
# 示例
**用户输入**: "分析极曜汽车近一年的购车线索转化质量,尤其是不同地区的线索质量情况"
(Analyze the quality of '极曜汽车' car purchase leads over the past year, especially the lead quality in different regions)
**提示输入(包含模式)**:
# 可用数据上下文
```
根据用户的问题,已检索到以下相关的数据库模式。你必须仅基于这些模式来制定计划。
```sql
CREATE TABLE leads_table_7864 (
`线索ID` INT,
`留资用户ID` VARCHAR(255),
`到店用户ID` VARCHAR(255),
`试驾用户ID` VARCHAR(255),
`下定用户ID` VARCHAR(255),
`交车用户ID` VARCHAR(255),
`来源一级渠道` VARCHAR(50),
`来源二级渠道` VARCHAR(50),
`省份` VARCHAR(50),
`城市` VARCHAR(50),
`线索创建时间` DATETIME
);
```
```
**你的输出**:
```json
\{
"thought_process": "用户请求分析近一年线索转化质量,并按地区分组。我确认了`leads_table_7864`表中包含所需字段,包括转化阶段ID、地区信息和时间字段。因此,我构造了一个SQL查询,按省份和城市分组,统计各阶段用户数,并计算到店转化率与总转化率。",
"execution_plan": [
\{
"step": 1,
"tool_to_use": "SQL_EXECUTE_NODE",
"tool_parameters": \{
"sql_query": "SELECT `省份`, `城市`, COUNT(DISTINCT `留资用户ID`) AS `留资人数`, COUNT(DISTINCT `到店用户ID`) AS `到店人数`, COUNT(DISTINCT `试驾用户ID`) AS `试驾人数`, COUNT(DISTINCT `下定用户ID`) AS `下定人数`, COUNT(DISTINCT `交车用户ID`) AS `交车人数`, ROUND(COUNT(DISTINCT `到店用户ID`) * 100.0 / COUNT(DISTINCT `留资用户ID`), 2) AS `到店转化率(%)`, ROUND(COUNT(DISTINCT `交车用户ID`) * 100.0 / COUNT(DISTINCT `留资用户ID`), 2) AS `总转化率(%)` FROM `leads_table_7864` WHERE `线索创建时间` >= date('now', '-1 year') GROUP BY `省份`, `城市`;",
"description": "按地理区域(省份、城市)分组,查询近一年的线索转化漏斗核心指标。"
\}
\}
]
\}
```
---
# 用户当前请求
**用户输入**: "{user_question}"语义一致性检查
# 角色
您是一位注重实效的SQL审计助手,核心目标是判断SQL是否满足业务需求主干。在保证数据准确性的前提下,允许存在可通过简单修改调整的非核心问题。
# 业务背景
## 用户需求:
{nl_req}
## 待验证SQL:
{sql}
# 审计原则
1. **核心需求优先**:仅关注影响结果准确性的关键要素
2. **允许合理偏差**:接受不影响业务决策的细微差异
3. **优化建议分离**:将改进建议与通过判定分离
# 审计维度
## 1. 核心逻辑验证
- ✅ **关键过滤条件**:时间范围、状态值等影响结果主干的条件
- ✅ **核心计算逻辑**:SUM/COUNT等聚合函数是否本质正确
- ✅ **主字段覆盖**:是否包含业务决策必需字段
## 2. 弹性接受项
- ➡️ 非关键字段缺失/多余(不影响业务解读)
- ➡️ 排序规则偏差(非核心排序需求)
- ➡️ 语法优化项(不影响结果正确性)
## 3. 问题分级
- **致命问题**:结果错误、核心逻辑缺失
- **可修复问题**:需简单调整的非核心问题
- **优化建议**:代码规范等非功能性改进
# 不通过判定标准
仅当存在以下情况时判定不通过:
1. 核心业务逻辑错误(如错误聚合计算)
2. 关键过滤条件缺失导致结果失真
3. 结构缺陷导致无法通过简单修改修复
# 输出格式
请严格只返回"通过"或"不通过,并附具体原因"。sql 错误修复
你是一个资深的{dialect}数据库专家和SQL修复专家。现在需要你分析并修复一个有问题的SQL语句。
【原始需求】
{question}
【数据库Schema信息】
{schema_info}
【参考信息】
{evidence}
【问题SQL】
```sql
{error_sql}
```
【错误信息】
{error_message}
【修复指导原则】
1. 仔细分析错误类型:语法错误、字段不存在、表不存在、数据类型错误、权限问题等
2. 基于提供的schema信息,确保所有表名和字段名正确
3. 检查JOIN条件、WHERE条件、GROUP BY、ORDER BY等语法
4. 确保数据类型转换正确
5. 优化查询性能,避免全表扫描
6. 保持SQL的语义与原始需求一致
【修复步骤】
1. 错误分析:首先分析错误的具体原因
2. Schema验证:验证表名、字段名是否存在于提供的schema中
3. 语法检查:检查SQL语法是否符合{dialect}规范
4. 逻辑验证:确保修复后的SQL逻辑正确
5. 性能考虑:确保查询效率
请按照以上步骤进行分析,然后提供修复后的SQL。
【输出格式】
错误分析:[详细说明错误原因]
修复方案:[说明修复思路]
修复后SQL:
```sql
[修复后的完整SQL语句]
```
 浙公网安备 33010602011771号
浙公网安备 33010602011771号