
102302156 李子贤 数据采集第四次作业
作业1
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
(1)代码和运行结果
点击查看代码
import time
import sqlite3
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 数据库配置
DB_FILE = 'stock_db.sqlite3'
# 板块URL
BOARD_URLS = {
'沪深A股': 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board',
'上证A股': 'http://quote.eastmoney.com/center/gridlist.html#sh_a_board',
'深证A股': 'http://quote.eastmoney.com/center/gridlist.html#sz_a_board'
}
def init_db():
"""初始化数据库"""
conn = sqlite3.connect(DB_FILE)
cursor = conn.cursor()
create_sql = """
CREATE TABLE IF NOT EXISTS stock_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
board TEXT NOT NULL,
code TEXT NOT NULL,
name TEXT NOT NULL,
price REAL,
change_pct REAL,
change_val REAL,
volume REAL,
turnover REAL,
amplitude REAL,
high REAL,
low REAL,
open REAL,
close REAL,
crawl_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(board, code)
);
"""
cursor.execute(create_sql)
conn.commit()
conn.close()
print(f"数据库初始化成功:{DB_FILE}")
def save_db(board, stocks):
"""保存数据到数据库"""
if not stocks:
return
conn = sqlite3.connect(DB_FILE)
cursor = conn.cursor()
insert_sql = """
INSERT INTO stock_data (
board, code, name, price, change_pct,
change_val, volume, turnover, amplitude, high,
low, open, close, crawl_time
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
ON CONFLICT(board, code) DO UPDATE SET
price = excluded.price,
change_pct = excluded.change_pct,
change_val = excluded.change_val,
volume = excluded.volume,
turnover = excluded.turnover,
amplitude = excluded.amplitude,
high = excluded.high,
low = excluded.low,
open = excluded.open,
close = excluded.close,
crawl_time = excluded.crawl_time;
"""
current_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
stocks_with_time = [s + (current_time,) for s in stocks]
cursor.executemany(insert_sql, stocks_with_time)
conn.commit()
conn.close()
print(f"成功保存 {len(stocks)} 条{board}数据")
def wait_load(driver):
"""等待页面加载"""
target = 'div.quotetable table tbody tr'
for i in range(3):
WebDriverWait(driver, 15).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, target)))
time.sleep(2)
return True
time.sleep(10)
return len(driver.find_elements(By.CSS_SELECTOR, target)) > 0
def print_header():
"""打印表格表头"""
print("\n" + "=" * 200)
header = (
f"{'序号':<6} | "
f"{'代码':<10} | "
f"{'名称':<10} | "
f"{'最新价':<10} | "
f"{'涨跌幅':<10} | "
f"{'涨跌额':<10} | "
f"{'成交量(手)':<14} | "
f"{'成交额':<12} | "
f"{'振幅':<10} | "
f"{'最高':<10} | "
f"{'最低':<10} | "
f"{'今开':<10} | "
f"{'昨收':<10}"
)
print(header)
print("-" * 200)
def print_row(index, stock):
"""打印单条股票数据"""
row = (
f"{index:<6} | "
f"{stock[1]:<10} | "
f"{stock[2]:<10} | "
f"{stock[3] if stock[3] else '-':<10} | "
f"{f'{stock[4]}%' if stock[4] else '-':<10} | "
f"{stock[5] if stock[5] else '-':<10} | "
f"{f'{stock[6] / 10000:.2f}万' if stock[6] else '-':<14} | "
f"{f'{stock[7] / 100000000:.2f}亿' if stock[7] else '-':<12} | "
f"{f'{stock[8]}%' if stock[8] else '-':<10} | "
f"{stock[9] if stock[9] else '-':<10} | "
f"{stock[10] if stock[10] else '-':<10} | "
f"{stock[11] if stock[11] else '-':<10} | "
f"{stock[12] if stock[12] else '-':<10}"
)
print(row)
def parse_text(text, units=None):
"""解析文本为数值"""
if not units:
units = []
cleaned = ''.join([c for c in text.strip() if c.isdigit() or c in '.%' or c in units])
if not cleaned or cleaned in ['-', '']:
return None
# 处理百分号
if cleaned.endswith('%'):
cleaned = cleaned[:-1]
# 处理单位
unit = ''
for u in units:
if cleaned.endswith(u):
unit = u
cleaned = cleaned[:-len(u)]
break
# 转换数值
val = float(cleaned)
if unit == '万':
val *= 10000
elif unit == '亿':
val *= 100000000
return val
def get_text(cell):
"""获取单元格文本(处理嵌套span)"""
try:
return cell.find_element(By.TAG_NAME, 'span').text.strip()
except:
return cell.text.strip()
def crawl_board(driver, board, url):
"""爬取单个板块数据"""
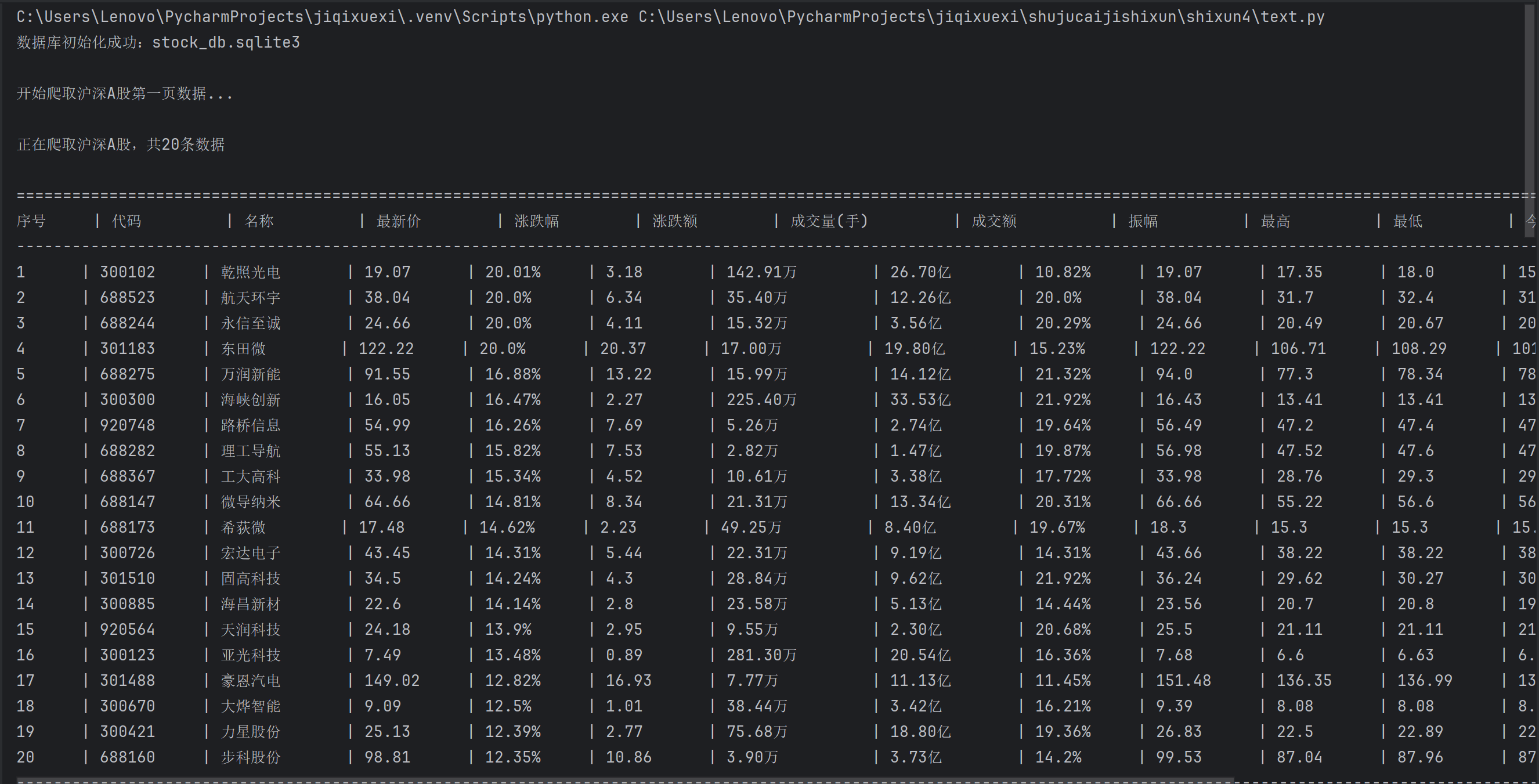
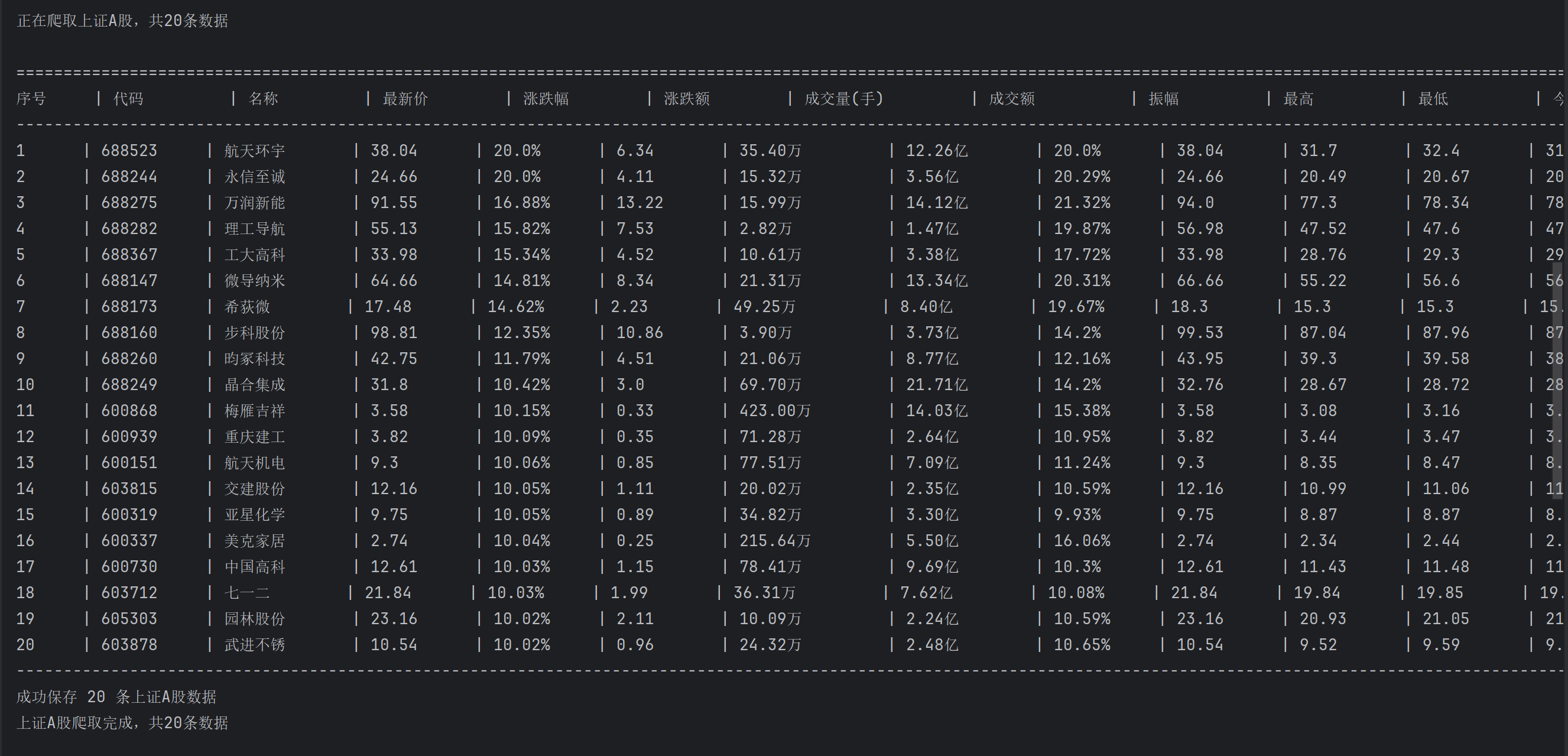
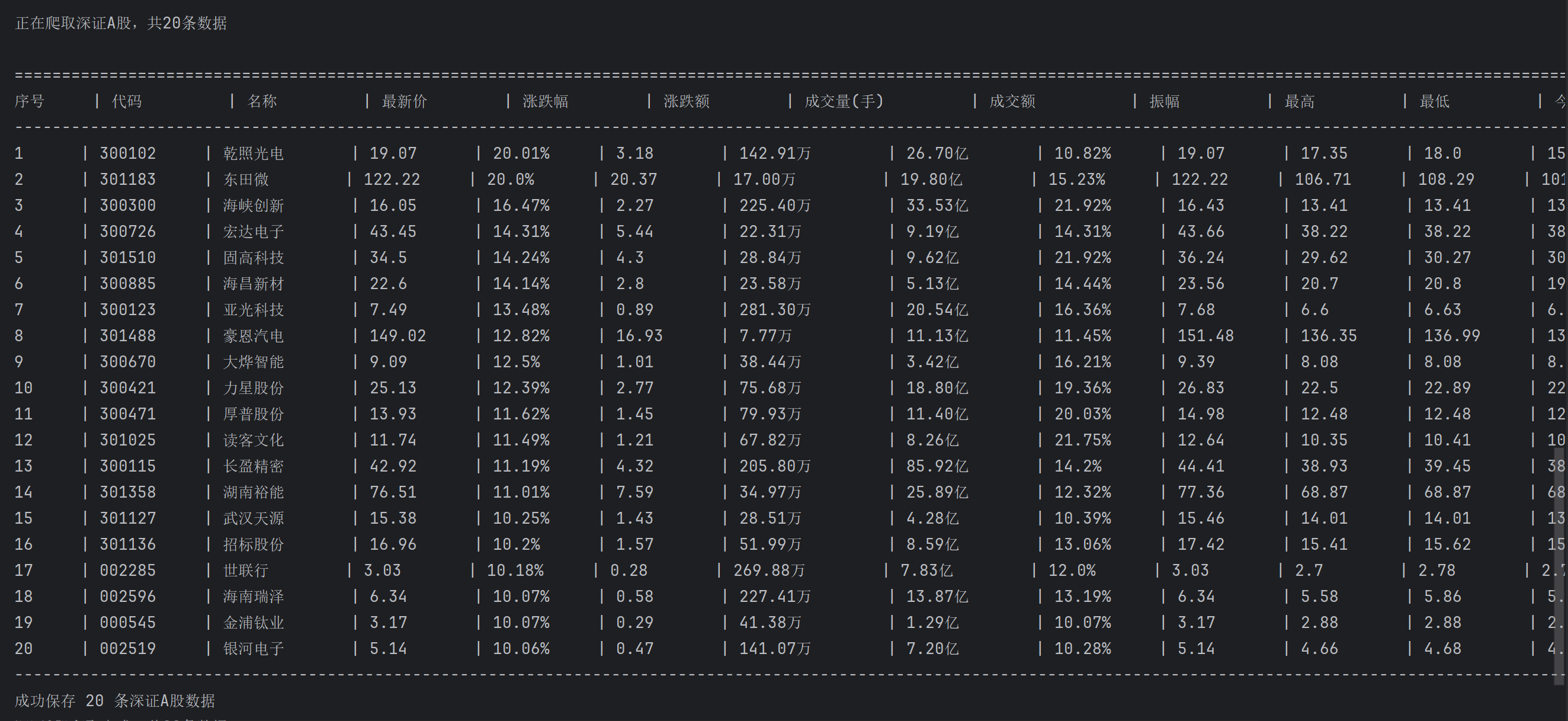
print(f"\n开始爬取{board}第一页数据...")
stocks = []
retry = 0
driver.get(url)
time.sleep(2)
while retry < 3:
if not wait_load(driver):
retry += 1
print(f"{board}加载失败,重试{retry}/3...")
driver.refresh()
time.sleep(5)
continue
table = driver.find_element(By.CSS_SELECTOR, 'div.quotetable table')
rows = table.find_elements(By.CSS_SELECTOR, 'tbody tr')
if not rows:
retry += 1
print(f"{board}无数据,重试{retry}/3...")
driver.refresh()
time.sleep(5)
continue
print(f"\n正在爬取{board},共{len(rows)}条数据")
print_header()
for row in rows:
cells = row.find_elements(By.TAG_NAME, 'td')
if len(cells) < 13:
continue
# 提取数据
seq = cells[0].text.strip()
code = cells[1].text.strip()
name = cells[2].text.strip()
price = parse_text(get_text(cells[4]))
change_pct = parse_text(get_text(cells[5]))
change_val = parse_text(get_text(cells[6]))
volume = parse_text(get_text(cells[7]), units=['万'])
turnover = parse_text(get_text(cells[8]), units=['亿'])
amplitude = parse_text(get_text(cells[9]))
high = parse_text(get_text(cells[10]))
low = parse_text(get_text(cells[11]))
open_val = parse_text(get_text(cells[12]))
close_val = parse_text(get_text(cells[13]))
# 保存数据
stock = (board, code, name, price, change_pct, change_val, volume, turnover, amplitude, high, low, open_val,
close_val)
stocks.append(stock)
print_row(seq, stock)
print("-" * 200)
break
if retry >= 3:
print(f"{board}爬取失败")
return stocks
def main():
init_db()
driver = webdriver.Chrome()
for board, url in BOARD_URLS.items():
stocks = crawl_board(driver, board, url)
save_db(board, stocks)
print(f"{board}爬取完成,共{len(stocks)}条数据\n")
time.sleep(3)
driver.quit()
print(f"所有板块爬取完成!数据库文件:{DB_FILE}")
if __name__ == "__main__":
main()
(2)心得体会
通过观察要爬取的目标网页,我们可以看到,要爬取的信息都存放在一个table中,所以
通过这个代码table = driver.find_element(By.CSS_SELECTOR, 'div.quotetable table')可以爬取到整个表格。
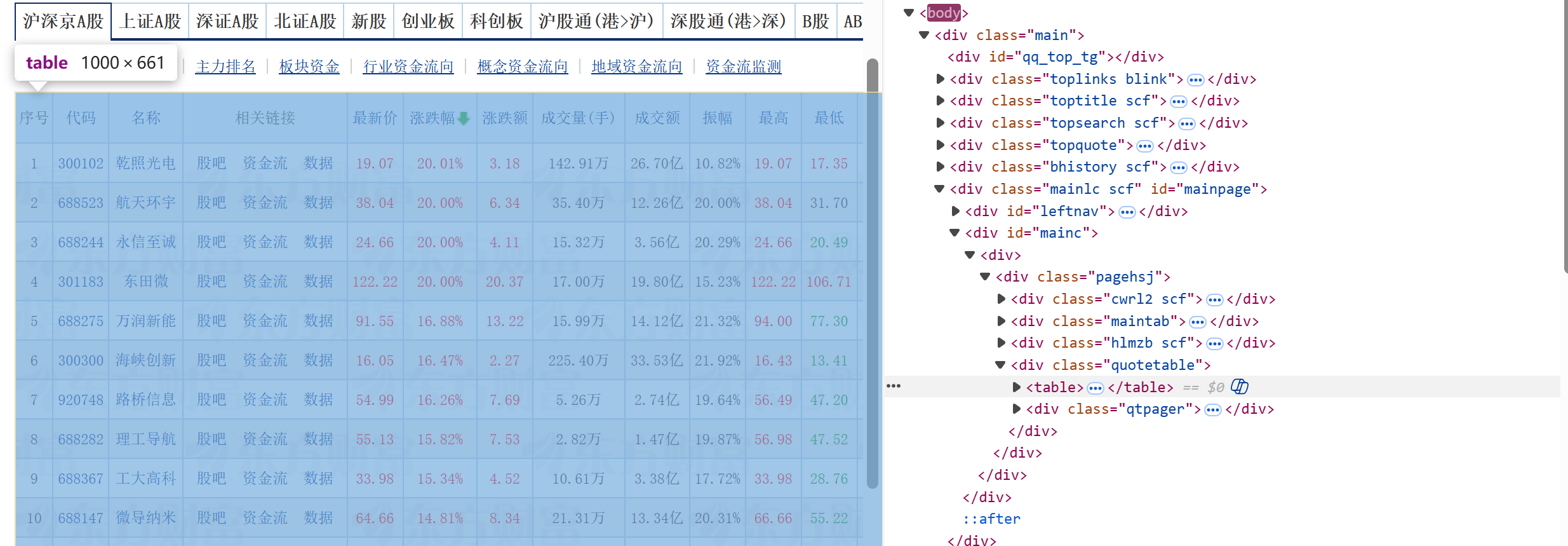
在table中继续提取找tr,就构成了一个存储每一行信息tr的列表
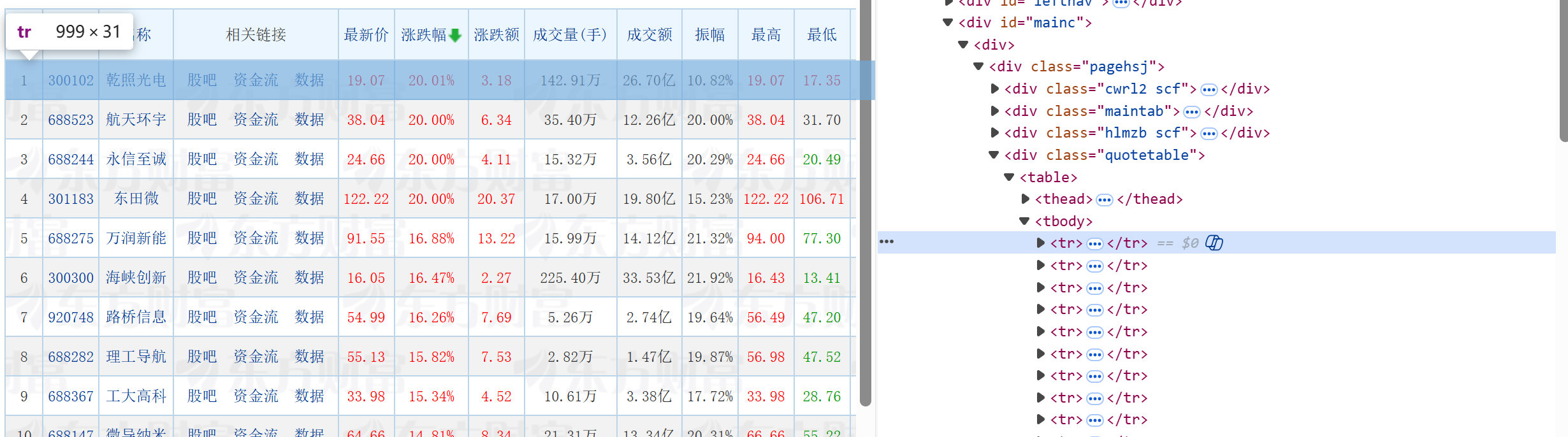
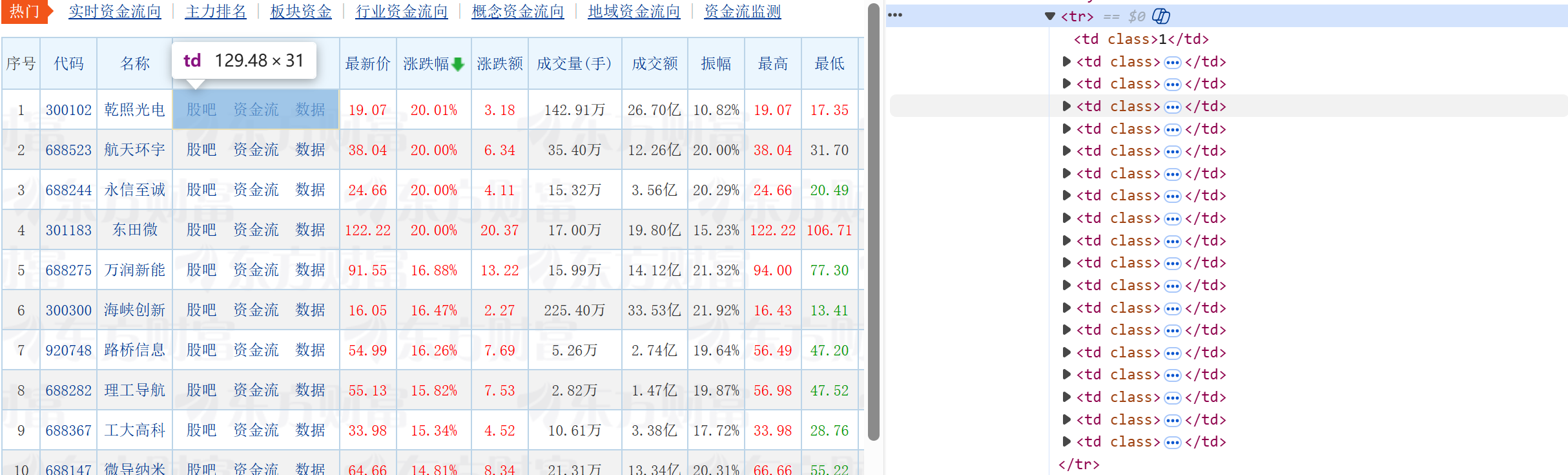
通过遍历每一个tr中的td,去爬取我们所需要的td索引信息,对爬取到的信息进行单位换算等操作。
通过这次实践,我体会到在之前只是用xpath去爬取这种动态数据的时候很不方便,需要去动态的寻找网页返回的js包,再去对js包去进行爬取才可以,但是用到Selenium,能直接解析由 JavaScript 动态生成的内容,解决了传统静态爬虫无法获取 JS 渲染数据的问题。
Gitee文件夹链接:https://gitee.com/lizixian66/shujucaiji/blob/homework4/gupiao.py
作业2
要求:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
(1)代码和运行结果
点击查看代码
import time
import re
import pymysql
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
class MoocCrawler:
def __init__(self, db_config):
# 浏览器配置
chrome_opt = Options()
chrome_opt.add_argument("--disable-gpu")
chrome_opt.add_argument("--no-sandbox")
chrome_opt.add_argument("--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
self.driver = webdriver.Chrome(options=chrome_opt)
self.wait = WebDriverWait(self.driver, 60)
# MySQL 数据库初始化
self.db_conn = pymysql.connect(**db_config)
self.db_cursor = self.db_conn.cursor()
self.create_table()
self.main_window = None
# 要爬取的课程URL
self.course_urls = [
"https://www.icourse163.org/course/BIT-268001?tid=1475671444",
"https://www.icourse163.org/course/cupl-1472831187?tid=1475446449"
]
def create_table(self):
self.db_cursor.execute("DROP TABLE IF EXISTS mooc_courses")
create_sql = """
CREATE TABLE IF NOT EXISTS mooc_courses (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
school VARCHAR(255),
teacher VARCHAR(255),
team TEXT,
count INT,
process VARCHAR(255),
intro TEXT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
self.db_cursor.execute(create_sql)
self.db_conn.commit()
print("MySQL 数据库表初始化完成!")
def login(self):
self.driver.get("https://www.icourse163.org")
input("登录成功后按回车键继续...")
self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@id="web-nav-container"]/div/div/div/div[3]/div[2]/div/span/a')))
print("登录成功!")
def go_personal_center(self):
center_btn = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@id="web-nav-container"]/div/div/div/div[3]/div[2]/div/span/a')))
center_btn.click()
time.sleep(3)
self.main_window = self.driver.current_window_handle
print("已进入个人中心")
def get_course_info(self, url):
print(f"\n开始爬取:{url}")
# 访问课程详情页
self.driver.get(url)
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".course-title")))
# 1. 课程名称
name = self.driver.find_element(By.CSS_SELECTOR, ".course-title").text.strip()
# 2. 学校名称
school_link = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="j-teacher"]/div/a')))
data_label = school_link.get_attribute("data-label")
school = data_label.split(".")[-1].strip() if "." in data_label else data_label.split("-")[-1].strip()
# 3. 主讲教师
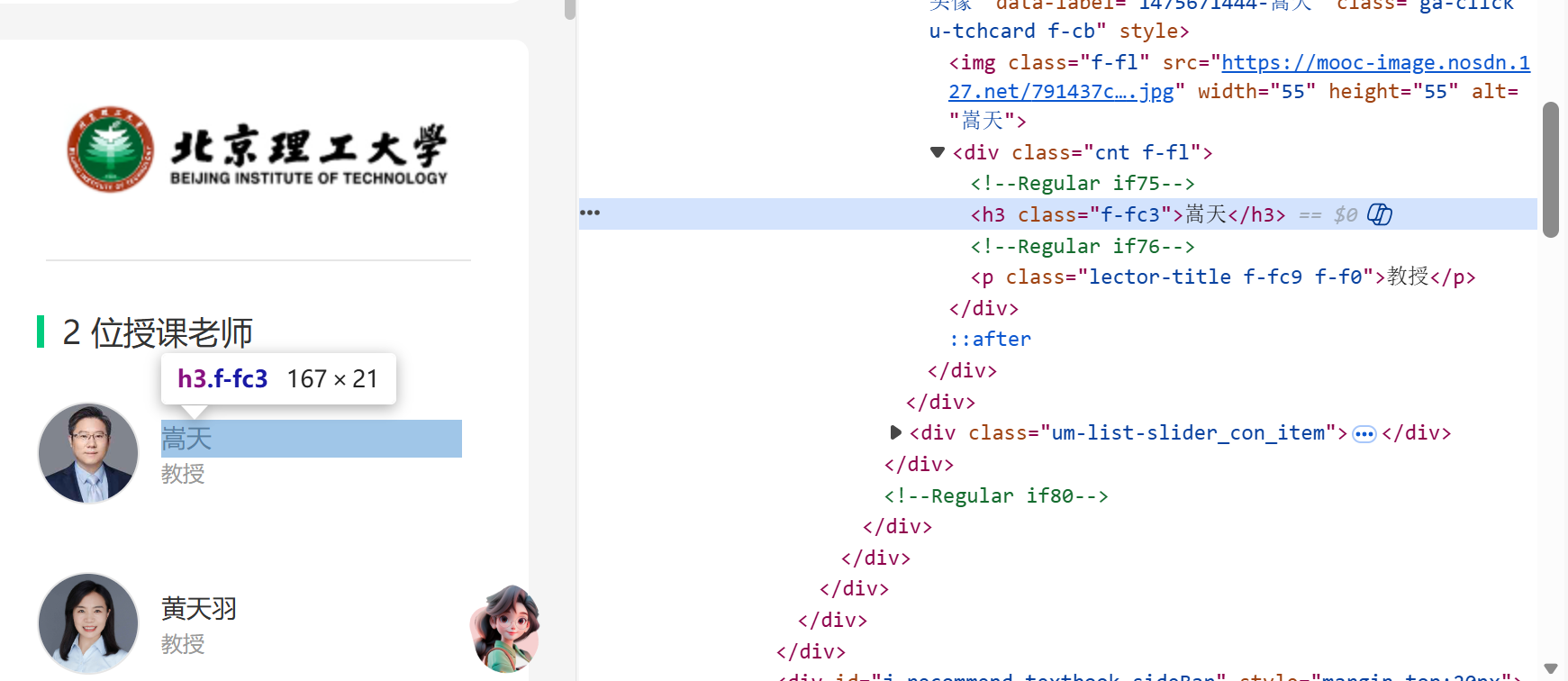
teacher = self.driver.find_element(By.XPATH,'//*[@id="j-teacher"]/div/div/div[2]/div/div/div/div/div/h3[1]').text.strip()
# 4. 教学团队
team = [t.text.strip() for t in self.driver.find_elements(By.XPATH, '//*[@id="j-teacher"]/div/div/div[2]/div/div/div/div/div/h3')]
team_str = ",".join(team)
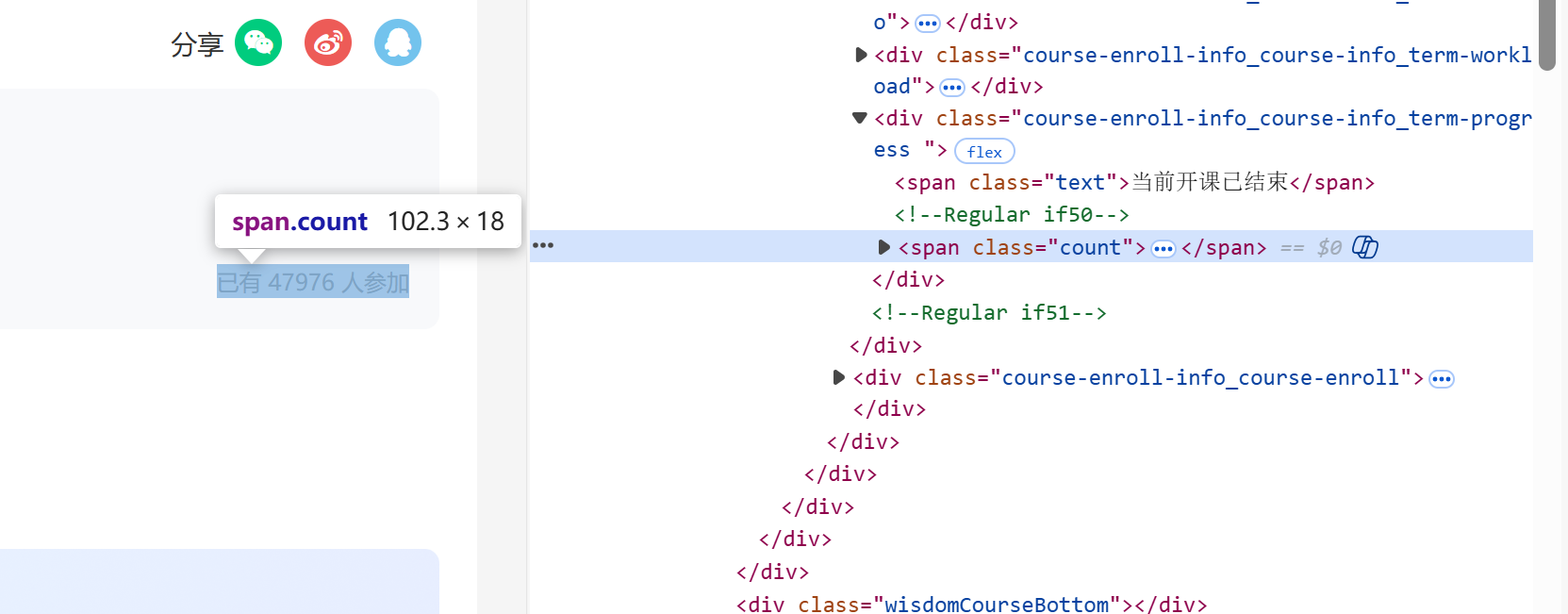
# 5. 参与人数
count_text = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="course-enroll-info"]/div/div[1]/div[4]/span[2]'))).text.strip()
count_text = count_text.replace('万', '0000').replace(',', '')
count = int(re.findall(r'(\d+)', count_text)[0])
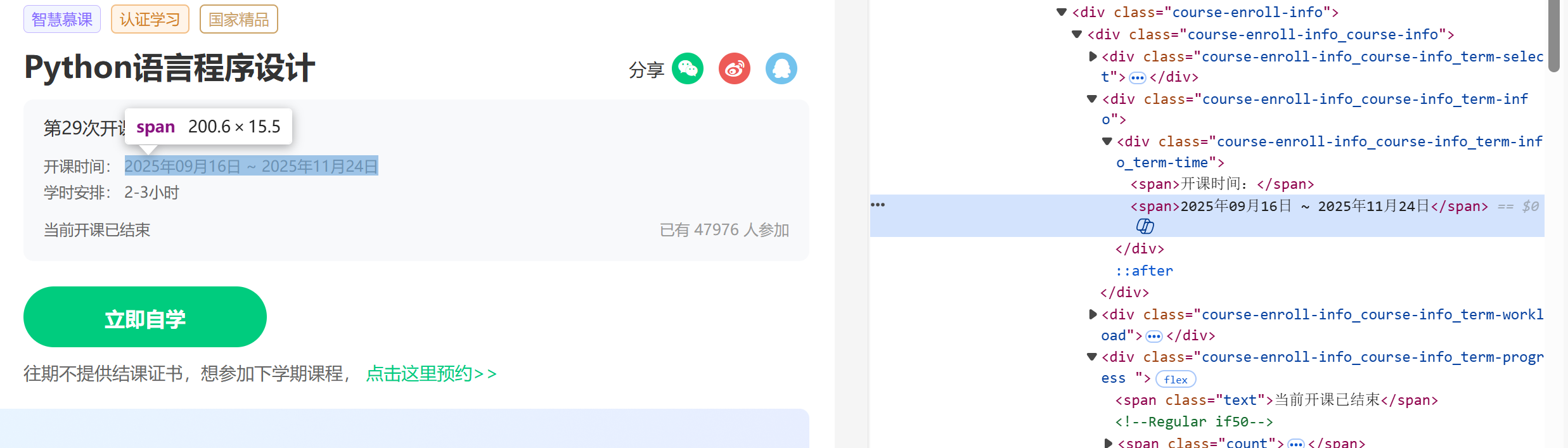
# 6. 课程进度/时间
time_container = self.driver.find_element(By.CSS_SELECTOR,".course-enroll-info_course-info_term-info_term-time")
process = "".join([span.text.strip() for span in time_container.find_elements(By.TAG_NAME, "span")])
# 7. 课程简介
intro = self.driver.find_element(By.CSS_SELECTOR, "#j-course-heading-intro").text.strip()
print(f"爬取成功:{name}")
return {
"name": name,
"school": school,
"teacher": teacher,
"team": team_str,
"count": count,
"process": process,
"intro": intro
}
def save_db(self, course):
"""插入语句"""
insert_sql = """
INSERT INTO mooc_courses (name, school, teacher, team, count, process, intro)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
try:
params = (
course["name"],
course["school"],
course["teacher"],
course["team"],
course["count"],
course["process"],
course["intro"]
)
self.db_cursor.execute(insert_sql, params)
self.db_conn.commit()
print(f"已保存到 MySQL 数据库:{course['name']}")
except Exception as e:
print(f"保存数据库出错:{e} | 参数数量:{len(params)}")
self.db_conn.rollback()
def crawl_all(self):
for i, url in enumerate(self.course_urls, 1):
print(f"\n===== 处理第{i}/{len(self.course_urls)}个课程 =====")
self.driver.execute_script(f"window.open('{url}');")
time.sleep(2)
self.driver.switch_to.window(self.driver.window_handles[-1])
course = self.get_course_info(url)
self.save_db(course)
self.driver.close()
self.driver.switch_to.window(self.main_window)
time.sleep(1)
def close(self):
self.db_cursor.close()
self.db_conn.close()
self.driver.quit()
print("\n爬虫结束,资源已释放")
def run(self):
print("中国大学MOOC爬虫启动!")
self.login()
self.go_personal_center()
self.crawl_all()
self.close()
if __name__ == "__main__":
db_config = {
'host': 'localhost',
'user': 'root',
'password': 'lzx2022666',
'database': 'mooc_db',
'charset': 'utf8mb4'
}
crawler = MoocCrawler(db_config)
crawler.run()
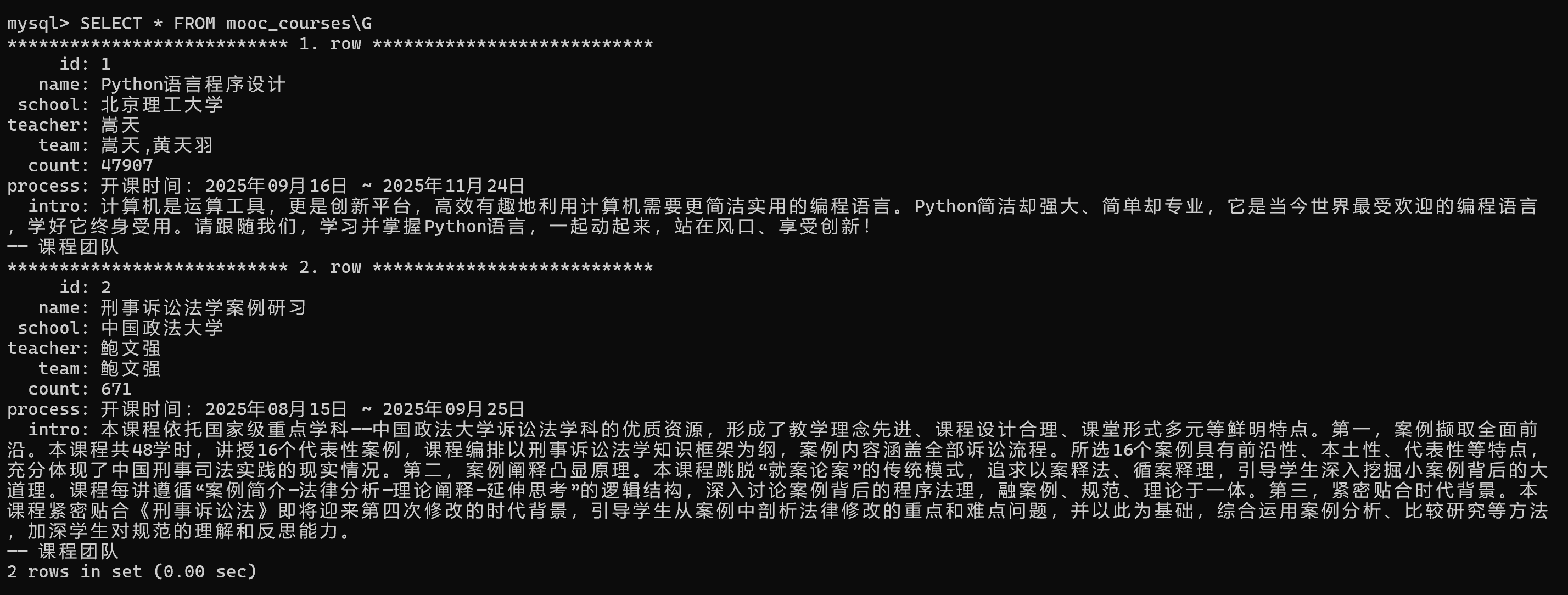
(2)心得体会
若要爬取到自己想要的信息,必须要找到准确的xpath,以下是我通过f12查看到的页面结构:
课程名称://[@id="g-body"]/div[1]/div/div/div/div[2]/div[2]/div/div[2]/div[1]/span[1]
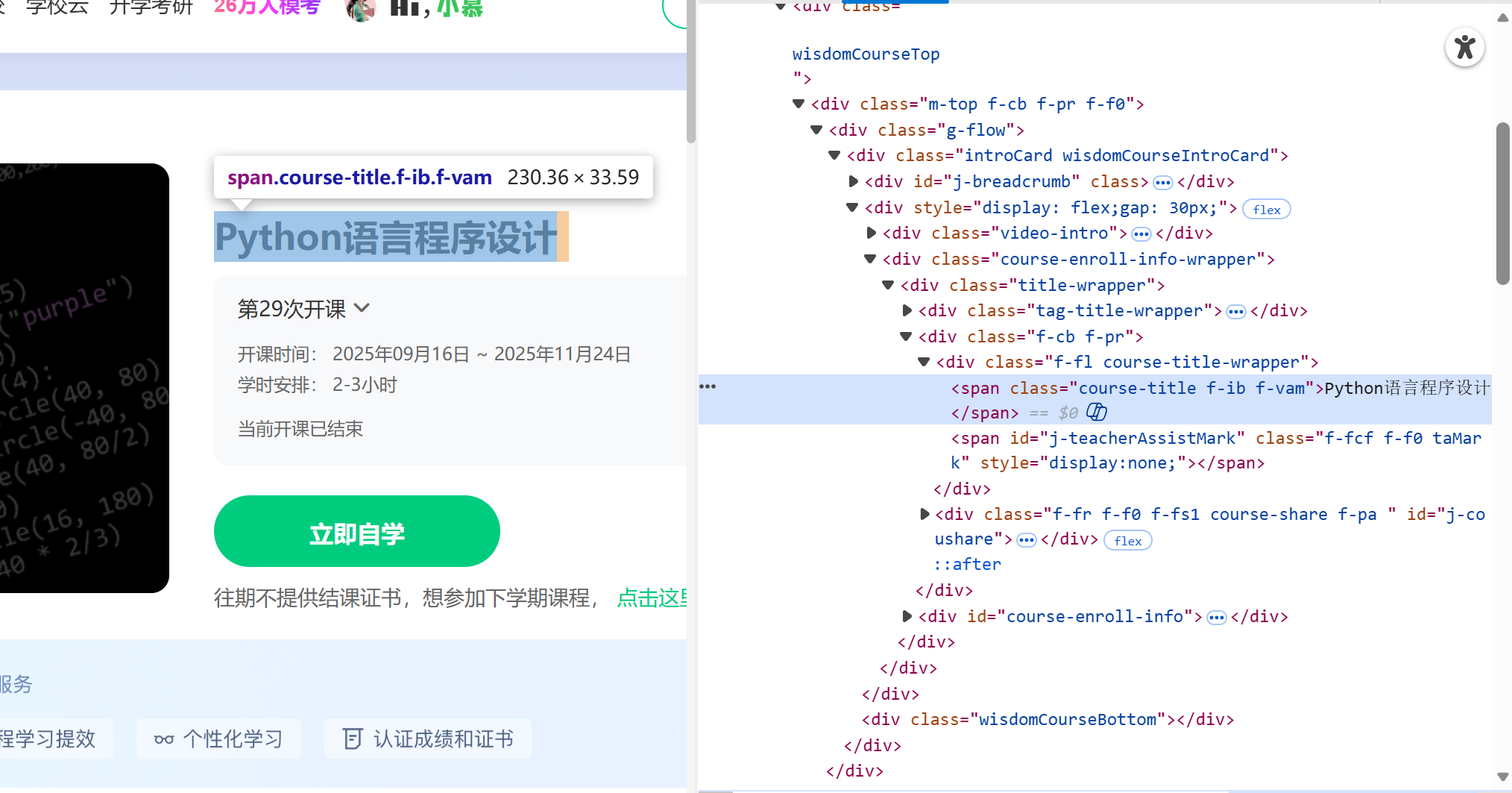
学校名称://[@id="j-teacher"]/div/a/img
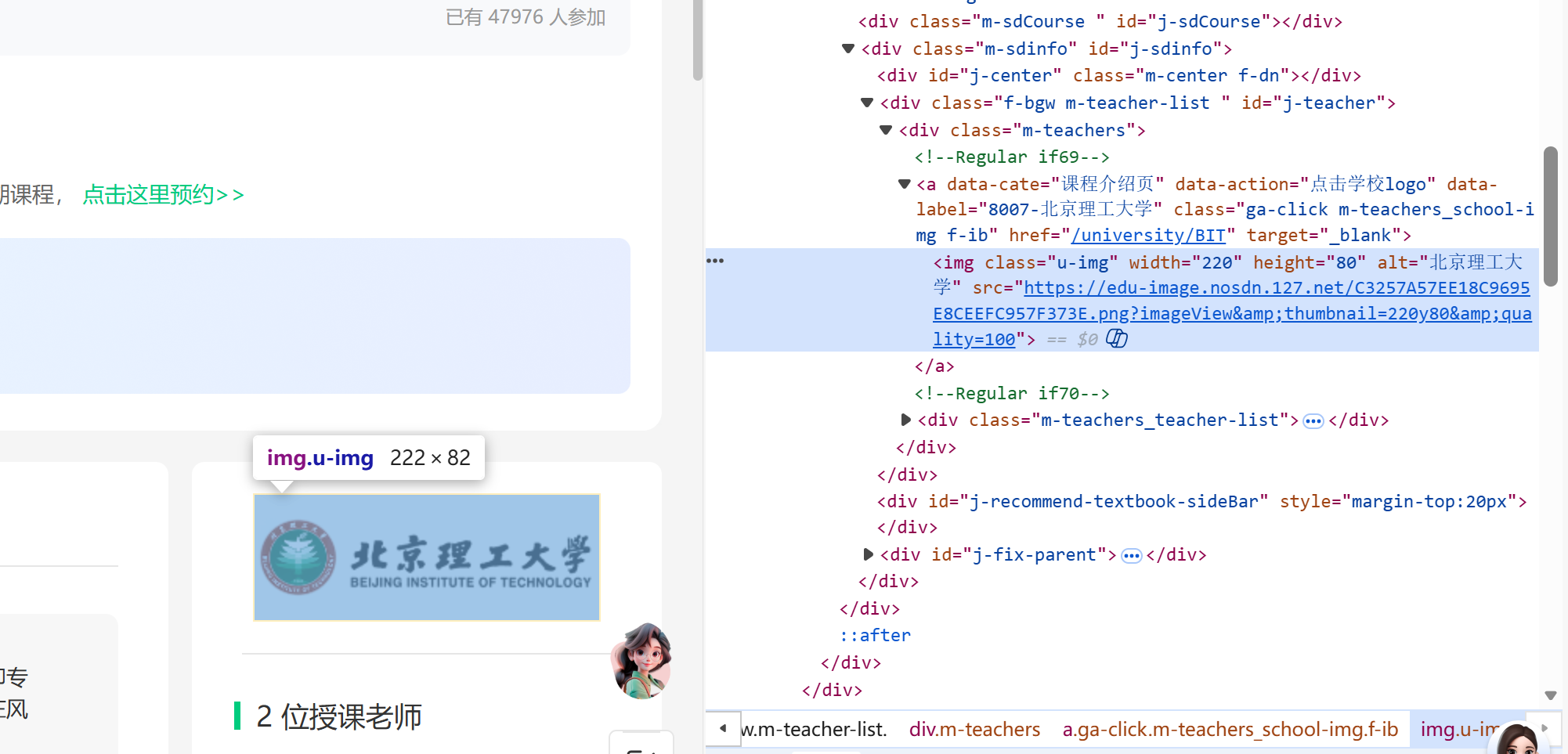
主讲教师、教学团队://[@id="j-teacher"]/div/div/div[2]/div/div/div[1]/div/div/h3
参与人数://[@id="course-enroll-info"]/div/div[1]/div[4]/span[2]
课程进度/时间://[@id="course-enroll-info"]/div/div[1]/div[2]/div/span[2]
课程简介://[@id="j-rectxt2"]
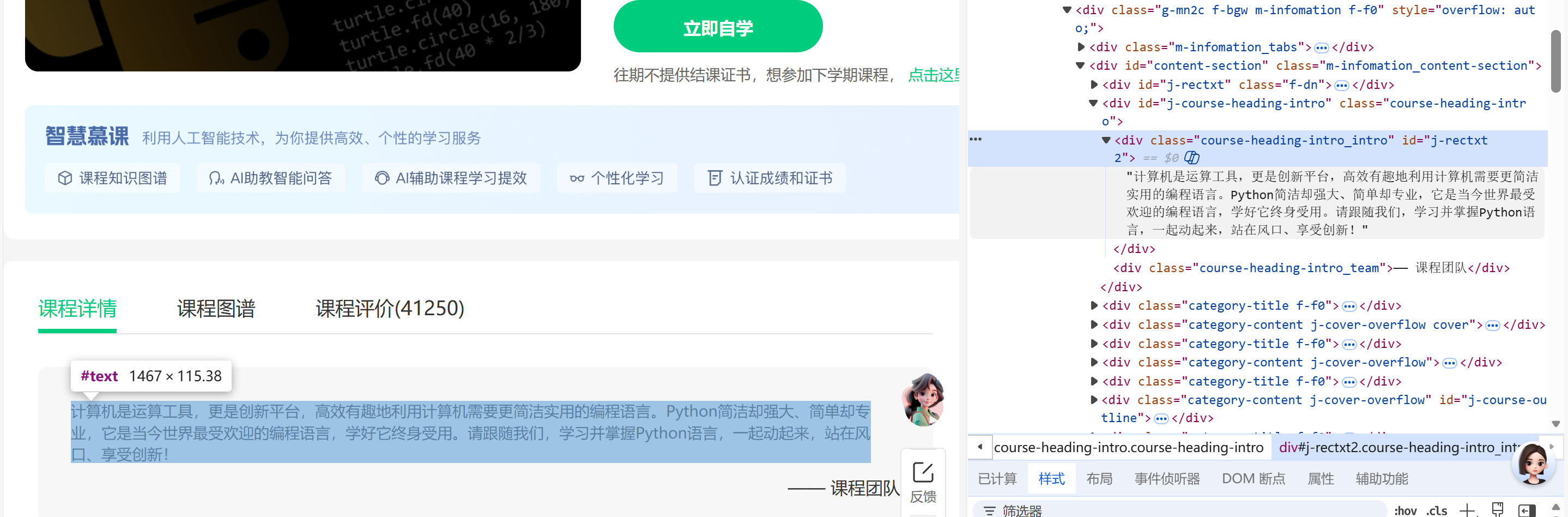
手动登录和页面跳转是核心操作环节,程序启动后会暂停等待,登录完成后跳转至个人课程页,实际开发中发现,若不切换到新打开的课程页面,程序会一直操作主窗口,导致元素定位失败,这让我明白,页面跳转的核心不仅是 “打开 URL”,更是 “切换操作上下文”,确保程序的操作对象与目标页面一致,代码中需要通过window.open打开新窗口、switch_to.window切换窗口、close关闭窗口等操作。
Gitee文件夹链接:https://gitee.com/lizixian66/shujucaiji/blob/homework4/mooc.py
作业3
要求:掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
(1)运行结果
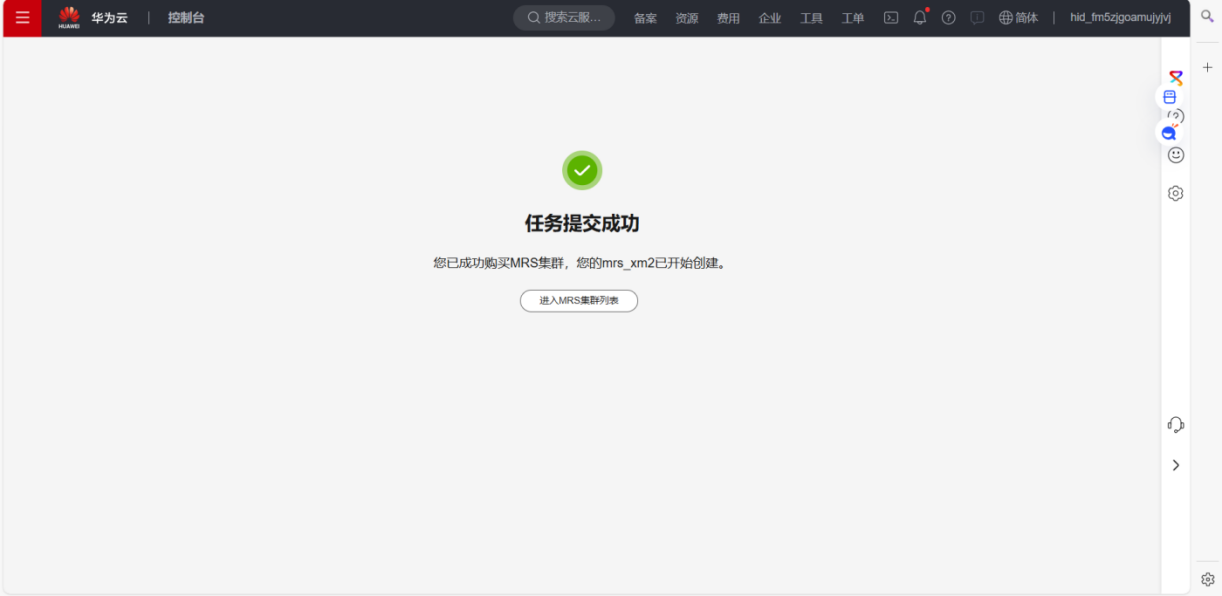
环境搭建:
任务一:开通MapReduce服务
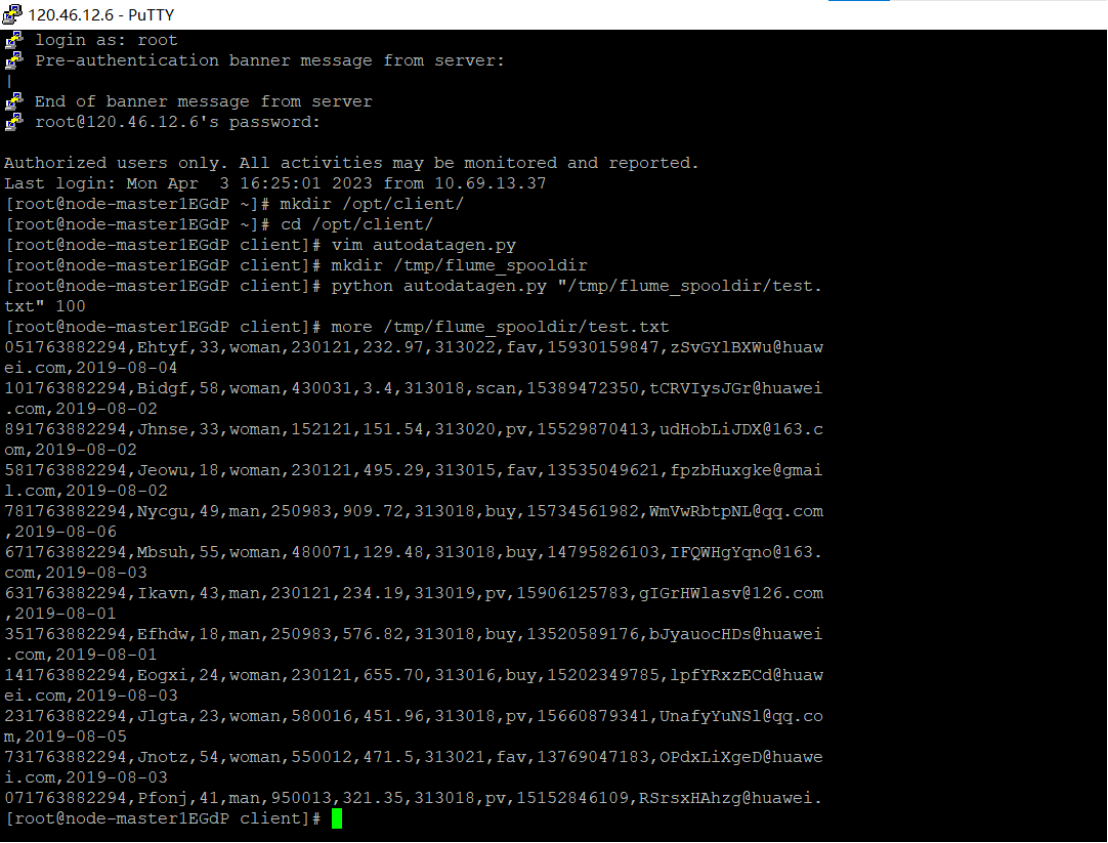
实时分析开发实战:
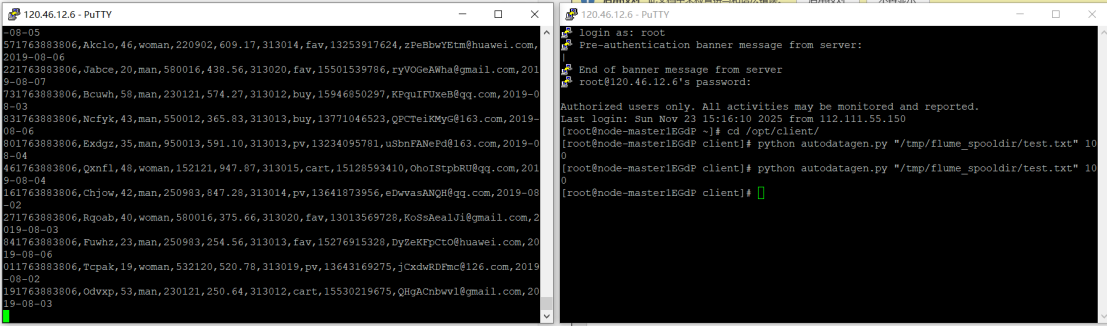
任务一:Python脚本生成测试数据
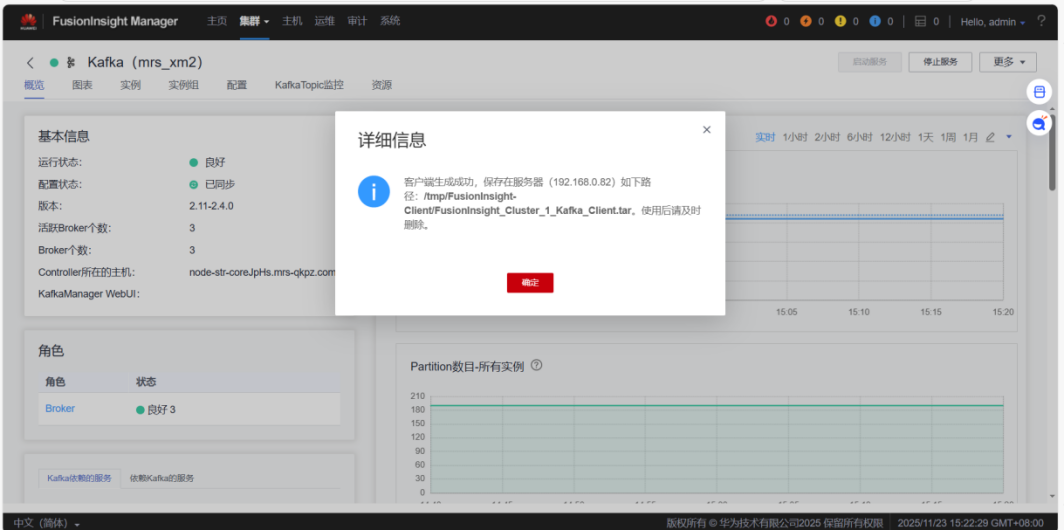
任务二:配置Kafka
1.下载Flume客户端
2.校验下载的客户端文件包
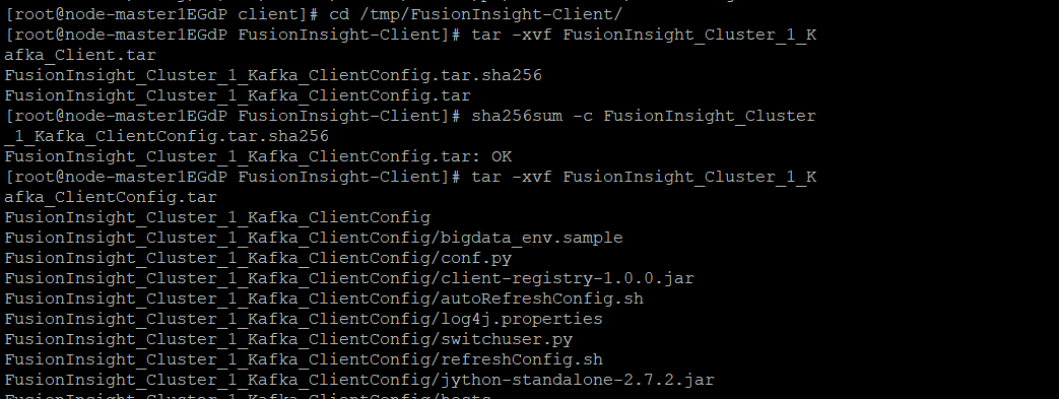
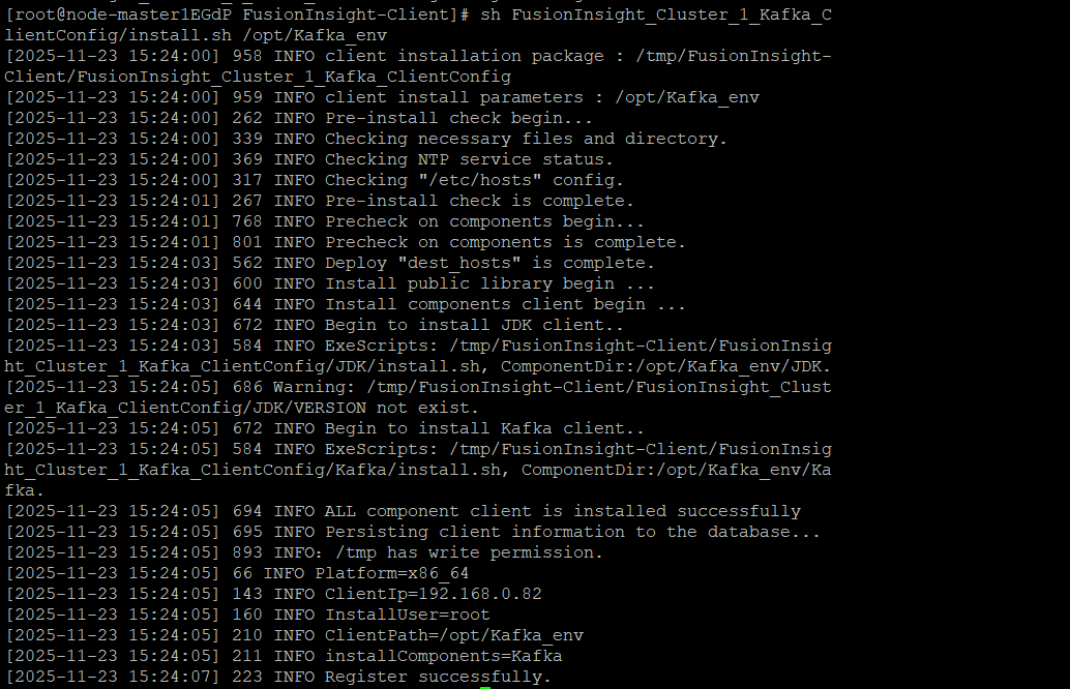
3.安装Kafka客户端
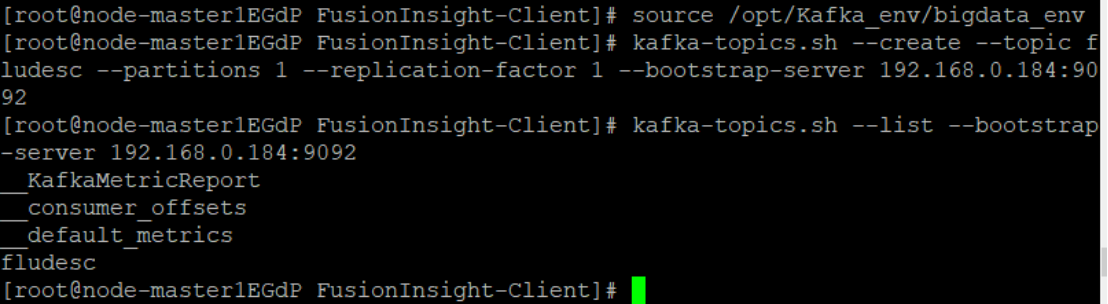
4.在kafka中创建topic
任务三: 安装Flume客户端
1.下载Flume客户端
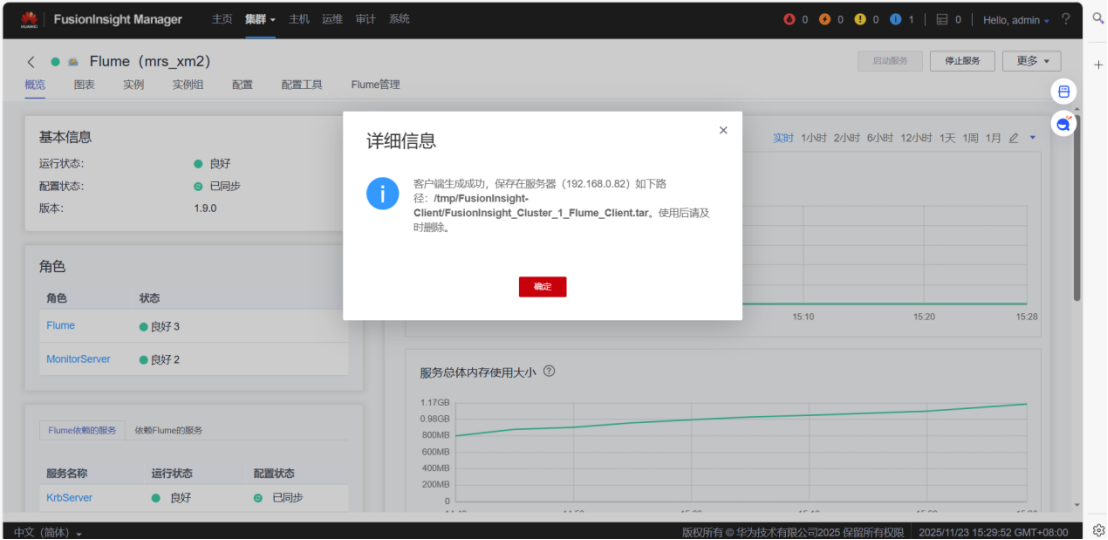
2.校验下载的客户端文件包
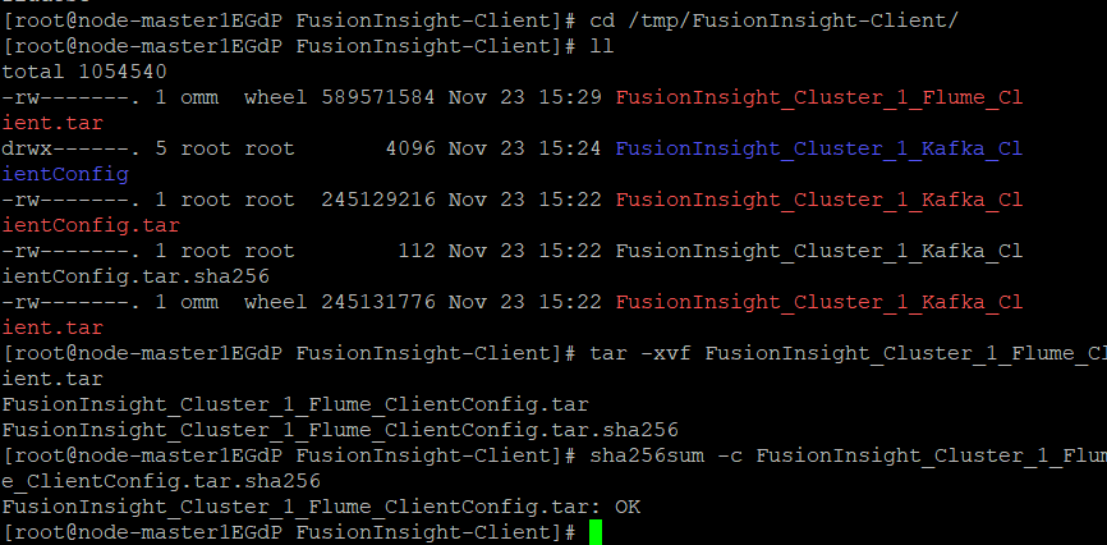
3.安装Flume运行环境
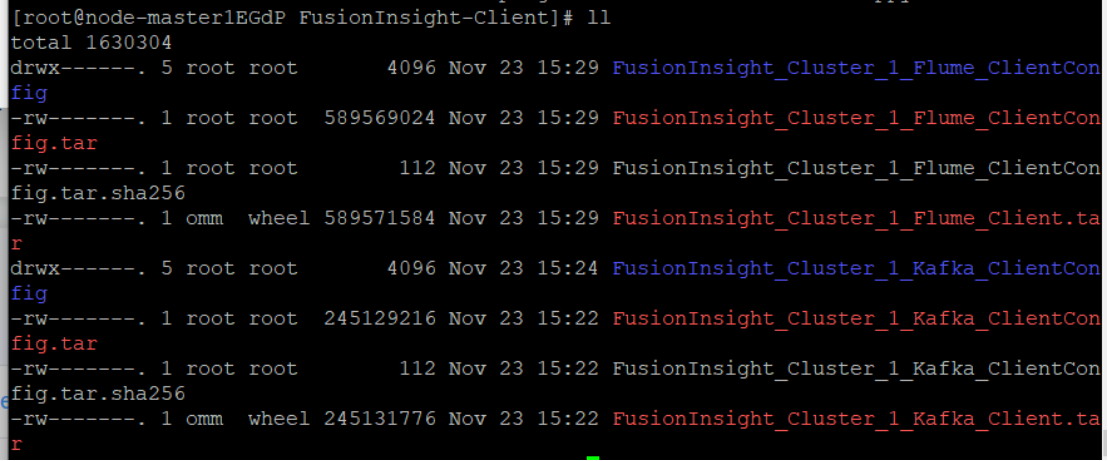
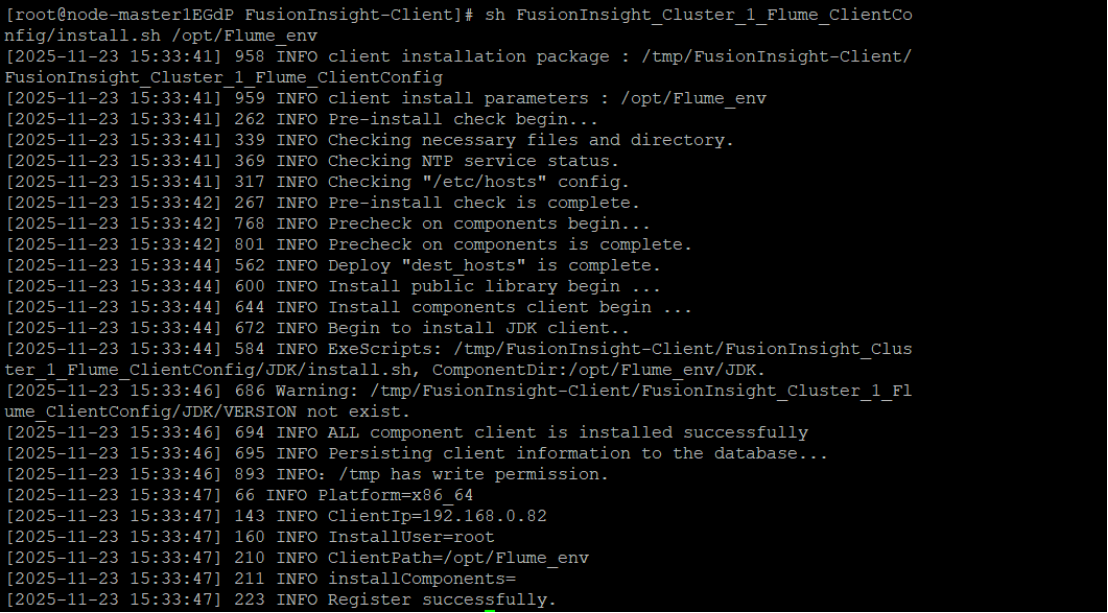
4.安装Flume客户端
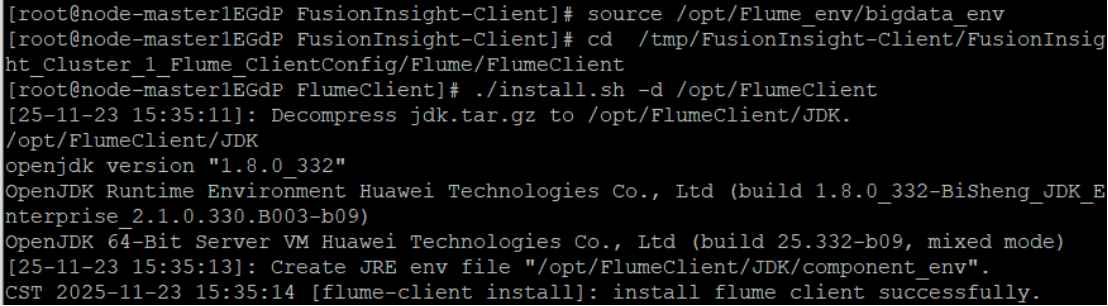
5.重启Flume服务

任务四:配置Flume采集数据
1.修改配置文件
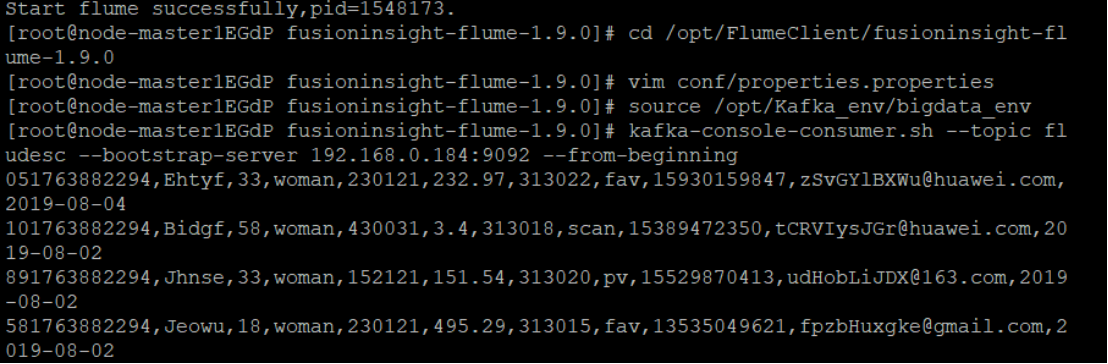
2.创建消费者消费kafka中的数据
(2)心得体会
参与 Flume 日志采集实验,让我对大数据实时数据采集有了实操层面的认知。从华为云 MRS集群搭建,到Python脚本生成测试数据、配置Kafka与Flume客户端,每一步都需要严谨的操作逻辑。这让我深刻体会到大数据配置的严谨性。实验中多窗口协作操作、Linux 命令的灵活运用,也提升了我的实操能力。当看到 Flume 成功将数据采集到 Kafka 并被消费者消费时,我切实理解了 Flume 作为日志采集工具的核心作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号