
102302156 李子贤 数据采集第一次作业
作业1
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
(1)代码和运行结果
点击查看代码
import urllib.request
from bs4 import BeautifulSoup
# 获取目标网页的HTML内容
def get_html(url):
try:
req = urllib.request.Request(url)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
return html
except Exception as e:
print(f"获取网页失败:{e}")
return None
# 解析HTML,提取大学排名数据
def parse_html(html):
if html is None:
return []
# 初始化解析器并获取表格行数据
soup = BeautifulSoup(html, 'html.parser')
rows = soup.select('tr') # 选择所有表格行
rank_data = []
for row in rows:
# 提取排名
rank_elem = row.select_one('div.ranking')
if not rank_elem:
continue
rank_text = rank_elem.text.strip().replace(' ', '')
if not rank_text.isdigit():
continue
# 提取学校名称
name_elem = row.select_one('div.univname')
if not name_elem:
continue
name = name_elem.text.strip().split('\n')[0].strip()
# 提取省市、学校类型、总分(从表格单元格中获取)
tds = row.select('td')
if len(tds) < 5:
continue
province = tds[2].text.strip()
school_type = tds[3].text.strip()
score = tds[4].text.strip()
# 收集数据
rank_data.append([rank_text, name, province, school_type, score])
return rank_data
# 格式化打印排名数据
def print_rank(data):
if not data:
print("没有获取到有效排名数据")
return
# 打印表头
print(f"{'排名':<6}{'学校名称':<20}{'省市':<8}{'学校类型':<10}{'总分'}")
for item in data:
print(f"{item[0]:<6}{item[1]:<20}{item[2]:<8}{item[3]:<10}{item[4]}")
def main():
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
html = get_html(url)
if html:
print("网页获取成功,开始解析...\n")
rank_data = parse_html(html)
print_rank(rank_data)
else:
print("网页获取失败,无法继续")
if __name__ == "__main__":
main()
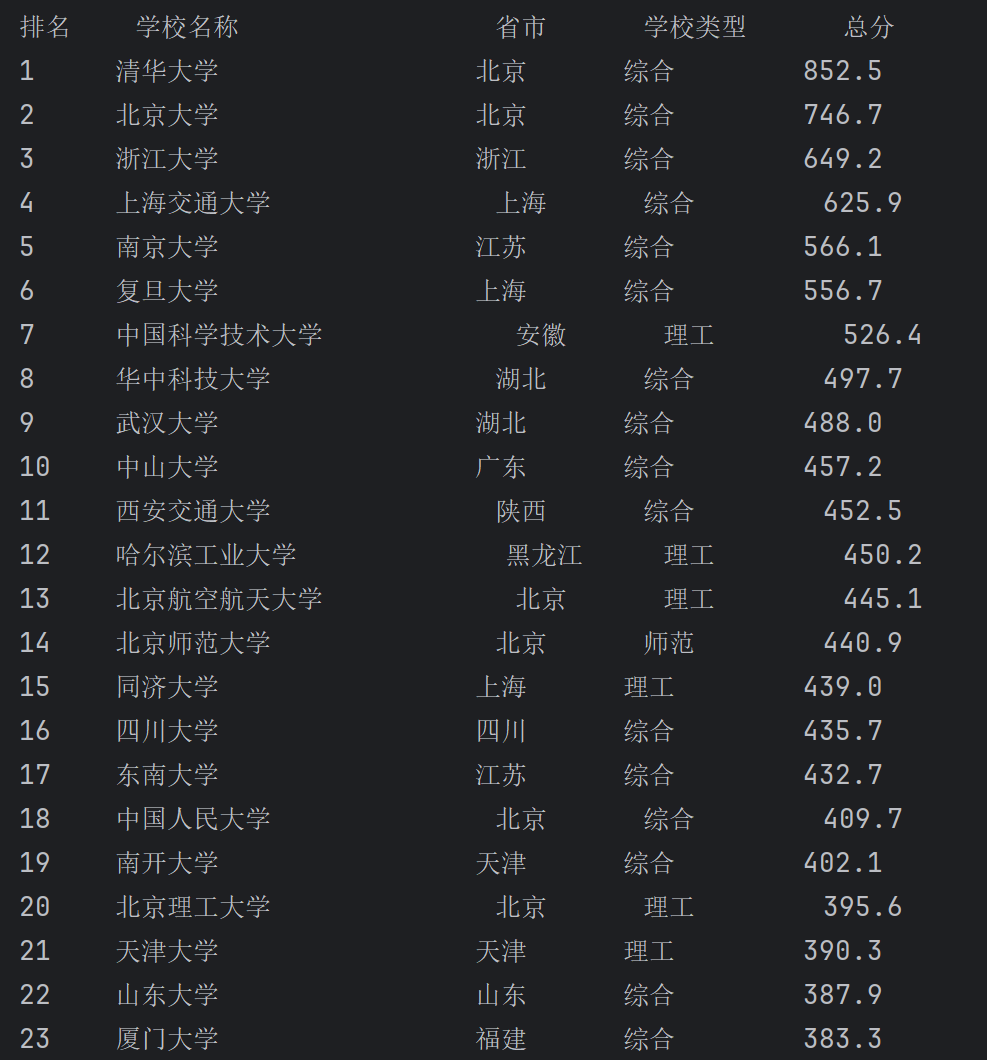
(2)心得体会
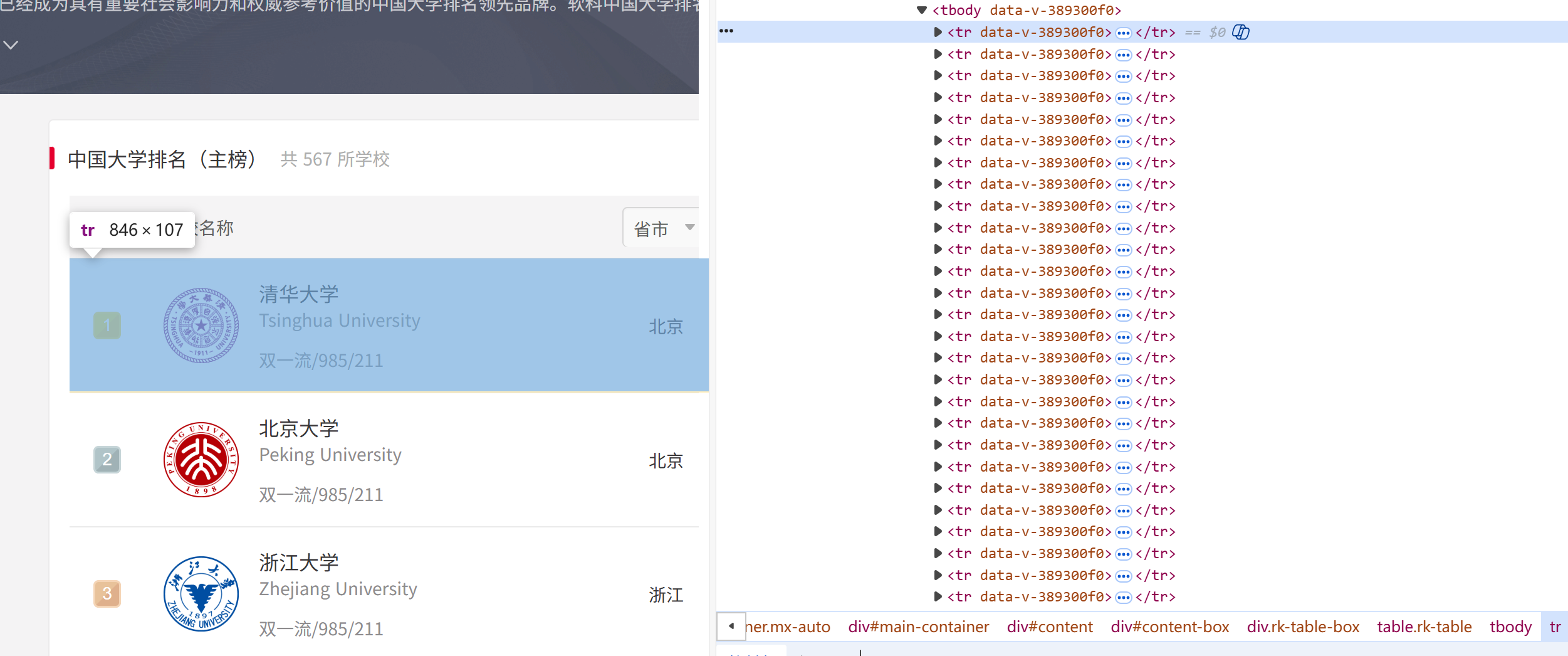
从上图可以看出,我们需要提取的信息包含在表格的tbody中,我们只需要先提取每一个tr行
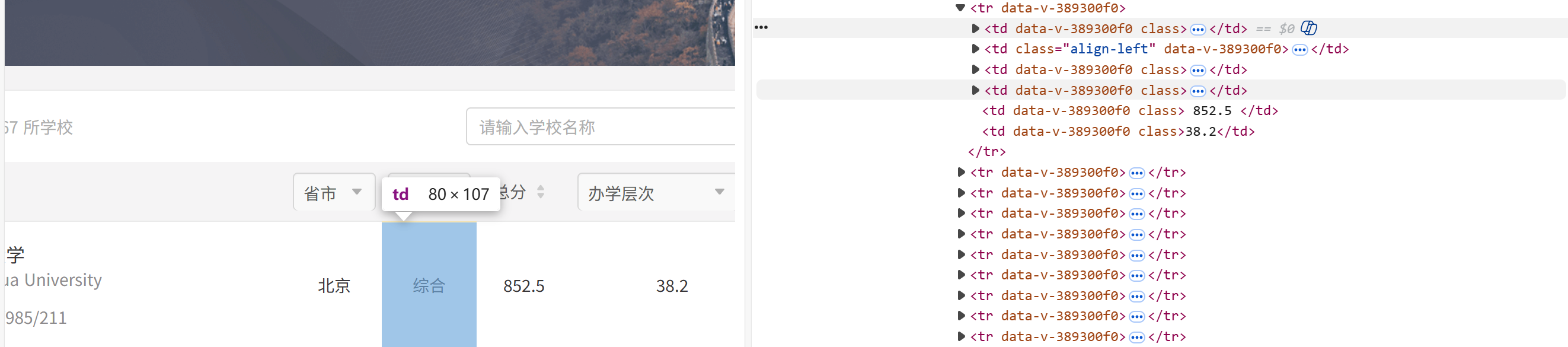
再分别对每一个tr行提取相对应的td标签中的内容,即可得到我们想要的结果。
因此,我们得出爬取一个网页中的信息,必须要先知道我们所要爬取的内容的html结构,对症下药才可以得到我们想要的信息。
作业2
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
(1)代码和运行结果
点击查看代码
import urllib3
import re
def crawl_dangdang_books(keyword, max_items=30):
http = urllib3.PoolManager()
# 设置请求头,模拟浏览器访问
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
}
all_names = []
all_prices = []
url = f"https://search.dangdang.com/?key={keyword}&page=1"
try:
# 发送GET请求,设置超时和重试机制
response = http.request(
'GET',
url,
headers=headers,
timeout=10,
retries=urllib3.Retry(3, backoff_factor=0.5)
)
# 解码网页内容
html = response.data.decode('gbk', errors='ignore')
# 提取商品名称:匹配含class="pic"的a标签中的title属性
name_pattern = re.compile(r'<a\s+.*?class="pic".*?title="(.*?)".*?>',re.DOTALL | re.VERBOSE )
names = name_pattern.findall(html)
valid_names = [n for n in names if n.strip()]
all_names.extend(valid_names[:max_items])
# 提取价格:匹配class="price_n"的span标签中的数值(去除¥符号)
price_pattern = re.compile(r'<span class="price_n">¥(.*?)</span>')
prices = price_pattern.findall(html)
valid_prices = [p for p in prices if p.strip()]
all_prices.extend(valid_prices[:max_items])
# 打印当前页数据提取统计
print(f"第1页:名称{len(valid_names)}个,价格{len(valid_prices)}个,有效匹配{min(len(valid_names), len(valid_prices))}个")
except Exception as e:
print(f"爬取失败:{str(e)}")
# 组合名称和价格为元组列表返回
products = list(zip(all_names, all_prices))
return products
if __name__ == "__main__":
products = crawl_dangdang_books("书包")
# 打印爬取结果
if products:
print(f"\n===== 爬取结果(共{len(products)}项) =====")
for i, (name, price) in enumerate(products, 1):
print(f"{i}. 名称:{name} | 价格:¥{price}")
else:
print("未爬取到有效商品数据")

(2)心得体会
我选择爬取的网站是当当网(https://search.dangdang.com/?key=书包&page=1)
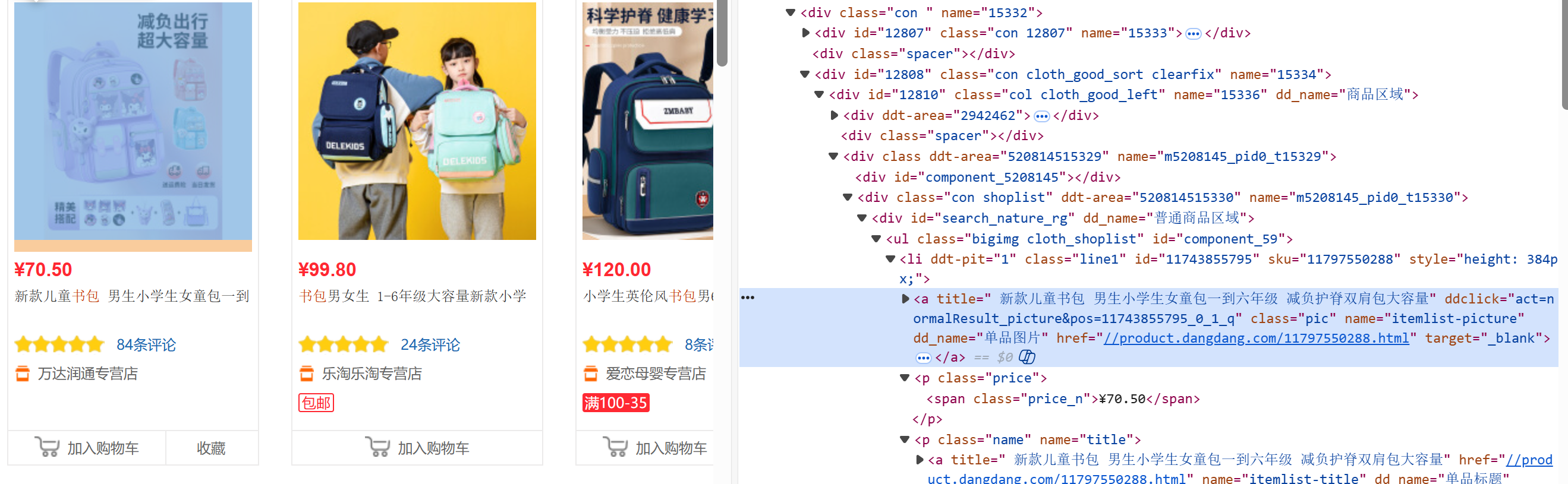
由上图可以得到我们想要爬取的书包名称在class="pic"的a标签中的title属性,使用正确的正则表达式(r'<a\s+.?class="pic".?title="(.?)".?>')即可得到信息,在爬取时我发现如果只使用a标签下的title属性,会匹配到其他的信息,所以我们需要多添加一些约束条件,这样才可以精确的定位到我们想要的信息。
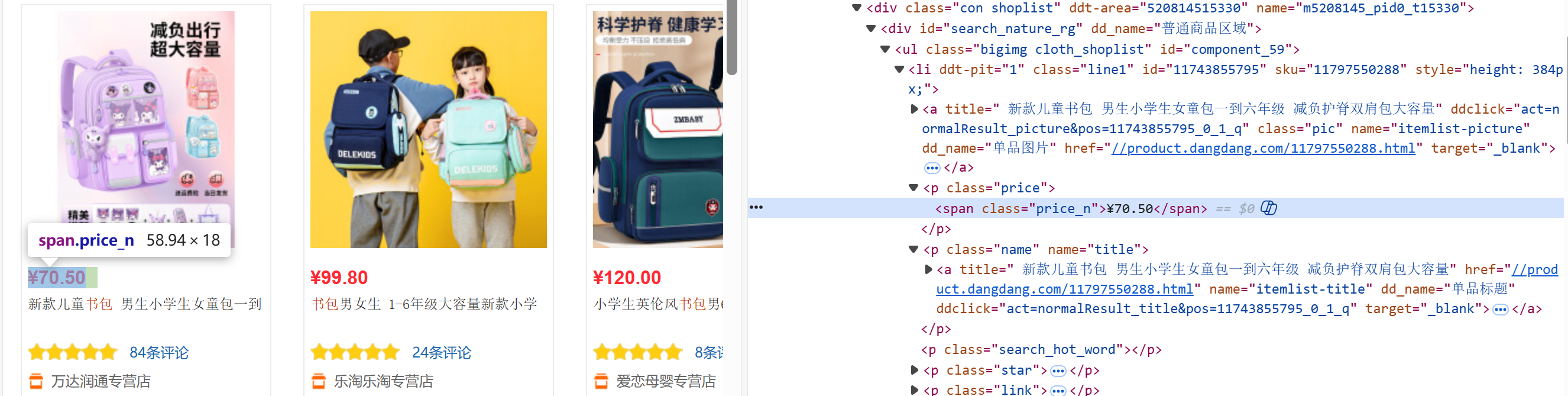
同理,我们查看价格的html标签,他存放在class="price_n"的span标签中,使用正确的正则表达式(r'¥(.*?)')即可得到信息。
作业3
爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
(1)代码和运行结果
点击查看代码
import urllib.request
import re
import os
def main():
# 目标网页 URL
url = "https://news.fzu.edu.cn/info/1012/120223.htm"
# 图片保存目录
save_dir = "fzu_jpg_imgs"
os.makedirs(save_dir, exist_ok=True)
try:
# 请求网页获取内容
req = urllib.request.Request(url)
with urllib.request.urlopen(req) as response:
html = response.read().decode("utf-8")
except Exception as e:
print(f"获取网页内容失败:{e}")
return
# 正则匹配 <img> 标签中 src 属性为 .jpg 的链接
img_pattern = r'<img[^>]*?src=["\'](.*?\.jpg)["\']'
img_urls = re.findall(img_pattern, html)
if not img_urls:
print("未找到 .jpg 格式图片")
return
# 遍历图片链接并下载
for i, img_url in enumerate(img_urls, 1):
# 拼接完整绝对 URL
full_img_url = urllib.parse.urljoin(url, img_url)
# 提取图片文件名
img_name = os.path.basename(full_img_url)
save_path = os.path.join(save_dir, img_name)
try:
# 请求图片
img_req = urllib.request.Request(full_img_url)
with urllib.request.urlopen(img_req) as img_resp:
with open(save_path, "wb") as f:
f.write(img_resp.read())
print(f"[{i}/{len(img_urls)}] 成功下载:{img_name}")
except Exception as e:
print(f"[{i}/{len(img_urls)}] 下载失败 {full_img_url}:{e}")
if __name__ == "__main__":
main()

(2)心得体会
我爬取的图片网站为(https://news.fzu.edu.cn/info/1012/120223.htm)

由html结构我们可以看出,图片的后缀为.jpg格式,所以我们先利用re正则表达式去匹配所有src属性为.jpg的标签,定位到我们想要的图片后,就要进行图片保存的操作
这是 “数据保存” 的核心步骤,针对每张图片做三件事:
1.处理链接:将网页中可能存在的 “相对路径” 转为可直接访问的 “绝对路径”;
2.定义路径:明确本地保存的位置和文件名,避免混乱;
3.下载保存:以二进制模式(图片是二进制文件)写入本地,同时捕获单张图片的下载异常(避免一张失败导致整体中断)。
由此可以得出下载图片的时候要注意路径等问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号