
C语言库函数探究
原文:http://www.cnblogs.com/33debug/p/7355400.html
1、strlen()求字符串长度
1 //模拟实现strlen函数
2 #include<stdio.h>
3 #include<stdlib.h>
4 #include<string.h>
5 #include<assert.h>
6 int my_strlen1(const char* str) //借助临时变量实现
7 {
8 int count = 0;
9 while (*str)
10 {
11 count++;
12 *str++;
13 }
14 return count;
15 }
16 int my_strlen2(char* s)
17 {
18 char* p = s;
19 /*while (*p != '\0')
20 p++;*/
21 while (*p++);
22 return p - s - 1;
23 }
24 int my_strlen3(char* str) //递归法
25 {
26 if (!*str)
27 return 0;
28 else
29 return 1 + my_strlen3(str + 1);
30 }
31 int main()
32 {
33 char src[] = "qwertyuiop";
34 int num1 = my_strlen1(src);
35 int num2 = my_strlen2(src);
36 int num3 = my_strlen3(src);
37 printf("%d\n", num1);
38 printf("%d\n", num2);
39 printf("%d\n", num3);
40 getchar();
41 return 0;
42 }
2、strcpy()字符串拷贝函数
1 char* my_strcopy1(char* dest, const char* str)
2 {
3 assert(dest != NULL);
4 assert(str != NULL);
5 char* ret = dest;
6 while (*dest++ = *str++)
7 {
8 ;
9 }
10 return ret;
11 }
12 char* my_strcopy2(char* dest, const char* str)
13 {
14 assert(dest != NULL);
15 assert(str != NULL);
16 char* ret = dest;
17 while (*str != '\0')
18 {
19 *dest = *str;
20 dest++;
21 str++;
22 }
23 *dest = *str;
24 return ret;
25 }
26 int main()
27 {
28 char str[] = "abcdefg";
29 char dest1[10];
30 char dest2[10];
31 my_strcopy1(dest1, str);
32 my_strcopy2(dest2, str);
33 printf("%s\n", dest1);
34 printf("%s", dest2);
35 getchar();
36 return 0;
37 }
(1)字符数组dest1和dest2必须定义得足够长,以容纳复制进去的字符串;
(2)与其相关的还有strncpy()函数定义拷贝固定长度的字符
1 strncpy(str1, str2);
作用是将str2中前2个字符复制到str1中,取代str1中原有的前两个字符,N应不大于str1原字符长度(不包括‘\0’)。
3、strcmp()字符串比较函数
1 int my_strcmp(const char *str1, const char *str2)
2 {
3 while (*str1 == *str2)
4 {
5 if (*str1 == '\0')
6 return 0;
7 else
8 {
9 str1++;
10 str2++;
11 }
12 }
13 return (*str1 - *str2);
14 }
15 int main()
16 {
17
18 printf("%d\n", my_strcmp("awc", "aaaa")); //输出大于0的数
19 printf("%d\n", my_strcmp("ac", "aw")); //输出小于于0的数
20 printf("%d\n", my_strcmp("awc", "awc")); //输出0
21 printf("%d\n", strcmp("awc", "aaaa")); //输出1
22 printf("%d\n", strcmp("ac", "aw")); //输出-1
23 printf("%d\n", strcmp("awc", "awc")); //输出0
24 getchar();
25 return 0;
26 }
4、strcat()字符串连接函数
1 char *my_strcat(char *dst, const char *str)
2 {
3 char *ret = dst;
4 assert(dst != NULL);
5 assert(str != NULL);
6 while (*dst != '\0')
7 {
8 dst++;
9 }
10 while (*dst++ = *str++)
11 {
12 ;
13 }
14 return ret;
15 }
16 int main()
17 {
18 char arr[20] = "abcdefg";
19 my_strcat(arr, "hit");
20 printf("%s\n", arr);
21 getchar();
22 return 0;
23 }
5、strstr()找子串(模式匹配)
原型可以写成:char *my_strstr(const char *str, const char *substr)
char substr = "ababa";



代码如下:
1 char *my_strstr(const char *str, const char *substr)
2 {
3 const char *str1 = NULL;
4 const char *str2 = NULL;
5 const char *start = str;
6 assert(str);
7 assert(substr);
8 if (*substr == NULL)
9 {
10 return (char *)str;
11 }
12 while (*start)
13 {
14 str1 = start;
15 str2 = substr;
16 while ((*str1) && (*str2) && (*str1 == *str2))
17 {
18 str1++;
19 str2++;
20 }
21 if (*str2 == '\0')
22 {
23 return (char *)start;
24 }
25 start++;
26 }
27 return NULL;
28 }
29 int main()
30 {
31 char str1[] = "ababcababa";
32 char str2[] = "ababa";
33 char *ret = my_strstr(str1, str2);
34 if (ret != NULL)
35 printf("%s\n", ret);
36 else
37 printf("not exit!\n");
38 getchar();
39 return 0;
40 }
(2)介绍另外一种方法,KMP算法

这时,按第一种方法是,将目标串整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"查找位置"移到已经比较过的位置,重比一遍。一个基本事实是,当 i=4,j=4 c与a不匹配时,你其实知道前面四个字符是"abab"。KMP算法的想法是,设法利用这个已知信息,不要把"查找位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。

我们可以针对搜索词,算出一张《部分匹配表》如上表。这张表是如何产生的,后面会介绍,这里先看它的用法。

已知c与a不匹配时,前面四个字符"abab"是匹配的。查表可知,最后一个匹配字符b对应的"部分匹配值"为0,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
4 - 0 等于4,所以将搜索词向后移动4位。

因为a与c不匹配,搜索词还要继续往后移。这时,已匹配的字符数为0,对应的"部分匹配值"为0。所以后移一位

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果目标字符串后面还有,还要继续搜索的话(即找出全部匹配),移动位数 = 5 - 3,再将搜索词向后移动2位,这里就不再重复了。
下面介绍部分匹配值的算法:

"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ababa"为例:
- "a"的前缀和后缀都为空集,共有元素的长度为0;
- "ab"的前缀为[a],后缀为[b],共有元素的长度为0;
- "aba"的前缀为[a, ab],后缀为[ba, a],共有元素的长度1;
- "abab"的前缀为[a, ab, aba],后缀为[bab, ab, b],共有元素的长度为2;
- "ababa"的前缀为[a, ab, aba, abab],后缀为[baba, aba, ba, a],共有元素为"aba",长度为3;
next数组的求解思路(即部分匹配值)
通过上文完全可以对kmp算法的原理有个清晰的了解,那么下一步就是编程实现了,其中最重要的就是如何根据待匹配的模版字符串求出对应每一位的最大相同前后缀的长度。
1 void makeNext(const char* str,int next[])
2 {
3 int num,max;//q:模版字符串下标;k:最大前后缀长度
4 int len = strlen(str);//模版字符串长度
5 next[0] = 0;//模版字符串的第一个字符的最大前后缀长度为0
6 for (num = 1,max = 0; num < len; ++num)//for循环,从第二个字符开始,依次计算每一个字符对应的next值
7 {
8 while(max > 0 && str[num] != str[max])//递归的求出P[0]···P[q]的最大的相同的前后缀长度k
9 max = next[max - 1];
10 if (str[num] == str[max])//如果相等,那么最大相同前后缀长度加1
11 {
12 max++;
13 }
14 next[num] = max;
15 }
16 }
1 int kmp(const char T[],const char P[],int next[])
2 {
3 int n,m;
4 int i,q;
5 n = strlen(T);
6 m = strlen(P);
7 makeNext(P,next);
8 for (i = 0,q = 0; i < n; ++i)
9 {
10 while(q > 0 && P[q] != T[i])
11 q = next[q-1];
12 if (P[q] == T[i])
13 {
14 q++;
15 }
16 if (q == m)
17 {
18 printf("Pattern occurs with shift:%d\n",(i-m+1));
19 }
20 }
21 }
22
23 int main()
24 {
25 int i;
26 int next[20]={0};
27 char T[] = "ababxbababcadfdsss";
28 char P[] = "abcdabd";
29 printf("%s\n",T);
30 printf("%s\n",P );
31 // makeNext(P,next);
32 kmp(T,P,next);
33 for (i = 0; i < strlen(P); ++i)
34 {
35 printf("%d ",next[i]);
36 }
37 printf("\n");
38
39 return 0;
40 }
KMP算法的时间复杂度为O(m+n);空间复杂度为O(n)。
6、strlwr将字符串中的字符转换为小写
原型为:char *strlwr(char *str);
参数说明:str为要转换的字符串。
返回值:返回转换后的小写字符串,其实就是将str返回。
strlwr() 不会创建一个新字符串返回,而是改变原有字符串。所以strlwr()只能操作字符数组,而不能操作指针字符串,因为指针指向的字符串是作为常量保存在静态存储区的,常量不能被修改
注意:strlwr()和不是标准库函数,只能在windows下(VC、MinGW等)使用,Linux GCC中需要自己定义。
1 char* my_strlwr(char *str)
2 {
3 assert(str);
4 char* start = str;
5 while (*start)
6 {
7 if (*start >= 'A' && *start <= 'Z')
8 *start += 32;
9 start++;
10 }
11 return str;
12 }
13 char* my_strupr(char *str)
14 {
15 assert(str);
16 char* start = str;
17 while (*start)
18 {
19 if (*start >= 'a' && *start <= 'z')
20 *start -= 32;
21 start++;
22 }
23 return str;
24 }
25 int main()
26 {
27 char str1[] = { "ABCDCFbbbdgeJhssW" };
28
29 printf("%s\n", my_strlwr(str1)); //调用该函数,并且输出新的字符串
30 printf("%s\n", my_strupr(str1)); //调用该函数,并且输出新的字符串
31 getchar();
32 return 0;
33 }
7、memcpy内存拷贝函数
函数原型:void *memcpy(void *dest, const void *src, size_t n);
功能:从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中。
返回值:函数返回指向dest的指针。
说明:1.source和destin所指的内存区域可能重叠,但是如果source和destin所指的内存区域重叠,那么这个函数并不能够确保source所在重叠区域在拷贝之前不被覆盖。而使用memmove可以用来处理重叠区域。函数返回指向destin的指针。
1 void *my_memcpy(void *dest, const void *str, int sz)
2 {
3 int i = 0;
4 char *pdest = (char *)dest;
5 char *pstr = (char *)str;
6 assert(dest);
7 assert(str);
8 for (i = 0; i < sz; i++)
9 {
10 *pdest = *pstr;
11 pdest++;
12 pstr++;
13 }
14 return dest;
15 }
16 int main()
17 {
18 int i = 0;
19 int arr1[10] = { 1, 2, 3, 4, 5, 6, 7, 8 };
20 int arr2[20];
21 my_memcpy(arr2,arr1,5*sizeof(int));
22 for (i = 0; i < sizeof(arr2) / sizeof(arr2[0]); i++)
23 {
24 printf("%d\n", arr2[i]);
25 }
26 getchar();
27 return 0;
28 }
8、memmove内存拷贝函数
函数原型:void *memmove(void *dest, const void *src, size_t n);
描述:memmove() 函数从src内存中拷贝n个字节到dest内存区域,但是源和目的的内存可以重叠。
返回值:memmove函数返回一个指向dest的指针。
它和memcpy唯一区别就是在对待重叠区域的时候,memmove可以正确的完成对应的拷贝,而memcpy不能。
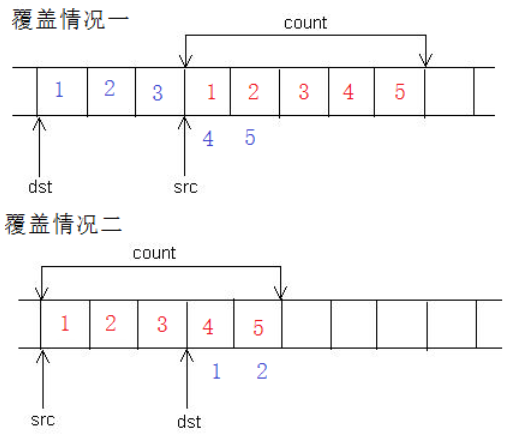
1 #include<stdio.h>
2 #include<string.h>
3 #include<assert.h>
4 void *my_memmove(void *dest, const void *str, int count)
5 {
6 char *pdest = (char *)dest;
7 const char *pstr = (char *)str;
8 assert(pdest);
9 assert(pstr);
10 if (pdest > pstr)
11 {
12 while (count--)
13 {
14 *(pdest + count) = *(pstr + count);
15 }
16 }
17 else
18 {
19 while (count--)
20 {
21 *pdest = *pstr;
22 pdest++;
23 pstr++;
24 }
25 }
26 return dest;
27 }
28
29 int main()
30 {
31 int i = 0;
32 int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
33 my_memmove(arr + 1, arr + 3, 4 * sizeof(int));
34 for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
35 {
36 printf("%d\n", arr[i]);
37 }
38 getchar();
39 return 0;
40 }
赐教!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号