
阿里云mse无损上下线问题复盘
1.现象
- 2025/03/11 14:34:57 秒,iot-device-cloud-storage 调用 iot-cloud-storage-center 报错如图
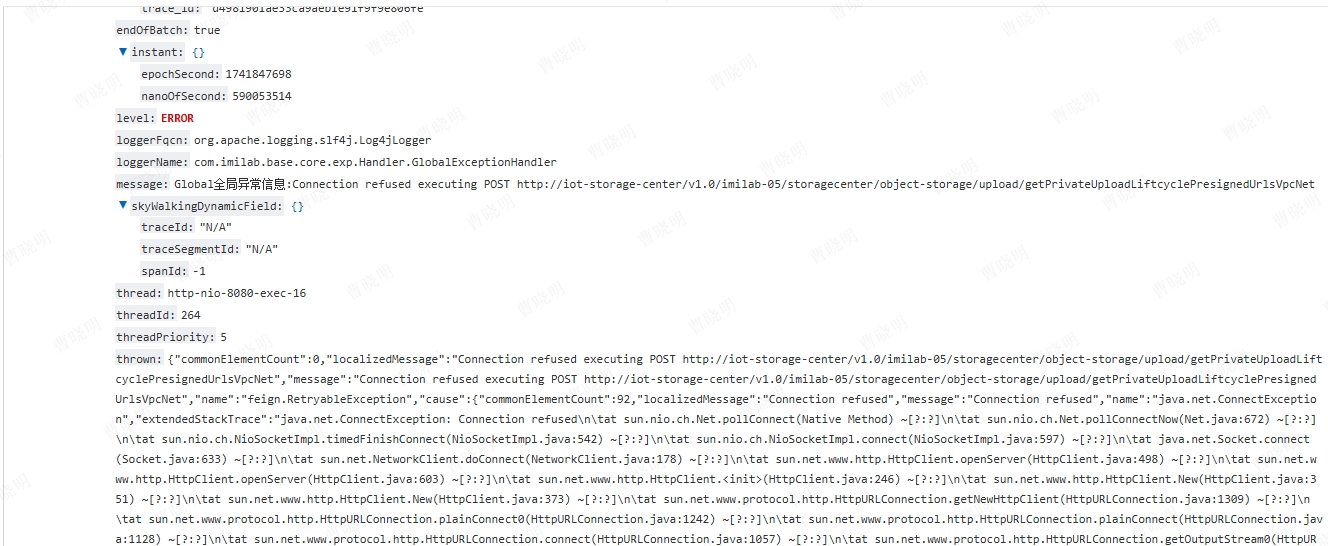
- 2025/03/28 18:56:34 iot-user 服务滚动发布,iot-message-center 调用 iot-user 报错如图
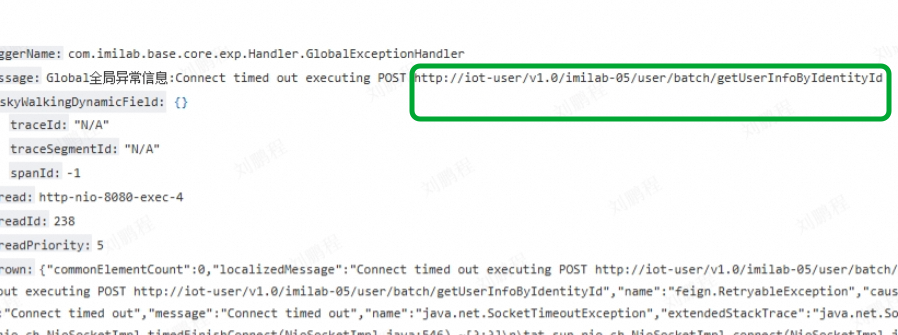
2.原因
- 无损上线,服务上线没有通知机制,依靠客户端主动刷新缓存(spring.cloud.loadbalancer.cache.ttl 默认 35s)。
- 无损下线,服务下线时有主动通知机制,下线时会直接通知客户端下线的节点。
- 当存活节点只有单节点时,在无损下线所有节点都完成主动通知完成中间,新上线的节点还未通过主动刷新被客户端获取到时,会导致客户端的 provider 列表为空,即无服务可用。openfeign 的兜底策略,会直接使用服务名去进行网络请求(使用 RetryableFeignBlockingLoadBalancerClient 客户端进行调用,引入 spring-retry 后的默认客户端),也就是上图中看到的 http://iot-user 、http://iot-cloud-storage-center,恰巧 k8s 中每个应用都创建了与之同名的 svc 域名,所以报错连接拒绝,而不是 503,预期结果:如果服务不用,报错 503。
3.分析
这个问题的本质是,服务优雅上线,没有主动通知机制,但无损下线有主动通知机制,使用单副本部署的服务,大概率会出现无服务可用的情况。
- 服务上线,不做主动通知(合理)
- 服务下线,主动通知(合理)
- 单副本部署服务(不合理)
4.改进
- Java 服务引入 spring-retry 依赖(检查一下,多数服务之前就已经引入了),运维统一修改 server.port ( deployment 和 svc )端口为 80 (原为 8080),当 nacos 出现服务不可用,只要 pod 仍可用,可借助RetryableFeignBlockingLoadBalancerClient的兜底逻辑,直接通过 k8s svc 域名进行服务内部调用。
- 生产环境,严禁单副本部署,且必须保证低峰期所有 pod 承接流量的那部分负载,平均负载要 ≤ (n - 1) / n * 100 %。理论公式,部分环境差异自行判断。
○ 新服务上线,consumer 还未刷新获取到新上线节点的实例信息,下线节点的流量都转发给剩余未下线的老节点的服务进行承压。
○ 打个比方,当前有两个节点,负载为 50%,无损上下线期间,会出现只有一个节点可用的情况,此时下线节点的流量会转到唯一的节点上,如果剩下的唯一节点,没能力承接这部分流量,就会出现节点宕机。
- 如果及特殊情况,单副本部署,需要降低 spring.cloud.loadbalancer.cache.ttl 默认值(默认35s)加快 consumer 缓存刷新频率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号