

Python常见字符编码间的转换
1. 前言
Python2.x和Python3.x在字符编码的设置上也有很大区别(Python3未来将是主流,所以Python3为主),今天我们就来一起学习下。
上一篇文章里已经简述了Python的常见编码了,这里就不再赘述了,还不清楚的可以先去看下: https://www.cnblogs.com/lizexiong/p/14531204.html
2. Unicode 和 UTF-8的爱恨纠葛
Unicode 起到了2个作用:
- 直接支持全球所有语言,每个国家都可以不用再使用自己之前的旧编码了,用unicode就可以了。(就跟英语是全球统一语言一样)
- unicode包含了跟全球所有国家编码的映射关系。
Unicode解决了字符和二进制的对应关系,但是使用unicode表示一个字符,太浪费空间。
例如:利用unicode表示"Python"需要12个字节才能表示,比原来ASCII表示增加了1倍。
由于计算机的内存比较大,并且字符串在内容中表示时也不会特别大,所以内容可以使用unicode来处理,但是存储和网络传输时一般数据都会非常多,那么增加1倍将是无法容忍的!!!
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间!
UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚语系占3个,其它及特殊字符占4个。
UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
UTF-32: 使用4个字节表示所有字符。
总结:UTF 是为unicode编码 设计 的一种在存储和传输时节省空间的编码方案。
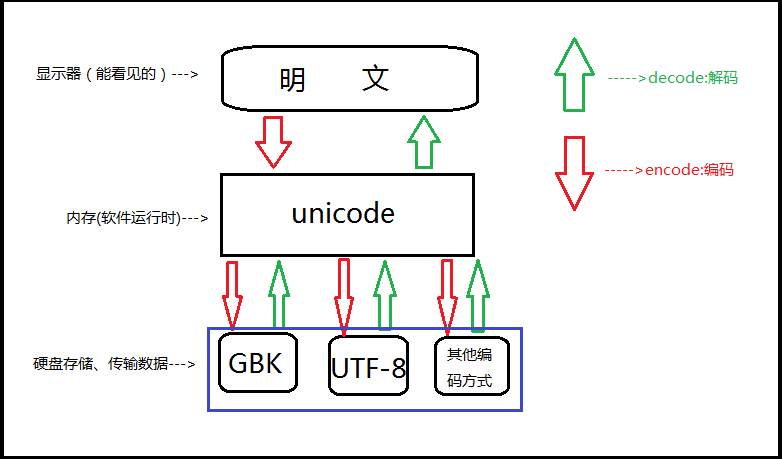
3. 字符在硬盘上的存储
首先要明确的一点就是,无论以什么编码在内存里显示字符,存到硬盘上都是2进制(0b是说明这段数字是二进制,0x表示是16进制。0x几乎所有的编译器都支持,而支持0b的并不多)。理解这一点很重要。
ascii编码(美国):
l 0b1101100
o 0b1101111
v 0b1110110
e 0b1100101
GBK编码(中国):
老 0b11000000 0b11001111
男 0b11000100 0b11010000
孩 0b10111010 0b10100010
还要注意的一点是:存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读(开头声明或转换),要不然就乱了。
4. 编码的转换
虽然有了unicode and utf-8 ,但是由于历史问题,各个国家依然在大量使用自己的编码,
比如中国的windows,默认编码依然是gbk,而不是utf-8。
基于此,如果中国的软件出口到美国,在美国人的电脑上就会显示乱码,因为他们没有gbk编码。
所以该怎么办呢?
还记得我们讲unicode其中一个功能是其包含了跟全球所有国家编码的映射关系,这时就派上用场了。无论你以什么编码存储的数据,只要你的软件在把数据从硬盘读到内存里,转成unicode来显示,就可以了。由于所有的系统、编程语言都默认支持unicode,那你的gbk软件放到美国电脑上,加载到内存里,变成了unicode,
中文就可以正常展示啦。
Python3执行过程
解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode把代码字符串按照语法规则进行解释所有的变量字符都会以unicode编码声明
在py3上 把你的代码以utf-8编写, 保存,然后在windows上执行。
发现可以正常执行!
其实utf-8编码之所以能在windows gbk的终端下显示正常,是因为到了内存里python解释器把utf-8转成了unicode,但是这只是python3, 并不是所有的编程语言在内存里默认编码都是unicode,比如 万恶的python2 就不是,它是ASCII(龟叔当初设计Python时的一点缺陷),想写中文,就必须声明文件头的coding为gbk or utf-8, 声明之后,python2解释器
仅以文件头声明的编码去解释你的代码,加载到内存后,并不会主动帮你转为unicode,也就是说,你的文件编码是utf-8,加载到内存里,你的变量字符串就也是utf-8, 这意味着什么?意味着,你以utf-8编码的文件,在windows是乱码。
其实乱是正常的,不乱才不正常,因为只有2种情况 ,你的windows上显示才不会乱。
- Python2执行过程
Python2并不会自动把文件的编码转为Unicode存在内存中。
- 字符串以GBK格式显示
- 字符串是unicode编码
所以我们只有手动转,Python3 自动把文件编码转为unicode必定是调用了什么方法,这个方法就是,decode(解码)和encode(编码)
例如:
#!/usr/bin/env python3 #-*- coding:utf-8 -*- # write by congcong s = '匆匆' print(s) s1 = s.decode("utf-8") # utf-8 转成 Unicode,decode(解码)需要注明当前编码格式 print(s1,type(s1)) s2 = s1.encode("gbk") # unicode 转成 gbk,encode(编码)需要注明生成的编码格式 print(s2,type(s2)) s3 = s1.encode("utf-8") # unicode 转成 utf-8,encode(编码)注明生成的编码格式 print(s3,type(s3))
文件在Python2和Python3环境下运行结果的区别,如下所示:
#coding:utf-8 s = "你好,中国!" print(s) # Python2输出乱码,Python3正常输出 print(type(s)) # 均输出 <type 'str'> #解码成unicode s1 = s.decode("utf-8") print(s1) # Python2中输出 “你好,中国!”,Python3显示'str'对象没有属性'decode' print(type(s1)) # Python2中输出 <type 'unicode'> Python3中输出 <class 'str'> #编码成gbk 或 utf-8 s2 = s1.encode('gbk') print(s2) # Python2中输出 “你好,中国!” print(type(s2)) # Python2中输出 <type 'str'> s3 = s1.encode('utf-8') print(s3) # Python2输出乱码, print(type(s3)) # 输出 <type 'str'>
编码相互转换的规则如下:
5. 如何验证编码转对了呢?
- 查看数据类型,python 2 里有专门的unicode 类型
- 查看unicode编码映射表
unicode字符是有专门的unicode类型来判断的,但是utf-8,gbk编码的字符都是str,你如果分辨出来的当前的字符串数据是何种编码的呢?
有人说可以通过字节长度判断,因为utf-8一个中文占3字节,gbk一个占2字节。
看输出的字节个数,也能大体判断是什么类型。精确的验证一个字符的编码呢,就是拿这些16进制的数跟编码表里去匹配。
关于 Unicode 与 GBK 等编码对应关系(以中文"路"为例):
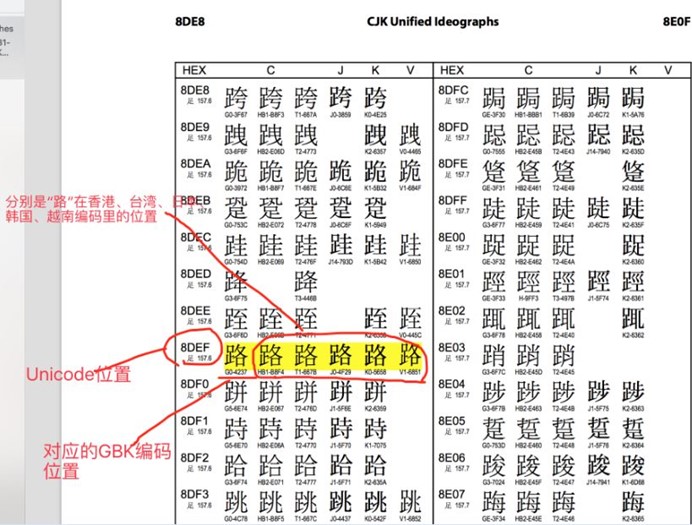
完整的编码对应表可到这个网站下载:unicode与gbk的映射表 http://www.unicode.org/charts/
6. Python bytes类型
把8个二进制一组称为一个byte,用16进制来表示。为的就是让人们看起来更可读。我们称之为bytes类型,即字节类型。
python2的字符串其实更应该称为字节串。 通过存储方式就能看出来, 但python2里还有一个类型是bytes呀,难道又叫bytes又叫字符串?
嗯 ,是的,在python2里,bytes == str , 其实就是一回事。
除此之外呢, python2里还有个单独的类型是unicode , 把字符串解码后,就会变成unicode。
>>> s '\xe8\xb7\xaf\xe9\xa3\x9e' #utf-8 >>> s.decode('utf-8') u'\u8def\u98de' #unicode 在unicode编码表里对应的位置 >>> print(s.decode('utf-8')) 路飞 #unicode 格式的字符
Python2的默认编码是ASCII码,当后来大家对支持汉字、日文、法语等语言的呼声越来越高时,Python于是准备引入unicode,但若直接把默认编码改成unicode的话是不现实的, 因为很多软件就是基于之前的默认编码ASCII开发的,编码一换,那些软件的编码就都乱了。所以Python 2就直接搞了一个新的字符类型,就叫unicode类型,比如你想让你的中文在全球所有电脑上正常显示,在内存里就得把字符串存成unicode类型。
>>> s = "路飞" >>> s '\xe8\xb7\xaf\xe9\xa3\x9e' >>> s2 = s.decode("utf-8") >>> s2 u'\u8def\u98de' >>> type(s2) <type 'unicode'>
注意:
Python3 除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单纯二进制啦。
在py3里看字符,必须得是unicode编码,其它编码一律按bytes格式展示。
Python只要出现各种编码问题,无非是哪里的编码设置出错了
常见编码错误的原因有以下这些:
-
Python解释器的默认编码
-
Python源文件文件编码
-
Terminal使用的编码
-
操作系统的语言设置
总结:
python3
-
文件默认编码是utf-8 , 字符串编码是 unicode
-
以utf-8 或者 gbk等编码的代码,加载到内存,会自动转为unicode正常显示。
python2
-
文件默认编码是ascii , 字符串编码也是 ascii , 如果文件头声明了是gbk,那字符串编码就是gbk。
-
以utf-8 或者 gbk等编码的代码,加载到内存,并不会转为unicode,编码仍然是utf-8或者gbk等编码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号