


集成方法
集成算法
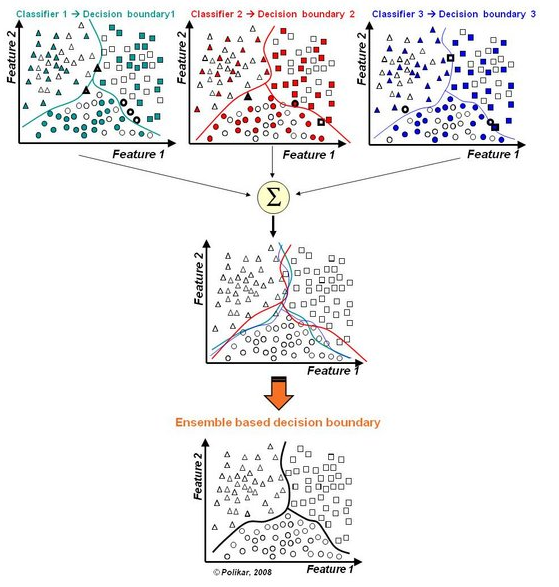
1.是通过聚合多个分类器的预测来提高分类准确率。集成算法由训练数据构建一组基分类器,然后通过每个基分类器的预测进行投票来进行分类。
2.集成分类器的性能优于单个分类器必须满足两个条件:
(1)基分类器必须是相互独立的。
(2)基分类器应当好于随机猜测分类器。
3.构建集成分离器的方法
(1)通过处理训练数据集。
根据某种抽样分布,通过对原始数据进行再抽样来得到多个训练集,然后使用特定的学习算法为每一个训练集建立一个分类器。典型:装袋(Bagging)和提升 (Boosting)。
(2)通过处理输入特征
通过选择输入特征的子集来形成每个训练集,子集可以随机选择,也可以根据领域专家的建议选择。适合含有大量冗余特征的数据集。典型:随机森林。
4.随机森林
**集成学习(ensemble)**思想是为了解决单个模型或者某一组参数的模型所固有的缺陷,从而整合起更多的模型,取长补短,避免局限性。随机森林就是集成学习思想下的产物,将许多棵决策树整合成森林,并合起来用来预测最终结果。
决策树(Decision Tree)与随机森林(Random Forest)
随机森林算法简介:
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 Leo Breiman和Adele Cutler发展出推论出随机森林的算法。而 "Random Forests" 是他们的商标。 这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合Breimans 的 "Bootstrap aggregating" 想法和 Ho 的"randomsubspace method"以建造决策树的集合。
根据下列算法而建造每棵树 :
1. 用M来表示训练用例(样本)的个数,N表示特征数目。
2. 输入特征数目n,用于确定决策树上一个节点的决策结果;其中n应远小于N。
3. 从M个训练用例(样本)中以有放回抽样的方式,取样k次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
4. 对于每一个节点,随机选择n个特征,每棵决策树上每个节点的决定都是基于这些特征确定的。根据这n个特征,计算其最佳的分裂方式。
5. 每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用。
6. 最后测试数据,根据每棵树,以多胜少方式决定分类。
在构建随机森林时,需要做到两个方面:数据的随机性选取,以及待选特征的随机选取,来消除过拟合问题。
首先,从原始的数据集中采取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。第二,利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。最后,如果有了新的数据需要通过随机森林得到分类结果,就可以通过对子决策树的判断结果的投票,得到随机森林的输出结果了。如下图,假设随机森林中有3棵子决策树,2棵子树的分类结果是A类,1棵子树的分类结果是B类,那么随机森林的分类结果就是A类。
与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
优点:
随机森林的既可以用于回归也可以用于分类任务,并且很容易查看模型的输入特征的相对重要性。随机森林算法被认为是一种非常方便且易于使用的算法,因为它是默认的超参数通常会产生一个很好的预测结果。超参数的数量也不是那么多,而且它们所代表的含义直观易懂。
随机森林有足够多的树,分类器就不会产生过度拟合模型。
缺点:
由于使用大量的树会使算法变得很慢,并且无法做到实时预测。一般而言,这些算法训练速度很快,预测十分缓慢。越准确的预测需要越多的树,这将导致模型越慢。在大多数现实世界的应用中,随机森林算法已经足够快,但肯定会遇到实时性要求很高的情况,那就只能首选其他方法。当然,随机森林是一种预测性建模工具,而不是一种描述性工具。也就是说,如果您正在寻找关于数据中关系的描述,那建议首选其他方法。
适用范围:
随机森林算法可被用于很多不同的领域,如银行,股票市场,医药和电子商务。在银行领域,它通常被用来检测那些比普通人更高频率使用银行服务的客户,并及时偿还他们的债务。同时,它也会被用来检测那些想诈骗银行的客户。在金融领域,它可用于预测未来股票的趋势。在医疗保健领域,它可用于识别药品成分的正确组合,分析患者的病史以识别疾病。除此之外,在电子商务领域中,随机森林可以被用来确定客户是否真的喜欢某个产品。
二、sklearn中随机森林算法应用举例:
(1)基本步骤:
①选择数据:将你的数据分成三组:训练数据、验证数据和测试数据
②模型数据:使用训练数据来构建使用相关特征的模型
③验证模型:使用你的验证数据接入你的模型
④测试模型:使用你的测试数据检查被验证的模型的表现
⑤使用模型:使用完全训练好的模型在新数据上做预测
⑥调优模型:使用更多数据、不同的特征或调整过的参数来提升算法的性能表现
————————————————
版权声明:本文为CSDN博主「AI专家」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42039090/article/details/80640890


 浙公网安备 33010602011771号
浙公网安备 33010602011771号