
Python网络爬虫-全国各省新冠疫情数据爬取
一、选题的背景
为什么要选择此选题?要达到的数据分析的预期目标是什么?(10分)从社会、经济、技术、数据来源等方面进行描述(200字以内)
以数据大屏的表现形式,对新型冠状病毒感染的肺炎疫情全国态势进行防控预警与洞察分析。本作品针对2020年的新型冠状病毒感染的肺炎疫情作出数据可视化处理,以全国疫情总态势作为切入点,直观全面的疫情态势的总趋势以及提早进行防控预警洞察分析,分析全国疫情数据,用最直观的表现手段,减少用户的认知负荷,提高决策者的决策效率与精准度。以国内确疫情概况为基本,深入挖掘分析各项数据指标,分析趋势占比,以直观展现疫情多维度的信息和走势,为疫情防控提供高效的信息视图。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称
全国各省疫情数据可视化
2.主题式网络爬虫爬取的内容与数据特征分析
疫情的数据:'https://gwpre.sina.cn/interface/fymap2020_data.json? '
疫情数据是类似接口发送请求后就能获取返回的Json格式的数据。
百度的热搜:’http://top.baidu.com/buzz?b=1&fr=topindex’
百度的热搜数据为网页,需要解析网页结构,才能回去元素里的内容。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
通过requests爬虫爬取疫情数据接口:https://gwpre.sina.cn/interface/fymap2020_data.json?1582011487323全国各个城市的历史数据,将获取的数据通过pandas和json对数据进行处理和简单的保存,并爬取百度的热搜’http://top.baidu.com/buzz?b=1&fr=topindex’查看疫情下的热点问题情况等,对数据进行清洗,处理缺失值、重复值及无效数据,并针对分析目标,可对数据进行适当拆分、合并或剔除等处理,将处理后的数据保存到excel文件,对清洗后的数据,进行可视化分析,探索隐藏在大量数据背后的规律,在绘制柱状图、饼图、词云图和地图。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
网页的结构为一个大div标签中存放全部的div热搜数据的内容
2.Htmls页面解析
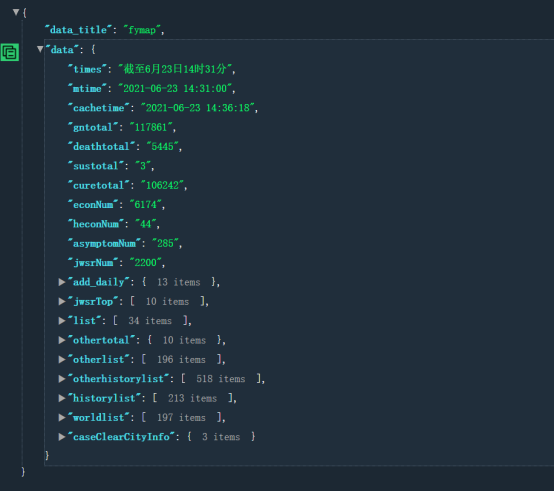

3.(节点(标签)查找方法与遍历方法(必要时画出节点树结构) 疫情数据发送请求后获取的数据如图,本次可视化中用到的数据为list中全国各省份的疫情数据;需要进行数据的整合和清洗获取本次用到的信息,并将信息存入对应的列表中,以便后期的绘图制作。
百度热搜数据为网页,需要利用python的BeautifulSoup库中find_all('a',class_='title_dIF3B'获取当前全部的热搜数据,并进行数据的处理保存
四、网络爬虫程序设计
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
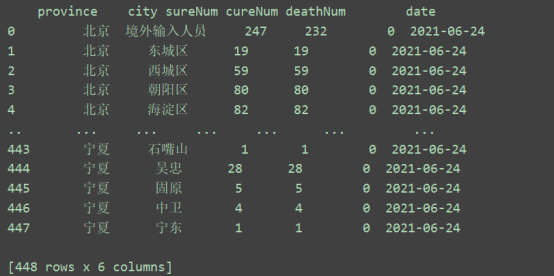
import os from datetime import date import pandas as pd import requests from bs4 import BeautifulSoup from pandas import DataFrame from pyecharts import options as opts from pyecharts.charts import Bar, Pie, Page, Scatter, Boxplot, WordCloud # 数据爬取 from pyecharts.globals import ThemeType def spider(): def get_page(url): # 获取响应头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36' } # 验证是否爬取成果 try: r = requests.get(url, headers=headers) r.raise_for_status() r.encoding = r.apparent_encoding return r.json() except Exception as e: print("Error", e) return "" # 解析html网页代码 def parse_page(data_json): data = data_json['data']['list'] date = data_json['data']['cachetime'].split(' ')[0] all_data = [] for i in data: if len(i['city']) != 0: province = i['name'] for j in i['city']: data_one = {} # 省份 data_one['province'] = province # 城市 data_one['city'] = j['name'] # 确诊人数 data_one['sureNum'] = j['conNum'] # 治愈人数 data_one['cureNum'] = j['cureNum'] # 死亡人数 data_one['deathNum'] = j['deathNum'] # 日期 data_one['date'] = date all_data.append(data_one) else: # 台湾、香港、澳门城市为空,需要单独追加 data_one = {} data_one['province'] = i['name'] data_one['city'] = i['name'] data_one['sureNum'] = i['value'] data_one['deathNum'] = i['deathNum'] data_one['cureNum'] = i['cureNum'] data_one['date'] = date all_data.append(data_one) result = pd.DataFrame(all_data) print(result) return (result) # 保存数据 def save_file(data_df): columns = ['province', 'city', 'sureNum', 'deathNum', 'cureNum', 'date'] if os.path.exists('疫情数据.xlsx'): data_df.to_excel('疫情数据.xlsx', mode='a', columns=columns, encoding='utf-8', header=False, index=False) else: data_df.to_excel('疫情数据.xlsx', columns=columns, encoding='utf-8', index=False) if __name__ == "__main__": url = 'https://gwpre.sina.cn/interface/fymap2020_data.json?1582011487323' data_json = get_page(url) result = parse_page(data_json) if os.path.exists('疫情数据.xlsx'): os.remove('疫情数据.xlsx') save_file(result)
2.数据可视化
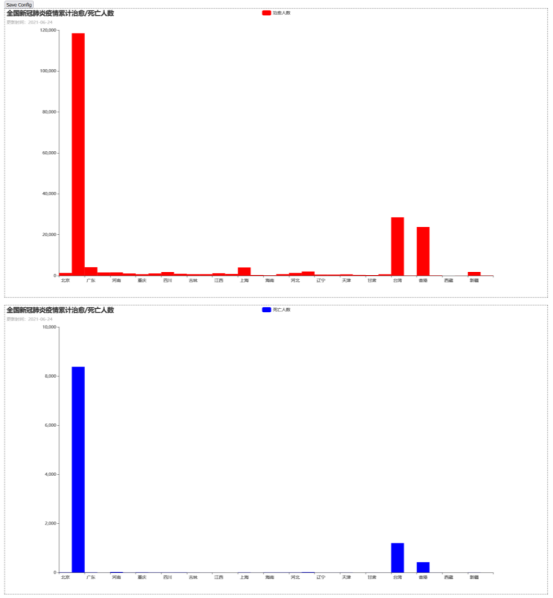
# 绘制柱状图 def bar1_get(): bar = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.PURPLE_PASSION, width="100%", height="800px")) # 设置x轴--疫情治愈地区的列表 .add_xaxis(list(obj_sure.keys())) # 设置y轴--对应疫情地区治愈人数的列表 .add_yaxis("治愈人数", list(obj_sure.values()), category_gap=0, color="red", gap="100%") # 设置柱状图标题 .set_global_opts(title_opts=opts.TitleOpts(title="全国新冠肺炎疫情累计治愈/死亡人数", # 设置柱状图副标题 subtitle="更新时间:{}".format(date.today()), # 设置柱状图标题位置制定 pos_top="top")) # 是否显示y轴的值 .set_series_opts(label_opts=opts.LabelOpts(is_show=False), ) ) return bar def cloud_get(): url = "https://top.baidu.com/board?tab=realtime" list_title = [] list_num = [] # 请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Mobile Safari/537.36' } # 发送请求 resp = requests.get(url, headers=headers) html = resp.content soup = BeautifulSoup(html, 'html.parser') hot_title = soup.find_all('span', class_="one-line-ellipsis _38vEKmzrdqNxu0Z5xPExcg") hot_number = soup.find_all('span', class_="_2-OsoCiQjnZhfC5xiIyFR3") for item in hot_title: list_title.append(item.get_text()) for item in hot_number: list_num.append(int(item.get_text().replace("万", "0000"))) data = { "title": list_title, "number": list_num, } df_data = DataFrame(data) columns = ['title', 'number'] if os.path.exists('热搜数据.xlsx'): os.remove('热搜数据.xlsx') if os.path.exists('热搜数据.xlsx'): df_data.to_excel('热搜数据.xlsx', mode='a', columns=columns, encoding='utf-8', header=False, index=False) else: df_data.to_excel('热搜数据.xlsx', columns=columns, encoding='utf-8', index=False) df = pd.read_excel("热搜数据.xlsx") dfnum = df.loc[:] obj = {} for row in dfnum.iterrows(): if row[1]['title'] not in obj.keys(): obj[row[1]['title']] = row[1]['number'] data_wc = list(zip(list(obj.keys()), list(obj.values()))) print(data_wc) wc = ( WordCloud(init_opts=opts.InitOpts(theme=ThemeType.PURPLE_PASSION, width="100%", height="800px")) .add("", data_wc, word_size_range=[10, 80], word_gap=5, shape="circle") .set_global_opts(title_opts=opts.TitleOpts(title="全国疫情词云")) ) return wc def bar2_get(): bar = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.PURPLE_PASSION, width="100%", height="800px")) # 设置x轴--疫情治愈地区的列表 .add_xaxis(list(obj_sure.keys())) # 设置y轴--对应疫情地区治愈人数的列表 .add_yaxis("死亡人数", list(obj_death.values()), category_gap=0, color="blue", gap="100%") # 设置柱状图标题 .set_global_opts(title_opts=opts.TitleOpts(title="全国新冠肺炎疫情累计治愈/死亡人数", # 设置柱状图副标题 subtitle="更新时间:{}".format(date.today()), # 设置柱状图标题位置制定 pos_top="top")) # 是否显示y轴的值 .set_series_opts(label_opts=opts.LabelOpts(is_show=False), ) ) return bar
# 绘制饼图 def pie_get(): pie = Pie(init_opts=opts.InitOpts(width="100%", height="800px")) # 拼接治愈地区列表和治愈人数列表,形成一个新列表,列表中的每一个元素都是一个元组 data = list(zip(list(obj_death.keys()), list(obj_death.values()))) # 为饼图添加data数据 pie.add("死亡人数", data) # 设置标题 pie.set_global_opts( title_opts=opts.TitleOpts(title="死亡人数"), # 将标题设置在右边 legend_opts=opts.LegendOpts(pos_right="right") ) # 饼图各部分所表示的城市,治愈人数,所占的百分比 # pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}人:{d}%")) return pie def scatter_get(): df_city = df.loc[:, ['province', 'city', 'sureNum']] df_city = df_city.drop(0) obj = {} for row in dfnum.iterrows(): if row[1]['province'] not in obj.keys(): obj[row[1]['province']] = [] obj[row[1]['province']].append(row[1]['sureNum']) sc = ( Scatter(init_opts=opts.InitOpts(width="100%", height="800px")) .add_xaxis(list_cure) .add_yaxis("治愈人数", y_axis=list_num) ) return sc def box_get(): df_city = df.loc[:, ['province', 'city', 'sureNum']] df_city = df_city.drop(0) obj = {} for row in dfnum.iterrows(): if row[1]['province'] not in obj.keys(): obj[row[1]['province']] = [] obj[row[1]['province']].append(row[1]['sureNum']) list_box = list(obj.values()) bp = Boxplot(init_opts=opts.InitOpts(width="100%", height="800px")) bp.add_xaxis(list_cure) bp.add_yaxis("治愈人数", list_box) return bp def page_simple(): page = Page(layout=Page.DraggablePageLayout, ) page.add( bar1_get(), bar2_get(), pie_get(), scatter_get(), box_get(), cloud_get() ) page.render("demo.html") print("绘图完毕") if __name__ == '__main__': spider() # 治愈人数 obj_sure = {} # 死亡人数 obj_death = {} # 读取爬虫生成的excel文件中的内容 df = pd.read_excel("疫情数据.xlsx") # 按列读取excel表中的对应3列,存储格式为dataframe dfnum = df.loc[:, ['province', 'sureNum', 'deathNum']] # 遍历列 for row in dfnum.iterrows(): # 判断obj_sure中有无对应的建,如果没有设置键以及对应的值,如果有将对应地区的治愈人数累加 if row[1]['province'] not in obj_sure.keys(): obj_sure[row[1]['province']] = row[1]['sureNum'] obj_sure[row[1]['province']] += row[1]['sureNum'] # 遍历列 for row in dfnum.iterrows(): # 判断obj_death中有无对应的建,如果没有设置键以及对应的值,如果有将对应地区的死亡人数累加 if row[1]['province'] not in obj_death.keys(): obj_death[row[1]['province']] = row[1]['deathNum'] obj_death[row[1]['province']] += row[1]['deathNum'] list_cure = list(obj_sure.keys()) list_num = list(obj_sure.values()) page_simple()

3.将以上各部分的代码汇总,附上完整程序代码
import os from datetime import date import pandas as pd import requests from bs4 import BeautifulSoup from pandas import DataFrame from pyecharts import options as opts from pyecharts.charts import Bar, Pie, Page, Scatter, Boxplot, WordCloud # 数据爬取 from pyecharts.globals import ThemeType def spider(): def get_page(url): # 获取响应头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36' } # 验证是否爬取成果 try: r = requests.get(url, headers=headers) r.raise_for_status() r.encoding = r.apparent_encoding return r.json() except Exception as e: print("Error", e) return "" # 解析html网页代码 def parse_page(data_json): data = data_json['data']['list'] date = data_json['data']['cachetime'].split(' ')[0] all_data = [] for i in data: if len(i['city']) != 0: province = i['name'] for j in i['city']: data_one = {} # 省份 data_one['province'] = province # 城市 data_one['city'] = j['name'] # 确诊人数 data_one['sureNum'] = j['conNum'] # 治愈人数 data_one['cureNum'] = j['cureNum'] # 死亡人数 data_one['deathNum'] = j['deathNum'] # 日期 data_one['date'] = date all_data.append(data_one) else: # 台湾、香港、澳门城市为空,需要单独追加 data_one = {} data_one['province'] = i['name'] data_one['city'] = i['name'] data_one['sureNum'] = i['value'] data_one['deathNum'] = i['deathNum'] data_one['cureNum'] = i['cureNum'] data_one['date'] = date all_data.append(data_one) result = pd.DataFrame(all_data) print(result) return (result) # 保存数据 def save_file(data_df): columns = ['province', 'city', 'sureNum', 'deathNum', 'cureNum', 'date'] if os.path.exists('疫情数据.xlsx'): data_df.to_excel('疫情数据.xlsx', mode='a', columns=columns, encoding='utf-8', header=False, index=False) else: data_df.to_excel('疫情数据.xlsx', columns=columns, encoding='utf-8', index=False) if __name__ == "__main__": url = 'https://gwpre.sina.cn/interface/fymap2020_data.json?1582011487323' data_json = get_page(url) result = parse_page(data_json) if os.path.exists('疫情数据.xlsx'): os.remove('疫情数据.xlsx') save_file(result) # 绘制柱状图 def bar1_get(): bar = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.PURPLE_PASSION, width="100%", height="800px")) # 设置x轴--疫情治愈地区的列表 .add_xaxis(list(obj_sure.keys())) # 设置y轴--对应疫情地区治愈人数的列表 .add_yaxis("治愈人数", list(obj_sure.values()), category_gap=0, color="red", gap="100%") # 设置柱状图标题 .set_global_opts(title_opts=opts.TitleOpts(title="全国新冠肺炎疫情累计治愈/死亡人数", # 设置柱状图副标题 subtitle="更新时间:{}".format(date.today()), # 设置柱状图标题位置制定 pos_top="top")) # 是否显示y轴的值 .set_series_opts(label_opts=opts.LabelOpts(is_show=False), ) ) return bar def cloud_get(): url = "https://top.baidu.com/board?tab=realtime" list_title = [] list_num = [] # 请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Mobile Safari/537.36' } # 发送请求 resp = requests.get(url, headers=headers) html = resp.content soup = BeautifulSoup(html, 'html.parser') hot_title = soup.find_all('span', class_="one-line-ellipsis _38vEKmzrdqNxu0Z5xPExcg") hot_number = soup.find_all('span', class_="_2-OsoCiQjnZhfC5xiIyFR3") for item in hot_title: list_title.append(item.get_text()) for item in hot_number: list_num.append(int(item.get_text().replace("万", "0000"))) data = { "title": list_title, "number": list_num, } df_data = DataFrame(data) columns = ['title', 'number'] if os.path.exists('热搜数据.xlsx'): os.remove('热搜数据.xlsx') if os.path.exists('热搜数据.xlsx'): df_data.to_excel('热搜数据.xlsx', mode='a', columns=columns, encoding='utf-8', header=False, index=False) else: df_data.to_excel('热搜数据.xlsx', columns=columns, encoding='utf-8', index=False) df = pd.read_excel("热搜数据.xlsx") dfnum = df.loc[:] obj = {} for row in dfnum.iterrows(): if row[1]['title'] not in obj.keys(): obj[row[1]['title']] = row[1]['number'] data_wc = list(zip(list(obj.keys()), list(obj.values()))) print(data_wc) wc = ( WordCloud(init_opts=opts.InitOpts(theme=ThemeType.PURPLE_PASSION, width="100%", height="800px")) .add("", data_wc, word_size_range=[10, 80], word_gap=5, shape="circle") .set_global_opts(title_opts=opts.TitleOpts(title="全国疫情词云")) ) return wc def bar2_get(): bar = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.PURPLE_PASSION, width="100%", height="800px")) # 设置x轴--疫情治愈地区的列表 .add_xaxis(list(obj_sure.keys())) # 设置y轴--对应疫情地区治愈人数的列表 .add_yaxis("死亡人数", list(obj_death.values()), category_gap=0, color="blue", gap="100%") # 设置柱状图标题 .set_global_opts(title_opts=opts.TitleOpts(title="全国新冠肺炎疫情累计治愈/死亡人数", # 设置柱状图副标题 subtitle="更新时间:{}".format(date.today()), # 设置柱状图标题位置制定 pos_top="top")) # 是否显示y轴的值 .set_series_opts(label_opts=opts.LabelOpts(is_show=False), ) ) return bar # 绘制饼图 def pie_get(): pie = Pie(init_opts=opts.InitOpts(theme=ThemeType.PURPLE_PASSION, width="100%", height="800px")) # 拼接治愈地区列表和治愈人数列表,形成一个新列表,列表中的每一个元素都是一个元组 data = list(zip(list(obj_death.keys()), list(obj_death.values()))) # 为饼图添加data数据 pie.add("死亡人数", data) # 设置标题 pie.set_global_opts( title_opts=opts.TitleOpts(title="死亡人数"), # 将标题设置在右边 legend_opts=opts.LegendOpts(pos_right="right") ) # 饼图各部分所表示的城市,治愈人数,所占的百分比 # pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}人:{d}%")) return pie def scatter_get(): df_city = df.loc[:, ['province', 'city', 'sureNum']] df_city = df_city.drop(0) obj = {} for row in dfnum.iterrows(): if row[1]['province'] not in obj.keys(): obj[row[1]['province']] = [] obj[row[1]['province']].append(row[1]['sureNum']) sc = ( Scatter(init_opts=opts.InitOpts(theme=ThemeType.PURPLE_PASSION, width="100%", height="800px")) .add_xaxis(list_cure) .add_yaxis("治愈人数", y_axis=list_num) ) return sc def box_get(): df_city = df.loc[:, ['province', 'city', 'sureNum']] df_city = df_city.drop(0) obj = {} for row in dfnum.iterrows(): if row[1]['province'] not in obj.keys(): obj[row[1]['province']] = [] obj[row[1]['province']].append(row[1]['sureNum']) list_box = list(obj.values()) bp = Boxplot(init_opts=opts.InitOpts(theme=ThemeType.PURPLE_PASSION, width="100%", height="800px")) bp.add_xaxis(list_cure) bp.add_yaxis("治愈人数", list_box) return bp def page_simple(): page = Page(layout=Page.DraggablePageLayout, ) page.add( bar1_get(), bar2_get(), pie_get(), scatter_get(), box_get(), cloud_get() ) page.render("demo.html") print("绘图完毕") if __name__ == '__main__': spider() # 治愈人数 obj_sure = {} # 死亡人数 obj_death = {} # 读取爬虫生成的excel文件中的内容 df = pd.read_excel("疫情数据.xlsx") # 按列读取excel表中的对应3列,存储格式为dataframe dfnum = df.loc[:, ['province', 'sureNum', 'deathNum']] # 遍历列 for row in dfnum.iterrows(): # 判断obj_sure中有无对应的建,如果没有设置键以及对应的值,如果有将对应地区的治愈人数累加 if row[1]['province'] not in obj_sure.keys(): obj_sure[row[1]['province']] = row[1]['sureNum'] obj_sure[row[1]['province']] += row[1]['sureNum'] # 遍历列 for row in dfnum.iterrows(): # 判断obj_death中有无对应的建,如果没有设置键以及对应的值,如果有将对应地区的死亡人数累加 if row[1]['province'] not in obj_death.keys(): obj_death[row[1]['province']] = row[1]['deathNum'] obj_death[row[1]['province']] += row[1]['deathNum'] list_cure = list(obj_sure.keys()) list_num = list(obj_sure.values()) page_simple()
五、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
从绘制的图表中查看到各个省份的治愈的人数,饼图上可以观察到各省份的死亡人数个比例,柱状图可以观察到各省份的总和的人数,词云图中可以观察到百度热搜中
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
通过这次疫情爬虫可视化项目的设计知道做一个项目首先得学会需求分析,数据分析等,明白自己要做出一个什么效果,这才是一个很好的开始,清楚的自己知道要干嘛。也知道了爬虫的重要性,可以爬取如此多的数据,最后通过一些pyecharts库结合网页设计出自己想要的一个效果。在这个设计过程中巩固了许多知识也对一个小项目的开发有了自己的认识,并体会到了完成一个小项目的成就感。需要改进的地方认为许多可视化的图表中数据展示的不够明显,可能使pyecharts库用的不熟练,暂时只能绘制出简单的图表;这个疫情的数据应为是别人写好的接口数据,我只需要请求就能得到该数据,不需要经过过多的处理,但在爬取百度热搜数据的时候就会遇到许多的问题,所以之后还得多多锻炼爬虫的应用;或许还可以选择更具省份显示当前省份的数据等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号