
ElasticSearch搜索解析
这篇介绍稍多,篇幅可能有点多,下面会针对一些重要的点做一些小测试
搜索返回文档解析
hits
搜索返回的结果中最重要的一部分其中包含了 索引信息(_index,_type,_index,_source,_score),_source又是其中我们最需要的东西,里面包含了查询的整个文档的内容,默认返回10个文档,这块可以结合分页处理
took
显示查询花费的时间
shards
查询的数据实际都检索了几个分区,这块跟关系型数据库中的表分区差不多,mysql 中的 partitions 通过执行计划查看可以看到
"_shards" : {
"failed" : 0,
"successful" : 10,
"total" : 10
}
看下上面的问题,这里可以会有失败的检索分片个数,在时间过程中如果数据分片丢失了,这里仍然会返回查询到的数据
timeout
查询是否超时
"timed_out" : false,我们也可以这样来写
GET _index/_type/?timeout=50 (ms)
给出我们的预期检索时间,当数据体量过大的时候或服务器性能本身的瓶颈,可能一次有效的搜索返回的结果很大(很多满足条件的搜索),这可能需要很长的时间,这是用户不能接受的,给出一个预期的需要查询的失效时间,满足这个时间就会停止查询,返回我们的结果,当然 可能搜索 10ms可能也会有很多数据,这块就需要分页显示了,给数据库分页一个概念
多索引多类型查询
满足如下规则即可
_index1,_index2/_type1,_type2/_search 用逗号分隔开
对应泛指情况可以使用*来处理,这点有点类似 Window系统中常用的搜索 如 *.jpg
a*,b*/_type1,_type2/_search
这里需要说明的是所有的 索引类型都是组合关系
分页查询
分页查询结合前面的查询通过 size 、from 来处理
GET _index/_type/_search?size=10&from=10
size:需要查询的数据条数 、from:从那一条开始 默认是0,这块与EF中的 Take(size).Skip(from) 类似,取多少条,跳过多少开始取
这里如果是单个分片查询还好,如果数据来之多个分片的情况下,排序就需要处理了,否则查询出来的数据可能不是最满足我们条件的数据。
如果我们能在查询来自3个分片,我们需要在我们实际查询的逻辑是先查询出来在组合起来排序取到size,这点类似 你高中时期的成绩
如:我们需要取出来 全年级排名前40-50的人员信息,首先我们不能取每个班级第40-50的人员 然后按班级组合在一起 在取第40-50,显然这样做是错误的,因为 班级1-50中的一些完全有可能在年纪40-50中,但是这里有一个临界点,就是班级中50以后的绝对不会在年级的前50,这是可以肯定的,为了查询到最后的结果,必须把每个班级都是取前5-条数据,然后合并后在取第40-50的数据才是正确的
注:这里我们实际要检索的数据 是 【分片数据*from】的数量,当我们的分页纵深很大的时候 取到第500页,每页10条,3个分片,最终检索出来的数据是 3*5000 条数据的排序 ,如果取到数据纵深越大,搜索效率也是越低的
轻量查询
轻量级查询不需要写表达式,一般通过get请求,通过参数的方式查询结果,带有query match 等表达式的查询不一样,它是通过地址栏组合参数来处理
结合前面数据例子:
http://192.168.0.212:9200/liyouming/_search?pretty&q=+mytext:黎又铭)
结果:


{ "took" : 7, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : 3, "max_score" : 3.0561461, "hits" : [ { "_index" : "liyouming", "_type" : "liyoumingtext", "_id" : "c7eQAWoB0Mh7sqcTGY-K", "_score" : 3.0561461, "_source" : { "mytext" : "中午黎又铭在操场上打篮球" } }, { "_index" : "liyouming", "_type" : "liyoumingtext", "_id" : "dLeQAWoB0Mh7sqcTdo9b", "_score" : 2.1251993, "_source" : { "mytext" : "深夜还在写代码的人只有黎又铭" } }, { "_index" : "liyouming", "_type" : "liyoumingtext", "_id" : "crePAWoB0Mh7sqcTzY-2", "_score" : 0.8630463, "_source" : { "mytext" : "黎又铭早上吃了一碗面" } } ] } }
当然:我们要对同一个字段得到 or 这种操作 通过 条件空格 来分割多个选项,参数只能写q
如:http://192.168.0.212:9200/liyouming/_search?pretty&q=+mytext:(值1 值2)
这里还有其他的一些符号
+ 表示+后面的字段必须满足 值条件 类似 sql中的 in 包含
- 表示 - 后面的字段不能满足 值条件 类似 sql中的 not in 不包含
:表示用来区分字段与字段值
() 表示对于多个值的一种组合
这是对字符串的操作,有时候我们需要对日期 数字 等进行范围 大小等查询操作
下面来加几条数据
{ "url":"datetest/mytest", "param":{ "name":"张三", "date":"2019-04-18 15:15:16" } }
例子:
日期 http://192.168.0.212:9200/liyouming/_search?pretty&q=+date:>2019-03-01
显然这样搜索可能跟我们预期的结果不一样,一条数据有没有,其实添加的时候这个格式就错误了,可能没有被es认知并转换为时间类型,elasticsearch中会转换它认为是时间格式的字符串,详细可以参考这里:
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html
我们先不加入时间段部分,查询搜索就ok了
映射(Mapping)描述数据在每个字段内如何存储
如同前面对日期的识别,其实es映射支持类型有,当满足格式es会猜测类型
字符串:string
整数:byte, short, integer, long
浮点数:float, double
布尔型: boolean
日期: date
我们可以通过如下地址查看映射
http://192.168.0.212:9200/datetest/_mapping?pretty
来查看下 datetest 对于字段的映射,可以看到属性中的字段类型
结果:
{ "datetest" : { "mappings" : { "test" : { "properties" : { "date" : { "type" : "date" }, "name" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } } }
接下来检验下这些类型映射情况并实现搜索下查看下最终的结果 Put创建下
{ "index":"mappingtest/test", "param":{ "booltest1":false, "booltest2":"true", "inttest":123, "inttest1":"456", "floattest":123.45, "floattest1":"456.45", "datetest1":"2019-02-01", "datetest2":"2019-02-01 15:15:15", "datetest3":"2019-02-01T15:15:15", "datetest4":"10:15:30", "datetest5":"Tue, 3 Jun 2008 11:05:30 GMT", "datetest6":"2018-12-03+01:00", "datetest7":"20190103", } }
我们看下这些格式的映射情况 通过结果我们可以看到哪些字段被识别成了相应的类型
这是实际类型的识别情况
{ "mappingtest" : { "mappings" : { "test" : { "properties" : { "booltest1" : { "type" : "boolean" }, "booltest2" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "datetest1" : { "type" : "date" }, "datetest2" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "datetest3" : { "type" : "date" }, "datetest4" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "datetest5" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "datetest6" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "datetest7" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "floattest" : { "type" : "float" }, "floattest1" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "inttest" : { "type" : "long" }, "inttest1" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } } }
{ "index":"mappingtest/test", "param":{ "booltest1":false, // boolean "booltest2":"true", // text "inttest":123, // long "inttest1":"456", //text "floattest":123.45, //float "floattest1":"456.45", //text "datetest1":"2019-02-01",//date "datetest2":"2019-02-01 15:15:15",//text "datetest3":"2019-02-01T15:15:15", //date "datetest4":"10:15:30", //text "datetest5":"Tue, 3 Jun 2008 11:05:30 GMT", ", //text "datetest6":"2018-12-03+01:00", ", //text "datetest7":"20190103", ", //text } }
当然我们是可以对这块映射预先设置对于的类型(type)以及 分析器(analyzed),但是这块需要预先设置,如果对之前已经有的进行修改不会成功,下面我们添加了一个datetest10,我们在来测试羡慕提娜佳的数据看一下
{ "index":"mappingtest/_mapping/test", "param":{ "properties" : { "datetest10" : { "type" : "date", "analyzed":"ik_smart" } } } }
预先设定好类型后对后续的收录会出现相关的类型校验,如果没有被识别到对于类型的格式就会错误
分析(Analysis)全文是如何处理使之可以被搜索的
标准分析器:是Elasticsearch默认使用的分析器。它是分析各种语言文本最常用的选择
空格分析器:在空格的地方划分文本。它会产生
简单分析器:在任何不是字母的地方分隔文本,将词条小写。它会产生
语言分析器:特定语言分析器可用于 {ref}/analysis-lang-analyzer.html[很多语言]。它们可以考虑指定语言的特点
这里用中文分词分析器来举例,分析器会帮会将文档内容中一个字段按照分词的方式拆解开
这块跟搜索密不可分,这里就需要分词插件 分词库,这里测试用的ik
安装ik在前面的文章中已经介绍过了
如果是在数据中要查找新闻内容的化会出现 like '%搜索词汇%' 也可以通过全文查找,下面来介绍下es中的怎么来处理的
打个比方 分析器就是物流运输过程中的 分拣员,他会根据包裹的 地区 位置 等信息 分拣包裹 以便于用户能够准确的收到自己的包裹,分词如下一样,每个分词组都记录了来源的文档位置方便索引,同时对匹配会有一个评分,匹配度高的词汇来源文档次数越多,这样文档的评分就越高
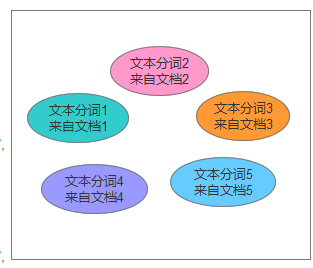
我们来创建一个我们的IK分析器测试 ik_max_word
{ "index":"_analyze?pretty", "param":{ "analyzer":"ik_max_word", "text":"这是一个非常好的分词库测试" } } 分词结果: { "tokens": [ { "token": "这是", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 }, { "token": "一个", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 1 }, { "token": "一", "start_offset": 2, "end_offset": 3, "type": "TYPE_CNUM", "position": 2 }, { "token": "个", "start_offset": 3, "end_offset": 4, "type": "COUNT", "position": 3 }, { "token": "非常好", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 4 }, { "token": "非常", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 5 }, { "token": "好", "start_offset": 6, "end_offset": 7, "type": "CN_CHAR", "position": 6 }, { "token": "的", "start_offset": 7, "end_offset": 8, "type": "CN_CHAR", "position": 7 }, { "token": "分词", "start_offset": 8, "end_offset": 10, "type": "CN_WORD", "position": 8 }, { "token": "词库", "start_offset": 9, "end_offset": 11, "type": "CN_WORD", "position": 9 }, { "token": "测试", "start_offset": 11, "end_offset": 13, "type": "CN_WORD", "position": 10 } ] }
同样的句子我们再来以另一种规则分词 ik_smart
{ "index":"_analyze?pretty", "param":{ "analyzer":"ik_smart", "text":"这是一个非常好的分词库测试" } } 分词结果可以看到 { "tokens": [ { "token": "这是", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 }, { "token": "一个", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 1 }, { "token": "非常好", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 2 }, { "token": "的", "start_offset": 7, "end_offset": 8, "type": "CN_CHAR", "position": 3 }, { "token": "分", "start_offset": 8, "end_offset": 9, "type": "CN_CHAR", "position": 4 }, { "token": "词库", "start_offset": 9, "end_offset": 11, "type": "CN_WORD", "position": 5 }, { "token": "测试", "start_offset": 11, "end_offset": 13, "type": "CN_WORD", "position": 6 } ] }
领域特定查询语言(Query DSL)Elasticsearch 中强大灵活的查询语言
说到这块的查询,表达式是以请求体的方式发送的而且是Get请求,一开始我也觉得很奇怪,我在.NetCore环境下模拟这些请求,Get请求带请求体连我的Api路由都没办法匹配到
我又尝试了用POST请求,但是这是可以查询到结果的,于是我在Linux上又试了一次
curl -XGET "localhost:9200/test/_search?pretty" -H "Context-Type:application/json" -d "{Query DSL}"
这样也是没问题的,这块是怎么回事呢?
官方也给出了说明:
某些特定语言(特别是 JavaScript)的 HTTP 库是不允许 GET 请求带有请求体的。事实上,一些使用者对于 GET 请求可以带请求体感到非常的吃惊,而事实是这个RFC文档 RFC 7231— 一个专门负责处理 HTTP 语义和内容的文档 — 并没有规定一个带有请求体的 GET 请求应该如何处理!结果是,一些 HTTP 服务器允许这样子,而有一些 — 特别是一些用于缓存和代理的服务器 — 则不允许。
对于一个查询请求,Elasticsearch 的工程师偏向于使用 GET 方式,因为他们觉得它比 POST 能更好的描述信息检索(retrieving information)的行为。然而,因为带请求体的 GET 请求并不被广泛支持,所以 search API同时支持 POST 请求
这也就是我使用POST请求的方式能够成功的原因,它是都(GET/POST)支持的
合并查询语句
叶子语句: 被用于将查询字符串和一个字段(或者多个字段)对比 , 入宫MSSQL中组成的一个一个的条件,在MSSQL中一个一个的条件之间会存在一定的关系,比如 >、 <、 in、 not in 、= 、还有就是组合()括号内的条件 等等,那么在es中是怎么来处理这样的查询关系呢?需要组合条件
如果是单个的查询 match 匹配 not_match 等,这里都是match 匹配 类似(like)而非精确查找,如 = 这种精确查找 要结合 _mapping 中的 not_analyzed 设置 和 terms 来处理
复合语句:在EF中用到过Linq lambda表达的都知道Expression,有时候在查询结果组合后都会返回一个 boolean值,在es中这块也是异曲同工。
查询表达式需要在query里面,当然也可以通过简单查询通过url地址处理,这里的是表达式方式,可以处理复杂的一些查询条件
{ "query":{ "match":{"filed1":"value1"}, "match":{"filed2":"value2"} } }
这里的每一个match都是匹配型的类似like,这里两个match之间的关系是and并且关系,下面我们来验证下
{ "index":"liyouming/_search?pretty", "param":{ "query":{ "match": { "mytext": "黎又铭" } } } }
可以看到结果 所有包含【黎又铭】的都检索出来了
{ "took": 6, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 3.0561461, "hits": [ { "_index": "liyouming", "_type": "liyoumingtext", "_id": "c7eQAWoB0Mh7sqcTGY-K", "_score": 3.0561461, "_source": { "mytext": "中午黎又铭在操场上打篮球" } }, { "_index": "liyouming", "_type": "liyoumingtext", "_id": "dLeQAWoB0Mh7sqcTdo9b", "_score": 2.1251993, "_source": { "mytext": "深夜还在写代码的人只有黎又铭" } }, { "_index": "liyouming", "_type": "liyoumingtext", "_id": "crePAWoB0Mh7sqcTzY-2", "_score": 0.8630463, "_source": { "mytext": "黎又铭早上吃了一碗面" } } ] } }
接下来使用2个条件
{ "index":"liyouming/_search?pretty", "param":{ "query":{ "match": { "mytext": "黎又铭" }, "match": { "mytext": "中午" } } } } 查询结果 同时满足条件的就只有1条数据了 { "took": 4, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 1.0187154, "hits": [ { "_index": "liyouming", "_type": "liyoumingtext", "_id": "c7eQAWoB0Mh7sqcTGY-K", "_score": 1.0187154, "_source": { "mytext": "中午黎又铭在操场上打篮球" } } ] } }
关于这块查询还有太多的东西,将会在后面的章节继续介绍
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!
本文版权归作者和博客园共有,来源网址:http://www.cnblogs.com/liyouming欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号