

具身智能基础技术路线
具身智能即Emoboided AI 是集成环境理解、智能交互、认知推理、规划执行于一体的系统化方案
-
环境理解:通过融合多模态传感器信息,对物理环境的几何结构、物体属性、空间关系及潜在交互可能性(可供性)进行解析与建模。
-
智能交互:基于对环境和任务上下文的理解,以自然、高效的方式(如语言、手势)与人类或其他智能体进行信息交换与协作。
-
认知推理:运用已有知识和逻辑规则,对感知信息进行抽象、归纳和演绎,以理解隐含信息、预测未来状态并做出决策。
-
规划执行:将高层任务目标分解为一系列可执行的原子动作序列,并控制身体在物理世界中精准、可靠地完成该序列。
基础技术路线
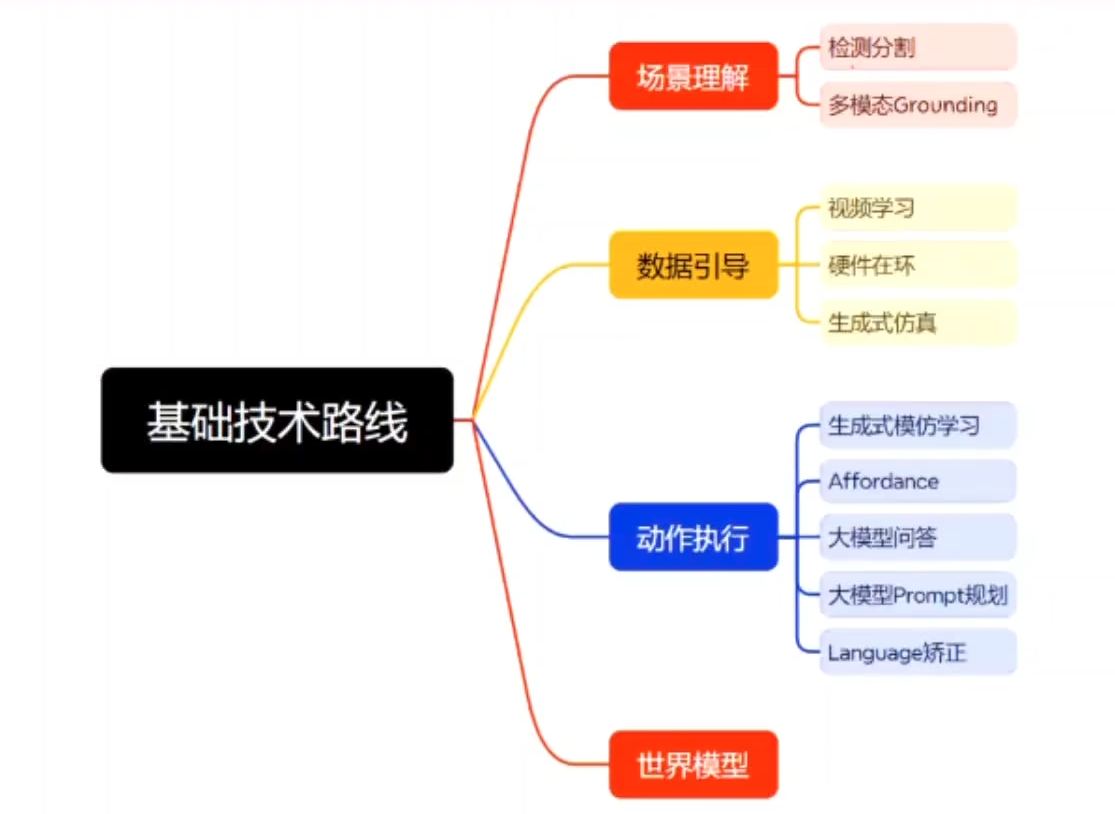
场景理解
-
检查分割:在场景理解中,检查分割通过将图像中的目标区域精确划分出来,从而支持后续的识别与分析。
-
多模态 grounding:多模态 grounding 将语言描述与视觉区域对齐,实现“词语—图像区域”的对应,帮助模型理解跨模态语义。
数据引导
-
视频学习:利用大量视频数据进行模型训练,让模型从时序信息中学习动态场景理解。
-
硬件在环:通过将真实硬件接入仿真环境,在闭环测试中验证算法和系统的可靠性。
-
生成式仿真:借助生成模型自动合成多样化的仿真数据,用于提升模型的泛化能力。
动作执行
-
生成式模仿学习:通过生成模型学习专家演示的动作分布,实现自主体对复杂任务的模仿与泛化。
-
Affordance:通过场景中物体与环境的可供性(能做什么)推理,指导智能体选择合理的交互动作。
-
大模型问答:利用大语言模型对任务或环境问题进行推理问答,辅助动作决策。
-
大模型 Prompt 规划:通过精心设计 Prompt,引导大模型输出结构化的行动计划。
-
Language 矫正:对指令或模型生成的文本进行语义纠错和规范化,保证动作执行的准确性与一致性。
世界模型
世界模型(World Model):指智能体在交互过程中构建和利用对环境的内部表征,用于预测未来状态和规划最优动作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号