

Spark实践之SparkSQL
Spark SQL
Spark为结构化数据处理引入了一个称为Spark SQL的编程模块。它提供了一个称为DataFrame的编程抽象,并且可以充当分布式SQL查询引擎。
Spark SQL的特性
- 集成
无缝地将SQL查询与Spark程序混合。 Spark SQL允许将结构化数据作为Spark中的分布式数据集(RDD)进行查询,在Python,Scala和Java中集成了API。这种紧密的集成使得可以轻松地运行SQL查询以及复杂的分析算法。
- Hive兼容性
在现有仓库上运行未修改的Hive查询。 Spark SQL重用了Hive前端和MetaStore,提供与现有Hive数据,查询和UDF的完全兼容性。只需将其与Hive一起安装即可。
- 标准连接
通过JDBC或ODBC连接。 Spark SQL包括具有行业标准JDBC和ODBC连接的服务器模式。
- 可扩展性
对于交互式查询和长查询使用相同的引擎。 Spark SQL利用RDD模型来支持中查询容错,使其能够扩展到大型作业。不要担心为历史数据使用不同的引擎。
Spark SQL 数据类型
Spark SQL 支持多种数据类型,包括数字类型、字符串类型、二进制类型、布尔类型、日期时间类型和区间类型等。
数字类型包括:
ByteType:代表一个字节的整数,范围是 -128 到 127¹²。ShortType:代表两个字节的整数,范围是 -32768 到 32767¹²。IntegerType:代表四个字节的整数,范围是 -2147483648 到 2147483647¹²。LongType:代表八个字节的整数,范围是 -9223372036854775808 到 9223372036854775807¹²。FloatType:代表四字节的单精度浮点数¹²。DoubleType:代表八字节的双精度浮点数¹²。DecimalType:代表任意精度的十进制数据,通过内部的 java.math.BigDecimal 支持。BigDecimal 由一个任意精度的整型非标度值和一个 32 位整数组成¹²。
字符串类型包括:
StringType:代表字符字符串值。
二进制类型包括:
BinaryType:代表字节序列值。
布尔类型包括:
BooleanType:代表布尔值。
日期时间类型包括:
TimestampType:代表包含字段年、月、日、时、分、秒的值,与会话本地时区相关。时间戳值表示绝对时间点。DateType:代表包含字段年、月和日的值,不带时区。
区间类型包括:
YearMonthIntervalType (startField, endField):表示由以下字段组成的连续子集组成的年月间隔:MONTH(月份),YEAR(年份)。DayTimeIntervalType (startField, endField):表示由以下字段组成的连续子集组成的日时间间隔:SECOND(秒),MINUTE(分钟),HOUR(小时),DAY(天)。
复合类型包括:
ArrayType (elementType, containsNull):代表由 elementType 类型元素组成的序列值。containsNull 用来指明 ArrayType 中的值是否有 null 值。MapType (keyType, valueType, valueContainsNull):表示包括一组键值对的值。通过 keyType 表示 key 数据的类型,通过 valueType 表示 value 数据的类型。valueContainsNull 用来指明 MapType 中的值是否有 null 值。StructType (fields):表示一个拥有 StructFields (fields) 序列结构的值。StructField (name, dataType, nullable):代表 StructType 中的一个字段,字段的名字通过 name 指定,dataType 指定 field 的数据类型,nullable 表示字段的值是否有 null 值。
DataFrame
DataFrame 是 Spark 中用于处理结构化数据的一种数据结构。它类似于关系数据库中的表,具有行和列。每一列都有一个名称和一个类型,每一行都是一条记录。
DataFrame 支持多种数据源,包括结构化数据文件、Hive 表、外部数据库和现有的 RDD。它提供了丰富的操作,包括筛选、聚合、分组、排序等。
DataFrame 的优点在于它提供了一种高级的抽象,使得用户可以使用类似于 SQL 的语言进行数据处理,而无需关心底层的实现细节。此外,Spark 会自动对 DataFrame 进行优化,以提高查询性能。
下面是一个使用DataFrame的代码例子:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("DataFrame Example").getOrCreate()
import spark.implicits._
val data = Seq(
("Alice", 25),
("Bob", 30),
("Charlie", 35)
)
val df = data.toDF("name", "age")
df.show()在这个示例中,我们首先创建了一个 SparkSession 对象,然后使用 toDF 方法将一个序列转换为 DataFrame。最后,我们使用 show 方法来显示 DataFrame 的内容。
创建 DataFrame
在 Scala 中,可以通过以下几种方式创建 DataFrame:
- 从现有的 RDD 转换而来。例如:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Create DataFrame").getOrCreate()
import spark.implicits._
case class Person(name: String, age: Int)
val rdd = spark.sparkContext.parallelize(Seq(Person("Alice", 25), Person("Bob", 30)))
val df = rdd.toDF()
df.show()- 从外部数据源读取。例如,从 JSON 文件中读取数据并创建 DataFrame:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Create DataFrame").getOrCreate()
val df = spark.read.json("path/to/json/file")
df.show()- 通过编程方式创建。例如,使用
createDataFrame方法:
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
val spark = SparkSession.builder.appName("Create DataFrame").getOrCreate()
val schema = StructType(
List(
StructField("name", StringType, nullable = true),
StructField("age", IntegerType, nullable = true)
)
)
val data = Seq(Row("Alice", 25), Row("Bob", 30))
val rdd = spark.sparkContext.parallelize(data)
val df = spark.createDataFrame(rdd, schema)
df.show()DSL & SQL
在 Spark 中,可以使用两种方式对 DataFrame 进行查询:DSL(Domain-Specific Language)和 SQL。
DSL 是一种特定领域语言,它提供了一组用于操作 DataFrame 的方法。例如,下面是一个使用 DSL 进行查询的例子:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("DSL and SQL").getOrCreate()
import spark.implicits._
val df = Seq(
("Alice", 25),
("Bob", 30),
("Charlie", 35)
).toDF("name", "age")
df.select("name", "age")
.filter($"age" > 25)
.show()SQL 是一种结构化查询语言,它用于管理关系数据库系统。在 Spark 中,可以使用 SQL 对 DataFrame 进行查询。例如,下面是一个使用 SQL 进行查询的例子:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("DSL and SQL").getOrCreate()
import spark.implicits._
val df = Seq(
("Alice", 25),
("Bob", 30),
("Charlie", 35)
).toDF("name", "age")
df.createOrReplaceTempView("people")
spark.sql("SELECT name, age FROM people WHERE age > 25").show()DSL 和 SQL 的区别在于语法和风格。DSL 使用方法调用链来构建查询,而 SQL 使用声明式语言来描述查询。选择哪种方式取决于个人喜好和使用场景。
Spark SQL 数据源
Spark SQL 支持多种数据源,包括 Parquet、JSON、CSV、JDBC、Hive 等。
下面是示例代码:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Data Sources Example").getOrCreate()
// Parquet
val df = spark.read.parquet("path/to/parquet/file")
// JSON
val df = spark.read.json("path/to/json/file")
// CSV
val df = spark.read.option("header", "true").csv("path/to/csv/file")
// JDBC
val df = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://host:port/database")
.option("dbtable", "table")
.option("user", "username")
.option("password", "password")
.load()
df.show()load & save
在 Spark 中,load 函数用于从外部数据源读取数据并创建 DataFrame,而 save 函数用于将 DataFrame 保存到外部数据源。
下面是从 Parquet 文件中读取数据并创建 DataFrame 的示例代码:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Load and Save Example").getOrCreate()
val df = spark.read.load("path/to/parquet/file")
df.show()下面是将 DataFrame 保存到 Parquet 文件的示例代码:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Load and Save Example").getOrCreate()
import spark.implicits._
val df = Seq(
("Alice", 25),
("Bob", 30),
("Charlie", 35)
).toDF("name", "age")
df.write.save("path/to/parquet/file")函数
Spark SQL 提供了丰富的内置函数,包括数学函数、字符串函数、日期时间函数、聚合函数等。你可以在 Spark SQL 的官方文档中查看所有可用的内置函数。
此外,Spark SQL 还支持自定义函数(User-Defined Function,UDF),可以让用户编写自己的函数并在查询中使用。
下面是一个使用 SQL 语法编写自定义函数的示例代码:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.udf
val spark = SparkSession.builder.appName("UDF Example").getOrCreate()
import spark.implicits._
val df = Seq(
("Alice", 25),
("Bob", 30),
("Charlie", 35)
).toDF("name", "age")
df.createOrReplaceTempView("people")
val square = udf((x: Int) => x * x)
spark.udf.register("square", square)
spark.sql("SELECT name, square(age) FROM people").show()在这个示例中,我们首先定义了一个名为 square 的自定义函数,它接受一个整数参数并返回它的平方。然后,我们使用 createOrReplaceTempView 方法创建一个临时视图,并使用 udf.register 方法注册自定义函数。最后,我们使用 spark.sql 方法执行 SQL 查询,并在查询中调用自定义函数。
DataSet
DataSet 是 Spark 1.6 版本中引入的一种新的数据结构,它提供了 RDD 的强类型和 DataFrame 的查询优化能力。
创建DataSet
在 Scala 中,可以通过以下几种方式创建 DataSet:
- 从现有的 RDD 转换而来。例如:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Create DataSet").getOrCreate()
import spark.implicits._
case class Person(name: String, age: Int)
val rdd = spark.sparkContext.parallelize(Seq(Person("Alice", 25), Person("Bob", 30)))
val ds = rdd.toDS()
ds.show()- 从外部数据源读取。例如,从 JSON 文件中读取数据并创建 DataSet:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Create DataSet").getOrCreate()
import spark.implicits._
case class Person(name: String, age: Long)
val ds = spark.read.json("path/to/json/file").as[Person]
ds.show()- 通过编程方式创建。例如,使用
createDataset方法:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Create DataSet").getOrCreate()
import spark.implicits._
case class Person(name: String, age: Int)
val data = Seq(Person("Alice", 25), Person("Bob", 30))
val ds = spark.createDataset(data)
ds.show()DataSet和DataFrame区别
DataSet 和 DataFrame 都是 Spark 中用于处理结构化数据的数据结构。它们都提供了丰富的操作,包括筛选、聚合、分组、排序等。
它们之间的主要区别在于类型安全性。DataFrame 是一种弱类型的数据结构,它的列只有在运行时才能确定类型。这意味着,在编译时无法检测到类型错误,只有在运行时才会抛出异常。
而 DataSet 是一种强类型的数据结构,它的类型在编译时就已经确定。这意味着,如果你试图对一个不存在的列进行操作,或者对一个列进行错误的类型转换,编译器就会报错。
此外,DataSet 还提供了一些额外的操作,例如 map、flatMap、reduce 等。
RDD & DataFrame & Dataset 转化
RDD、DataFrame、Dataset三者有许多共性,有各自适用的场景常常需要在三者之间转换。
- DataFrame/Dataset转RDD
val rdd1=testDF.rdd
val rdd2=testDS.rdd- RDD转DataFrame
import spark.implicits._
case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型
val testDS = rdd.map {line=>
Coltest(line._1,line._2)
}.toDS可以注意到,定义每一行的类型(case class)时,已经给出了字段名和类型,后面只要往case class里面添加值即可。
- Dataset转DataFrame
import spark.implicits._
val testDF = testDS.toDF- DataFrame转Dataset
import spark.implicits._
case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型
val testDS = testDF.as[Coltest]这种方法就是在给出每一列的类型后,使用as方法,转成Dataset,这在数据类型在DataFrame需要针对各个字段处理时极为方便。
注意: 在使用一些特殊的操作时,一定要加上 import spark.implicits._ 不然toDF、toDS无法使用。4
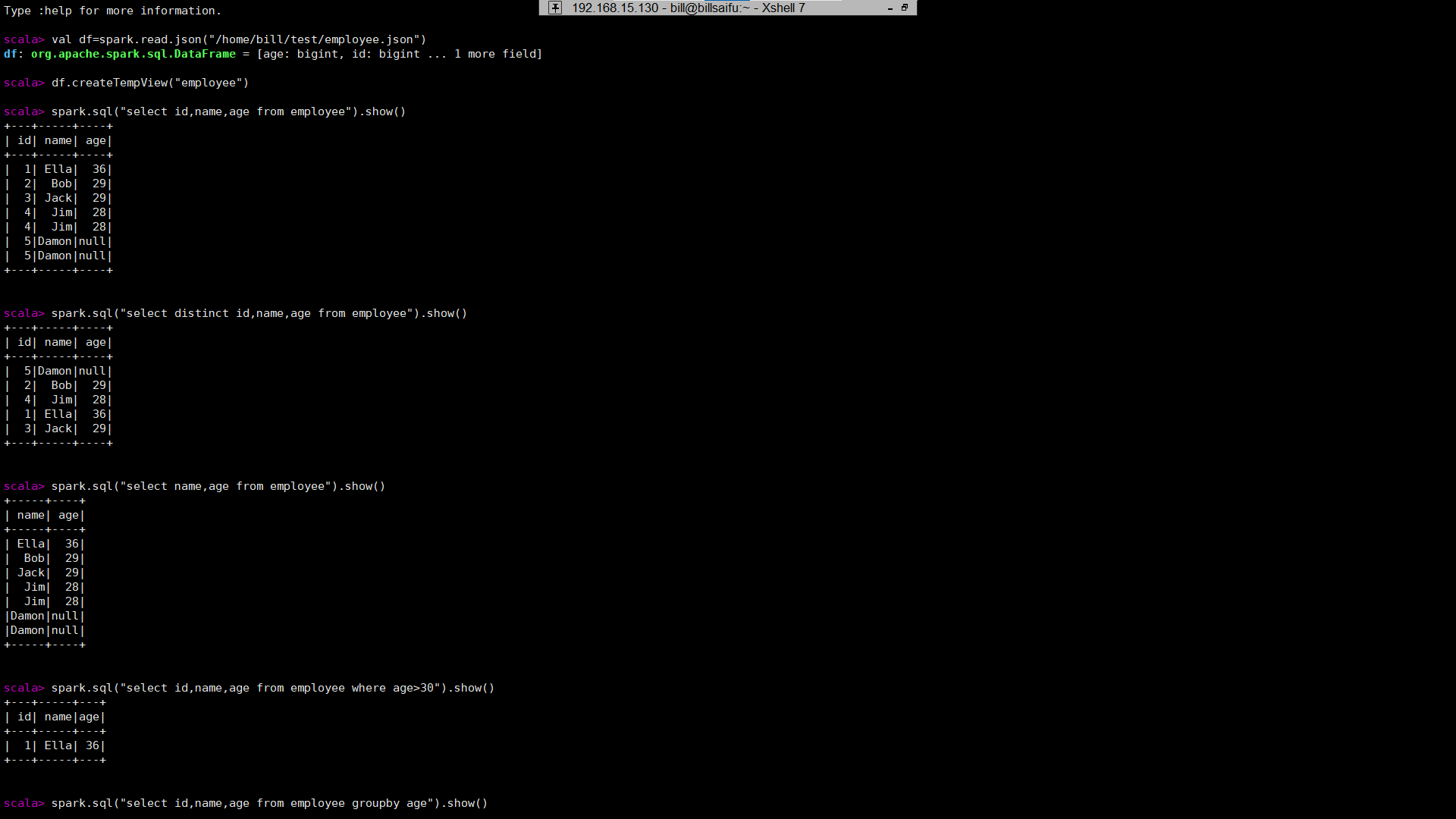
将下列 JSON 格式数据复制到 Linux 系统中,并保存命名为 employee.json。
{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
为 employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
(1) 查询所有数据;
(2) 查询所有数据,并去除重复的数据;
(3) 查询所有数据,打印时去除 id 字段;
(4) 筛选出 age>30 的记录;
(5) 将数据按 age 分组;
(6) 将数据按 name 升序排列;
(7) 取出前 3 行数据;
(8) 查询所有记录的 name 列,并为其取别名为 username;
(9) 查询年龄 age 的平均值;
(10) 查询年龄 age 的最小值。


(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee,包含如表 6-2 所示的
两行数据。表 表 6-2 employee 表原有数据id name gender Age1 Alice F 222 John M 25
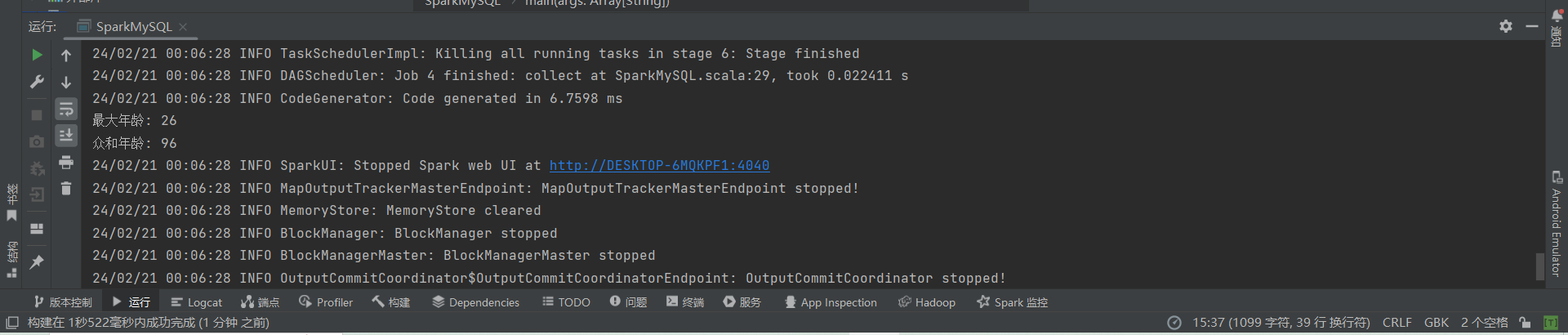
(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入如表 6-3 所
示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。表 表 6-3 employee 表新增数据id name gender age3 Mary F 264 Tom M 23
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkMySQL {
def main(args: Array[String]): Unit = {
// 1. 创建 SparkSession 对象
val spark = SparkSession.builder()
.appName("Spark MySQL Example")
.config("spark.master", "local")
.getOrCreate()
// 2. 加载数据到 DataFrame
val data: DataFrame = spark.createDataFrame(Seq(
(3, "Marry", "F", 26),
(4, "Tom", "M", 23)
)).toDF("id", "name", "gender", "age")
// 3. 将数据插入到 MySQL 数据库中
val url = "jdbc:mysql://billsaifu:3306/sparktest"
val tableName = "employee"
val properties = new java.util.Properties()
properties.setProperty("user", "root")
properties.setProperty("password", "123456")
data.write.mode("append").jdbc(url, tableName, properties)
// 4. 执行聚合操作
val df = spark.read.jdbc(url, tableName, properties)
val maxAge = df.selectExpr("max(age)").collect()(0)(0)
val sumAge = df.selectExpr("sum(age)").collect()(0)(0)
// 5. 打印结果
println(s"最大年龄: $maxAge")
println(s"众和年龄: $sumAge")
// 6. 关闭 SparkSession
spark.stop()
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号