DGL学习(三): 消息传递教程
在本节中,我们将不同级别的消息传递API与PageRank一起使用。 在DGL中,消息传递和功能转换是用户定义的函数(UDF)。
PageRank 算法:
在PageRank的每次迭代中,每个节点(网页)首先将其PageRank值均匀地分散到其下游节点。 每个节点的新PageRank值是通过汇总从其邻居收到的PageRank值来计算的,然后通过阻尼因子(damping factor)进行调整:
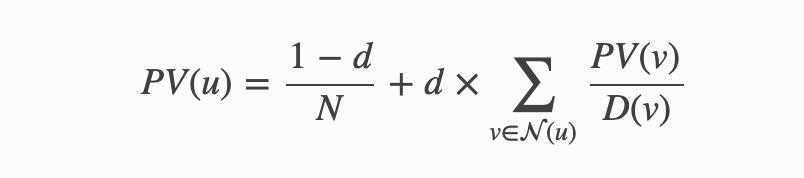
生成一个随机图, 两点之间有边的概率为 P:
import networkx as nx import matplotlib.pyplot as plt import torch import dgl N = 100 P = 0.1
DAMP = 0.8
g = nx.erdos_renyi_graph(N, P) g = dgl.DGLGraph(g)
src = list(range(1,51));dst = [0]*50 # 使用list批量添加
g.add_edges(src, dst)
print(g.number_of_edges()) print(g.number_of_nodes()) nx.draw(g.to_networkx(), node_size=50, node_color=[[.5, .5, .5,]])
plt.show()
在pagerank 中, 初始化每个节点初始值为 1/N, 将节点的出度作为节点的特征。
## pv 算法初始值 g.ndata['pv'] = torch.ones(N) / N g.ndata['deg'] = g.out_degrees(g.nodes()).float()
定义消息函数,该函数将每个节点的PageRank值除以其出度,然后将结果作为消息传递给其邻居。
在DGL中,消息函数是针对边的,表示为Edge UDF。 Edge UDF接受单个参数edges。 它具有三个成员src,dst和data,用于访问源节点特征,目标节点特征和边特征。实现pv算法仅需从src中取特征。
def pagerank_message_func(edges): return {'pv': edges.src['pv'] / edges.src['deg']}
定义reduce函数,该函数从其mailbox中聚合消息和删除消息,并计算其新的PageRank值。
reduce函数是针对节点的,表示为 Node UDF。 Node UDF接受单个参数nodes,nodes具有两个成员mailbox和data。 data包含节点特征,mailbox包含所有传入消息特征,这些功能沿第二维堆叠(dim = 1参数)。
可以结合下图进行理解:
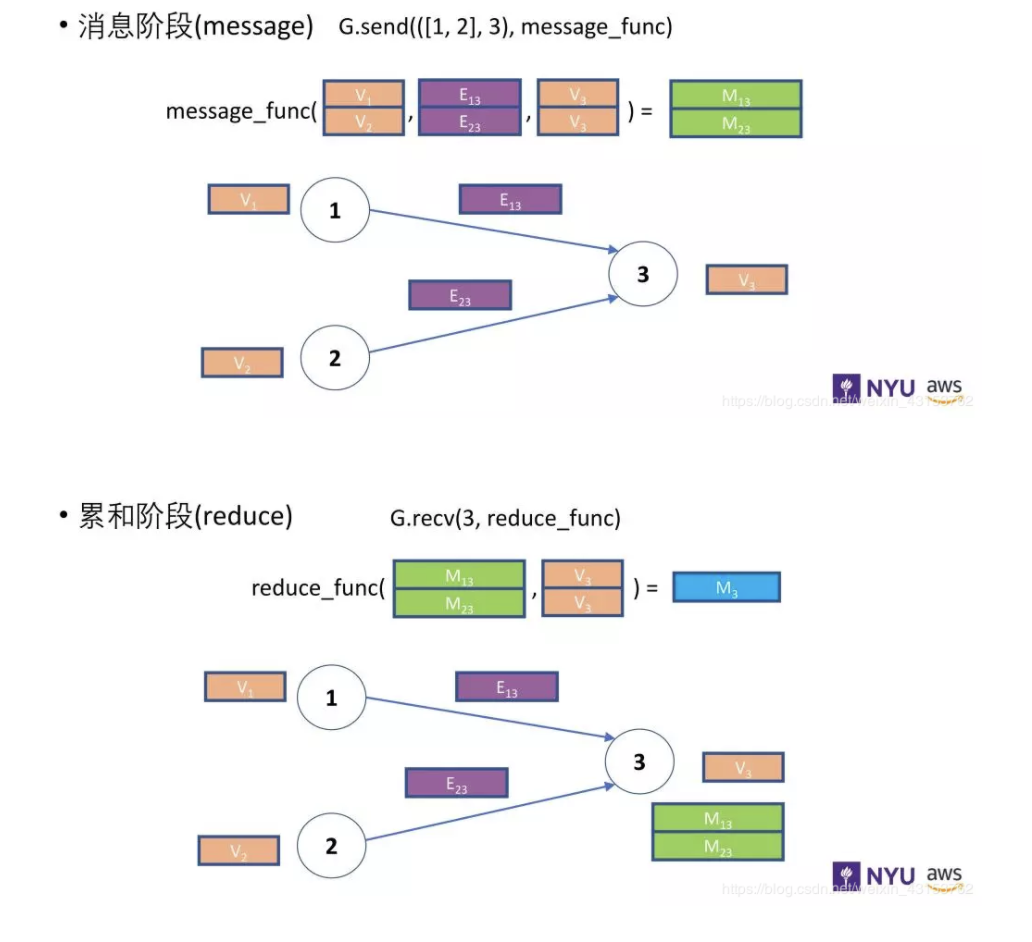
def pagerank_reduce_func(nodes): msgs = torch.sum(nodes.mailbox['pv'], dim=1) pv = (1 - DAMP) / N + DAMP * msgs return {'pv' : pv}
注册消息函数和规约函数, 之后DGL调用它。 pagerank_naive是page_rank的简单实现。
# 注册消息函数和归约函数,稍后DGL将调用它。 g.register_message_func(pagerank_message_func) g.register_reduce_func(pagerank_reduce_func) def pagerank_naive(g): # Phase #1: send out messages along all edges. for u, v in zip(*g.edges()): g.send((u, v)) # Phase #2: receive messages to compute new PageRank values. for v in g.nodes(): g.recv(v) # 迭代10轮 for k in range(10): pagerank_naive(g) print(g.ndata['pv'])


tensor([0.0446, 0.0107, 0.0087, 0.0102, 0.0085, 0.0130, 0.0091, 0.0059, 0.0079, 0.0088, 0.0082, 0.0087, 0.0098, 0.0087, 0.0100, 0.0092, 0.0065, 0.0168, 0.0064, 0.0106, 0.0098, 0.0117, 0.0077, 0.0113, 0.0111, 0.0100, 0.0077, 0.0051, 0.0084, 0.0070, 0.0048, 0.0163, 0.0102, 0.0084, 0.0098, 0.0127, 0.0101, 0.0091, 0.0091, 0.0083, 0.0088, 0.0095, 0.0132, 0.0106, 0.0057, 0.0099, 0.0068, 0.0106, 0.0098, 0.0068, 0.0140, 0.0087, 0.0083, 0.0120, 0.0107, 0.0109, 0.0072, 0.0090, 0.0069, 0.0124, 0.0094, 0.0106, 0.0071, 0.0093, 0.0070, 0.0059, 0.0068, 0.0162, 0.0082, 0.0129, 0.0063, 0.0134, 0.0116, 0.0095, 0.0107, 0.0147, 0.0085, 0.0099, 0.0084, 0.0069, 0.0112, 0.0120, 0.0076, 0.0105, 0.0125, 0.0091, 0.0063, 0.0085, 0.0051, 0.0102, 0.0116, 0.0070, 0.0120, 0.0094, 0.0156, 0.0159, 0.0096, 0.0125, 0.0065, 0.0107])
大图的批处理语义
上图中的方法需要遍历所有节点,不适合于大图,DGL通过允许在一个batch的节点或边上进行计算来解决此问题。 例如,以下代码一次性触发所有多个节点的消息函数和规约函数。
def pagerank_batch(g): g.send(g.edges()) g.recv(g.nodes()) for k in range(10): #pagerank_naive(g) pagerank_batch(g) print(g.ndata['pv'])
并行性方面: 由于每个节点接受的输出参数是不同的,不同长度的张量没法进行stack。所以DGL按传入消息的数量对节点进行分组,分组调用reduce函数来解决该问题。
使用更高级别的API来提高效率
def pagerank_level2(g): g.update_all()
使用内置API
一些常用的消息函数和规约函数DGL都包含了,直接调用即可。
import dgl.function as fn def pagerank_builtin(g): g.ndata['pv'] = g.ndata['pv'] / g.ndata['deg'] g.update_all(message_func=fn.copy_src(src='pv', out='m'), reduce_func=fn.sum(msg='m',out='m_sum')) g.ndata['pv'] = (1 - DAMP) / N + DAMP * g.ndata['m_sum']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号