

浅析TCMalloc
1.简介
1.1名词解释
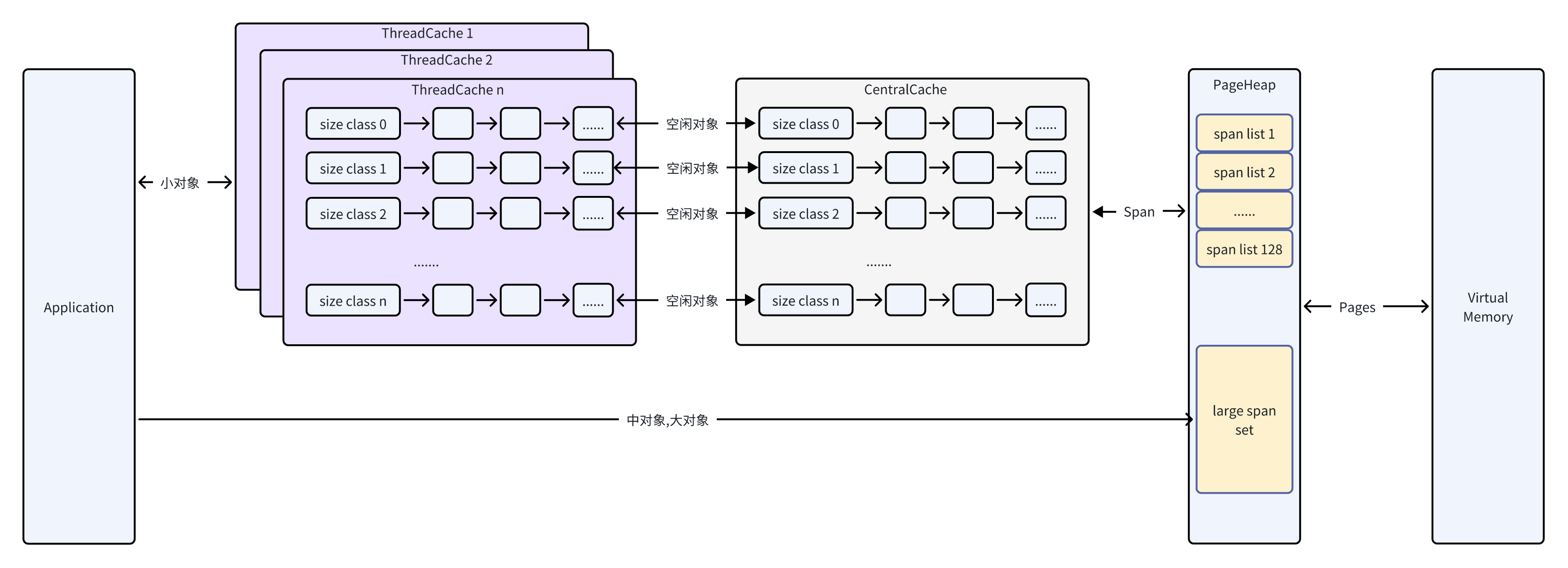
TCMalloc全称Thread-Caching Malloc,即线程缓存的malloc,是Google开发的内存分配器,实现了高效的多线程内存管理器,用于替代系统的内存分配相关的函数(malloc,free,new,new[]等).整个 TCMalloc对内存的管理实现了三级缓存,分别是ThreadCache(线程级缓存),Central Cache(中央缓存:CentralFreeeList),PageHeap(页缓存).
TCMalloc 按照内存大小区间划分为小/中/大三类,由不同的数据结构进行管理。

1.2性能对比
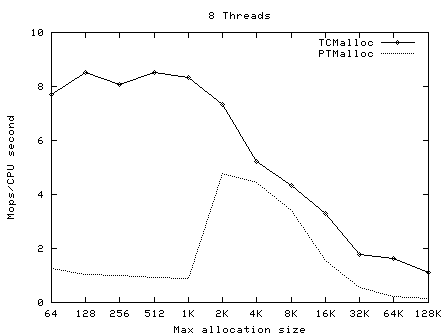
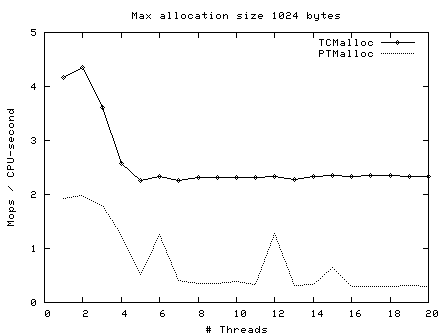
一次malloc和free操作,ptmalloc需要300ns,而tcmalloc只要50ns。同时tcmalloc也优化了小对象的存储,需要更少的空间。tcmalloc特别对多线程做了优化,对于小对象的分配基本上是不存在锁竞争,而大对象使用了细粒度、高效的自旋锁(spinlock)。分配给线程的本地缓存,在长时间空闲的情况下会被回收,供其他线程使用,这样提高了在多线程情况下的内存利用率,不会浪费内存,而这一点ptmalloc2是做不到的。
PTMalloc和TCMalloc的多线程不同大小申请释放测试:
1.3全景图
内存管理可以分为三个层次,从下往上分别是:
- 操作系统内核的内存管理.
- glibc层使用系统调用维护的内存管理算法.
- 应用层从glibc动态分配内存后,根据应用程序本身的程序特性进行优化.比如引用计数std::shared_ptr,内存池.
TCMalloc的层次和大致的内部结构:
![]()
TCMalloc 可以分为三个部分:前端,中端,后端. - 前端是一个缓存,为应用程序提供快速的内存分配和释放.
- 中端负责重新填充前端缓存.
- 后端负责从操作系统获取内存.

2.后端
TCMalloc 的后端有三项工作:
- 管理大块未使用的内存.
- 当没有合适大小的内存可用于满足分配请求时,它负责从操作系统获取内存.
- 将不需要的内存返回给操作系统.
后端的管理内容分两种: - 传统 pageheap,用以管理TCMalloc 页大小块中的内存.
- 大 pageheap,管理大页块内存,使分配器能够通过减少 TLB未命中来提高应用程序性能.
2.1 Page/Span
Page:是内存的基本分配单位,也称为页.大小一般是8KB. TCMalloc按照8KB大小将虚拟内存空间地址划分为N个Page进行管理.PageID由虚拟内存地址直接转换而得.
Span:是由N个连续的Page组成.
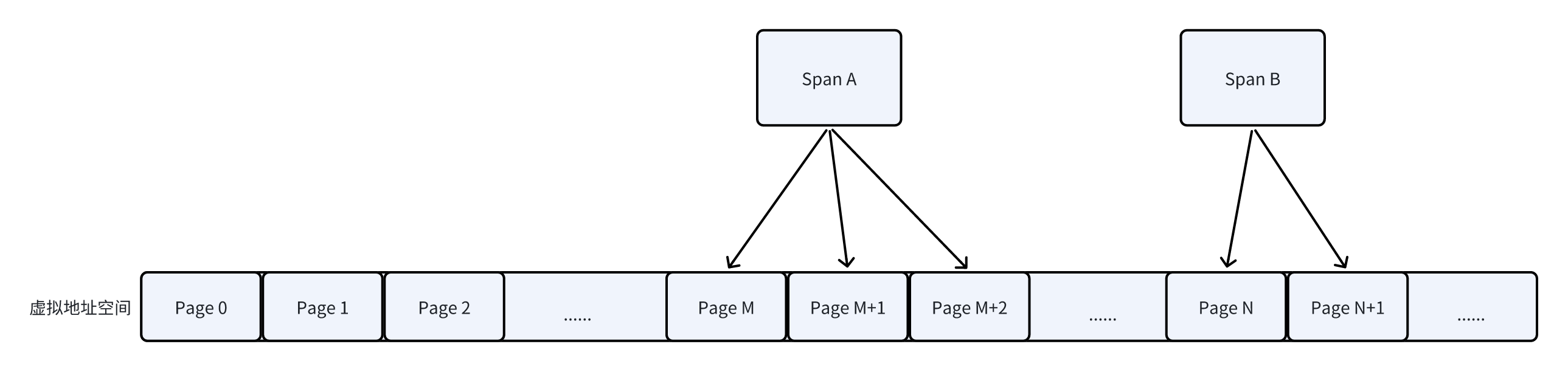
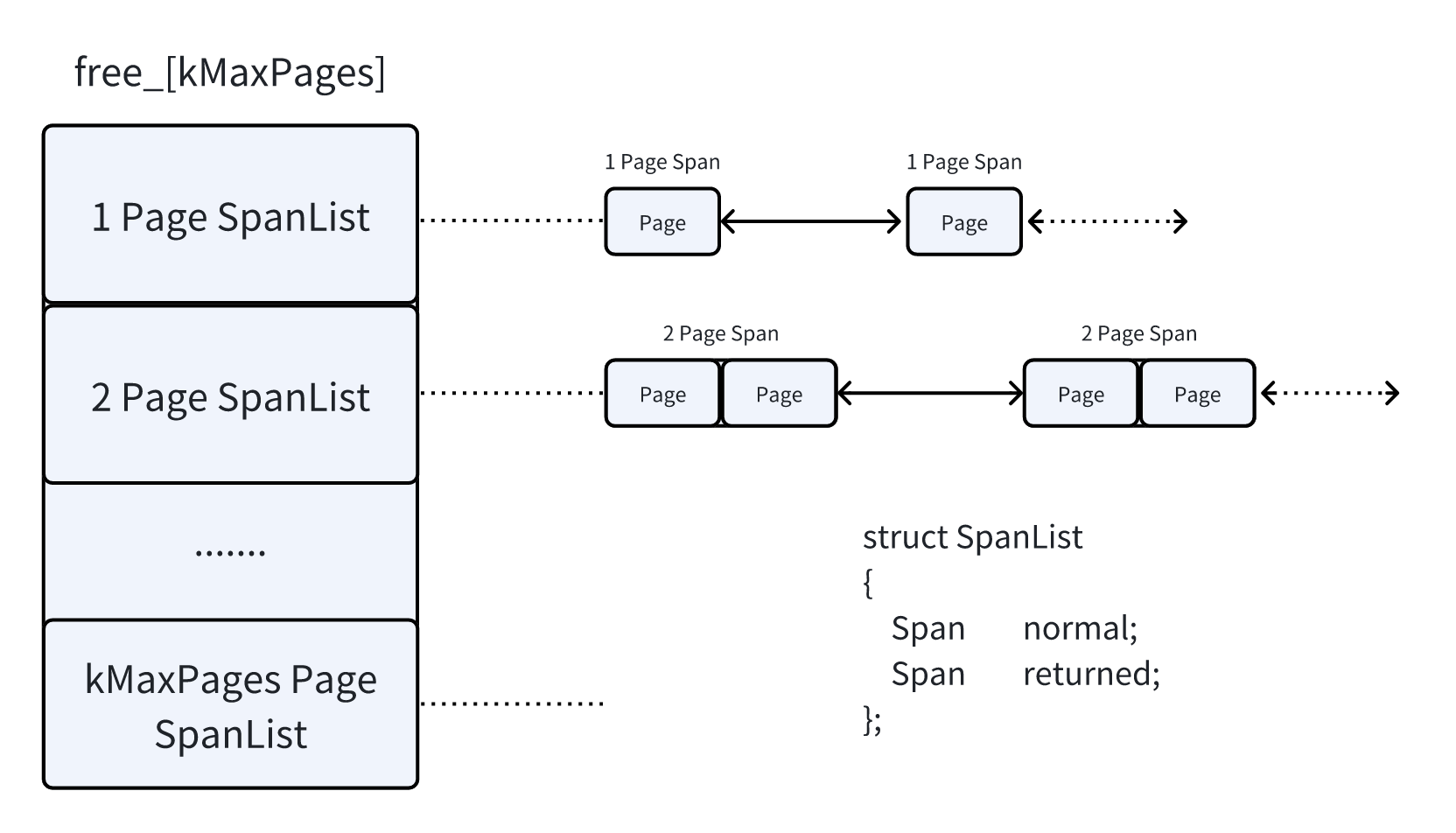
1MB以内的小内存块的Span按照Page数量分类,可以分为128[=1MB/8KB]种,存放在数组SpanList free_[kMaxPages];中.
大于含有1MB的大内存块的Span存放在std::set中.
问: 为什么1MB以内的Span放在数组内?为什么大于1MB的Span存放在std::set中?
Span的定义:
`
// Information kept for a span (a contiguous run of pages).
struct Span {
PageID start; // Starting page number //---> Page开始ID
Length length; // Number of pages in span //---> 连续length个Page
Span* next; // Used when in link list //---> 组成链表
Span* prev; // Used when in link list //---> 组成链表
union {
void* objects; // Linked list of free objects
// Span may contain iterator pointing back at SpanSet entry of
// this span into set of large spans. It is used to quickly delete
// spans from those sets. span_iter_space is space for such
// iterator which lifetime is controlled explicitly.
char span_iter_space[sizeof(SpanSet::iterator)]; //---> 1MB以上的span在set中的位置
};
unsigned int refcount : 16; // Number of non-free objects //---> objects被使用的个数
unsigned int sizeclass : 8; // Size-class for small objects (or 0)
unsigned int location : 2; // Is the span on a freelist, and if so, which?
unsigned int sample : 1; // Sampled object?
bool has_span_iter : 1; // Iff span_iter_space has valid
// iterator. Only for debug builds.
// ......
// What freelist the span is on: IN_USE if on none, or normal or returned
enum { IN_USE, ON_NORMAL_FREELIST, ON_RETURNED_FREELIST }; //---> span当前的状态
};
`
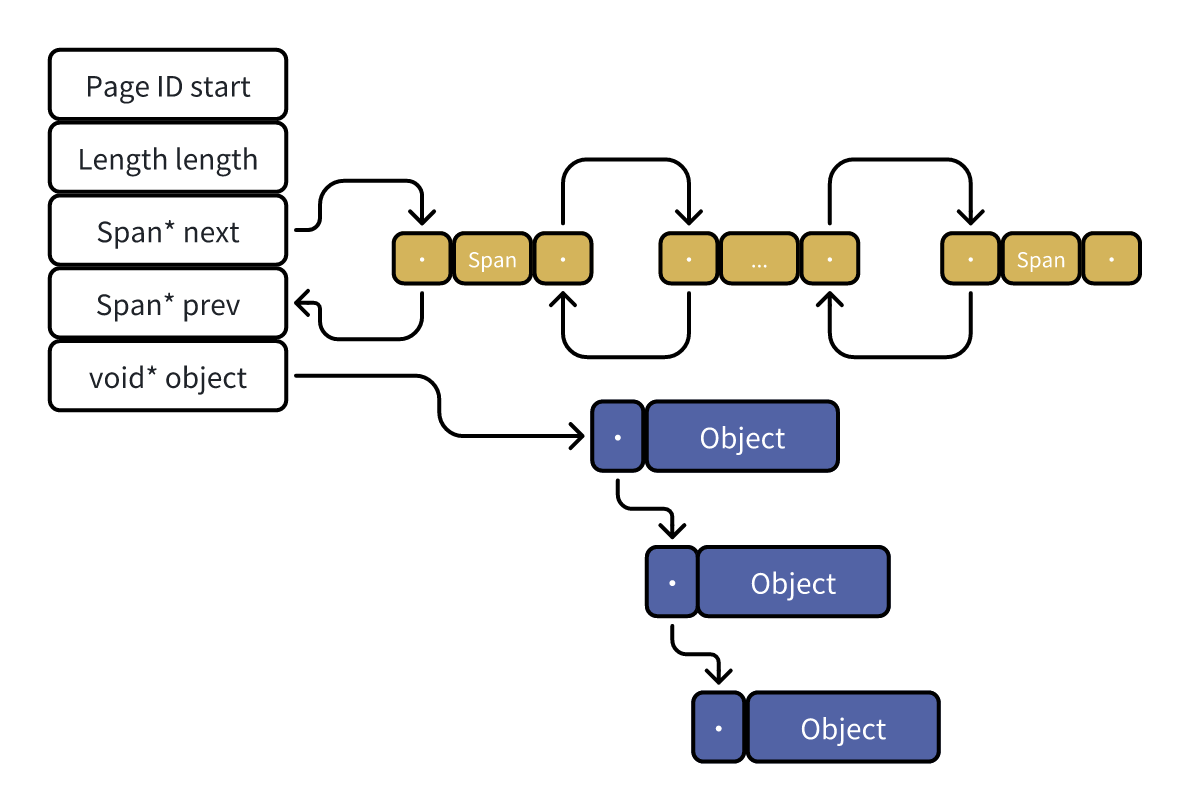
2.2 Object 和 SizeMap
一个Span会被按照某个大小拆分为N个Objects,同时这N个Objects构成一个FreeList[上面图中的 void* object ].
那么这个N是怎么确定的?每个Object的大小是怎么确定的?
答案是依赖代码维护的映射列表.
static constexpr SizeClassInfo kSizeClassesList[kCount] = { // 这里的每一行 称之为SizeClass // <bytes>, <pages>, <batch size> // Object大小列,一次申请的page数,一次移动的objects数(内存申请或回收) { 0, 0, 0}, { 8, 1, 32}, { 16, 1, 32}, { 32, 1, 32}, { 64, 1, 32}, { 80, 1, 32}, { 96, 1, 32}, { 112, 1, 32}, { 128, 1, 32}, // ....... { 155648, 19, 2}, { 172032, 21, 2}, { 188416, 23, 2}, { 204800, 25, 2}, { 221184, 27, 2}, { 237568, 29, 2}, { 262144, 32, 2}, }
通过 SizeMap,对小内存继续细分。SizeMap 将用户申请的不超过 256K 的内存大小映射到 2175 种对齐的大小类型(size class),最小 8 字节,最大 256K,并记录了大小类型到 num_objects_to_move、class_to_pages 的映射关系。
上层想申请的内存块大小如何映射到 kSizeClassesList 呢?
`
// Examples:
// Size Expression Index
// -------------------------------------------------------
// 0 (0 + 7) / 8 0
// 1 (1 + 7) / 8 1
// ...
// 1024 (1024 + 7) / 8 128
// 1025 (1025 + 127 + (120<<7)) / 128 129
// ...
// 32768 (32768 + 127 + (120<<7)) / 128 376
static inline size_t SmallSizeClass(size_t s) {
return (static_cast<uint32_t>(s) + 7) >> 3;
}
static inline size_t LargeSizeClass(size_t s) {
return (static_cast<uint32_t>(s) + 127 + (120 << 7)) >> 7;
}
`
2.3 PageMap
Span中存在着指向page的索引,但如果想把被释放的span合并为更大的span,还需要知道被释放的span拥有的page前后的page所在的span.也即需要page到span的映射.
目前x86_64处理器在内存虚拟地址到物理地址转换中只查看低48位,高16位与第47位一致。
pagemap_,即PageID和它所属Span映射表;64位内存地址,除去8K页配置(13位)和地址高16位不使用,剩余35位(64-13-16=35)分为12位、12位、11位构成三级Radix Tree结构。
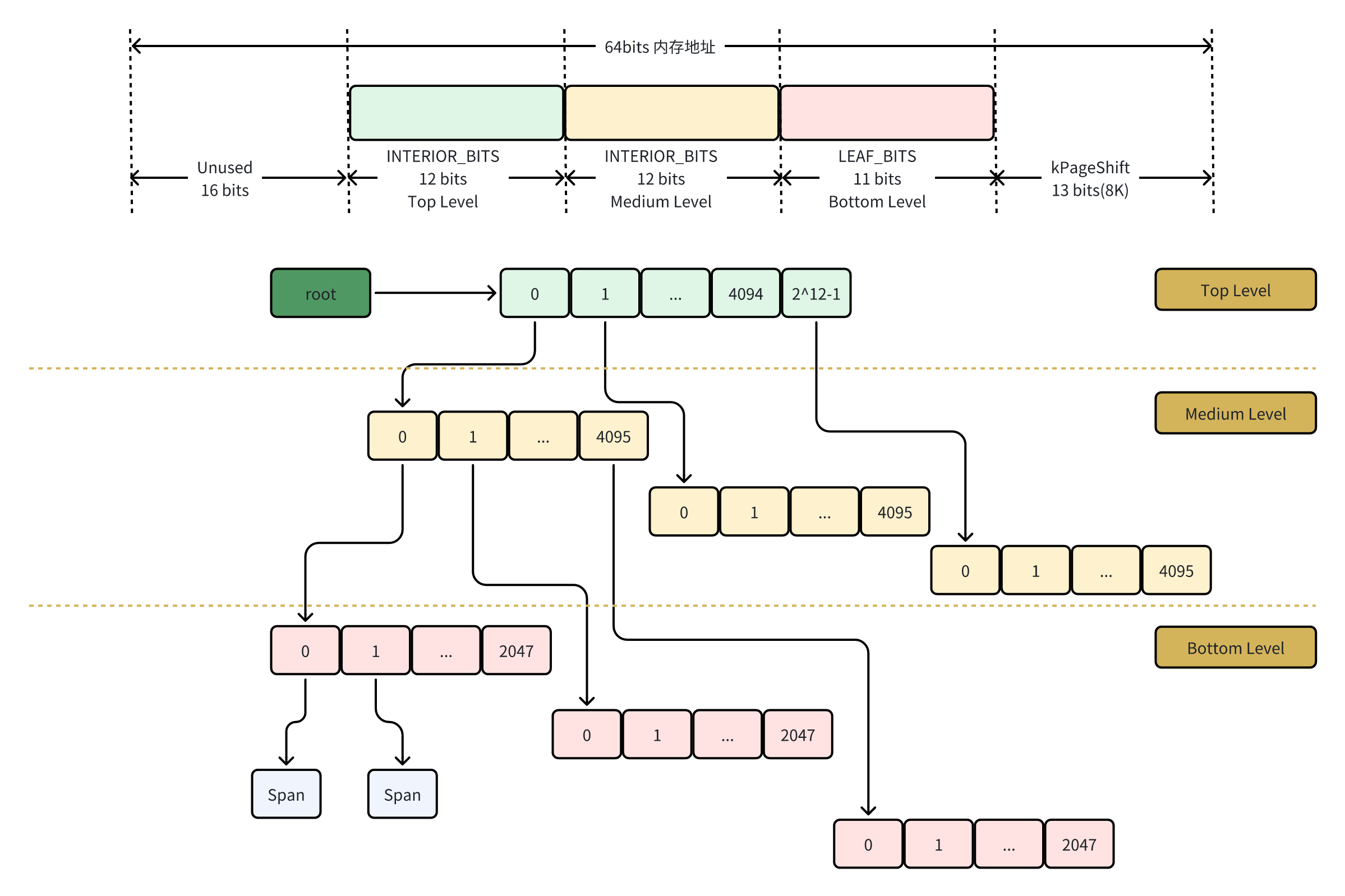
`
// pagemap_检索示例
const PageID p = reinterpret_cast<uintptr_t>(ptr) >> kPageShift;
Span* span = Static::pageheap()->GetDescriptor(p);
Span* GetDescriptor(PageID p) const {
return reinterpret_cast<Span*>(pagemap_.get(p));
}
void* get(Number k) const {
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH-1);
const Number i3 = k & (LEAF_LENGTH-1);
if ((k >> BITS) > 0 ||
root_.ptrs[i1] == NULL || root_.ptrs[i1]->ptrs[i2] == NULL) {
return NULL;
}
return reinterpret_cast<Leaf*>(root_.ptrs[i1]->ptrs[i2])->values[i3];
}
`
2.4 PageMapCache
PageMapCache 即记录PageID和它对应SizeClass映射。其结构(PackedCache)使用kHashbits、kValuebits、kKeybits相关位数进行标识,实现是一个包含2^16(kHashbits=16)个entry数组,entry内容由Key | Value组成,有效位数分别为kKeybits - kHashbits | kValuebits(kKeybits为kAddressBits-kPageShift,64-13=51; kValuebits=7)。
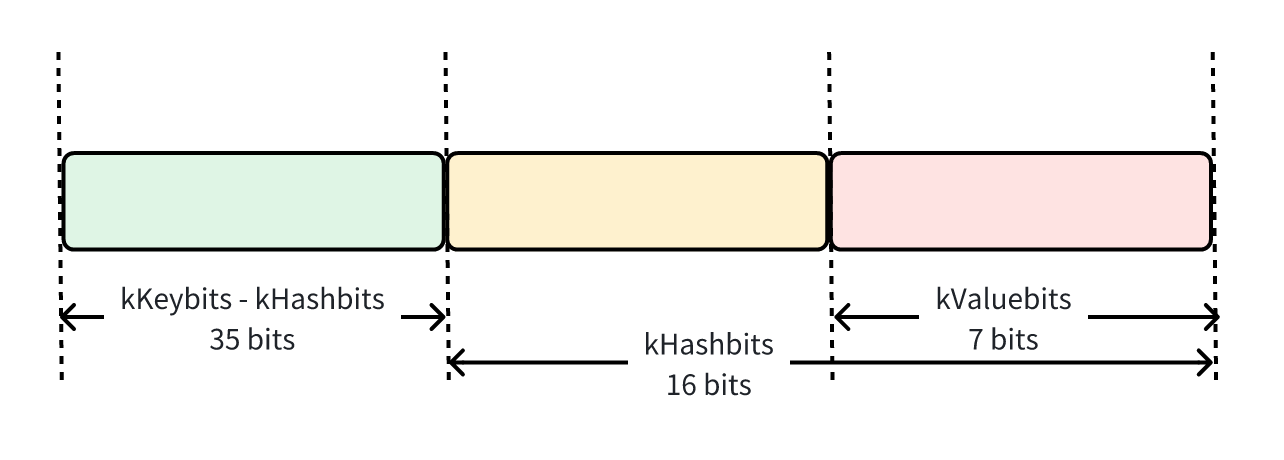
`
// pagemap_cache_检索示例
Static::pageheap()->TryGetSizeClass(p, &cl)
bool TryGetSizeClass(PageID p, uint32* out) const {
return pagemap_cache_.TryGet(p, out);
}
class PackedCache {
public:
typedef uintptr_t T;
typedef uintptr_t K;
typedef uint32 V;
static const int kHashbits = 16;
static const int kValuebits = 7;
bool TryGet(K key, V* out) const {
T hash = Hash(key);
T expected_entry = key;
expected_entry &= ~N_ONES_(T, kHashbits);
T entry = array_[hash];
entry ^= expected_entry;
if (PREDICT_FALSE(entry >= (1 << kValuebits))) {
return false;
}
*out = static_cast
return true;
}
void Put(K key, V value) {
ASSERT(key == (key & kKeyMask));
ASSERT(value == (value & kValueMask));
array_[Hash(key)] = KeyToUpper(key) | value;
}
}
`
2.5 SpanSet
SpanSet 在后端中用于存储大于等于1MB的内存块.当APP申请的内存块大小在SizeMap中找不到对应的SizeClass时,就直接从后端找,而不经过ThreadCache->中端->后端这个路径去寻找.
typedef std::set<SpanPtrWithLength, SpanBestFitLess, STLPageHeapAllocator<SpanPtrWithLength, void> > SpanSet;
2.6 PageHeap
至此,包含 SpanList,SpanSet,PageMap,PageMapCache的PageHeap脉络就清晰了.

3.中端
中端负责向前端提供内存,并向后端返回内存.中端包括传输缓存和中央空闲列表.每个大小类别都有一个传输缓存和一个中央空闲列表.
3.1 Transfer Cache
当前端的ThreadCache 请求或者返回符合其对应的SizeClass个Object时,则直接从TCEntry数组中取出或者放入一个TCEntry.其他情况:
1.获取object,从 noneempty_中找空闲object.
2.归还object,从object地址找出其对应的span,归还到其object链中.
Transfer Cache 主要用于内存在两个不同的CPU/线程之间快速流动.
当请求和返回的个数不等于其对应的SizeClass个Object时,则对empty_或其对应的Span进行操作.
3.2 Central Free List
中央空闲列表包含 empty_ 和 nonempty_两个 dummy head.
- 当前端向中端申请Object时
从 nonempty_ 链表中的span顺序找object,从每个span中找到可用的object,就穿到结果链表中.被掏空object的span就放入 empty_ 链表中.如果所有span都找过了,还是不够.就从后端申请 npages 内存作为一个span插入到empty_中供取用。
问:npages的n是怎么确定的?
- 当前端向中端释放Object时
对于释放的Object链中的每个Object,根据其地址找到对应的Span.将Object插入其Span中.如果此Span的所有Object都归队了,则将此Span从CentralFreeList链中摘出,返还给后端.
问: Object如何根据地址找到其对应的Span?
![]()

3.3 锁
中端用的锁有两种:pageheap_lock和 CentralFreeList锁.
pageheap_lock:中端向后端申请span和释放span的时候,后端不自己加锁,而是中端
使用此锁.
CentralFreeList锁:每种Class size 的CentralFreeList都拥有一把锁,这把锁是在操作TCEntry
和Span时使用.涉及到后端操作时,会释放掉,然后使用pageheap_lock.
4.前端
4.1数据结构
在多线程的场景下,所有线程都从CentralCache 分配的话,竞争可能相当激烈。TCMalloc 给每个Thread/CPU都做了一个局部的 ThreadCache.
- 当外界申请内存时
就从对应的class size中pop出对应个数的Object,不够则从中端拿. - 当外界释放内存时
存入对应的class size的Object链表中,如果超出了链表最大长度,则返还给中端.
![]()

4.2 per-Thread/per-CPU
前端最初支持object的每个线程缓存(名字的由来:Thread Caching Malloc).但是这回导致内存占用随线程数量的增加而增加.现代应用程序可能具有大量的线程,这就会导致:
- 要么大量的TheadCache,造成内存浪费.
- 要么大部分线程具有极小的 caches,极小的caches会导致频繁地向 middle-end 申请和释放内存,性能变差.
google库里的TCMalloc 支持 per-CPU模式.这种模式下,系统中的每个逻辑CPU都有自己的缓存.
![]()
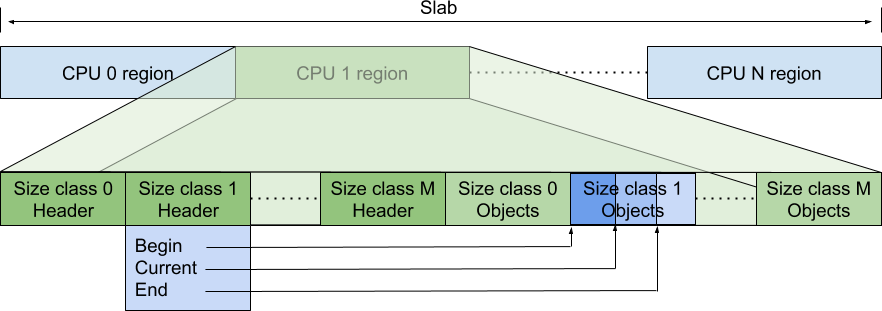
4.3 锁
前端操作不是号称无锁的吗?怎么还会用到锁?
- 这里的锁用的是pageheap_lock作为一个全局锁.用于ThreadCache本身的创建/初始化/销毁的时候加锁.
- 每个ThreadCache不是孤立的,而是链表串起来的,并且每个ThreadCache的max_size_是动态变化的.当一个ThreadCache的长度超长后,除了向中端释放一些object,还会从其他ThreadCache偷kStealAmount长度加到自己的max_size_上,此时需要pageheap_lock加锁.
5.总结
APP申请内存:
- 小对象,根据申请的内存块的大小,确定SizeClass,从对应的ThreadCache中找出对应数量的Object,如果Object不足,则从CentralFreeList的span链表中搜集M个Object到ThreadCache中.如果CentralFreeList中的Span都空了,则从PageHeap寻找N个page的Span,找不到则在N+1个Page的Span,直至大内存Span中寻找,如果仍然找不到,就尝试把空闲的大小span都标记释放,引起合并,再找.如果还找不到则向系统申请内存.
- 大对象,越过ThreadCache和CentralCache,直接从PageHeap中寻找Pages.
APP释放内存: - 小对象,根据PageMapCache,获取SizeClass,将内存块还给ThreadCache,如果超出最大长度,则返还M个Object到CentralCache中,每个Object插入到自己的Span中,如果Span所有的Object都归队了,就返还给后端删除/合并入空闲队列.
- 大对象,删除对应的span,如果前/后也有span,就合成更大的span存入SpanSet中[默认行为.也可以设置为返还给系统].

 浙公网安备 33010602011771号
浙公网安备 33010602011771号