


数据库的定义、作用介绍:
什么是数据库?
按照数据结构来组织、存储和管理数据的建立在计算机存储设备上的仓库。
数据库的发展史:
起始于1962年,1968年在IBM出现
数据库在测试过程中的作用:
需求分析阶段:了解测试环境数据库、表、数据等信息、需求
用例设计阶段:测试数据准备
用例执行阶段:测试数据构造、测试结果数据检查、代码逻辑查看
自动化测试:测试脚本、数据、工具
性能压力测试:数据准备、性能数据分析
测试环境搭建:维护数据库、执行配置脚本、备份恢复数据库等
数据库的分类:
层次式数据库
网络式数据库
关系式数据库(常用)
关系型数据库:
常用:
Oracle:Oracle(甲骨文)公司,多平台,性能最高,获得最高安全认证,适用大型
DB2:IBM公司,多平台,性能较高,获得最高安全认证,企业级应用最广
SQL Server:微软、windows平台,中小型网站和电子商务办公系统
MySQL:瑞典my sql AB公司,多平台,开源,中小型网站开发
Access:微软、windows平台,小型系统使用
MariaDB:MySQL的一个分支,完全兼容MySQL,包括API和命令行,使之能够成为MySQL的代替品
不常用:
Informix,Sybase,PostgreSQL
非关系型数据库:
常用:
Redis:开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型数、Key-Value数据库,并提供多种语言的PI
MongoDB:基于分布式文件存储的数据库。有C++语言编写,旨在为WEB应用服务器扩展的高性能数据存储解决方案。支持的查询语言非常强大,单表查询的绝大部分性能,而且还支持对数据建立索引。
Memcached:是一个高性能的分布式内存对象缓存系统,用于动态Web应用数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高数据库驱动网站的速度。
Cassandra:一个开源的、分布式、无中心、支持水平扩展、高可用的KEY-Value的NOSQL数据库。
不常用:
HBase、MemacheDB、BerkeleyDB、Tokyo Cabinnet
Oracle介绍:
公司简介:全称甲骨文股份有限公司(甲骨文软件系统有限公司),是全球最大的企业级软件公司(被成为“纯软件公司的先驱”。在个人计算机领域,靠卖软件赚钱的公司),总部位于美国加利福尼亚州的红木滩,其创始人是拉里诶里森。
市场份额:Oracle(54%)、IBM-DB2(21%)、MicrosoftMSQL(14%)
相关认证:OCM认证【大师】、OCP认证【专家】、OCA认证【专员】等
版本:免费版、标准版、标准版2、企业版
Oracle Server主要文件目录介绍:
admin:主要存放数据库运行过程中产生的跟踪文件(后台进程,用户sql语句)
bin:包含数据库管理各种命令
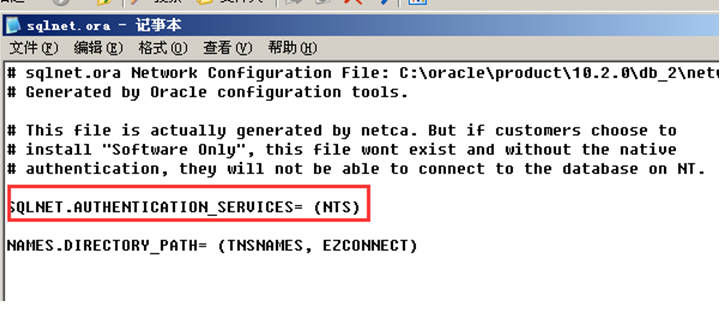
ADMIN重要:里面有监听文件(listence.ora tnsnames.ora sqlnet.ora)
Db_1:服务器数据库文件夹,代表Oracle目录树的根, 它包含与Oracle软件运行有关的子目录和网络文件以及选定的组件等
Oradata:数据库物理文件存储在oradata/db_name目录下,该目录主要存储数据库的控制文件、数据文件、重做日志文件。其中*.dbf文件对应数据库中每个表空间;.ctl文件为控制文件;.log文件对应重做日志文件组及其成员
Flash_recovery_area:目录存储并管理与备份和恢复有关的文件。它包含系统中每个数据库的子目录。该目录可用于存储与恢复有关的文件,如控制文件、联机重做日志副本、归档日志、闪回日志以及Oracle数据库恢复管理器(RMAN)备份等。

adump:一般是audit dump
bdump:中有alert文件,和一些后台进程的trace file,bdump文件下放着的是数据库的预警文件,如果数据库出问题,该文件是DBA要查看的首选文件
cdump:一般放置一些核心的trace文件
udump:放着的是用户进程跟踪文件,用于收集客户应用的SQL语句的统计信息。
pfile:文件下放着的自然是数据库的初始化参数文件。
注:如果觉得oracle卡了 ,可以把bdump和udump文件夹下文件删除
Oracle Client主要文件目录介绍:
ORACLE_HOME主要包括的子目录有:
BIN--主要包含用于数据库管理的各种命令等
cdd--与Oracle Cluster Synchronization服务有关的文件
dbs--存放数据库实例模式的脚本等
demo--存放数据库实例模式的脚本等
install--用于存储ORACLE安装后的端口号,iSQL*PLUS以及Enterprise Manager
Database Control启动并登录的方式等
NETWORD\ADMIN--有关监听器listener.ora和sqlnet.ora以及tnsnames.ora等
config--用于与Oracle Enterprise Menagement有关的端口管理等
database--初始化参数与口令文件
Oracle两种用户认证方式:
Sqlnet.authentication_services=(NTS)|(NONE)
NTS:操作系统认证方式,不使用口令文件;
NONE:口令文件认证方式
访问Oracle数据库四种方法:sql*plus工具、dos窗口sqlplus、isql、plsql
Cmd>regedit 进入注册表编辑器快捷命令,红框显示oracle注册信息
Oracle版本号的含义
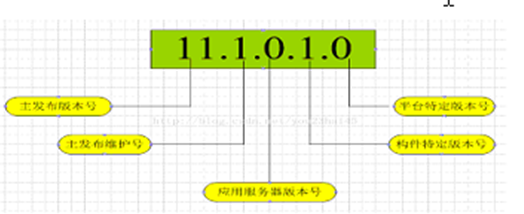
Oracle产品版本号由5部分数字组成
1、主发布版本号:是版本的最重要的标识号,表示重大的改进和新的特征
2、主发布维护号:维护版本号,一些新的特性的增加和改进
3、应用服务器版本号:Oracle应用服务器的版本号
4、构件特定版本号:针对构件升级的版本号
5、平台特定版本号:标识操作系统平台相关的发布版本
1)Oracle主要版本
Oracle
Oracle 8/Oracle 8i(1CD):“i”表示internet,表示Oracle开始进军网络
Oracle 9i(3CD):属于Oracle 8i的稳定版本,现在依然大范围使用(使用率非常高,因为正好是中国进行电子化信息改革的开始)
Oracle 10g(630M):“g”表示网格Grid技术,使用了网络计算的方式,提升了数据库的分布式的访问性能
Oracle 11g(1.7G):属于Oracle 10g的稳定版本,现在新项目使用较多
plsql语句(Structured Query Language:结构化查询语言)
一、sql编写规范
明确规范
- sql语句的所有表名、字段名全部小写,系统保留字、内置函数名、sql保留字大写。
- 连接符or、in、and、以及=、<=、>= 等前后加上一个空格。
- 对较为复杂的sql语句、过程、函数加上注释,说明算法、功能。
- SQL 语句的缩进风格
1. 一行有多列,超过80个字符时,基于列对齐原则,采用下行缩进
2. where子句书写时,每个条件占一行,语句另起一行时,以保留字或者连接符开始,连接符右对齐。
多表连接时,使用表的别名来引用列。
其他注意事项
SQL 命令是大小写不敏感
- SQL 命令可写成一行或多行
- 一个关键字不能跨多行或缩写
- 子句通常位于独立行,以便编辑,并易读
二、SQL语言基础
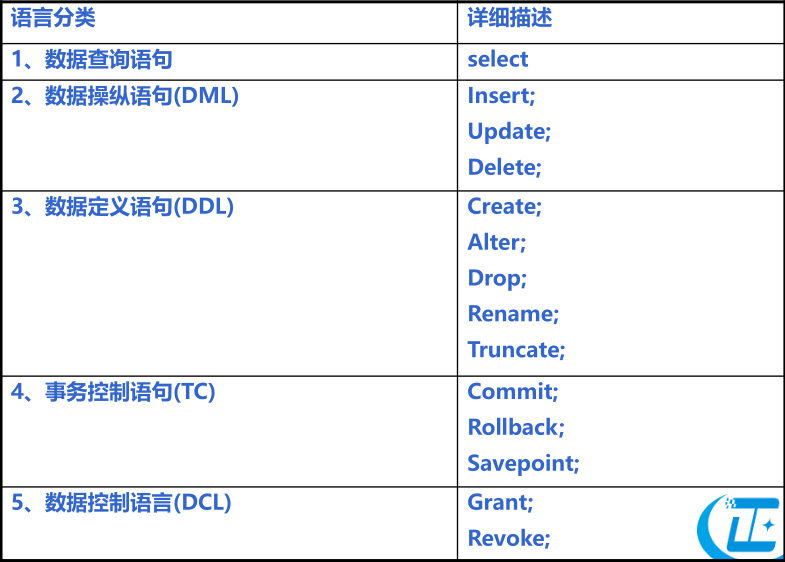
SQL语言分类
SQL语句规则
- SQL 语句是大小写不敏感
- SQL 语句可写成一行或多行
- 一个关键字不能跨多行或缩写
- 子句通常位于独立行,以便编辑,并易读
- 空格和缩进使程序易读
- 关键字大写,其他小写
算数表达式:
对NUMBER和DATE型数据可用算数运算创建表达式

例如:select sal+800 from emp;
select sal-200 from emp;
select sal*5 from emp;
select sal/3 from emp;
运算优先级:
乘法和除法的优先级高于加法和减法
同级运算的顺序是从左到右
表达式中使用括号可强行改变优先级的运算顺序
定义空值
空值指不可用,不知道,不实用的值
空值不等于零或空格
包括空值的算数表达式等于空
定义列的别名
改变列的标题头
使用计算结果
列的别名
如果使用特殊字符,或大小写敏感,或有空格时,需加双引号
例如 select ename as name from emp;或select ename name fromemp;
连结操作
将列或字符与其它列连结
用双“||”表示
产生的结果列是一个字符表达式
例如:
SELECT ename||job AS "Employees" FROM emp;
文字字符串
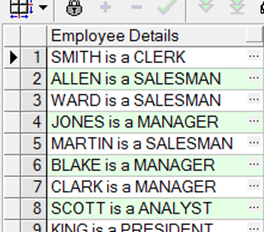
文字字符串是一个包括在SELECT列表中的字符,表达式,或数字
日期和字符型文字字符必须用单引号括起来
每返回一条记录字符被输出一次
例:SELECT ename ||' '||'is a'||' '||job AS "Employee Details" FROM emp;
|
构造命令
SELECT 'delete from '||table_name||' where 1=0;'||chr(10)
FROM user_all_tables;
显示:
delete from CUSTOMERS where 1=0;
delete from PRODUCT_TYPES where 1=0;
delete from PRODUCTS where 1=0;
delete from PURCHASES where 1=0;
delete from EMPLOYEES where 1=0;
……………
……………
重记录:
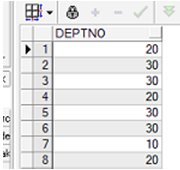
缺省情况下查询显示所有行,包括重行
例:SELECT deptno FROM emp;
显示有重复信息
|
不想要重复 用distinct(去重),具体为select distinct deptno from emp;
但是distinct操作会引起排序,通过排序去掉重复记录。
描述表结构
打开command windows , 输入"desc 表名",显示表结构(不能在sql windows中使用)
三、限定和排序数据
-
限制某一查询所取记录
-
排序查询结果
限定所选的条件
使用where限定查询条件
select [distinct]* from emp where deptno = 20 and mgr = 7788
注:from子句在where子句之后
字符串和日期
-
字符串和日期要用单引号扩起来
-
字符串是大小写敏感的,日期值是格式敏感的
-
缺省的日期格式是 'DD-MON-YY'
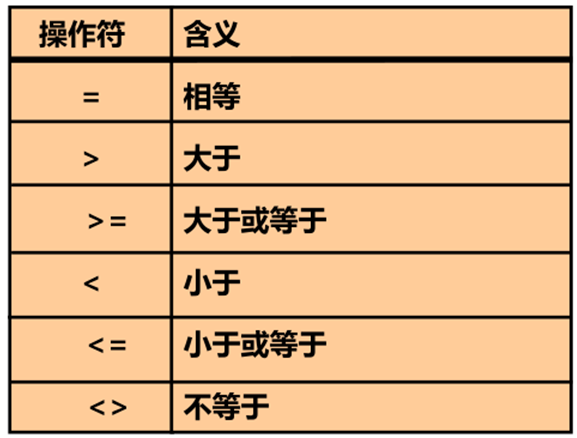
比较运算符
|
|

使用比较运算符
|
|
|
|

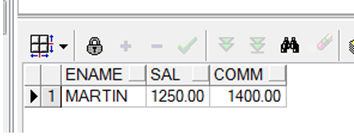
注:空值是直接不参与计算
其它的比较运算符
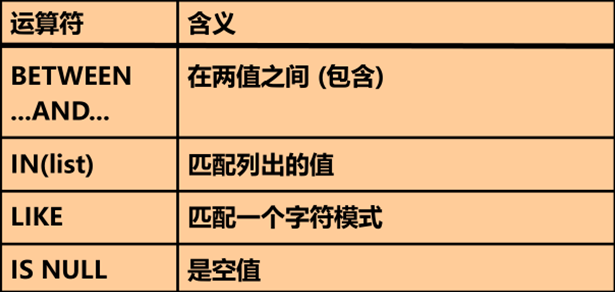
注:
between默认从小到达,不能输例如“between 1000 and 800”
使用BETWEEN运算符显示某一 值域范围的记录
注:
between默认从小到达,不能输例如“between 1000 and 800”
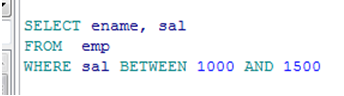
in的使用
使用IN运算符获得匹配列表值的记录
in 示例:

LIKE使用
使用LIKE运算符执行通配查询
查询条件可包含文字字符或数字
(%) 可表示零或多个字符
( _ ) 可表示一个字符
like 示例:
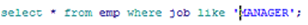
或

使用组合方式匹配字符
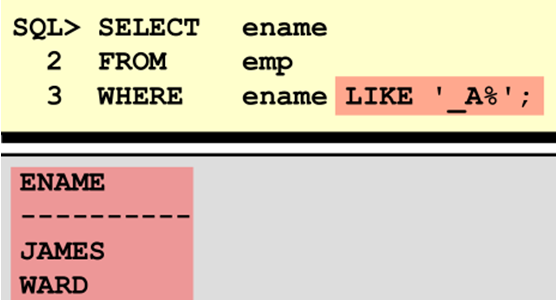
使用ESCAPE 标识符来查找带特殊符号的字符号

is null 使用
查询包含空值的记录
运算逻辑符
|
|
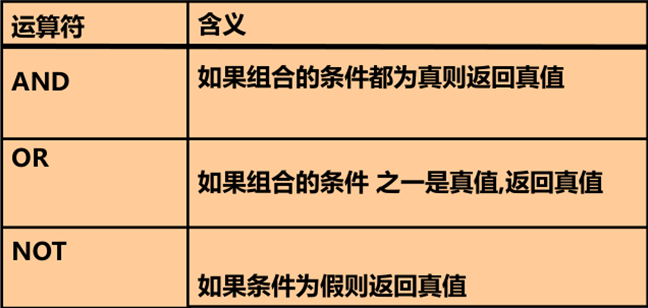
使用AND
AND需要条件都为TRUE
|
|
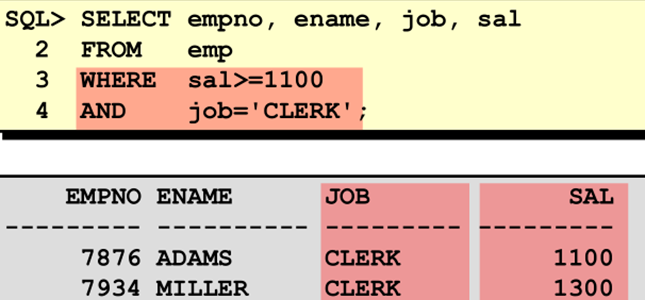
OR 运算符
OR需要条件之一是TRUE
|
|
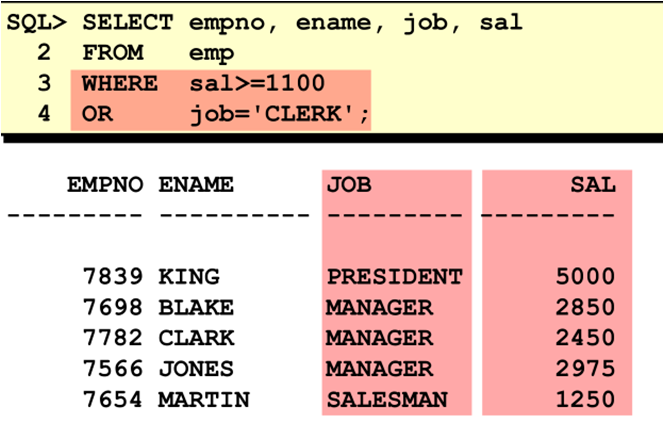
使用not in 运算符
|
|
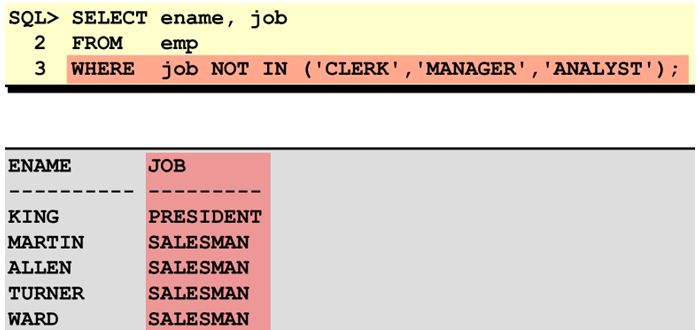
优先级规则
括号将跨越所有优先级规则
|
|
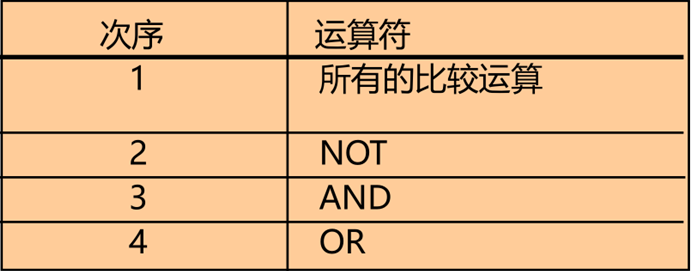
ORDER BY 子句
使用ORDER BY 子句将记录排序
-
ASC: 升序,缺省
-
DESC: 降序
ORDER BY 子句在SELECT语句的最后
降序排列:
|
|

使用列的别名排序
|
|

使用中文字符的别名排序
|
|

注:
-
按中文拼音进行排序:SCHINESE_PINYIN_M
-
按中文部首进行排序:SCHINESE_RADICAL_M
-
按中文笔画进行排序:SCHINESE_STROKE_M
通过ORDER BY 列表的顺序来排序
|
|
四、单组函数
-
描述可在SQL 中使用的各种函数
-
在SELECT语句中使用字符,数字,日期函数
-
描述转换函数的使用
函数过程
|
|
两种SQL函数
|
|
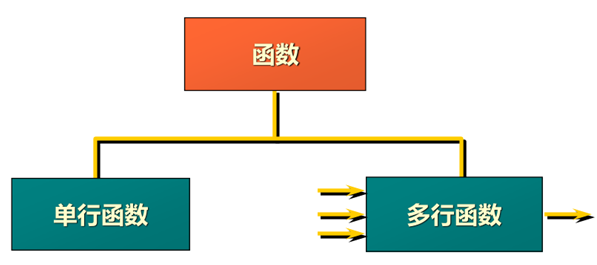
单行函数
-
操作数据项
-
接受参数并返回一个值
-
对每一返回行起作用
-
每一行返回一个结果
-
可修改数据类型
-
可使用嵌套
字符函数
|
|
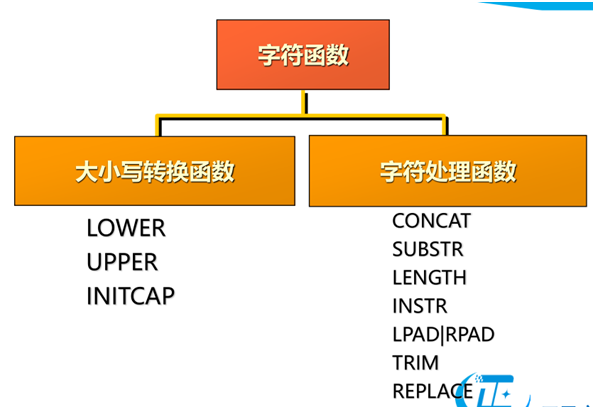
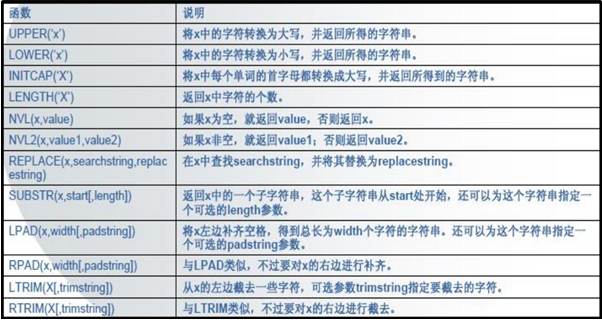
字符函数说明
使用大小写转换
显示员工号,名字,部门号
|
|
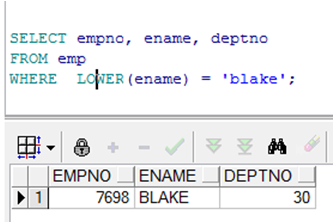
使用字符处理函数
|
|
|
|

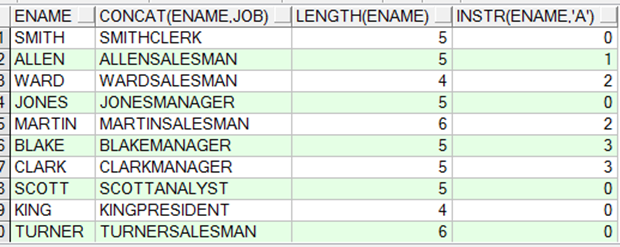
instr 找到字符位置 这里是找ename中A的位置
concat 连接两个字段
substr substr(字段名,a,b) 以“字段名”为基础,从第a个字符开始截取b个字符串
数字函数
|
|
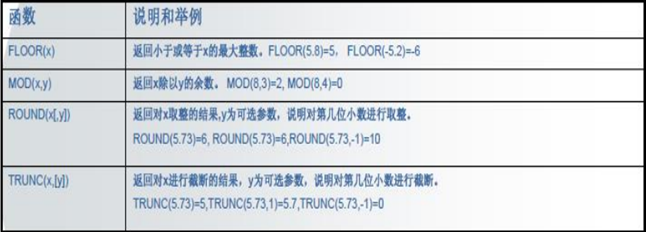
floor 向下取整
mod 取余数
round 默认个位取整,加条件确认取整位数(4舍五入)
trunc 去尾取整
示例:
SELECT FLOOR(5.8),FLOOR(-5.8) FROM dual;
SELECT MOD(8,3), MOD(8,4) FROM dual;
SELECT ROUND(5.73), ROUND(5.73),ROUND(5.73,-1) FROM dual;
SELECT TRUNC(5.73),TRUNC(5.73,1),TRUNC(5.73,-1) FROM dual;
日期
Oracle以内部数字格式存储日期:世纪,年,月,日,小时,分钟,秒
缺省的日期格式是 DD-MON-YY
SYSDATE 是返回日期和时间的函数
DUAL是用来查看SYSDATE的虚表
日期的运算
|
|
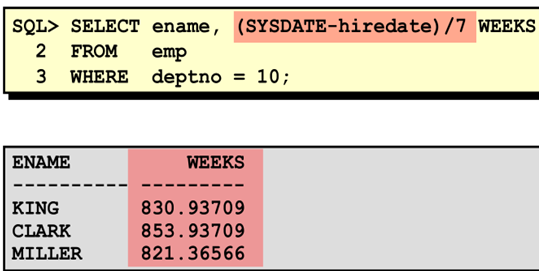
日期函数
|
|
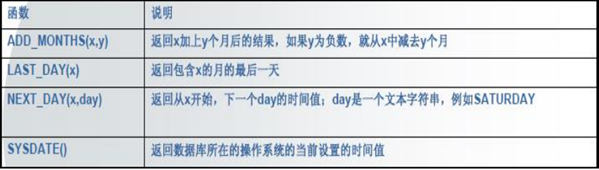
SELECT ADD_MONTHS('08-AUG-2007',13) FROM dual ;
SELECT LAST_DAY('08-AUG-2007') FROM dual;
SELECT NEXT_DAY('08-AUG-2007','SATURDAY') FROM dual;
SELECT SYSDATE FROM dual;
默认的日期格式是在数据库参数NLS_DATE_FORMAT中指定的,DBA可以修改
NLS_DATE_FORMAT的设置,方法是在数据库的init.ora或者spfile.ora文件中修改,当然更方便的方法是使用ALTER SESSION命令在SQL *Plus中修改,例如:ALTER SESSION SET
NLS_DATE_FORMAT='MONTH-DD-YYYY';
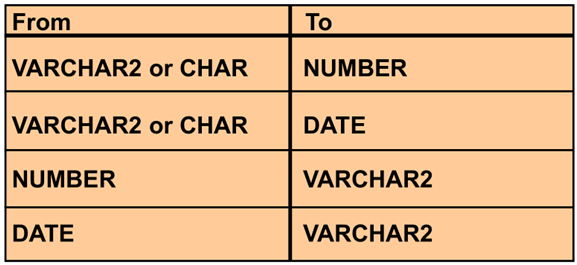
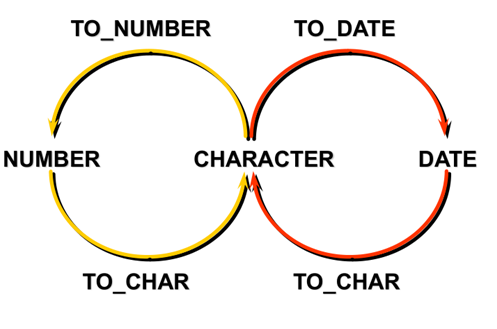
转换函数
|
|
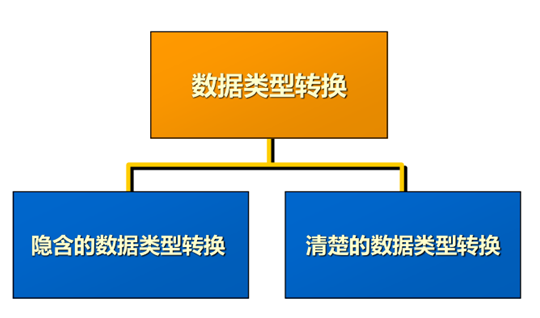
隐含的数据转换类型
-
作为赋值,Oracle可自动转换
|
|
-
表达式可自动转换数据类型
|
|
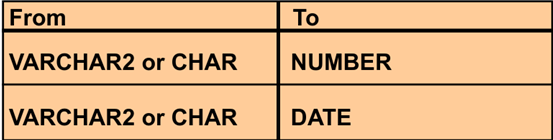
清楚的数据类型转换
|
|
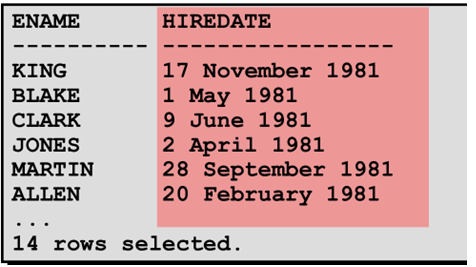
TO_CHAR 函数操作日期
|
|

格式规则
-
必须用单引号括起来,并且是大小写敏感
-
可包含任何有效的日期格式
-
有一个fm元素 用于填补空格或禁止前面的零
-
使用逗号分离日期值
日期格式基础
|
|
TO_CHAR函数处理日期
|
|
|
|

TO_CHAR函数处理数字
|
使用TO_CHAR函数将数字作为字符显示 |
|
|
|
|
|
|




TO_NUMBER和TO_DATE函数
使用TO_NUMBER函数将字符转换为数字
|
|

使用TO_DATE函数将字符转换为日期
|
|
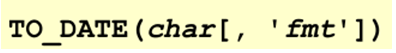
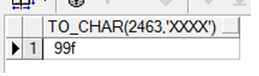
进制转换
-
十进制与十六进制
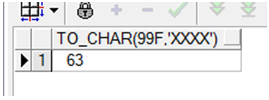
SQL > select to_char(2463,'xxxx') from dual;
TO_CH
-----
99f
已选择 1 行。
-
十六进制与十进制
SQL> select to_number(99f,'xxxx') from dual;
TO_NUMBER('99F','XXXX')
-----------------------
2463
已选择 1 行。
|
|
|
|
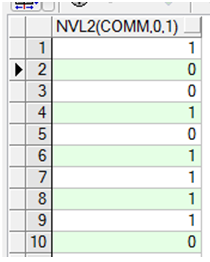
NVL函数
-
将空值转换为实际的值
数据格式可以是日期,字符,数字
数据类型必须匹配
NVL(comm,0)
NVL(hiredate,'01-JAN-97')
NVL(job,'No Job Yet')
NVL函数2
NVL2(expr1,expr2,expr3)
如果expr1不为Null,返回expr2,如果expr1为Null,返回expr3。
expr1可以为任何数据类型
示例:
NVL2(comm,0,1)
|
|
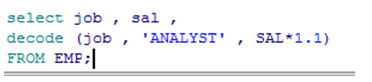
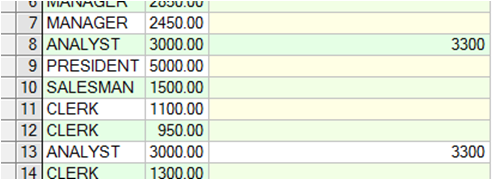
decode函数
DECODE函数类似于一系列CASE 或 IF-THEN-ELSE 语句
|
|
|
|
嵌套函数
-
单行函数可被嵌入到任何层(函数中套函数)
-
嵌套函数从最深层到最低层求值
示例:
SELECT ename,
NVL(TO_CHAR(mgr),'No Manager')
FROM emp
WHERE mgr IS NULL;
|
|

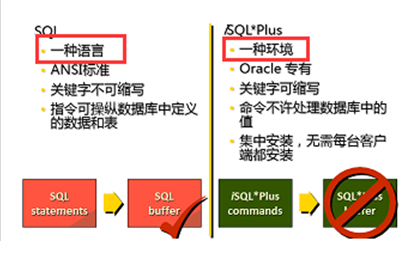
SQL指令和sql*plus命令的区别
|
|
iSQL*Plus概述
➢ 登陆到 iSQL*Plus
➢ 描述表的结构
➢ 编辑SQL语句
➢ 从iSQL*Plus执行SQL
➢ 将SQL语句保存或追加到文件中
➢ 执行存储的文件
➢ 从文件将SQL语句调到缓冲区编辑
SQL*Plus 的编辑命令
|
➢ I[NPUT] 输入SQL语句 ➢ I[NPUT] text ➢ L[IST] 显示SQL语句 ➢ L[IST] n ➢ L[IST] m n ➢ R[UN] 执行SQL语句 ➢ n ➢ n text ➢ 0 text |
➢ A[PPEND] text 追加SQL语句 ➢ C[HANGE] / old / new 修改SQL语句 ➢ C[HANGE] / text / ➢ CL[EAR] BUFF[ER] 清空缓冲区 ➢ DEL 删除SQL语句 ➢ DEL n ➢ DEL m n |
➢ SAVE filename 保存到文件 ➢ GET filename 从文件读取到缓冲区 ➢ START filename 执行文件 ➢ @ filename ➢ EDIT filename编辑文件 ➢ SPOOL filename 导出执行结果到文件 ➢ EXIT
|
五、从多个表显示数据
-
使用相等和不等连结写SELECT语句来访问多个表
-
使用外连接查询数据
-
表的自连接
使用连接从多个表中查询数据
|
|

在WHERE子句中写连接条件
在多个表中具有相同的列名
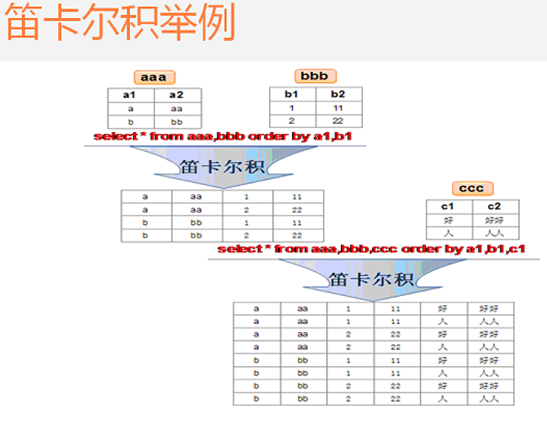
笛卡尔现象
➢ 笛卡尔结果形成于:
连接条件被省略
连接条件无效
第一个表的所有记录连接到第二个表的所有记录
➢ 为了避免笛卡尔结果我们总是在 WHERE 子句中使用有效连接
|
|
连接的类型
|
|
 |
|
|
|
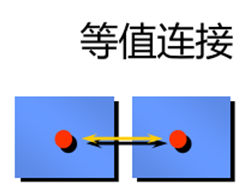
等值连接示例
|
|
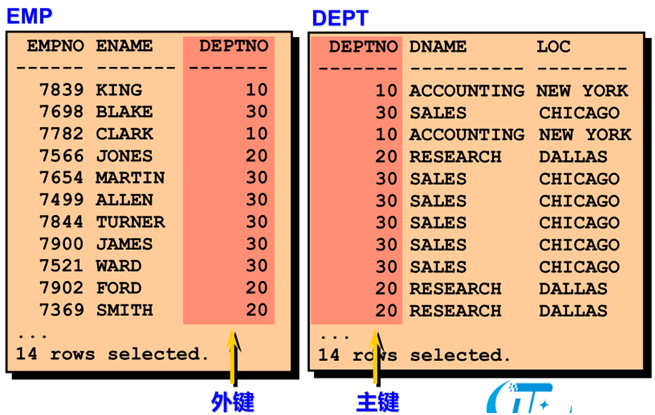
限定列名
➢ 使用表名作为前缀在多个表中指定列名
➢ 使用表前缀可以改进性能
➢ 使用列的别名以区分不同表的同名列
使用AND运算符附加查询条件
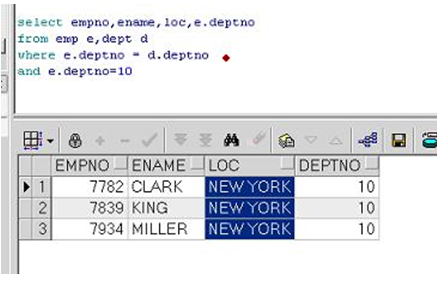
and用法 附加条件 筛选出 deptno=10的信息
使用别名简化查询
|
|
|
|


多表连接
|
|

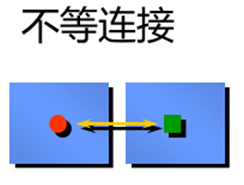
非等值连接
|
|
SAL在LOSAL和HISAL之间 |
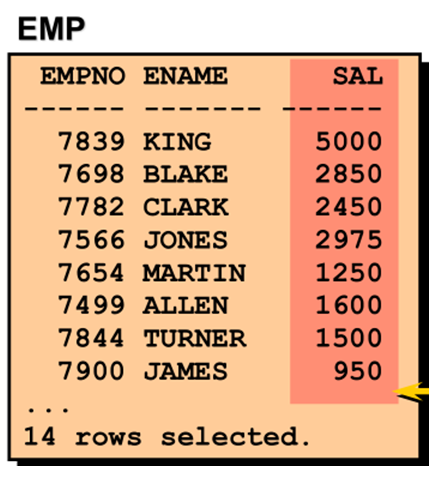

示例:
|
|
|

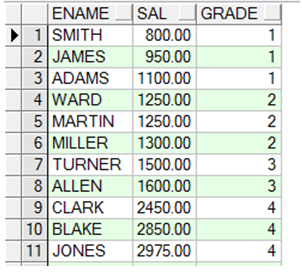
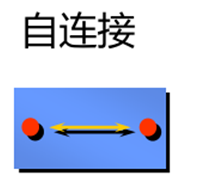
自连接
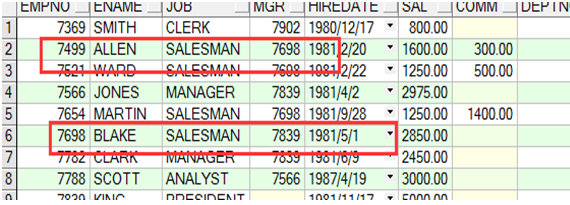
|
empno为7499的人的领导编号为7698,此为同一张表内的联系 |
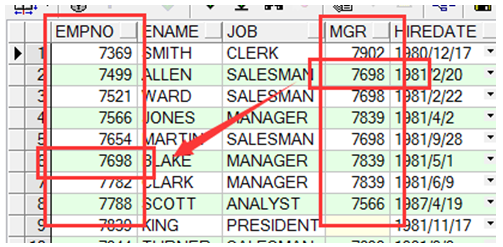
示例:
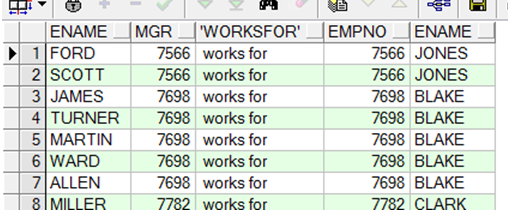
|
SELECT worker.ename, worker.mgr ,' works for ', manager.empno ,manager.ename FROM emp worker, emp manager WHERE worker.mgr = manager.empno; |
|
|
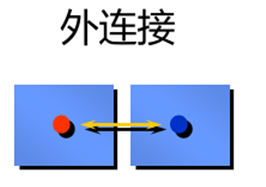
外连接
|
|
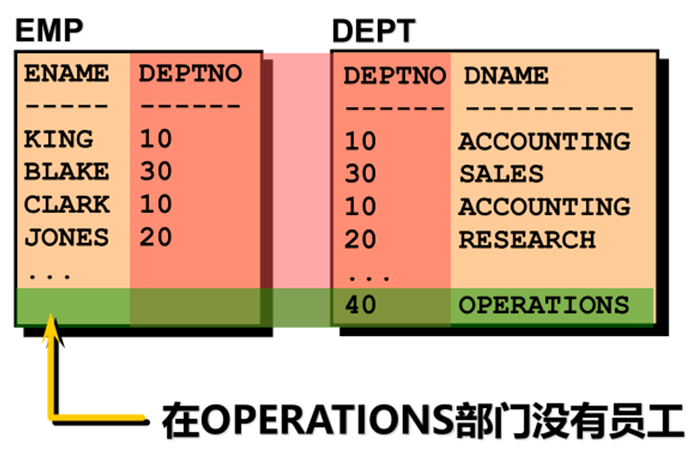
➢ 使用外连接看到不满足连接条件的记录
➢ 外连接运算符是加号(+)
➢ 外连接分为左连接、右连接
|
此为右连接,左连接条件为e.deptno = d.deptno (+) |
|
显示出了没有员工的编号40部门 |
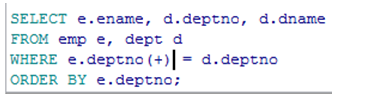
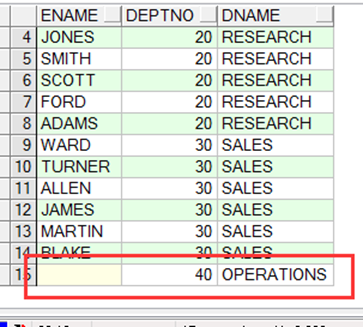
注:(+)在=左边是右连接,表示把右边的表的数据全部显示出来
(+)在=右边是左连接,表示把左边的表的数据全部显示出来
此外 左右连接还有一种写法
OUTER JOIN句法
ISO99标准把复杂的加号从Oracle outer join中拿出去,并使得outer join SQL更容易理解。
LEFT OUTER JOIN
RIGHT OUTER JOIN
示例:
select ename , dept.deptno
from emp left outer join dept
on emp.deptno = dept.deptno
|
|
|
|
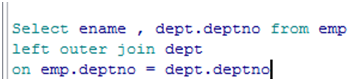
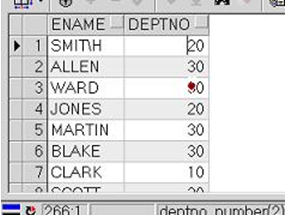
left outer join 左连接
展示左表中的所有记录
on表示满足什么条件 等同于where 只在左右连接时使用
六、组函数
• 熟悉组函数的用法
• 使用GROUP BY子句将数据分组
• 使用HAVING子句包括或排除被分组的记录
什么是分组函数?
分组函数运算每一组记录,每一组返回一个结果
分组函数的类型?
➢ AVG ([DISTINCT|ALL]n) 求平均数
➢ SUM ([DISTINCT|ALL]n) 求和
➢ COUNT ({ *|[DISTINCT|ALL]expr}) 计数
➢ MAX ([DISTINCT|ALL]expr) 求最大值
➢ MIN ([DISTINCT|ALL]expr) 最小值
➢ STDDEV ([DISTINCT|ALL]x) 标准差
➢ VARIANCE ([DISTINCT|ALL]x) 方差
使用AVG 和 SUM 函数
➢ 在数字类型数据使用AVG 和 SUM 函数
|
|
|
|


使用MIN 和 MAX 函数
➢ MIN 和 MAX函数适用于任何数据类型
|
|
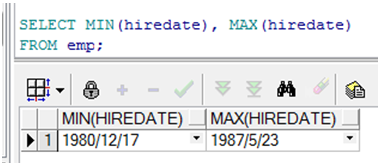
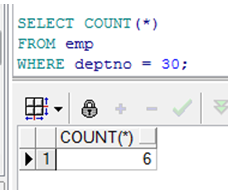
使用 COUNT 函数
➢ COUNT(*)返回表中的记录数
|
|
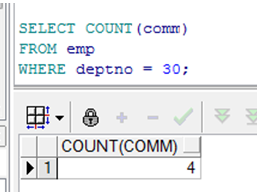
➢ COUNT(expr) 返回非空记录
|
|
分组函数和空值
➢ 分组函省略列中的空值
|
|
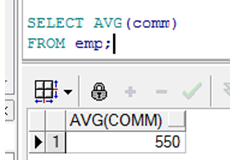
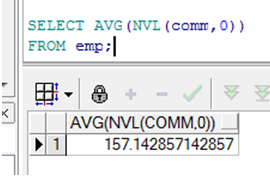
在分组函数中使用NVL函数
➢ NVL函数强制分组函数包括空值
|
|
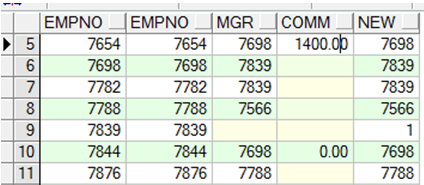
GROUP BY子句
➢ 使用GROUP BY子句将表分成小组
➢ 组函数忽略空值, 可以使用NVL,NVL2,COALESCE 等函数处理空值
注:group by 写在order by 之前
|
|
|
colaesce(字段,值,字段2,值),返回第一个不为空的字段并显示出这个字段,当第一个字段没有非空时,顺延查询第二个字段知道结束 |
|
|
|
|


所有用来分组的列在SELECT列表中不能使用分组函数
|
|
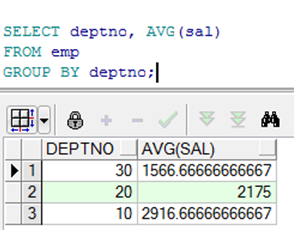
多列分组
在多列上使用 GROUP BY子句
|
|
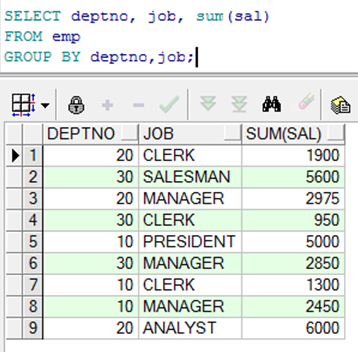
使用分组函数时的非法查询
➢ 不能使用WHERE子句限定组
➢ 可使用HAVING子句限定组
|
|

HAVING子句
➢ Having子句的作用是对行分组进行过滤
-
记录被分组
-
使用组函数
-
匹配HAVING子句的组被显示
|
|
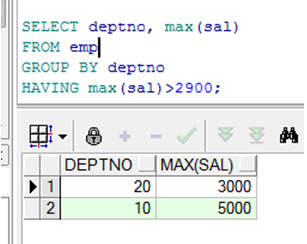
|
|
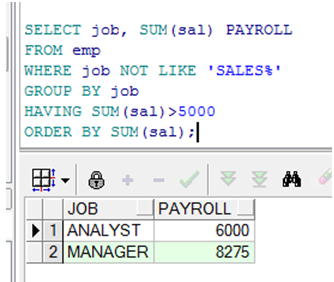
having用在group by之后 是对group by 的补充
嵌套组函数
➢ 显示最高的平均工资
|
|
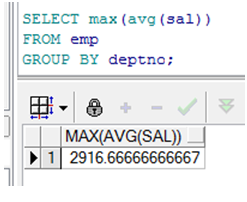
嵌套组函数必须有group by
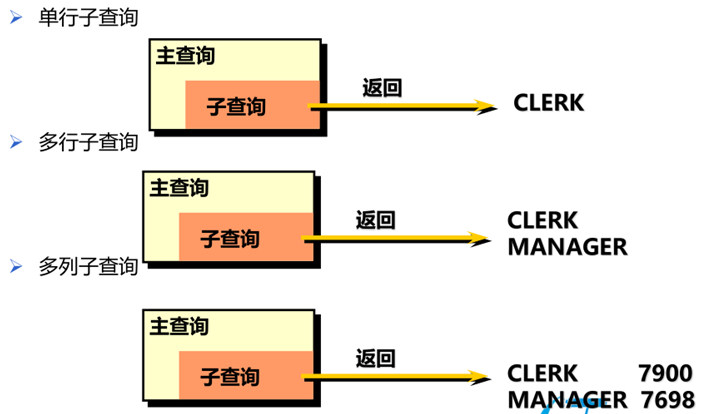
七、子查询
• 定义子查询
• 列出子查询的种类
• 编写单行和多行子查询
➢ 子查询在主查询前执行一次
➢ 主查询使用子查询的结果
|
|
使用子查询的规则
➢ 子查询要用括号括起来
➢ 将子查询放在比较运算符的右边
➢ 子查询中不要加ORDER BY子句
➢ 对单行子查询使用单行运算符
➢ 对多行子查询使用多行运算符
子查询的种类
|
|
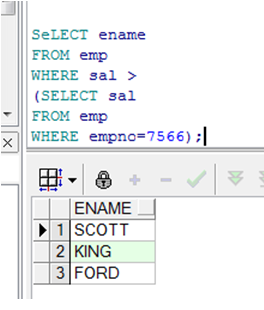
单行子查询
➢ 返回一行记录
➢ 使用单行记录比较运算符
|
|
示例:
|
|
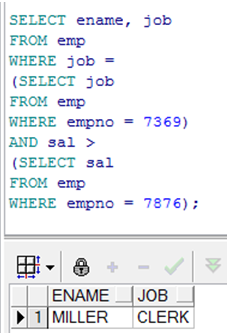
在子查询中使用分组函数
|
|
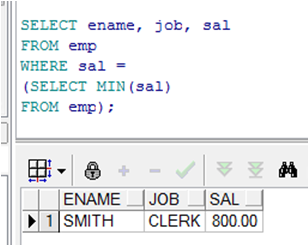
在子查询中使用HAVING子句
➢ 先执行子查询
➢ 然后返回结果到主查询的HAVING 子句
|
|

多行子查询
➢ 返回多行
➢ 使用多行比较运算符
|
|

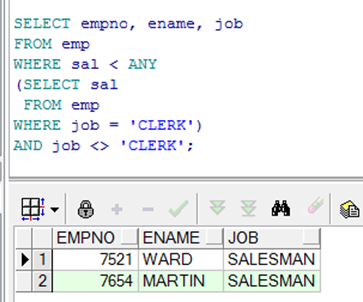
在多行子查询中使用ANY运算符
|
|
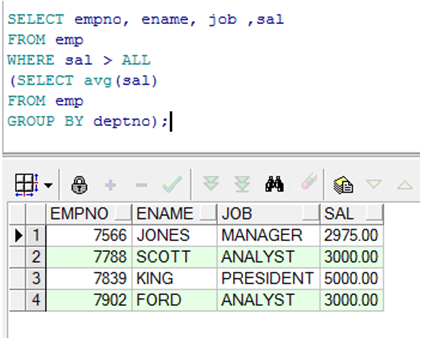
在多行子查询中使用ALL运算符
|
|
八、操作数据
描述DML语句
使用INSERT,UPDATE和DELETE命令操作数据
控制事务
➢ 使用 DML 语句可执行:
插入新数据
修改已有数据
删除数据
➢ 一个事务是DML语句的逻辑工作单元
INSERT 语句
INSERT语句一次将一个记录的数据输入表中
|
插入空值(不指定null) |
|
|
|
|
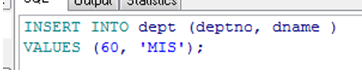
|
插入空值(指定null) |
|
|

|
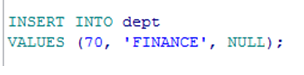
注:
1.在字段属性可以为空时,插入的值可以为空
2.insert 操作执行之后不会自动显示,要自主查询
INSERT语句中使用函数
➢ 例如使用SYSDATE函数插入当前的日期和时间
|
|
 |

➢ 增加一个员工
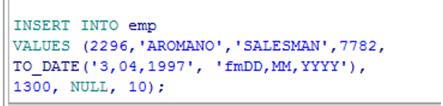 |

|
从其他表中拷贝记录
|
|
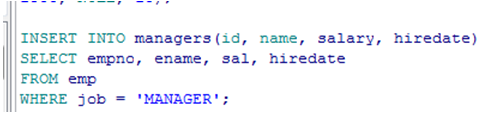
UPDATE 语句
➢ 使用UPDATE语句修改已存在的记录(update不能修改主键)
修改记录
➢ 使用WHERE子句修改指定的记录.
|
|
|
|

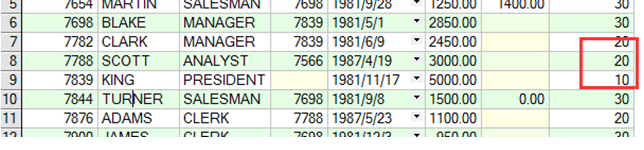
➢ 修改所有的记录.
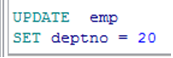 |
|
|
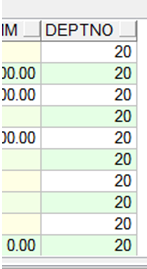
使用多列子查询修改数据
|
|
|
|
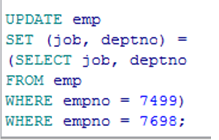
注:update 不能修改作为主键的字段为不存在的值
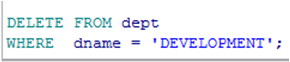
DELETE 语句
➢ 使用DELETE命令从表中删除记录.
 |
➢ 删除所有的记录
 |
删除的记录基于其他表的记录
➢ 使用子查询,删除的记录基于其他的表。
 |
删除记录时违反完整性约束
 |
dept表的deptno与emp表相关联(外键约束),删除违反完整性约束
数据库的事务
➢ 一组DML语句,修改的数据在他们中保持一致
➢ 一个 DDL 语句
➢ 一个 DCL 语句
数据库的事务
➢ 开始于第一个执行的语句
➢ 结束于:
COMMIT 或 ROLLBACK
DDL or DCL (grant/revoke) 语句
某些错误,退出,或系统崩溃
事务的自动处理
➢ 当下列情况发生时事务自动提交:
执行一个 DDL 语句
执行一个 DCL 语句
从 SQL*Plus正常退出
➢ 当从SQL*PLUS中强行退出或系统失败时,事物自动回滚
COMMIT和 ROLLBACK的优点
➢ 保证数据一致性
➢ 在数据永久性生效前重新查看修改的数据
➢ 相关逻辑操作单元
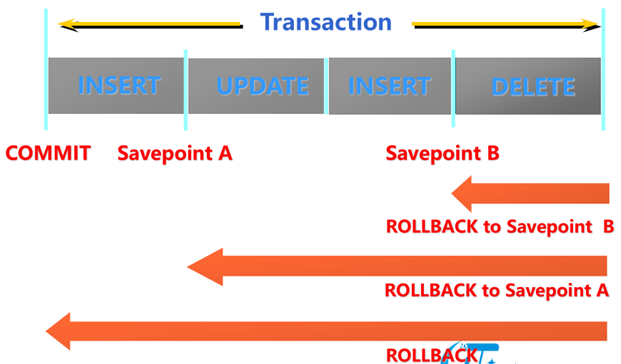
控制事务
|
提交或回滚前数据的状态
➢ 以前的数据可恢复.
➢ 当前的用户可看到DML操作的结果.
➢ 其他用户不能看到DML操作的结果.
➢ 被操作的数据被锁住,其他用户不能修改这些数据.
提交后数据的状态
➢ 数据的修改被永久写在数据库中.
➢ 数据以前的状态永久性丢失.
➢ 所有的用户都能看到操作后的结果.
➢ 记录锁被释放,其他用户可操作这些记录.
➢ 所有的 savepoints 被去掉.
注:
savepoint应用
|
|

回到a2之后还可以再回到a1 , 回到a1后,不能回到a2,因为a2在此时并没有被记录
回滚后数据的状态
➢ 语句将使所有的修改失效.
修改的数据被回退.
恢复数据以前的状态.
行级锁被释放.
回退到某一标识
➢ 使用语句产生一个标识,将事务分成几个阶段.
➢ 可回退到标识指定的阶段.
语句回滚
➢ 如果一条 DML 语句执行时失败,只有此语句回退.
Oracle 执行了一个自动的 savepoint.
其他的变化被保留.
➢ 客户应该执行COMMIT或ROLLBACK以结束事务.
事务特性
• 事务的ACID特性
• 1、原子性(atomicity):
一个事务中包含的所有sql语句都是一个不可分割的单元。
• 2、一致性(consistency)
事务必须确保数据库的状态是一致的。
• 3、隔离性(isolation)
多个事务独立运行,彼此不影响。
• 4、持久性(durability)
事务一旦提交,数据库的变化就会被永久保留下来。
读一致性
➢ 读一致性保证了查询数据得到一致的结果.
➢ 不同用户修改的数据不会发生冲突.
➢ 对相同的数据操作时确保:
查询时不用等写完成
写时不用等查询完成
小结
|
|

九、管理表
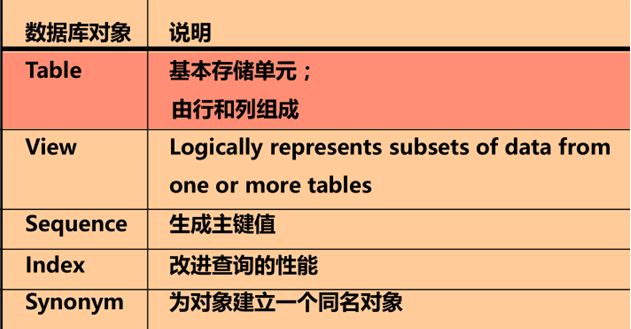
• 了解数据库的对象
• 创建表、改变表的定义,表中列可以使用的数据类型
• 删除表、改表名、截取表的所有记录
|
|
表命名规则
➢ 必须以字母开头
➢ 可包括数字
➢ 只能包含A-Z, a-z, 0-9, _, $, and #
➢ 不要使用oracle的保留字
➢ 同一用户的对象不能同名
创建表
你必须有 :
➢ 建表的权限
CREATE TABLE [schema.]table
(column datatype [DEFAULT expr];
➢ 有存储区域
➢ 你可指定:
表名 Table name
列名, 列的数据类型, 列的大
建表过程:
1.建表

2.添加信息
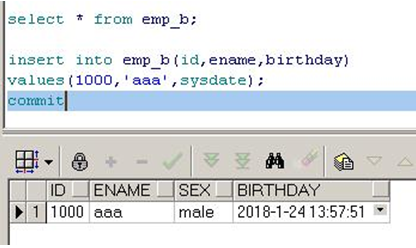
当没有输入值时,sex会采用默认的值‘male’
也可以通过自己输入值来输入
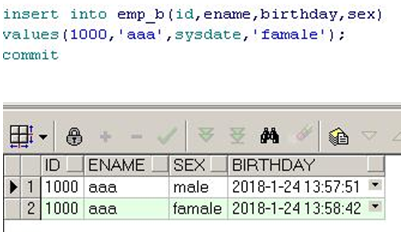
注:以现有的图表来创建表时 可以通过别名来更新字段名称
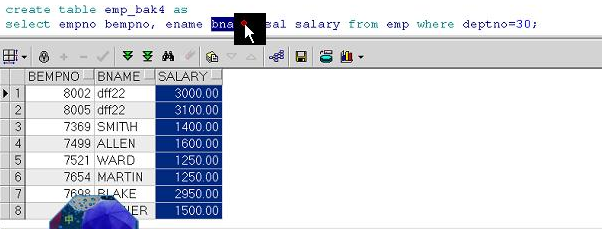
引用其他用户的表
➢ 其他用户的表不能直接访问
➢ 使用其他用户的表时需加用户名作为前缀
示例:
SELECT * FROM scott.emp;
缺省选项
➢ 在插入记录时为列指定缺省值

合法的值是字符,表达式.或SQL函数
非法值为其他的列名.
缺省的数据类型必须匹配列的数据类型.
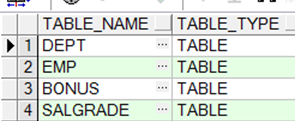
查询数据字典
➢ 查询此用户所拥有哪些表
|
|
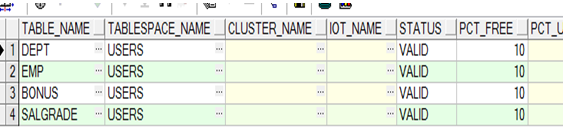 |

➢ 查询此用户拥有哪些类型的对象
|
|
|
|

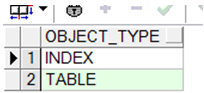
➢ 查询此用户拥有的表,视图,同义词,序列号
|
|
|
|

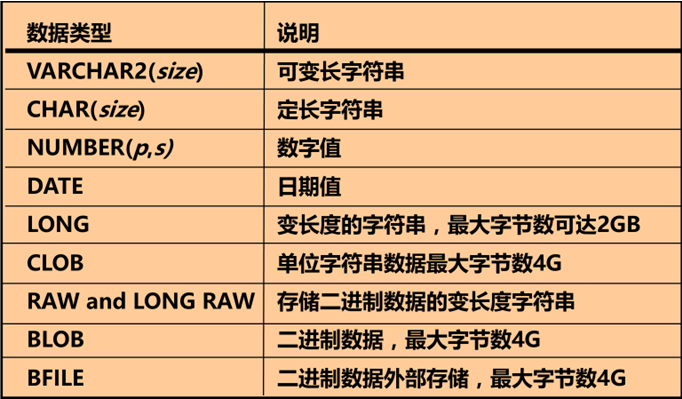
数据类型
|
|
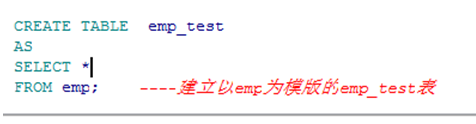
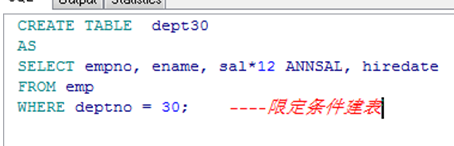
使用子查询创建表
➢ 使用子查询创建表
列的数目要和子查询中的匹配
可定义列名和缺省值
使用CTAS创建表
|
|
|
|
|
|

ALTER TABLE 语句
➢ 使用ALTER TABLE 语句可:
加一列 : alter table add
修改列 : alter table modify
对新列定义缺省值
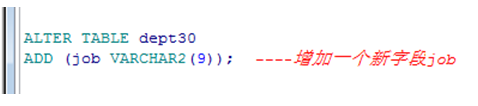
增加列
➢ 使用 ADD 子句增加列.
|
|
|
|

修改列
➢ 可修改列的数据类型,大小和缺省值.
|
|
|
|
 |


➢ 修改后的缺省值只影响以后插入的数据.
修改列名
➢ 在Oracle9i及后续版本,可以直接修改列名.
|
|

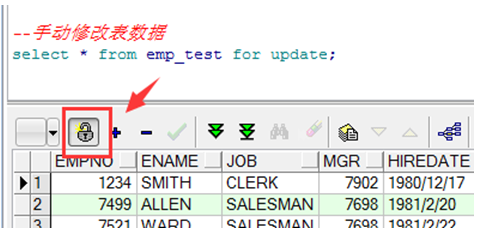
手动修改表
|
输入命令,点击锁即可手动修改 |
删除表
➢ 表中所有数据将被删除
➢ 事务被提交
➢ 所有索引被删除
➢ 不能回退
|
|

改变对象名称
➢ 使用RENAME语句改变对象名称
|
|

注:操作者必须是对象的所有者
截取表的所有记录
➢ TRUNCATE TABLE 语句:
删除表中所有记录
|
|

复位HWM
释放表的存储空间
➢ 不能回退
➢ 和DELETE一样,是删除记录的手段之一
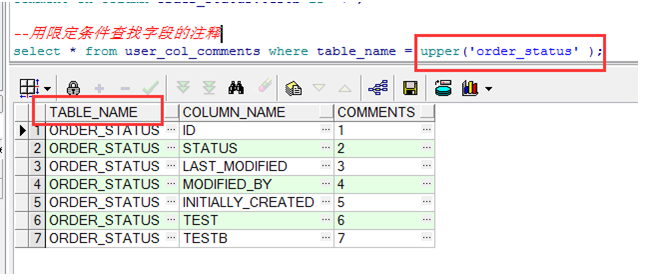
在表中加注释
➢ 使用COMMENT语句可向表或表中的列加注释
|
可以通过在表上右击选择view查看注释,也可以通过命令查看 |
|
给字段添加注释,只能逐个字段添加注释,不能一起添加 |


➢ 可通过如下数据字典视图看注释:(用select * from)
ALL_COL_COMMENTS
USER_COL_COMMENTS
ALL_TAB_COMMENTS
USER_TAB_COMMENTS
 |
|
where限定表名,但这个时候表名已经是table_name字段的值,所以必须要大写或用upper参数 |
小结
|
|
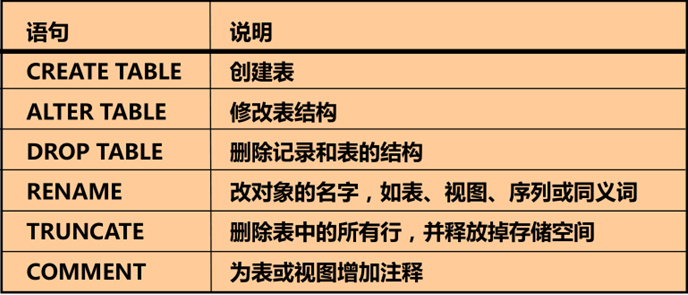
十、约束
• 了解什么是约束
• 创建约束和维护约束
什么是约束
➢ 约束是表级强制执行的规则.
➢ 当表中数据有相互依赖性时,可保护数据不被删除.
➢ Oracle 有如下类型的约束:
NOT NULL ----非空
UNIQUE Key ----唯一
PRIMARY KEY ----主键
FOREIGN KEY ----外键
CHECK ----检查
约束概况
➢ Oracle使用 SYS_Cn 格式命名约束
➢ 创建约束:
在建表的同时创建
建表后创建
➢ 可定义列级或表级约束.
➢ 可通过数据字典表查看约束.
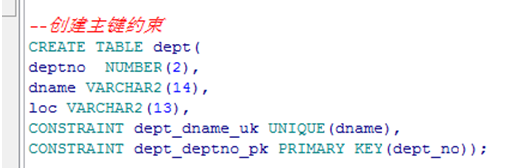
创建约束
not null、check只能对列进行约束
|
|
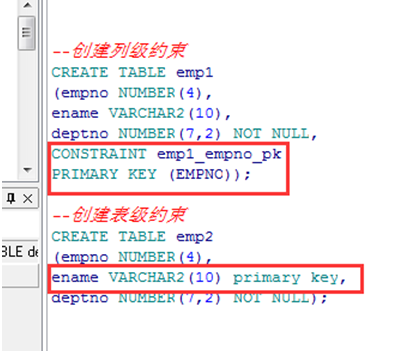
给字段emp1.empno/emp.ename创建主键约束(非空且唯一)
非空约束(NOT NULL)
➢ 确保列值非空
|
这里是从表级建立非空约束,定义了ename、deptno字段值不能为空 |
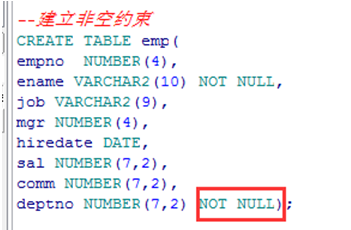
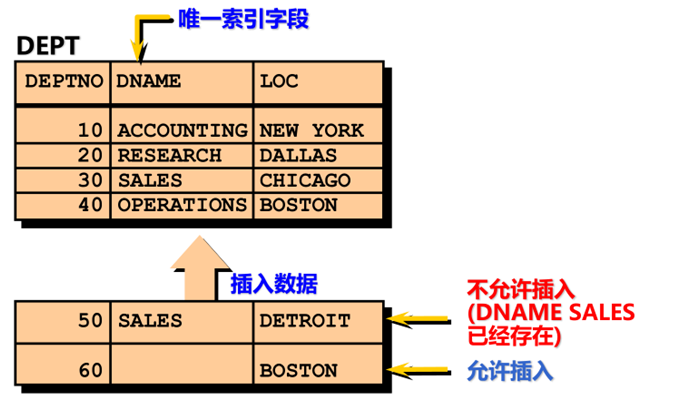
唯一性约束(UNIQUE)
示例:
|
dname字段已经有sales存在,新添加的字段sales不能重复,即再同一字段不允许存在相同的值 |
|
|

主键约束( PRIMARY KEY)
|
要求在同一个字段内的值 唯一且非空 |
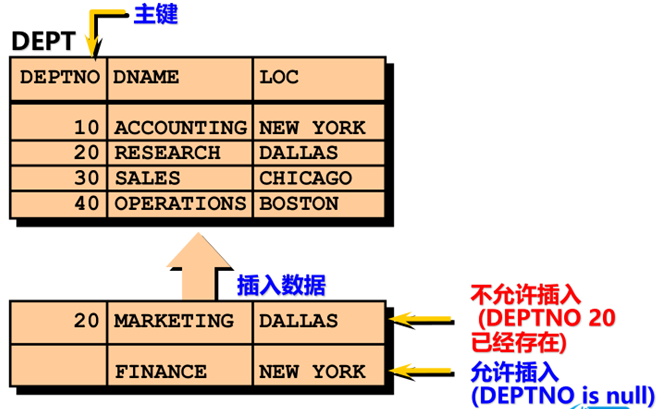
|
|
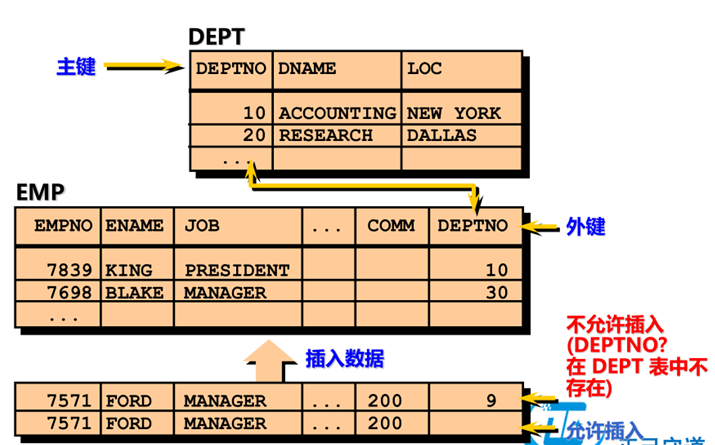
外键约束(FOREIGN KEY)
|
外键约束的字段被主键字段所约束,可以为空但不能是主键没有的值 |
|
|

外键约束的关键字
➢ FOREIGN KEY
定义子表的哪一列作为外键约束
➢ REFERENCES
指示主表和参照的列
➢ ON DELETE CASCADE
删除主表记录时将子表相关记录删除
➢ ON DELETE SET NULL
将外键引用置为空值
CHECK 约束
➢ 定义每一记录都要满足的条件
➢ 条件表达式不允许有:
CURRVAL, NEXTVAL, LEVEL, ROWNUM
SYSDATE, UID, USER, USERENV 函数
参照其他记录的值
|
创建的deptno的值只能在10~99之间 |

加约束
➢ 可加或删除约束,但不能修改
➢ 可使约束生效和失效
➢ 使用MODIFY子句可加 NOT NULL约束
|
使用modify给列增加not null约束 |
 |
|
使用modify 给列去除not null约束 |

|

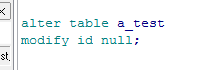
增加外键约束到EMP表
|
给mgr增加外键,参照主键empno |

删除约束
➢ 删除约束emp_mgr_fk.
|
|

➢ 删除主键约束和相关的外键约束.
 |
使约束失效
➢ 在ALTER TABLE 语句中执行DISABLE子句可使完整性约束失效
➢ 使用 CASCADE 选项可使依赖的完整约束失效
|
|

使约束生效
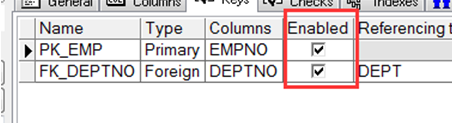
➢ 使用ENABLE子句将失效的约束生效
➢ 当使UNIQUE 或 PRIMARY KEY约束生效时,会自动创建 UNIQUE 或 PRIMARY KEY 索引.
|
|

注:也可以通过view窗口使约束生/失效
 |
查看约束
➢ 通过查看 USER_CONSTRAINTS 表可得到用户的所有约束.
 |
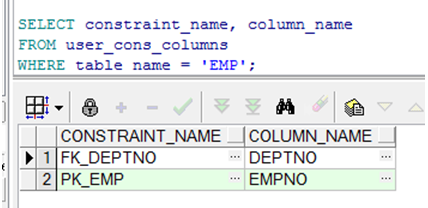
查看约束建立在哪些列
➢ 通过查询USER_CONS_COLUMNS 视图可获得约束建立在哪些列上
|
|
十一、视图(view)
• 描述视图
• 创建视图
• 通过视图获得数据
• 改变视图的定义
• 通过视图操作数据
• 删除视图
为什么使用视图
➢ 限制对数据的访问
➢ 很容易的写成复杂的查询
➢ 允许数据的独立性
➢ 不同的视图可获得相同的数据
简单视图和复杂视图
|
|

创建视图
➢ 创建视图的语句中可嵌入子查询.
➢ 子查询中可包括复杂的 SELECT 语法.
➢ 子查询中不能包含ORDER BY 子句
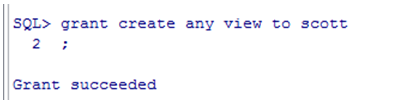
首先,scott用户是没有创建视图的权限的,必须先以system账户对scott进行赋权:
|
|
 |
创建视图
➢ 在子查询中使用列别名创建视图.
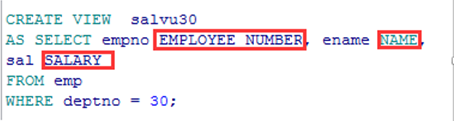
|
|
SELECT EMPLOYEE_NUMBER, NAME, SALARY FROM salvu30; |
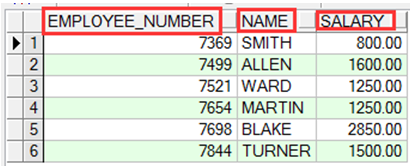
查询USER_VIEWS数据字典视图
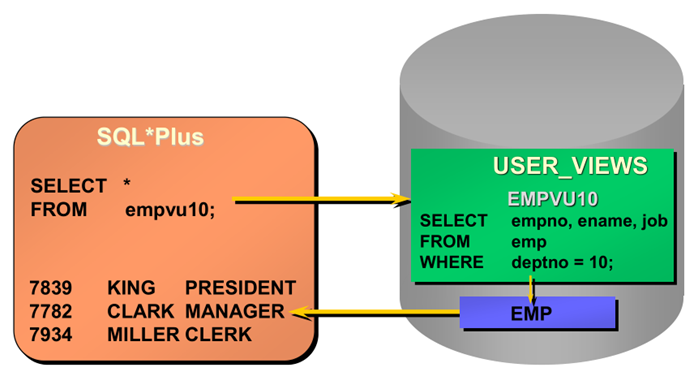
|
修改视图
➢ 使用CREATE OR REPLACE VIEW 子句修改 视图 ,并为每列加别名.
|
|
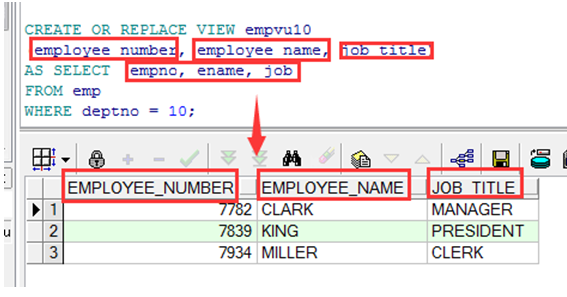
➢ 在CREATE VIEW语句中列的别名的顺序是和子查询中一致的.
创建复杂的视图
➢ 复杂视图的特点:
从多个表查询
包含函数
包含分组数据
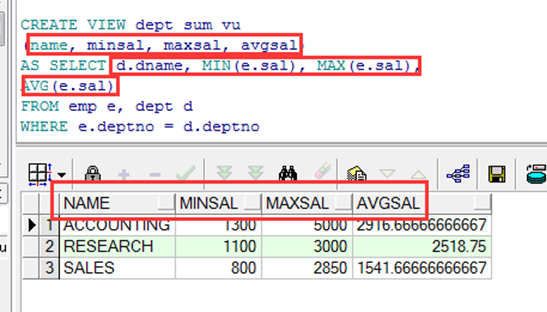
|
对视图进行DML操作的规则
➢ 可对简单视图执行DML操作
➢ 在下列情况下不能删除记录:
视图包括组函数
视图包括GROUP BY 子句
视图包括 DISTINCT
Rownum伪列关键词
➢ 在下列情况下不能修改记录 :
前面所提到的情况
列是由表达式定义的
包括ROWNUM 虚列
➢ 在下列情况下不能添加记录 :
前面所提到的情况
视图的基表有非空列,但在视图中没有此列
使用 WITH CHECK OPTION子句
➢ 使用WITH CHECK OPTION可使DML操作限制在视图所包含的范围
内.
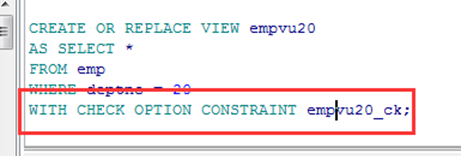 |
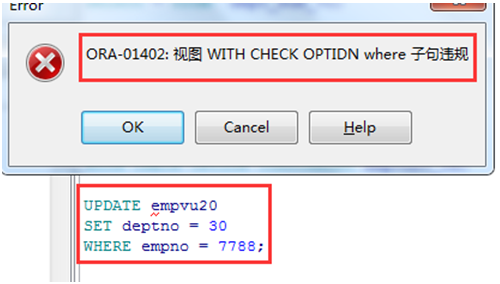 |
删除视图
➢ 删除视图并不删除基表中的数据.
 |
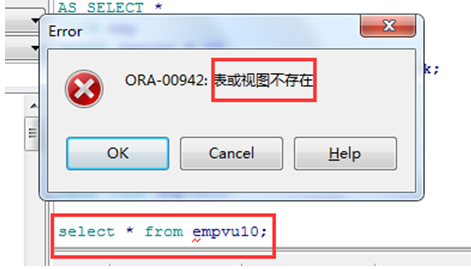
|
小结
➢ 视图可从其他的表或视图中获取数据.
➢ 视图提供如下优点:
限制数据的访问
简化查询
提供独立的数据
允许多个视图使用相同的数据
删除时不影响基表
十二、 其他数据库对象
• 描述其他的数据库对象和使用
• 创建,修改,使用序列号
• 创建和维护索引
• 创建公共和私有的同义词
数据库对象
|
|
什么是序列号
➢ 自动生成唯一的数字
➢ 是一个共享的对象
➢ 典型的应用于表的主键
➢ 可替代应用代码
➢ 将序列号值放在缓存中可提高访问速度
CREATE SEQUENCE 语句
➢ 定义序列号
 |
Increment by n:递增的量为n
Maxvalue:最大值/nomaxvalue:没有最大值
minvalue:最小值/nominvalue:没有最小值
cycle:循环/nocycle:没有循环
Cache n:缓存n条序列/不缓存
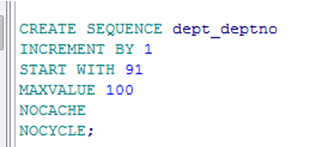
创建序列号
➢ 创建名字为 DEPT_DEPTNO的序列号,以供DEPT表使用 .
➢ 不加 CYCLE 选项.
 |
|
|

确认序列号
➢ 通过查询USER_SEQUENCES 数据字典表,可检查序列号的数值.
|
|
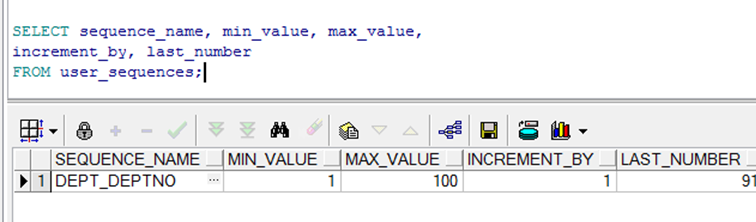
➢ LAST_NUMBER 列显示下一个可用的序列号.
NEXTVAL 和 CURRVAL
➢ NEXTVAL 返回下一个可用序列号值
➢ CURRVAL 包含当前的序列号值
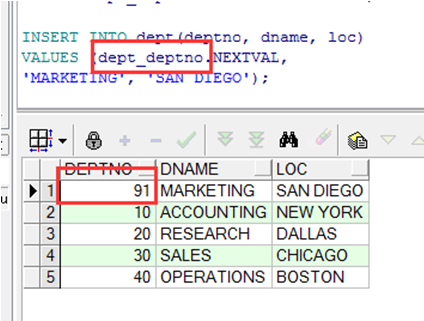
使用序列号
➢ 使用序列号插入记录
 |
➢ 查看插入的值
 |
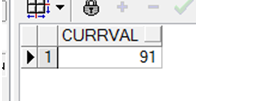
|
注:插入的值可以不按顺序,但一定要在设定的范围内并没有出现过。
修改序列号
➢ 可修改步增值,最大值,最小值, cycle选项, cache 选项.
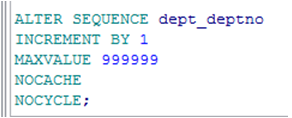 |
➢ 修改的规则:
你必须是序列号的所有者并有ALTER权限.
只对以后的序列号受影响.
序列号可被删除并重建,以获得新的开始值.
一些确认被执行. 例如:MAXVALUE不能小于当前序列号.
删除序列号
➢ 使用 DROP SEQUENCE 语句删除序列号.
 |
什么是索引
➢ 是一种对象
➢ 使用指针加快记录访问速度
➢ 减小硬盘 I/O
➢ 索引独立于表而存在
➢ 数据库自动使用和维护
怎样建索引
➢ 自动
唯一性索引自动被创建,当定义 PRIMARY KEY 或 UNIQUE 约
束时.
➢ 手动
使用CREATE INDEX命令.
创建索引
➢ 可基于一列或多列创建索引
 |
➢ 例子:
 |
创建索引规则
➢ 索引列应该经常在 WHERE 子句中,或是连接条件.
➢ 此列值域比较广.
➢ 此列包含大量空值.
➢ 在 WHERE 子句或连接条件中经常一起使用的列.
➢ 对大表查询的结果小于总数据的2~4% .
下列的表不适合建索引:
表很小
列不经常在WHERE子句中使用
对大表查询的结果大于总数据的2~4% .
表经常被修改
确认索引
➢ USER_INDEXES.
➢ USER_IND_COLUMNS .
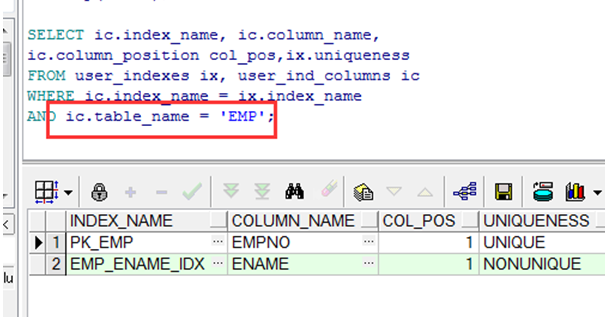 |
删除索引
➢ 删除索引.
 |
➢ 必须是索引的拥有者或者有 DROP ANY INDEX 权限.
同义词
➢ 同义词是数据库对象的另外一个名字,以方便使用.
参照其他用户的表.
较短的对象名.
|
|
|
加public代表所有人都可以用,不加表示只有当前用户可以用这个同义词 |

创建和删除同义词
➢ 创建.

|
➢ 删除.
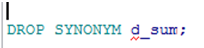
|
小结
➢ 自动生成序列号.
➢ 查看序列号的信息(USER_SEQUENCES).
➢ 建索引提高性能.
➢ 查看索引信息(USER_INDEXES).
➢ 使用同义词.
第十三章 用户及权限
• 创建用户
• 创建角色
• 授权和收回权限
权限
➢数据库的安全性
➢ 系统安全性
➢ 数据安全性
➢系统权限: 获得后可访问数据库
➢对象权限: 操作数据库对象的内容
➢Schema: 对象的集合(tables, views, sequences)
系统权限
➢ 多于100种系统权限可用
➢ DBA 有最高系统权限.
Create new users(创建新用户)
Remove users(删除用户)
Remove tables(删除表)
Backup tables(备份表)
建用户
➢ DBA 可使用 CREATE USER 语句建用户.

使用系统权限
➢ 创建用户后,DBA需授给用户系统权限.
➢ 一个应用开发者应有下列系统权限:
CREATE SESSION(建立会话的权限)
CREATE TABLE(建表权限)
CREATE SEQUENCE(建序列号权限)
CREATE VIEW(建视图权限)
CREATE PROCEDURE(存储过程权限)
授予系统权限
➢ DBA 可将指定的系统权限授予用户.

什么是角色(通过角色赋予权限)
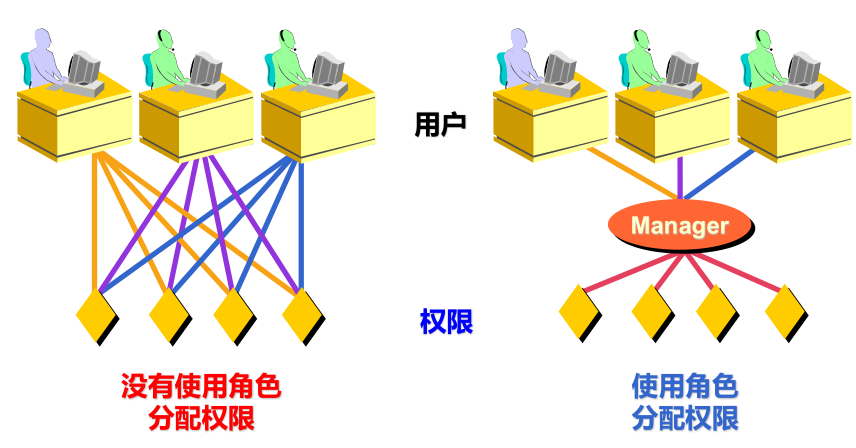 |
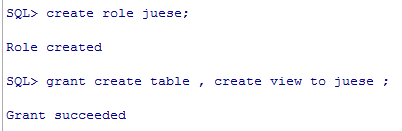
创建角色,用角色同时给多用户授权

改变用户口令
➢ 当建用户时会初始化一个口令.
➢ 用户可使用 ALTER USER 语句改变口令.

对象权限
➢ 对象不同,对象权限也不同.
➢ 对象的所有者拥有对象的所有权限.
➢ 对象的所有者可将指定的权限授予其他的用户.
|
|
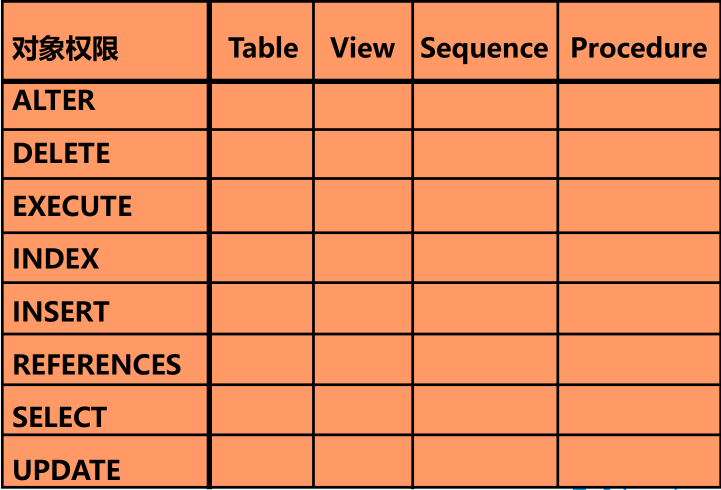
授予对象权限
指定对象权限赋予给用户

指定对象特定列的权限赋予给用户

使用WITH GRANT OPTION 和 PUBLIC 关键字
➢ 使被授予的用户可转授此权限.

➢ 所有的用户都可查询此表

确认权限的数据字典表
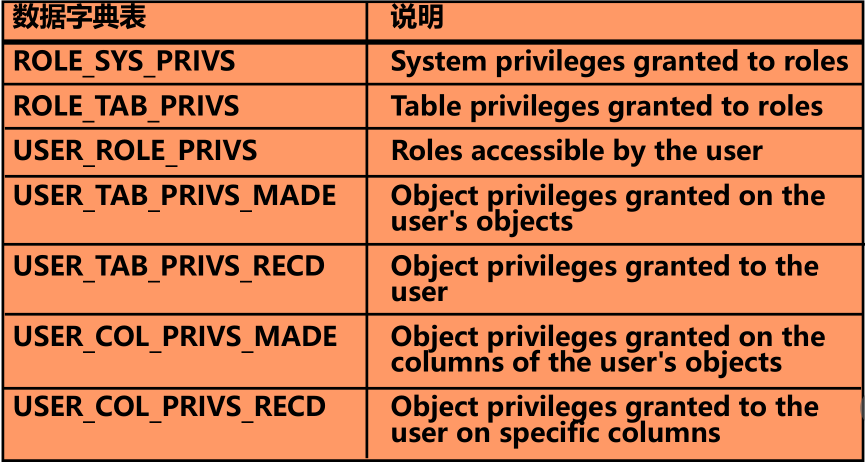 |
收回对象的权限
➢ 使用REVOKE语句从其他用户收回权限.
➢ 通过 WITH GRANT OPTION授予的权限也可收回.

小结

