
大数据-1
第一章:大数据概论
1.1 大数据定义
IT行业术语,是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
1.2 大数据主要解决问题
主要解决,海量数据的存储问题和海量数据的分析计算问题
第二章:Hadoop框架
2.1 Hadoop是什么
- Hadoop 是一个由Apache基金会所开发的分布式系统基础架构
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈
2.2 Hadoop组成 (2.x版本)
- HDFS——>负责数据存储
- Yarn——>负责资源调度
- MapReduce——>负责 计算
2.3 HDFS架构概述
2.3.1 HDFS 组成
- NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
2.3.3 HDFS特点
-
HDFS不支持对文件的随机写
可以追加,但是不能修改!
原因: 文件在HDFS上存储时,以block为基本单位存储!
①没有提供对文件的在线寻址(打开)功能
②文件以块形式存储,修改了一个块中的内容,就会影响当前块之后所有的块,效率低 -
HDFS不适合存储小文件
根本原因: HDFS存储了大量的小文件,会降低NN的服务能力!NN负责文件元数据(属性,块的映射)的管理,NN在运行时,必须将当前集群中存储所有文件的元数据全部加载到内存!
NN需要大量内存!举例: 当前运行NN的机器,有64G内存,除去系统开销,分配给NN 50G内存!
文件a (1k), 存储到HDFS上,需要将a文件的元数据保存到NN,加载到内存
文件名 创建时间 所属主 所属组 权限 修改时间+ 块的映射(1块)
150B文件b (128M), 存储到HDFS上,需要将b文件的元数据保存到NN,加载到内存
文件名 创建时间 所属主 所属组 权限 修改时间+块的映射(1块)
150B
最多存储50G/150B个文件b
50G/150B * 128M -
同一个文件在同一时刻只能由一个客户端写入!
-
块大小
-
块大小取决于dfs.blocksize,2.x默认为128M,1.x默认为64M
-
默认为128M的原因,基于最佳传输损耗理论!
不论对磁盘的文件进行读还是写,都需要先进行寻址!
最佳传输损耗理论:在一次传输中,寻址时间占用总传输时间的1%时,本次传输的损耗最小,为最佳性价比传输!
目前硬件的发展条件,普通磁盘写的速率大概为100M/S, 寻址时间一般为10ms!
10ms / 1% = 1s
1s * 100M/S=100M块在传输时,每64K还需要校验一次,因此块大小,必须为2的n次方,最接近100M的就是128M!
-
块大小需要合适调节
不能太大:
当前有文件a, 1G
128M一块 1G存8块 , 取第一块
1G一块 1G存1块 , 取第一块
只需要读取a文件0-128M部分的内容
①在一些分块读取的场景,不够灵活,会带来额外的网络消耗
②在上传文件时,一旦发生故障,会造成资源的浪费 -
不能太小:
文件a,128M
1M一块: 128个块,生成128个块的映射信息
128M一块, 1个块,一个块的映射信息
①块太小,同样大小的文件,会占用过多的NN的元数据空间
②块太小,在进行读写操作时,会消耗额外的寻址时间
- 副本数的概念指的是最大副本数!
- 具体存放几个副本需要参考DN节点的数量!每个DN节点最多只能存储一个副本!
-
-
默认块大小为128M,128M指的是块的最大大小!
- 每个块最多存储128M的数据,如果当前块存储的数据不满128M存了多少数据,就占用多少的磁盘空间!
- 一个块只属于一个文件!
-
shell操作命令
- hadoop fs : 既可以对本地文件系统进行操作还可以操作分布式文件系统!
- hdfs dfs : 只能操作分布式文件系统
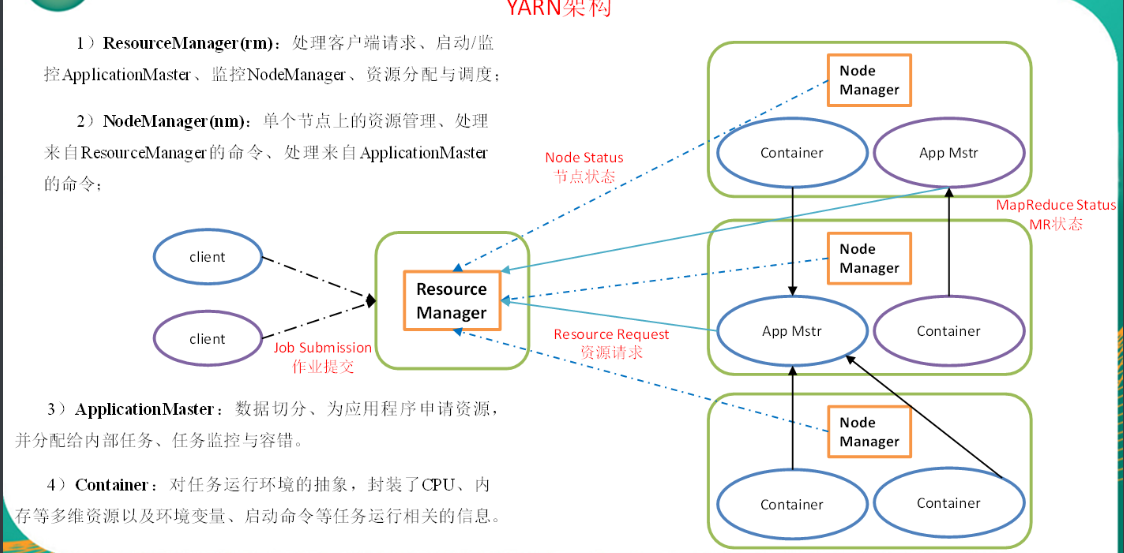
2.4 YARN架构概述
2.5 MapReduce架构概述
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
2.6 大数据技术生态体系
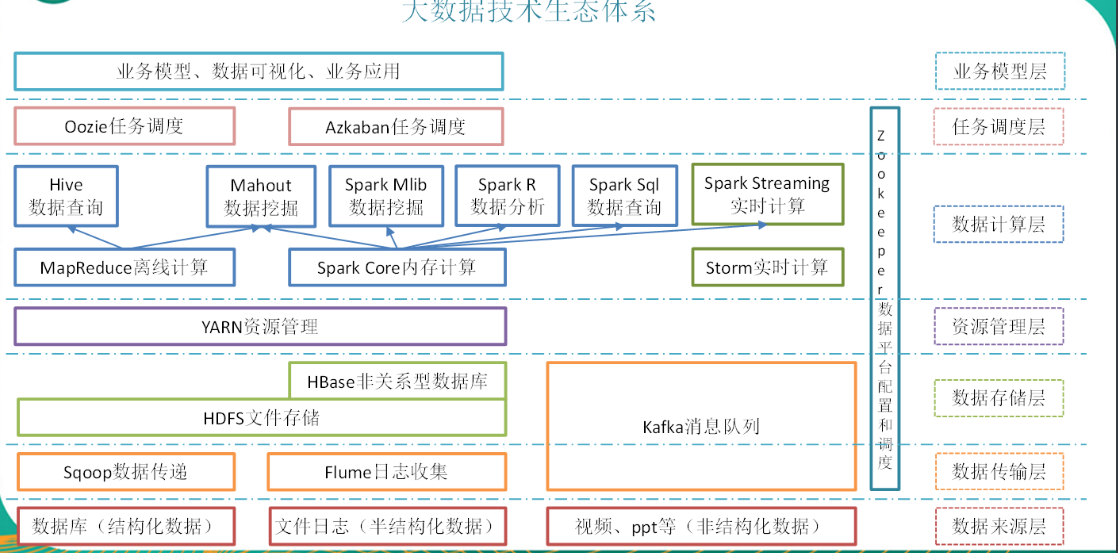
解释:
- Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
- Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
- Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- (2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
- (3)支持通过Kafka服务器和消费机集群来分区消息。
- (4)支持Hadoop并行数据加载。
- Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
- Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
- Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
- Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
- Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户

 浙公网安备 33010602011771号
浙公网安备 33010602011771号