
如何使用Scrapy 搭建一个爬虫项目
一、什么是Scrapy
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。 [1]
二、为什么要使用Scrapy
和requests库对比
| Requests | Scrapy |
|---|---|
| 功能库 | 框架 |
| 并发性能不足,性能较差 | 并发性好,性能较高 |
| 页面级别爬虫 | 网站级别爬虫 |
| 重点在于页面下载 | 重点在于爬虫结构 |
三、为什么Scrapy要使用命令行模式
- 命令行更容易实现自动化,适合脚本控制
- 实际上,Scrapy是给程序员用的,功能比界面更重要
四、Scrapy常用命令
| 命令 | 说明 | 命令行 |
|---|---|---|
| startproject | 创建一个新工程 | scrapy startproject 工程名 |
| genspider | 创建一个爬虫 | scrapy genspider 爬虫名 目标网站 |
| crawl | 运行一个爬虫 | scrapy crawl 爬虫名 |
注意:目标网站为去掉“http://www.”之后的内容。
五、使用Scrapy步骤
-
安装scrapy ,进入cmd
pip install Scrapy -
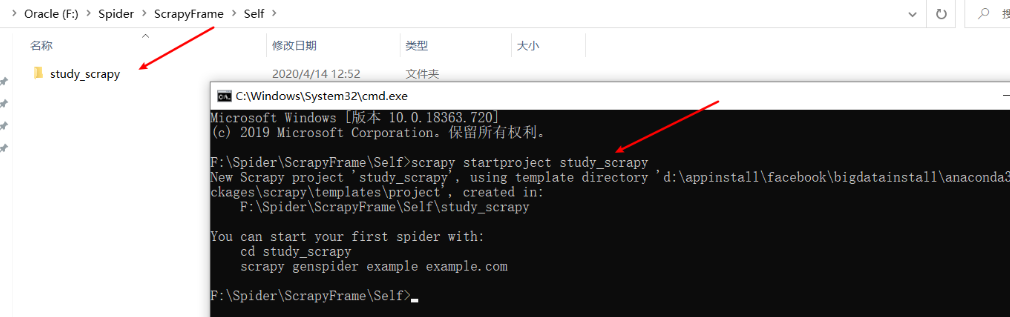
创建一个scrapy项目
scrapy startproject study_scrapy![]()
-
首先进入这个目录,再创建一个爬虫(如:我爬取51job网站)
scrapy genspider Job51 51job.com![]()
-
运行
scrapy crawl 爬虫名


至此如何使用Scrapy框架搭建一个爬虫就结束了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号