pandas模块
- 导入模块
import pandas as pd
- 数据类型
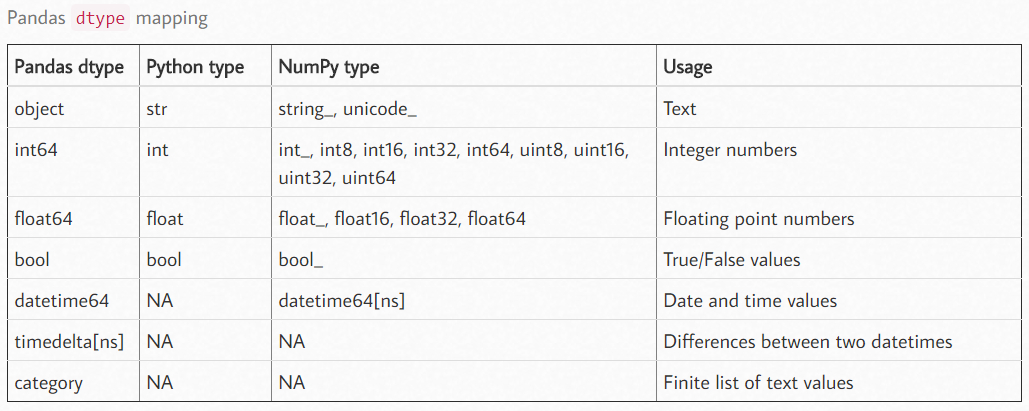
df.dtypes # 查看数据类型 df["Customer Number"] = df["Customer Number"].astype("int") # 使用astype函数就可以转换数据类型 # 传入的参数为一个字符串
# 数据导入之后进行类型转换是十分必要的
- Series类型
series,包含一个值序列以及索引(index),其实际上就是一个位于轴0的一维数组对象
生成:
pd.Series([1,2]) # 从列表产生Series,如果没有定义index,此时index是按照0开始自动生成 # 定义index需要和列表数据一一对应
索引:
obj.index # 返回一个rangeindex()对象,类似于range(),可以用于遍历
# 可以直接对其赋值一个列表,此时就会按照位置来更改数组对应的索引 obj.values # 返回一维array对象 obj['a'] # 使用index进行索引,返回单个值 obj[['a','b','c']] # 传入索引列表,此时返回series obj[obj > 0] # 也可以使用布尔索引,获得大于0的所有项 # 此处相当于传入一个全为布尔值的series
obj.name = 'a'
# 此处表示obj自身的name属性
obj.index.name = 'a'
# 此处表示的是obj索引的name属性
obj.iloc[1]
# 同样可以使用DataFrame中的loc方法
其实也可以将series考虑为数组形式的字典
pd.series({'a':1,'b':2})
# 可以直接传入字典,键作为index
series的相加,其会自动对齐索引,也即是说,同样index的项才会发生相加
逐元素计算
ser.map(lambda x: x+10)
# 与DataFrame中的apply功能基本类似
# 返回一个计算结果series
检查缺失值
obj,isnull() # 返回series,对缺失值赋值为True # obj.notnull()实现相反的功能 pd.isnull(obj) # 通过函数实现了此功能
series.dropna(inplace=True)
# 可以实现去除空值的作用
- DaraFrame类型
DataFrame表示的是矩阵的数据表
其既有行索引,也有行索引,可以被视为一个共享相同索引的series的字典
一般来说其是二维的,不过也可以通过分层索引达到更高的维度
通过字典生成表
data = {'a' : [1,2,3] , 'b' : [1,2,3]}
frame = pd.DataFrame(data)
# 使用字典进行创建
# 注意此时键为表头(column),键值为表头对应的所有数据
# 该数据如果为序列,则序列索引就是表索引(index)
# 如果是两层嵌套的字典,外部键作为column,内部键作为index
fram = pd.DataFrame(data,columns=[1,2,3],index=[1,2,3])
# 此处可以自定义表的columns和index
通过array生成表
frame = pd.DataFrame(data) # 此处的data就可以是二维array # array可以是各种嵌套的序列通过numpy模块组成 # 手动为其定义column和index
通过追加的方式生成表
frame = pd.DataFrame() frame.['a'] = seq # 首先新建一个空的DataFrame # 然后通过列表的形式为列赋值 # 通过这种方式来实现追加赋值
如果索引名称相同,上表可能会发生数据覆盖
frame.insert(index,column_name) # 通过插入的方式,指定列索引位置,追加一列 # 此时只是增加了一列,但是没有数据 frame.append(new,ignore_index=True) # 在最后一行追加一行
# 注意其不会在原对象上更改
# 添加的对象一般为series,并且index与原表头一致
# 此处不用管index,相当于list的追加
较好的方法是建立一个表头固定的DataFrame
然后使用append追加行
- 查询表的属性
df.columns # 获取列索引 df.index # 获取行索引 df.axes # 返回一个列表 # 第一个元素是行索引,第二个元素是列索引 df.values # 去除DataFrame的表头等 # 返回一个数组ndarray对象 df.info() # 返回每列的元素类型 df.describe() # 显示数据的数量,缺失值,最小最大数,平均值,分位数
- 数据的重组和拼接
其拥有多种数据拼接的方法
df3 = pd.merge(df1,df2,how='inner',on='alpha') # how参数制定了其连接方式 # inner指的是内连接,也就是按照指定列进行交集连接,此处指定了列为alpha
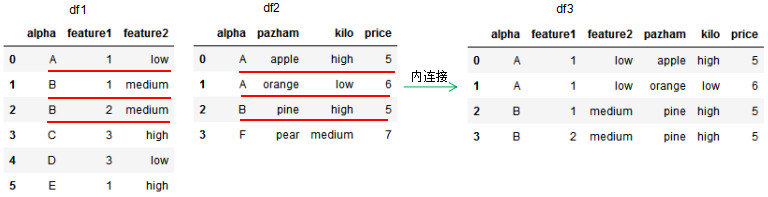
可以看出,此处指定的连接基准为alpha列,为内连接
其交集为A和B,也就是说每个A都要和另外一个表内的A进行连接
所以左侧有一个A,右侧有两个A,组合得到了就是两个A
(也就是各自有交集,这样合并起来,所有的列基本都有数据)
完成连接之后,就把其他列直接抄过来
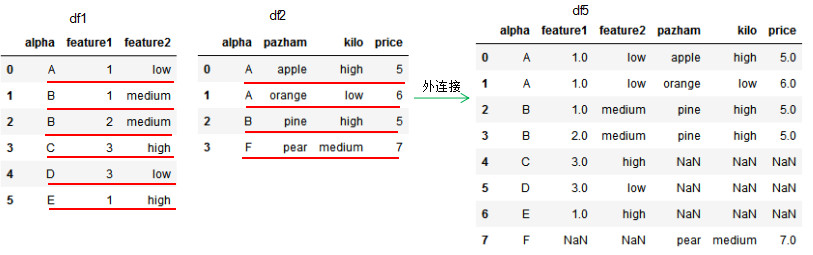
此处指定了外连接(how参数为outer),共有列名为alpha
也就是除了内连接得到的AABB之外
其他行也进行了照抄,只不过没有数值的地方为空值(也就是有些列会没有数据)
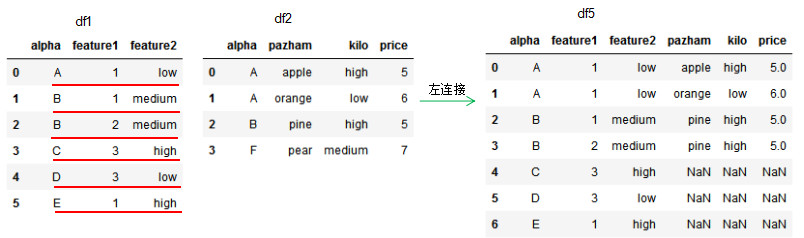
此处指定了左连接,how参数为left
可以看出,右侧的列中F并未进行连接
左连接实际上就是先完成内连接,然后再直接照抄左侧的其他行
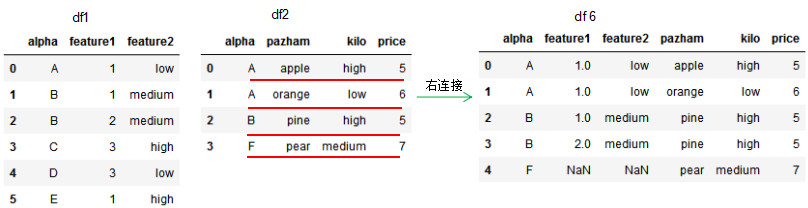
此处指定了左连接,how参数为right
df7 = pd.merge(df1,df2,on=['alpha','beta'],how='inner') # 实现多列连接
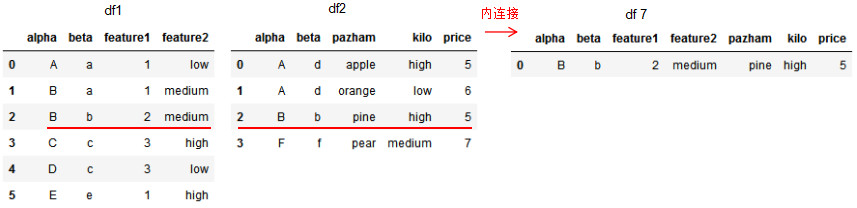
此处指定了多列,可以看出,其只有一个交集
(所以就只得到了一个交集)
df9 = pd.merge(df1,df2,how='inner',left_on='beta',right_index=True) # 也可以进行index的连接 # 同样也要指定列
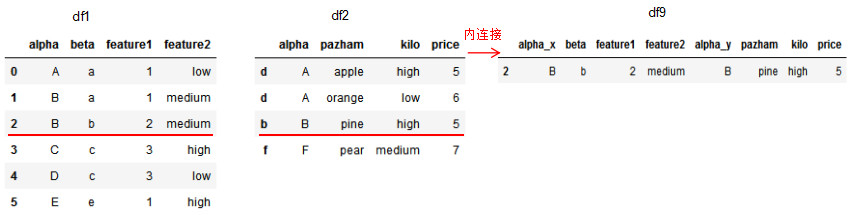
此时产生了alpha_x和alpha_y两列
pd.concat([df1,df2]) # 默认为行拼接,外拼接(并集)
# 注意传入的是一个列表
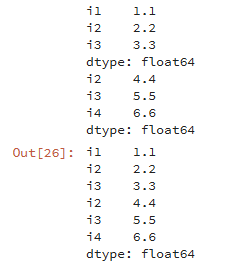
pd.concat([df1,df2],axis=1) # 进行列连接

pd.concat([df1,df2],axis=1,join='inner') # 进行内连接 # 对列进行连接

- 索引对象
frame.head() # 列出头部的五行查看详细信息 frame.columns # 返回一个index对象,表示表头 fram['a'] # 以字典标记的形式索引某列的数据
# 这个索引也可以是一个列表 frame.a # 以属性的形式索引某列的数据 # 其只在列名是有效的变量时才有效,一般不推荐使用 frame.loc['a'] # 通过loc属性的方式进行索引 fram['a'] = 1 # 此处会将该列的所有值赋值为1 fram['a'] = seq # seq为列表等序列,要求必须与dataframe的长度一致,序列索引就是index # 如果其为series,就会自动对齐索引(index),不存在的值为空值 # 如果索引的列不存在,就会直接新建,这也是追加数据的一个常用的方式 del fram['a'] # 用于删除此列
frame.T
# 进行转置来交换行列的轴
frame.values
# 返回二维的array
# 也可以对某行或者某列的数据返回为一维的array
索引对象是不可变对象,为labels,其允许重复的标签
可以直接在新建DataFrame的时候传入给columns和index
pd.index([1,2,3]) # 此处就返回了一个索引对象
index.tolist()
# 可以将一个索引对象转换为一个列表对象
index.to_series()
# 将索引转换为series
index。values
# 转换为数组
其同样也可以使用切片索引
对于series,在中括号中直接使用单个切片进行索引
obj[2:4] # 索引第2行到第3行的数据 obj[‘a':'c'] # 注意使用index名称进行切片时,其是要将末尾的index名称包括在内的
obj[obj['a']>0]
# 按照条件进行索引,实际上也就是一个筛选的过程
对于DataFrame
在中括号中传入单个值或者列表(包含着切片或者多个值),可以对列进行索引,表示在轴1进行选择
在中括号中直接传入切片或者布尔数组,可以对行进行索引,表示在轴0进行选择
(行索引使用整数对应的切片,列索引使用字符或者字符组成的列表切片)
data[:2]
# 选择第0行和第1行
# 因为行方向一般为整数
data[data['a']>0]
# 索引指定条件的行
# 因为此时指定的布尔条件是一列,所以是在轴0的方向上进行判断
data['a'] # 索引a这个列
# 因为列方向一般为字符
data[['a':'b']] # 索引a到b之前的所有列,包括b这个列
data.loc[data.index != 'a',data.columns != 1]
# 选择index不等于a,column不等于1的数据
# 可以直接指定index和column来确定
也可以使用loc(字符串)和iloc(整数)进行索引,其支持切片,列表,单值,布尔,使用逗号隔开
推荐使用iloc和loc,其表意更加清晰
注意iloc和loc之间的区别
iloc是以整数的序列来进行索引,其与数据表中自带的行和列索引没有关系,只与其位置有关系
当表中某些行被删除后,使用iloc来进行索引同样位置(iloc对应的索引)的元素就会发生变化
loc是使用数据表中自带的行和列索引
当表中某些行被删除后,使用loc索引同样位置的元素不会发生变化,因为每个数据对应的loc索引是固定不变的
当数据表发生变化时,建议使用loc
另外注意loc的切片包含了后面一个元素,于传统的切片不一样
重建索引
obj.reindex([1,2,3]) # 重建索引,注意此时索引与数据的对应关系仍然存在,只是更换了顺序 # 如果有些索引不存在,则填充为空值 obj.reindex([1,2,3],method='ffill') # 选择为不存在的索引的数据填充方式,如果不指定则默认填充空值 # ffill为前向填充(如果索引不存在,复制该索引的前一个值进行填充),bfill为后向填充
# 也可以使用fill_value来手动指定填充值
索引可能会含有重复索引值
同一个索引值可能会得到多组数据
修改索引列或者行
df.columns = seq df.index = seq # 直接传入序列来覆盖掉之前的索引 df = df.rename(columns={a:A,b:B},index={a:A,b:B}) # 可以同时对index和column进行更改 # 需要传入字典,键为原值,值为新值
- 删除数据
obj.drop(['a','b']) # 删除index为a和b的行 # 默认的删除轴为0轴,也就是在行方向上进行删除 obj.drop(['a','b'],axis=1) # 删除column为a和b的列 # 此时指定的删除轴为1轴 obj.drop(['a','b'],axis=1,inplace=True) # 直接在原表中进行修改,其会直接清除被删除的数据
data.drop(data.iloc[[index],:].index)
# 注意行索引为一个列表,此时才会输出索引,否则会输出列名
# ???
- 计算
DataFrame的相加,其会自动对齐column和index,得到结果
如果有一个无法对齐,则生成一个空值
如果有两个行列索引完全不同的表相加,则全部均为空值
df1.add(df2,fill_value=0) # 将df1和df2相加,出现空值使用0进行填充 # 也有radd()函数表示反转参数
将二维数组与一维数组相减,其会在二维数组的每一行进行相减,这就是广播机制
np.abs(frame) # numpy中的逐元素函数在pandas中也适用
更推荐使用apply方法来对DataFrame进行逐元素操作
frame.apply(function,axis=0) # 如果function是一个聚合函数(多个数据返回一个结果),则需要指定轴 # 指定轴0说明其要在行方向上进行计算,在每行被调用,计算每行的结果 # 此时传入的数据就是一个一维的series,输出为单个值 # 如果function是一个一般的函数(不进行聚合),则不需要指定轴 # 此时函数的传入数据就是单个值,传出数据也是单个值 # 对于function,可以使用匿名函数,也可以直接定义函数
# 当然function也可以返回series,其也可以看作聚合函数,指定轴
# 在每个轴上都会有一个series结果,结果就是每个轴上series构成的表
也可以使用applymap方法来进行格式化
frame.applymap(lambda x:'%.2f'%x)
# 对每个元素进行格式化
# 其会针对所有元素应用这个函数
内建的统计计算方法
df.sum(axis=0,skipna=False) # 在轴0方向上求和,也就是求每列的和 # 返回一个series # 拥有多种方法,count用于计算非空值的个数,mean用于求取均值
其他属性
obj.unique() # 获得唯一值 obj.value_counts() # 计算一列中不同种类数据的个数 obj.isin(['b']) # 返回布尔series,统计每列数据中是否包含b
按行或者列求和
#按行求和
df['row_sum'] = df.apply(lambda x: x.sum(), axis=1)
#按列求和
df.loc['col_sum'] = df.apply(lambda x: x.sum())
# 使用apply函数针对整个df进行操作
# apply默认为axis=0,即以每一列的所有元素进行一次计算,获得一个结果
# 使用匿名函数lambda,定义了变量x,实际上就是每列元素中的一个值
# 也可以直接进行计算
# 列求和
df.loc['col_sum'] = limit_data1.sum()
# 行求和
df['row_sum'] = df.sum(axis=1)
- 排序
frame.sort_index(axis=1) # 将元素按照轴1索引(也就是columns)进行重新排序 # ascending = False 可以指定为降序 frame.sort_values(by='b') # 表示以b列的数据作为标准,进行升序排列 # by参数也可以传入一个列表,仅在列表的第一个值有相同元素时才会考虑第二个值 # 可以按照某行(在轴1排序)或者某列(在轴0排序)的数据进行排列,在输入by对应的值时,如果索引是字符串,则输入字符串,如果是浮点,则输入浮点
# ascending参数设置为False为设置为降序
frame.rank(method='max') # 该函数主要用于计算数据的名次 # 有多种method # first表示出现重复数据时,谁先出现谁就排在前面,没有重复的名次 # min表示出现重复数据时,取最小的排名作为重复数据的名词,此时有重复的名次,并且会占位 # max表示出现重复数据时,取最大的排名作为重复数据的名词,此时有重复的名次,并且会占位 # dense表示出现重复数据时,取相同的排名,此时有重复的名次,并且不进行占位 # average表示出现重复数据时,用1除以重复数据的个数获得一个平均排名值,此时有重复的名次,其会进行占位
- 数据读取
csv文件(也可以使用csv模块来进行操作)
pd.read_csv('name',sep=',',names=['a','b'],index_col='a',skiprows=[0,1,3],na_values=['null']) # sep参数用于指定换行符,csv文件的换行符为逗号,此处实际上不需要再进行指定 # names参数为导入的csv表重新指定column # 默认认为第一行为其column # 也可以使用header指定用作列名的行数 # index_col用于指定索引行,默认认为第一列是索引列 # na_values用于指定缺失值的展现形式 # encoding参数用于指定文本的编码
行索引请定义为整型数字组成的序列,其具有唯一性,也方便遍历
(不要使用时间索引或者其他无规律的索引)
涉及到分块读取的参数
# skiprows用于跳过某些行 # nrows参数用于表示读入的行数,避免一次性读取大文件,通常用在调试程序的过程中
# chunksize参数可以设置每个块的行数,返回一个textfilereader对象,可以用于遍历
json文件(也可以使用json模块)
pd.read_json('name') # 自动将json中的键(只能为字符串)转换为行或者列中的标签
xml文件(也可以使用lxml模块)
pd.read_html('name') # 读取html文件
excel文件
pd.read_excel('name','sheet1') # 如果excel文件中有多个工作簿,此处可以指定
sql文件(可以使用sqlite3模块)
- 数据导出
csv文件
data.to_csv('name',sep='|',na_rep='null',index=False,header=False) # sep用于指定输出的分割符 # na_rep指定展示缺失值的形式 # index和header用于指定是否输出
json文件
data.to_json('name') # 可以将其转换为json格式的数据
excel文件
pd.to_excel('name','sheet1') # 如果excel文件中有多个工作簿,此处可以指定
- 数据清洗
一般以行作为单位来进行数据清洗,因为行一般认为是record
检查缺失值
data.isnull() # 按照原数组的格式,返回布尔值 # 空值显示为True # notnull为其反函数 data.isnull().any() # 其会按照行的统计缺失值,有缺失值就会认定为True,使用all(),需要全部为缺失值才会认定为True
# 返回每列对应的缺失值情况
data.isnull().sum() # 其可以按照行统计缺失值的个数,返回一列作为统计数据
过滤缺失值
data.loc[data.isnull().any():,] # 索引出没有空值的行 data.dropna(how='all') # 删除有空值的行 # 也可以传入axis=1来删除具有空值的列 # thresh参数表示保留下来的每一行,其非NA的数目>=该值 # 相当于确定了一个阈值 data.fillna(0,method='bfill') # 对缺失的值进行填充 # 可以传入value参数设置填充值0,也可以传入method参数确定是ffill还是bfill # 除了0,也可以传入字典,为每一列的空值填入不同的值 # 传入inplace=True可以直接在当前组进行更改 # 传入axis可以指定填充的轴,也就是指定基准的轴
检查重复值
data.duplicated() # 按照行来统计是否存在重复的行,注意对比的元素是行 # 若存在两行重复,则标记第二行为True # 默认是统计轴0 # 返回一个series
过滤重复值
data.drop_duplicates(['a','b'],keep='last') # 返回duplicated检查为False的行 # 此处以a列和b列同时重复作为判断标准 # 默认是保留第一个观测的值,使用keep参数可以指定保留最后一个观测值(last)
进行数据转换
convert = {'a'='A','b'='B'}
data['result'] = data['a'].map(convert)
# 通过map方法,其会按照字典的转换规则对该列(实际上是series)进行转换
# 也可以在map方法中传入一个函数(一般匿名函数即可)
data.replace([-999,1000],np.nan)
# 将-999和1000都替换为空值标记
# 参数也可以为两个列表(或者一个字典),其两个值之间有对应关系
data.index.map(convert)
# 可以使用map方法进行索引重建
data.rename(index=str.title,columns=str.upper,inplace=True)
# 可以重新分配行和列的索引名
# 使用inplace参数可以直接在原位置上进行更改
检测异常值
data[np.abs(data) > 2] # 注意此时data为一个series,当然可以是DataFrame索引的一个列 # 返回数值大于2的行 data[(np.abs(data) > 2).any(1)] # 注意此时的data为一个DataFrame # 返回所有存在着绝对值大于2的值的行 # any的参数1指定了轴方向,表示在轴1方向上统计 # any实际上就是一个聚合函数,此处在轴1上进行聚合
数据的空格需要进一步处理
(存在空格会导致索引出错,并且很难被发现)
一般空格来自于字符串,所以以下介绍字符串中空格的处理方法
string.lstrip() # 返回一个去除左侧空格的字符串 string.rstrip() # 返回一个去除右侧空格的字符串 string.strip() # 返回一个去除两侧空格的字符串 string.replace(" ", "") # 去除所有空格,包括内侧的空格
以下方法可以用于清除数据表的表头空格
columns_strip = data_all.columns.map(lambda x:x.strip()) # 索引实际上也是一维序列,可以使用map方法进行逐元素计算 # 此处就使用map进行空格去除 data_all.columns = columns_strip # 更改列名
相邻数据之间的比较
df a b c 0 1 1 1 1 2 1 4 2 3 2 9 3 4 3 16 4 5 5 25 5 6 8 36 # 计算元素之间的差值
df.diff(periods=1, axis=0)
# periods为平移的距离,为正则为向前平移(此时第一行就为NA)axis为平移的轴,0则为纵向平移 df.diff()
a b c 0 NaN NaN NaN 1 1.0 0.0 3.0 2 1.0 1.0 5.0 3 1.0 1.0 7.0 4 1.0 2.0 9.0 5 1.0 3.0 11.0 # 返回的数据具有相同的行数 #计算元素之间的比值
df.pct_change(periods=1) df.pct_change() a b c 0 NaN NaN NaN 1 1.000000 0.000000 3.000000 2 0.500000 1.000000 1.250000 3 0.333333 0.500000 0.777778 4 0.250000 0.666667 0.562500 5 0.200000 0.600000 0.440000
# 返回的数据具有相同的行数
删除存在指定值的行
data_deleted_0 = data.drop(data[(data[column_name] == 0)].index)
# 此处使用了布尔索引进行选择,随后输出符合条件项的index,最后使用drop来删除数据
- 时间处理
使用datetime对非标准时间进行处理
df_bank['a'] = df_bank['a'].astype('str') df_bank['a'] = df_bank['a'].apply(lambda x:datetime.datetime.strptime(x,'%Y%m%d')) # 首先要注意的是要将其转换为str格式,否则将无法转换为指定的时间格式 # 然后使用datetime.datetime.strptime()函数进行解析 df_data['时间'] = df_data['时间'].apply(lambda x:x.value) # 转化为结构时间就可以使用其属性
| %a | 本地(locale)简化星期名称 |
| %A | 本地完整星期名称 |
| %b | 本地简化月份名称 |
| %B | 本地完整月份名称 |
| %c | 本地相应的日期和时间表示 |
| %d | 一个月中的第几天(01 - 31) |
| %H | 一天中的第几个小时(24小时制,00 - 23) |
| %I | 第几个小时(12小时制,01 - 12) |
| %j | 一年中的第几天(001 - 366) |
| %m | 月份(01 - 12) |
| %M | 分钟数(00 - 59) |
| %p | 本地am或者pm的相应符 |
| %S | 秒(01 - 61) |
| %U | 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 |
| %w | 一个星期中的第几天(0 - 6,0是星期天) |
| %W | 和%U基本相同,不同的是%W以星期一为一个星期的开始。 |
| %x | 本地相应日期 |
| %X | 本地相应时间 |
| %y | 去掉世纪的年份(00 - 99) |
| %Y | 完整的年份 |
| %Z | 时区的名字(如果不存在为空字符) |
| %% | ‘%’字符 |
timestamp:表示某个时间点
data.to_timestamp() # 更改为时间戳
period:表示某个时间跨度。称之为区间,对应着特定的频率(比如为每月)
data.to_period('M') # 其就会将该数据中的时间频率更改为M,也就是月
timedelta:表示不同单位的时间,是时间点的抽象
pd.to_datetime(df["time"]) # 如果表中的时间项格式为object或者str,就需要用如上的函数将其转化为datetime格式
timestamp也具有很多属性
d=pd.Timestamp.now() # d # Timestamp('2019-01-16 20:41:19.035134+0800', tz='Asia/Shanghai') # 返回当前时刻的时间戳 d.tz # 返回时区<DstTzInfo 'Asia/Shanghai' CST+8:00:00 STD> d.tzinfo # 返回时区信息<DstTzInfo 'Asia/Shanghai' CST+8:00:00 STD> d.weekofyear # 3 d.dayofweek # 2周三 d.dayofyear # 16 d.days_in_month# 31 d.daysinmonth # 31 # 返回时间所处的次序 d.day # 16 d.microsecond # 35134 d.minute # 41 d.month # 1 d.nanosecond # 0 d.quarter# 1 d.second# 19 d.week # 3 d.year # 2019 d.hour # 20 # 拆分时间,分成各个块 d.fold# 0 d.freq d.freqstr # 返回时间的频率 d.is_leap_year # False d.is_month_end # False d.is_month_start # False d.is_quarter_end # False d.is_quarter_start# False d.is_year_end # False d.is_year_start # False # 进行时间判断 d.value# 1547642479035134000 # 返回一个unix时间标记,为纳秒,转化为秒需要除以十的九次方
进行转换
df['year'] = df['time].apply(lambda x:x.year) # 通过apply执行匿名函数,将其时间的属性作为列值 df['str_time'] = df['time'].strtime('%Y-%m') # 利用strtime()函数来将标准时间格式转换为想要的时间格式,此处就是几年几月
时间的计算
df['time'] + pd.Timedelta(days=-1) # 对该列中所有的时间项都减去一天
timedelta也有如下属性
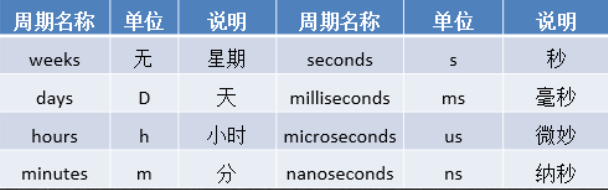
两个timestamp作差,就会得到一个timedelta,使用timedelta的属性就可以获得一定格式的时间差
生成时间索引
pd.data_range('1/1/2000',periods=1000) # 可以生成一个由2000年1月1日开始,1000天的时间序列
# 也可以直接传入起始和终止时间,分别对应了start参数和end参数
# 可以作为index使用
以时间作为索引是较好的方式(如果数据表中有时间列),因为时间列通常不会重复
pd.read_csv('name',sep=',',names=['a','b'],index_col='a',skiprows=[0,1,3],na_values=['null']) # 在导入时设置index_col为时间序列
时间范围索引
data['1/1/2020'] # 输入时间格式的字符串 # 可以直接索引到该项数据 data['2001-5'] # 可以直接索引到2001年5月的数据 # 该方法也可以直接套用到DataFrame的loc方法中 data[datetime(2011,1,1):'] # 也可以直接使用切片,查找自此处开始的所有数据 # 此处使用了datetime格式的数据 data[‘2011/1/1’:] # 与上式有相同的效果 data.truncate(after='1/9/2011') # 获得该日期之前的所有数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号