MySQL-简单查询
- 开启和关闭
mysql -uroot -p3306 -p
使用如上,输入用户名及端口号,然后输入密码即可完成用户登录
再键入exit即可退出
Linux系统中进行如下操作
service mysql start
service mysql stop
service mysql restart
检查是否启动
ps -ef | grep mysqld
数据库(database)一般包含了多个表(table)
使用模式(schema)来定义数据库和表的属性
表由列(column)组成,每个列都必须指定数据类型(datatype)
列也可以称为字段(field)
表中的每一条数据是按照行(row)来存储的
一条记录(record)等价于一行(row)
每个表应有一个主键(primary key)来精准定位到行,所以主键唯一,并且不能为空
可以使用多个列作为主键,此时就会形成列值的组合
- 数据库操作
注意需要添加分号,否则会报错
create database A if not exists; #创建数据库A
drop database B if exists; #删除数据库B
show databases; #显示已有的数据库 use A; #将数据库A作为工作数据库 select database(); #查看当前的工作数据库 show tables; #显示工作数据库拥有的数据表 show tables from B; #显示数据库B中的数据表,无需use B
show columns from a; #显示表a每一列对应的属性,包括数据类型等等 desc a; #查看表a的详细信息 select * from a; #查看表a的所有数据
select version(); #查看当前的版本
select user(); #查看当前的用户
create table if not exists b ( #创建表
'id' int unsigned auto_increment, #整型,具有自增属性
'aa' date,
'bb' varchar(40) not null, #此处不能为空
primary key ('id') #定义id为主键
)ENGINE=InnoDB DEFAULT CHARSET=utf8; #设置存储引擎和字符集
drop table b if exists; #删除表b
创建和删除时,需要使用exists以保证操作不会报错
不区分大小写,建议关键字大写,表名大写
单行注释 # 或者-- (注意此处要有一个空格)
多行注释 /* */
- 插入数据
insert into A ('aa','bb') values (1,2)
上述操作可以为字段添加值
注意插入数据是一条一条的插入
- 更新数据
update A a=1,b=2 #对表A更新a和b两个字段
可以更新多个字段的数据
- 删除数据
delete from A where id = 2 #删除表A中id为2的行
delete from A #删除表中所有数据
当你不再需要该表时, 用 drop
当你仍要保留该表,但要删除所有记录时, 用 truncate
当你要删除部分记录时, 用 delete
delete 和 truncate 仅仅删除表数据,drop 连表数据和表结构一起删除
delete 是 DML 语句,操作完以后如果没有不想提交事务还可以回滚,truncate 和 drop 是 DDL 语句,操作完马上生效,不能回滚
执行的速度上,drop>truncate>delete
- 数据类型
数值类型:严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)
|
TINYINT |
1 byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期及时间:DATETIME、DATE、TIMESTAMP、TIME和YEAR。
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 |
1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 |
YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型:字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
- select子句
首先要指定use的database
select x from a; #从表a中提取字段为x的数据
select x,y from a; #从表a中提取字段为x和y的数据 select 常量值; (字符型,日期型的常量必须用单引号括起来) select ‘john’; 字符 select 100; 数字 select version(); 函数,返回一个值 select 100/90; 表达式,相当于运算 select a as B; 可以取别名,为某个字段或者表达式等取别名 或者写为 select a A, b B from data; (注意此处是一个as对应一个字段,可以省略as,直接使用空格替代) 如果出现特殊字符,应该使用引号。一般来说,里面的中文不需要加引号。 select distinct 字段 from table 去重查询,可以先对数据进行了解 (此处字段不能是多个,否则会产生不规则的查询结果)
select x from a limit 100 offset 10; #查询表a的x字段数据,从第10条开始,查询100条
select distinct a,b from A; #选择a列和b列的非重复值
select可以看作是获得了一个返回的结果,相当于return
select 100+90; # 直接进行加法运算 select ‘123’+90; # 试图将字符串123转换为数值,如果成功,再去进行加法运算。如果失败,这个字符串就变成0. 可以看出,sql中加号就是运算符,没有其他的连接等功能。 select concat(‘a’,’b’,’c’) as d from table; # 这个表达式就实现了将a,b,c三列的数据合并,最后以d作为表头展示出来
- where子句
select a,b from A,B where a=b #筛选a=b的数据
where筛选条件(类似于if,对字段下面的数据,亦或是常量,字符等进行逐个筛选)
包括条件运算符(> < = !=)(注意此处使用的是=而不是==)
逻辑表达式(&& || and or not,用于连接条件表达式)
(当有多个条件运算符时,使用圆括号来指定顺序,and比or具有更高的优先级)
in操作符,例如wher id in (100,110),指定id为100或者110的数据,这是另一种指定离散范围的方法
模糊查询(between 1 and 2)
空值(is null或者is not null)
not取反,例如where id not in (1,2)或者where id not between 1 and 2或者not exists
- like子句
其会匹配一个类似于正则表达式的式子
%:表示任意 0 个或多个字符。可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)。表示任意次数,非严格占位
其不能匹配null值,通常用于匹配首部或者尾部为特定字符的数据
_:表示任意单个字符。匹配单个任意字符,它常用来限制表达式的字符长度语句。其为强匹配,严格占位
'%a' //以a结尾的数据 'a%' //以a开头的数据 '%a%' //含有a的数据 '_a_' //三位且中间字母是a的 '_a' //两位且结尾字母是a的 'a_' //两位且开头字母是a的
- regexp子句
regexp提供了正则表达式支持
假设a字段有a1000这个列值
select a from A where a like '1000' #并不会返回任何结果 select a from A where a regexp '1000' #其可以返回a1000这个值
like匹配整个列值,如果其仅仅部分出现,是无法匹配到的
而regexp则可以匹配到部分值,也就是包含了正则中定义的内容就可以
regexp '100' | '200' #使用or来连接多个正则表达式
[]:表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个
实际上其也完成了or的操作,[123]也可以为[1 | 2 | 3]
[^] :表示不在括号所列之内的单个字符。其取值和 [] 相同,但它要求所匹配对象为指定字符以外的任一个字符
注意[]匹配单一字符,是严格占位的字符
[1-9] #匹配1到9的所有数字 [a-z] #匹配a到z的所有字符
如果需要匹配到特殊字符,可以使用转义字符(\\)
第一个斜杠用于MySQL,第二个斜杠用于正则表达式
以上都是匹配到单个字符,下面可以使用一个表达式来匹配到多个字符
(注意以下匹配符号都放置在匹配内容的后面)
{n} 指定n个数目的匹配
{n:} 不少于n个数目的匹配
{n , m} 匹配数目的范围,为n到m
* 用于0个或者多个匹配,表示可有可无,不严格占位
+ 用于1个或者多个匹配,相当于{1, },表示必须有,不严格占位
? 用于0个和1个的匹配,相当于{0,1},表示可有可无,严格占位
以上正则表达式都是匹配数据中的任何位置,也可以指定位置进行匹配
这也是其与like之间的主要区别,like匹配整个串,regexp匹配子串
(注意以下的匹配符号都放置在匹配内容的前面)
^ 指定文本的开始 (在[ ]中即为取反)
$ 指定文本的结尾
[ [ :<: ] ] 指定词的开始
[ [ :>: ] ] 指定词的结尾
- union语句
select a from A union select b from B
连接多个语句的结果,组成一个结果集合
用于将不同表中相同列中查询的数据展示出来
注意其会删除重复的数据
UNION ALL 语句可用于将不同表中相同列中查询的数据展示出来;(包括重复数据)
- order by语句
select a,b,c from A order by a ASC #将查询的数据按照a字段数据的升序排列
ASC为升序排列,DESC为降序排列
也就是使用order by来指定作为排序依据的列,需要放在where的后面
当未使用该子句时,返回的结果通常是随机或者无序的
可以以多个列作为排序依据
使用多个列作为排序依据,一般是因为第一个列有些元素是相同的,需要借助第二个列来对这些相同的元素进行辅助排序
(此时可以对多个列指定DESC或者ASC)
如果第一个列没有重复元素,第二个列就没有作用
- group by语句
此处会涉及到分组函数,其实现统计功能
可以对多个同类型值计算得到一个统计值
Sum 求和(数值型) avg 平均值(数值型,只能用于单个字段) max 最大值 min 最小值 count 计算个数(非空个数,count(*) 会计算空值)
这些函数均是忽略null值的
count(distinct data) #可以判断出种类 count(字段) #获得该字段的非空数据个数,实际上也就是行数,通常将其作为一个已知数据来作为筛选条件 select count(*) from tables; #可以获得行数(此处注意计算了所有行,但是不包括全为null值的行)
注意聚合函数和单行函数(或者查询字段)一同查询,会产生不平衡的结构
所以后文会使用group by来进行统一
select max(salary),job from tables group by job; #查找每个job类别的最高工资
首先确定作为分组依据的列,此处为job列
(能作为分组依据的列,其内一定有很多相同的数据,这样才能将其划分为一组)
其次在每一个分组内计算统计值,此处对每个分组的值计算了max,同时获得了这个分组的类别
(注意使用了作为分组依据的列名,返回的是经过distinct的分组的类别,也就是每个分组给了一个组名,但不能使用其他列名,否则会出现不平衡的结构)
一般来说,group by是较先执行的,后面再在分好的组中执行其他筛选条件
一般使用了grop by之后要去使用order by,以保证分组之后能够更好的排序
- having语句
用于对where和group by查询出来的分组经行过滤,查出满足条件的分组结果
where只能对行进行过滤,其无法对分组结果进行过滤
它是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作。
- 执行顺序
FROM, including JOINs 需要检索的表,仅在从表中选择数据时使用
WHERE 行级别的过滤,非必须
GROUP BY 分组说明,仅在需要计算聚合结果的时候使用
HAVING 组级别的过滤,非必须
WINDOW functions
SELECT 要返回的列或者表达式,必须使用
DISTINCT
UNION
ORDER BY 输出排序顺序,非必须
LIMIT and OFFSET 要检索的行数,非必须
- 函数的结合
select *,function(*) 结果 from A #对表A中所有字段执行function计算,并为结果取了别名
使用这种方式,可以对筛选出的数据进行计算
最后可以分别将原始数据和计算结果展现出来(别名可以更好理解这个过程)
length() 获取参数值的字节个数 concat() 用于拼接字符串 upper() 变成大写 lower() 变成小写 select substr(‘ABC’,2,2) output 提取字符串的元素(类似于字符串切片,截取子串),此处提取的是BC (在sql语言中,所有的索引都是从0开始的,使用2,2的方式表示从第二个开始,取两个长度的字符,而不是起始的索引,即BC) instr(‘abc’,’bc’) 返回子串的起始索引,此处返回2,如果找不到返回0 trim(‘ abc ’) 可以去除空格 如果想去除其他的字符,可以使用trim(‘a’ from ‘aaaaaabcaaa’) (注意只是两侧的字符,不包括中间的字符) lpad(‘aa’,10,’*’) 用指定的字符进行左填充至指定的长度,当然也可以右填充,即rpad replace(‘abb’,’b’,’a’) 在字符串里面把某一个元素替换为了新的元素
- 数学计算函数
round() 四舍五入 round(1.567,2) 四舍五入到小数点后两位,就是1.57 ceil() 向上取整,返回大于等于该参数的最小整数,向下取整则为floor() truncate(1.6999,1) 直接截断,不做四舍五入,此时就是1.6 mod(10,3) 取模,结果为1 rand() 获取0-1随机数
- 时间处理函数
now() 返回当前系统的时间 curdate() 返回当前日期,不包含时间。 curtime() 返回当前时间,不包含日期(current,指现在的时间) year(now()) 对返回的系统时间进行处理,此时只返回年份字段 同时也有,month() 返回月份,monthname() 可以返回英文的月份
以上的参数都是标准的时间格式
标准时间格式的部分被提取
Date() #返回一个标准时间格式对应的日期 Time() #返回一个标准时间格式对应的时间 同时也有 year() month() day() hour() minute() second()
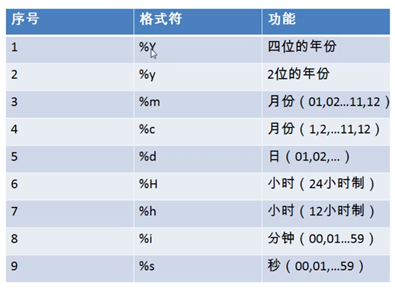
# 将一般时间格式转换为标准时间格式
str_to_date(‘9-13-1999’,’%m-%d-%y’)
# 这种格式用于告知系统哪一个对应的什么东西,也就是用后面的格式(注意要精确匹配,包括空格等等)解析前面的字符(这个一般就是字段里面的内容)
# 最终会返回系统默认的日期格式
# 将标准时间格式转换为一般时间格式 date_format(‘2018/6/6’.%y年%m月%d日)
# 完成任意的时间格式转换,系统会自动从标准时间格式中提取出%y,%m,%d,
# 此处就会返回2018年06月06日
datediff(‘a’,’b’) #可以获得两个日期之间相差的天数
- 字段操作函数
实现字段之间的拼接
select Concat(RTrim('a'),LTrim('b')) from A #将两个字段的数据合并
此处就相当于对字段使用了函数,只不过合并函数的参数是多个字段
RTime()函数的参数为单个字段
使用RTrim()去除右边的空格,LTrim()可以去除左边的空格
此时可以使用别名来为计算结果命名
- 文本处理函数
Left()返回串左边的字符
Length()返回串的长度
Locate()返回串的一个子串
Lower()将串转换为小写
Right()返回串右边的字符
SubString()返回子串
Upper()将串转换为大写

 浙公网安备 33010602011771号
浙公网安备 33010602011771号