pandas模块
- series的map方法
对某列中的数据集中进行某个操作
比如对gende这一列,将显示为男的替换为1,女的替换为0
#①使用字典进行映射
data["gender"] = data["gender"].map({"男":1, "女":0})
#②使用函数
def gender_map(x):
gender = 1 if x == "男" else 0
return gender
#注意这里传入的是函数名,不带括号
data["gender"] = data["gender"].map(gender_map)
可以使用字典映射,字典表示了一种替换规则,键为列中迭代的元素,值为需要进行的操作
(字典需要列出列中所有想要操作的元素来进行替换)
也可以使用函数,函数的传入参数就是列中的所有元素,比如上文的x
函数的返回值就是需要对列中所有元素替换的值
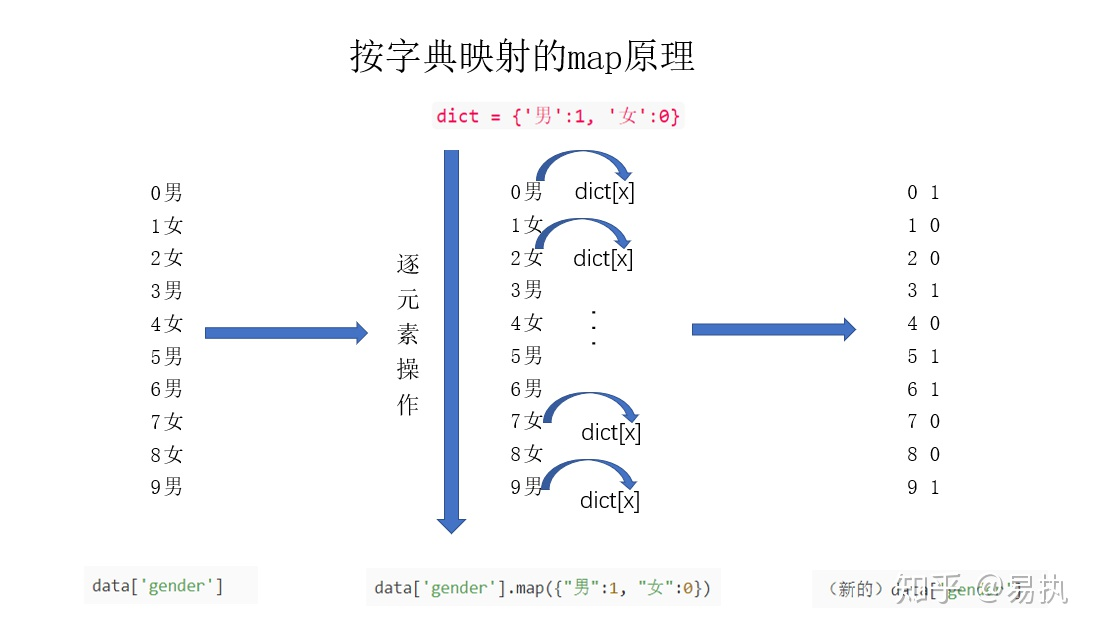
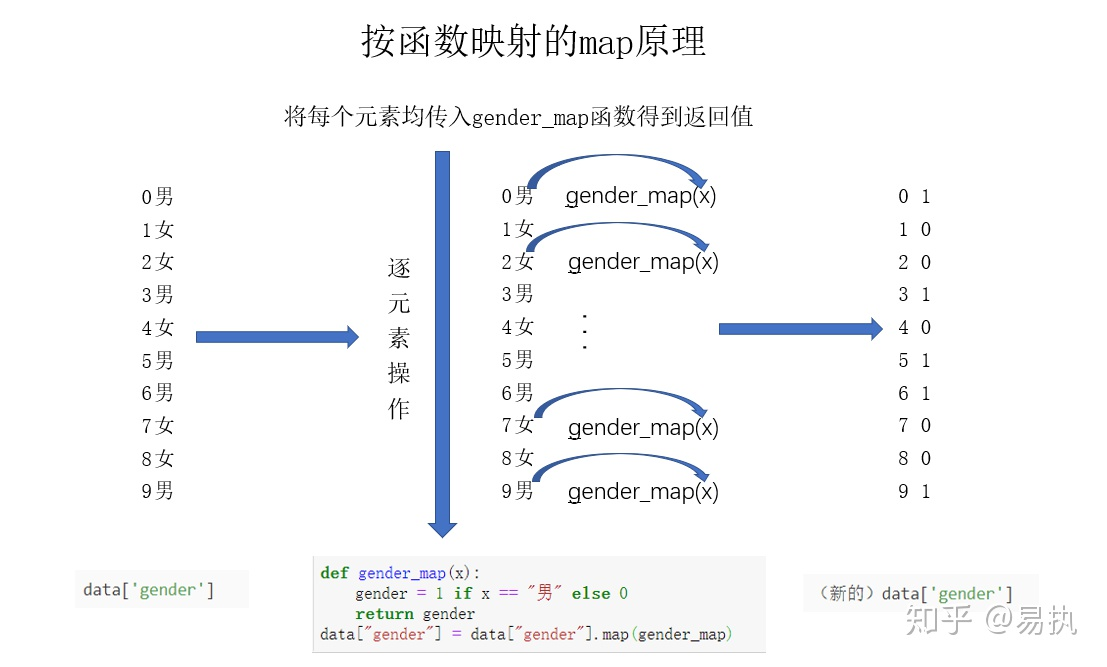
不论是利用字典还是函数进行映射,map方法都是把对应的数据逐个当作参数传入到字典或函数中,得到映射后的值。
- series的apply方法
map方法只能传入一个参数,也就是列中所有的元素
apply方法可以接受多个参数,也就是说这个自定义函数可以指定除列元素本身的其他参数
def apply_age(x,bias):
return x+bias
#以元组的方式传入额外的参数
data["age"] = data["age"].apply(apply_age,args=(-3,))
- Datafram中的apply方法
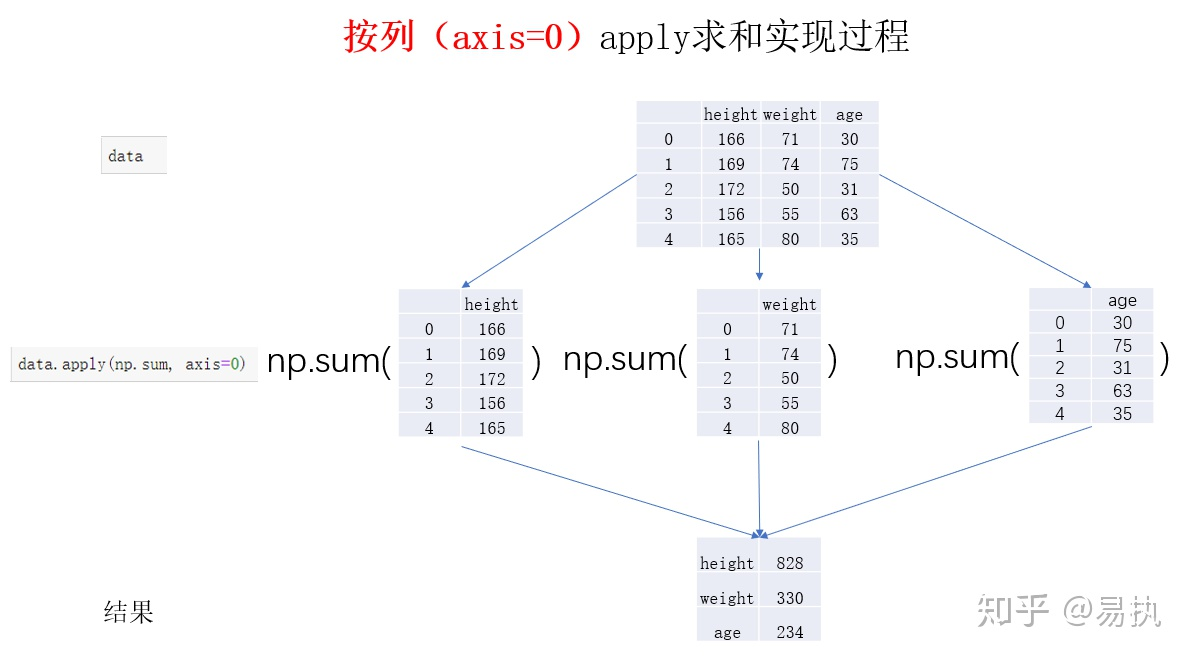
在DataFrame对象的大多数方法中,都会有axis这个参数,它控制了你指定的操作是沿着0轴还是1轴进行
axis=0代表操作对列columns进行,axis=1代表操作对行row进行(纵向为0轴,横向为1轴)
(与series的apply方法相比,其可以直接对多行或者多列进行操作)
使用内置函数np.sum和np.log来对列元素进行操作,内置函数会将前面的列元素(各列实际上都变成series,此处有好几个series,对每个series分别进行计算)都作为参数进行求和
注意np.sum和np.log返回的结果格式是不一样的
np.sum对1个series计算只会返回1个值,此处传入3个series,则获得了3个值,返回1个series
可以使用data['result']来接收
np.log对1个serie返回所有列元素对应的值,此处传入3个series,则获得了3*列长度个值,返回3个series
可以使用data[['height_log','weight_log','age_log']]来接收
# 沿着0轴求和 data[["height","weight","age"]].apply(np.sum, axis=0) # 沿着0轴取对数 data[["height","weight","age"]].apply(np.log, axis=0)

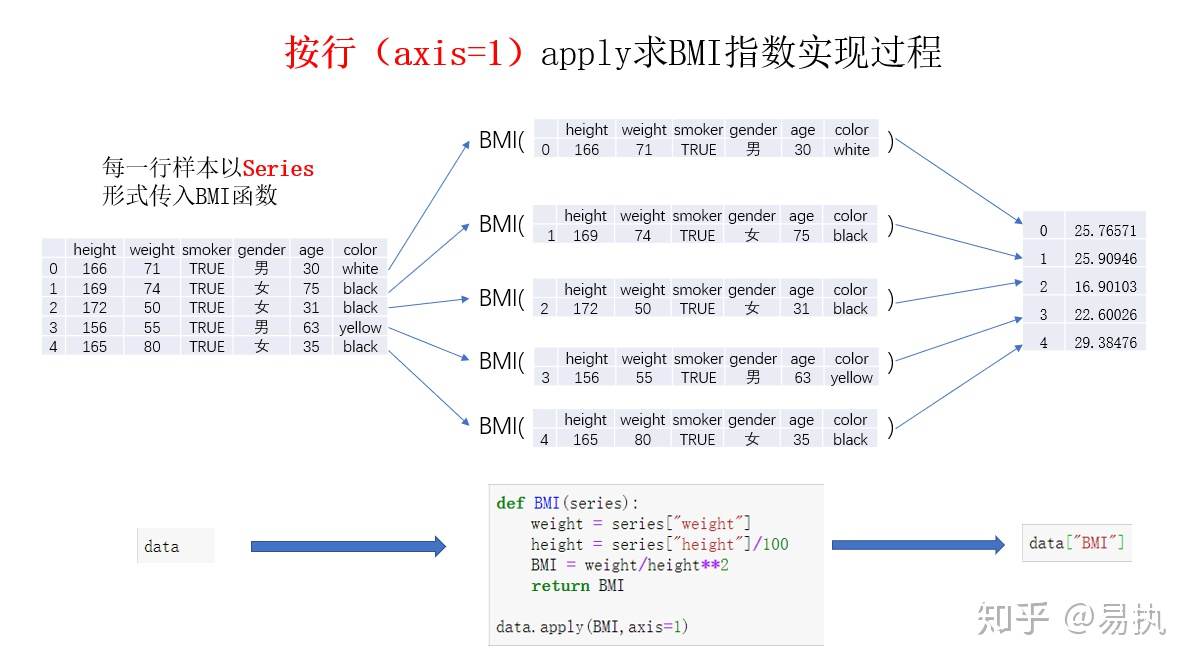
def BMI(series): weight = series["weight"] height = series["height"]/100 BMI = weight/height**2 return BMI data["BMI"] = data.apply(BMI,axis=1)
# 返回的值可以使用单独的列来进行承接,也可以直接在原列上进行替换
# 此处的传出数据为一列
注意函数参数是单个series(因为axis为1,此时就是一行),函数内部使用列索引(就是取行内的单个元素),返回的为单个series
(如果axis为0,此时就是一列,使用行索引来确定单个元素进行计算,dataframe的特殊之处就在此,其需要在函数内部再去索引来确定使用的元素类型)
- Dataframe中的applymap
df.applymap(lambda x:"%.2f" % x)
该方法的作用是为Dataframe中的所有参数都套用这个函数

- groupby
group = data.groupby("company")
其会按照company这一项进行分类,此时group是一个DataFrameGroupBy对象,包含了多个子Dataframe
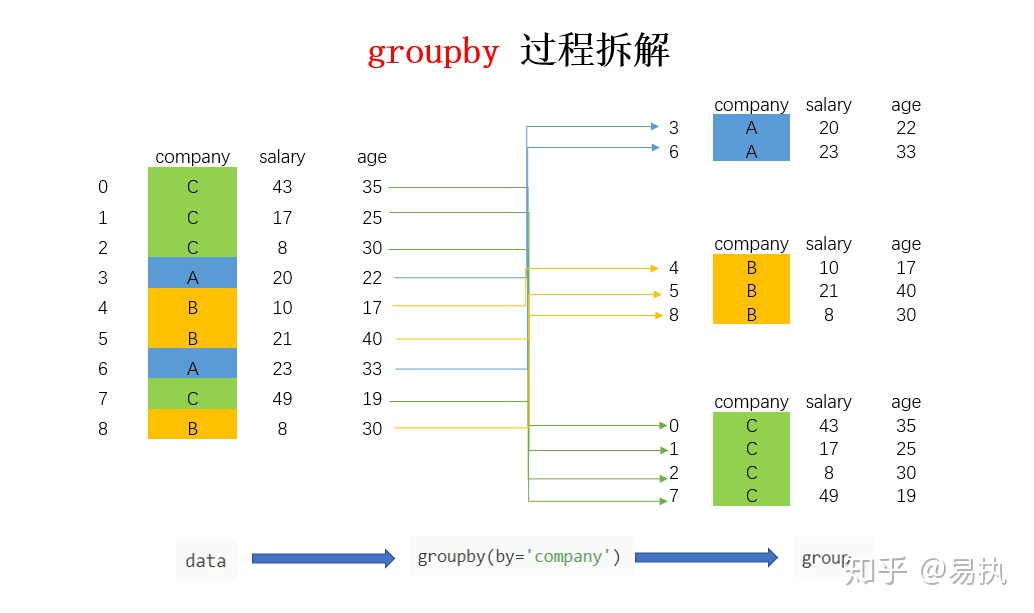
可以用于agg聚合操作,其也会返回一个dataframe来表示结果,有多少分组则会有多少行
In [12]: data.groupby("company").agg('mean')
Out[12]:
salary age
company
A 21.50 27.50
B 13.00 29.00
C 29.25 27.25
可以使用字典来指定不同的列执行不同的聚合目标
In [17]: data.groupby('company').agg({'salary':'median','age':'mean'})
Out[17]:
salary age
company
A 21.5 27.50
B 10.0 29.00
C 30.0 27.25
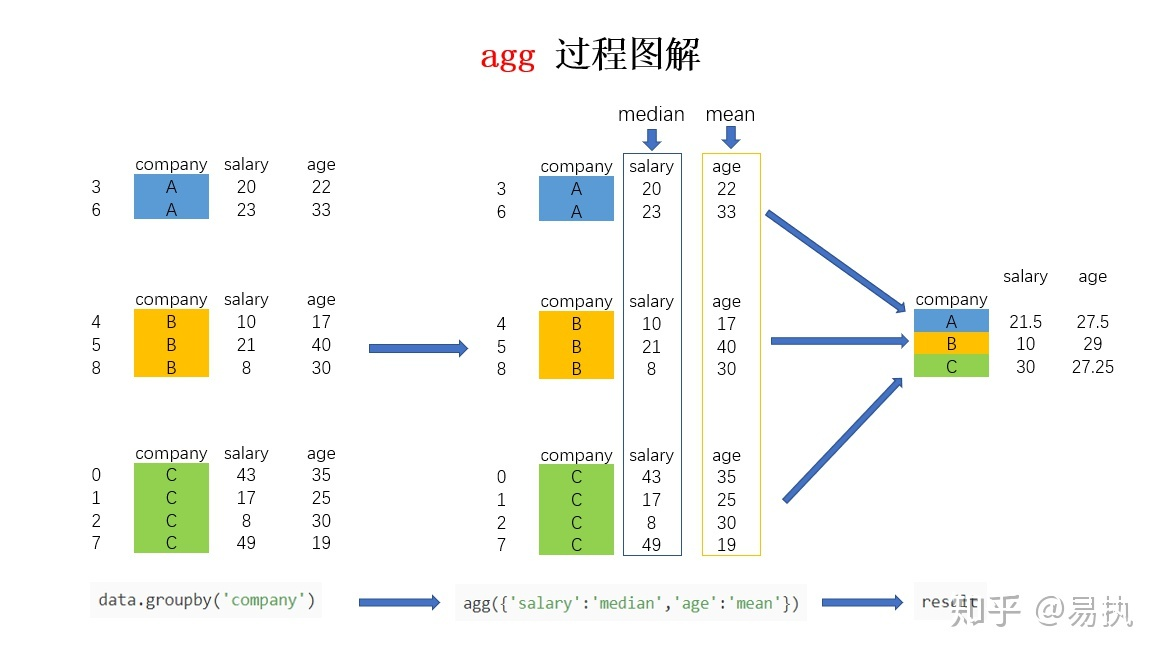
- transform操作
按照groupby后的子dataframe中salary项求平均值,然后每个group会得到一个salary的均值结果
transform会对同一组的每一条数据填充相同的结果(agg会把同一个组的多个元素合并为一组展示结果,而transform则是同时填充多个相同结果)
data['avg_salary'] = data.groupby('company')['salary'].transform('mean')
data
company salary age avg_salary
0 C 43 35 29.25
1 C 17 25 29.25
2 C 8 30 29.25
3 A 20 22 21.50
4 B 10 17 13.00
5 B 21 40 13.00
6 A 23 33 21.50
7 C 49 19 29.25
8 B 8 30 13.00
- 时间序列操作
Pandas时序处理中最常见的两种数据类型为datetime和timedelta
datetime顾名思义就是既有日期date也有时间time,表示一个具体的时间点(时间戳)
timedelta则表示两个时间点之间的差,比如2020-01-01和2020-01-02之间的timedelta即为一天
使用如下方式,可以将文件中时间格式转换为pandas中的datetime64类型
data["trade_date"] = pd.to_datetime(data.trade_date)
data.trade_date.head()
0 2019-01-02
1 2019-01-03
2 2019-01-04
3 2019-01-07
4 2019-01-08
Name: trade_date, dtype: datetime64[ns]
使用如下方式可以直接进行索引,而不需要去进行时间值的转换
data1 = data.set_index("trade_date")
# 2019年6月的数据
data1.loc["2019-06"].head()
close open high low
trade_date
2019-06-03 2890.0809 2901.7424 2920.8292 2875.9019
2019-06-04 2862.2803 2887.6405 2888.3861 2851.9728
2019-06-05 2861.4181 2882.9369 2888.7676 2858.5719
2019-06-06 2827.7978 2862.3327 2862.3327 2822.1853
2019-06-10 2852.1302 2833.0145 2861.1310 2824.3554
# 2019年6月-2019年8月的数据
data1.loc["2019-06":"2019-08"].tail()
close open high low
trade_date
2019-08-26 2863.5673 2851.0158 2870.4939 2849.2381
2019-08-27 2902.1932 2879.5154 2919.6444 2879.4060
2019-08-28 2893.7564 2901.6267 2905.4354 2887.0115
2019-08-29 2890.9192 2895.9991 2898.6046 2878.5878
2019-08-30 2886.2365 2907.3825 2914.5767 2874.1028
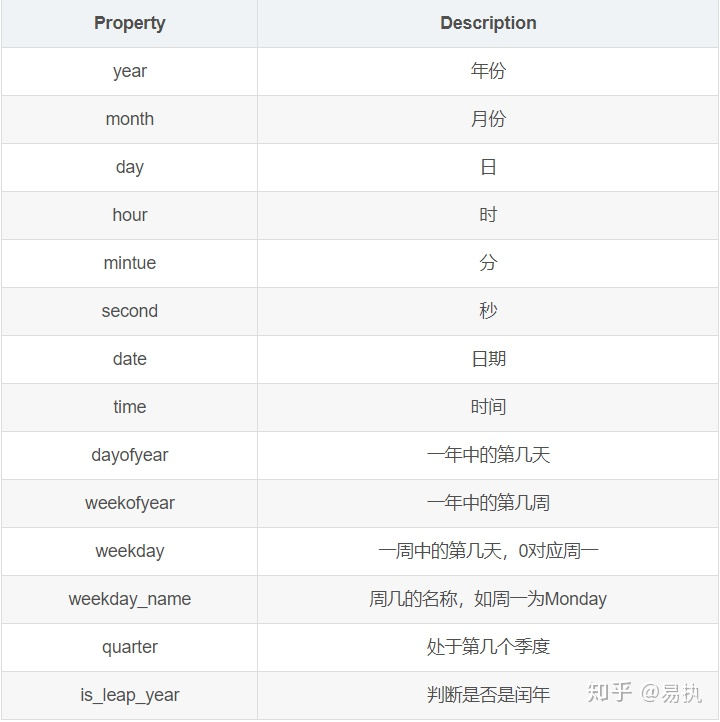
时间序列的属性
# 一年中的第几天
data.trade_date.dt.dayofweek[0]
# 2
# 返回对应日期
data.trade_date.dt.date[0]
# datetime.date(2019, 1, 2)
# 返回周数
data.trade_date.dt.weekofyear[0]
# 1
# 返回周几
data.trade_date.dt.weekday_name[0]
# 'Wednesday'
可以使用datetime模块进行更加细致的操作,详见datetime模块

 浙公网安备 33010602011771号
浙公网安备 33010602011771号