python网络爬虫之自动化测试工具selenium[二]
@
前言
hello,大家好,在上章的内容里我们已经可以爬取到了整个网页下来,当然也仅仅就是一个网页。
因为里面还有很多很多的标签啊之类我们所不需要的东西。
额,先暂且说下本章内容,如果是没有丝毫编程基础的小白来说是比较难懂的
本章内容重点是
1、分析网站的结构来获取一个json串,也就是之前我们爬的是一个网页,这次是爬取一个Ajax请求的一个响应数据(json串)。
2、使用selenuim模块自动化工具
所以如果需要获取一些评论啊,或者一些特殊的要求都可以学一下。
先说好,更上一章一样下载好selenium模块!!python网络爬虫之入门[一]

一、获取今日头条的评论信息(request请求获取json)
1、分析数据
进入头条

在fillder中分析一下这个网页的一个请求
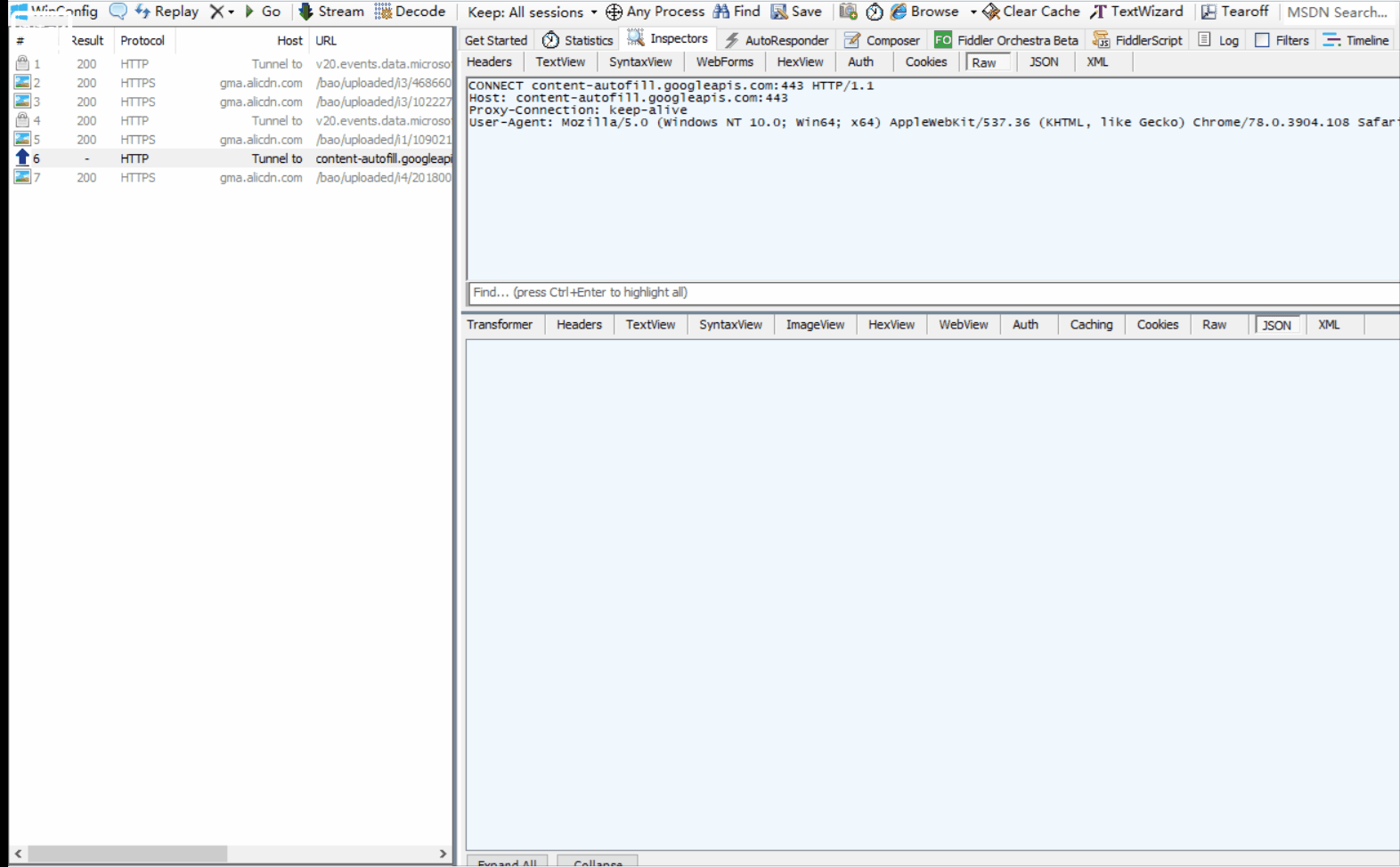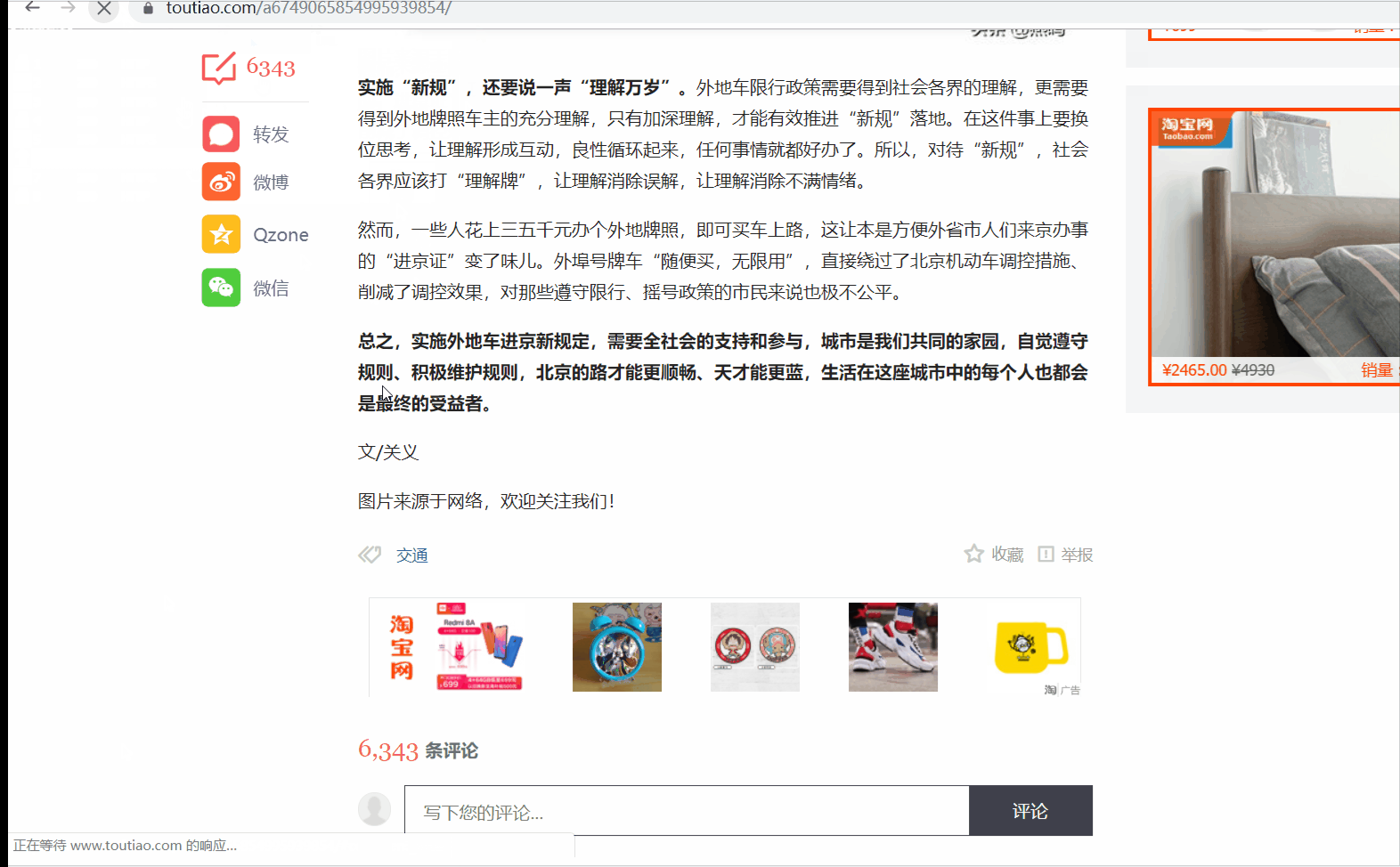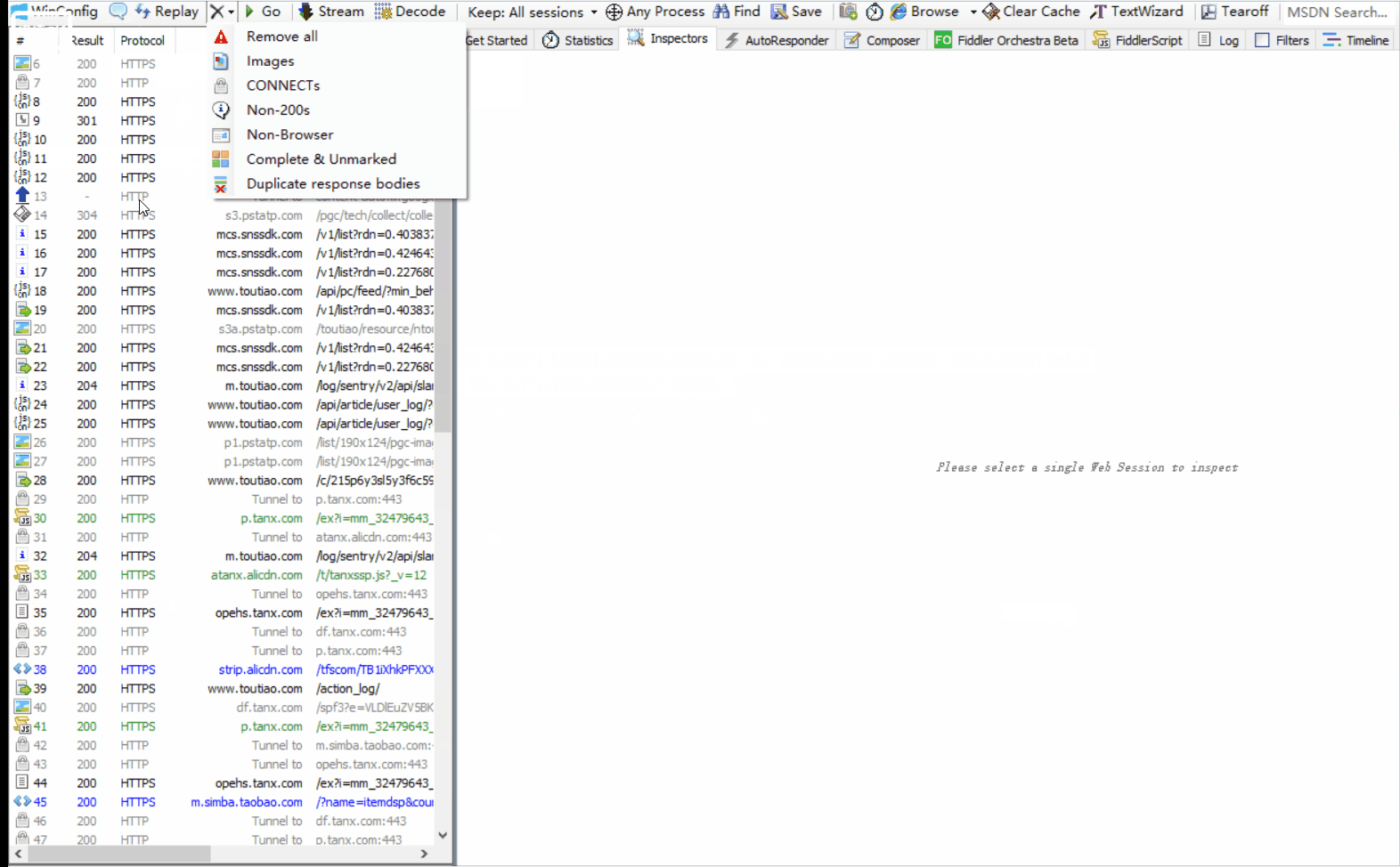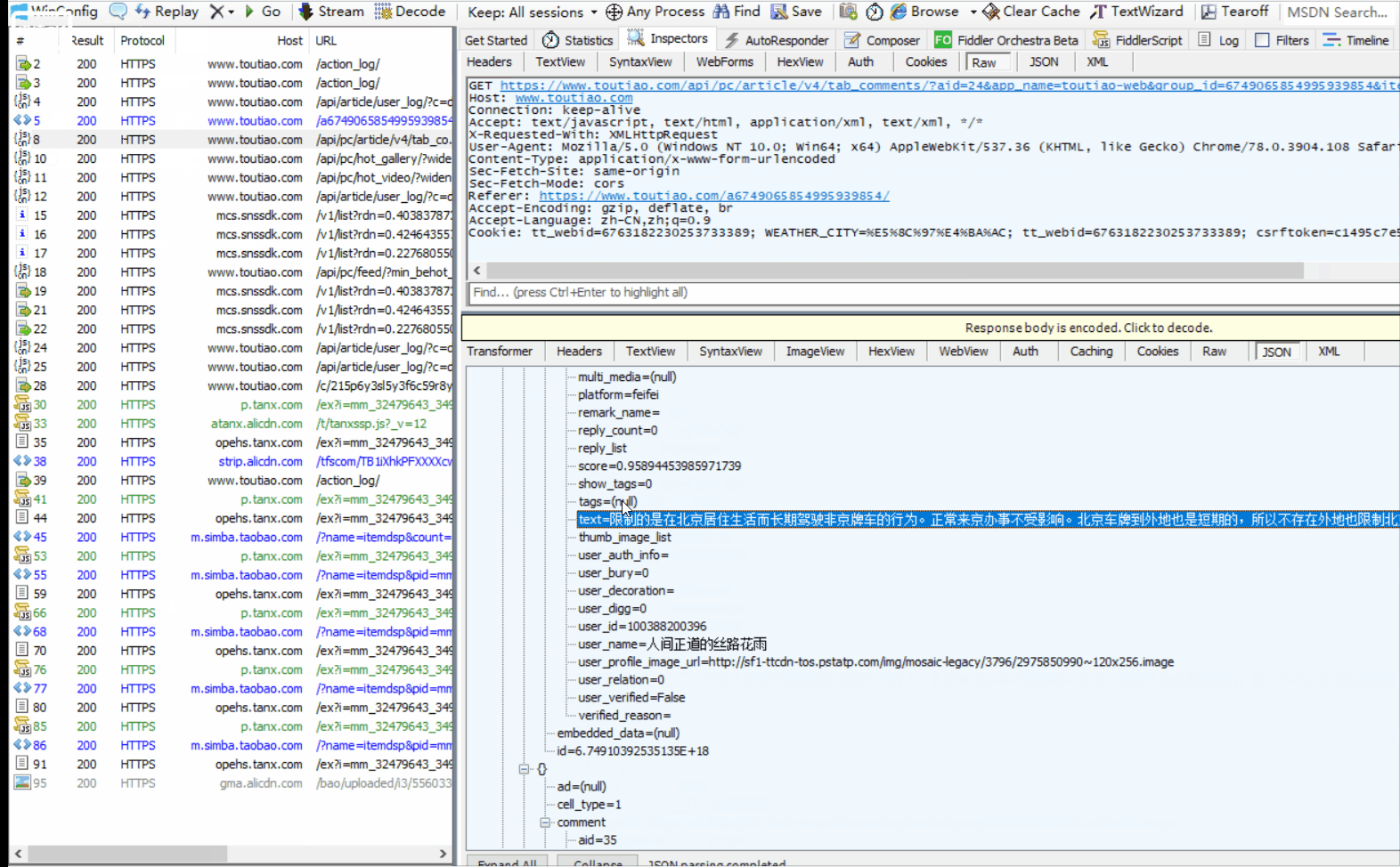
详细讲解:

我们测试一下

2、获取数据
ok,那么跟据我们之前所学的内容我们可以直接使用request模块请求一次

全部代码:
"""
使用requests模块爬取动态网页数据:
今日头条,某条新闻的评论信息
"""
import requests
url = "https://www.toutiao.com/api/comment/list/?group_id=6749065854995939854&item_id=6749065854995939854&offset=0&count=15"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
}
requests.packages.urllib3.disable_warnings()
# 请求,获得响应
response = requests.get(url, headers=headers, verify=False)
if response.status_code == 200:
# print(response.text)
# print(response.json())
print(response.text)
二、获取今日头条的评论信息(selenium请求获取)
ps:selenium模块其实是一个自动化测试工具,大家还可以深入了解,因为它不仅仅只能用来做爬虫。
还可以做为测试工具使用
1、分析数据
在使用selenium模块之前先确定好自己使用的浏览器的型号,因为知道后才能去下载属于自己的一个webdriver
比如我的浏览器型号

然后自行到网上找到自己浏览器的webdriver

每个的浏览器的driver都不一样,我的就是chromedriver.exe
然后放到自己的python解释器下的script目录下

来我们来解析一下这个网站:https://www.toutiao.com/a6747626504986853891/

我们来看一看主体部分:

2、获取数据
引入调用,我在上面已经把我们可能所需要的东西都获取到。也讲解了一下一下;

这个是加了一个python程序控制的点击事件。

lookthis....
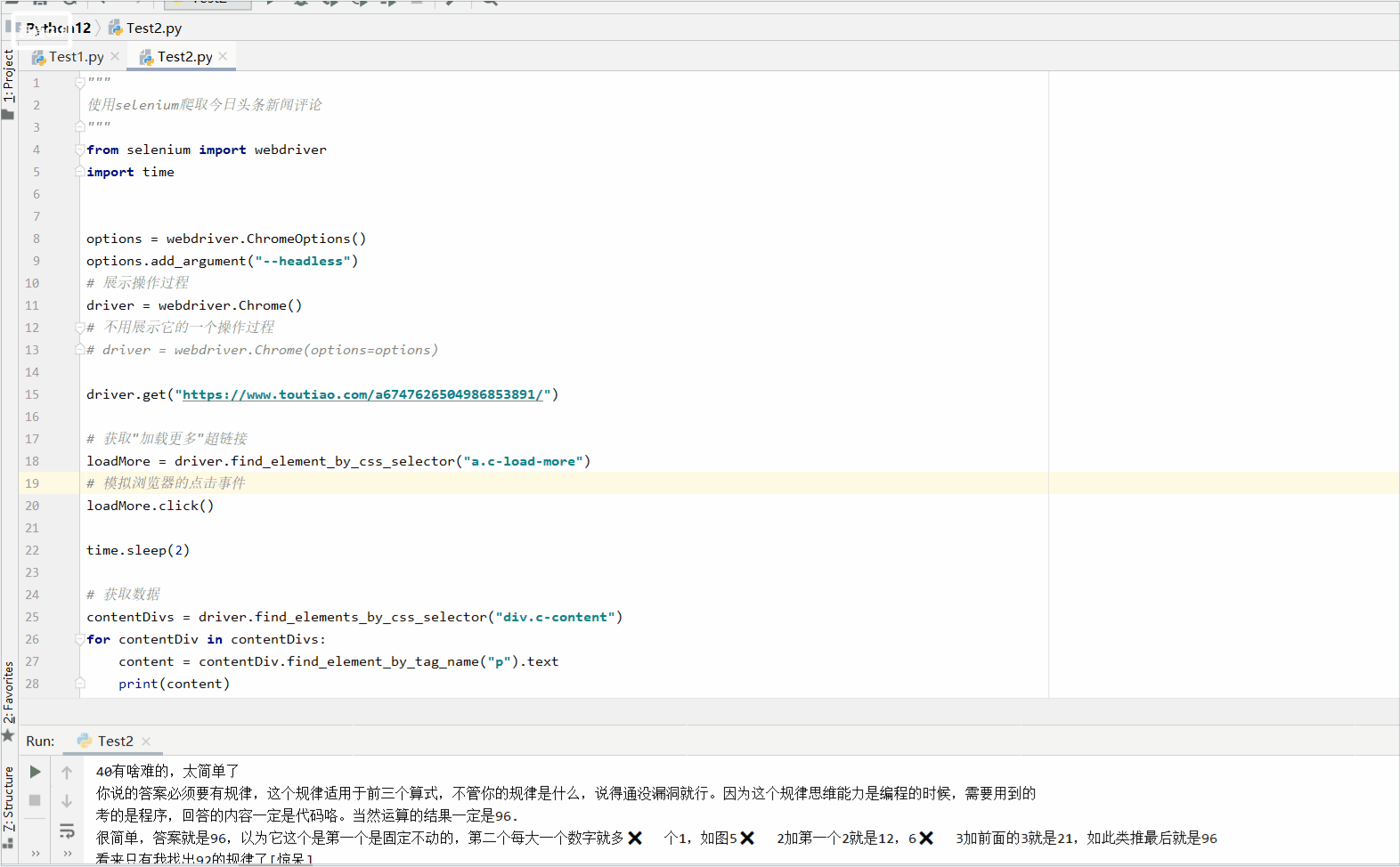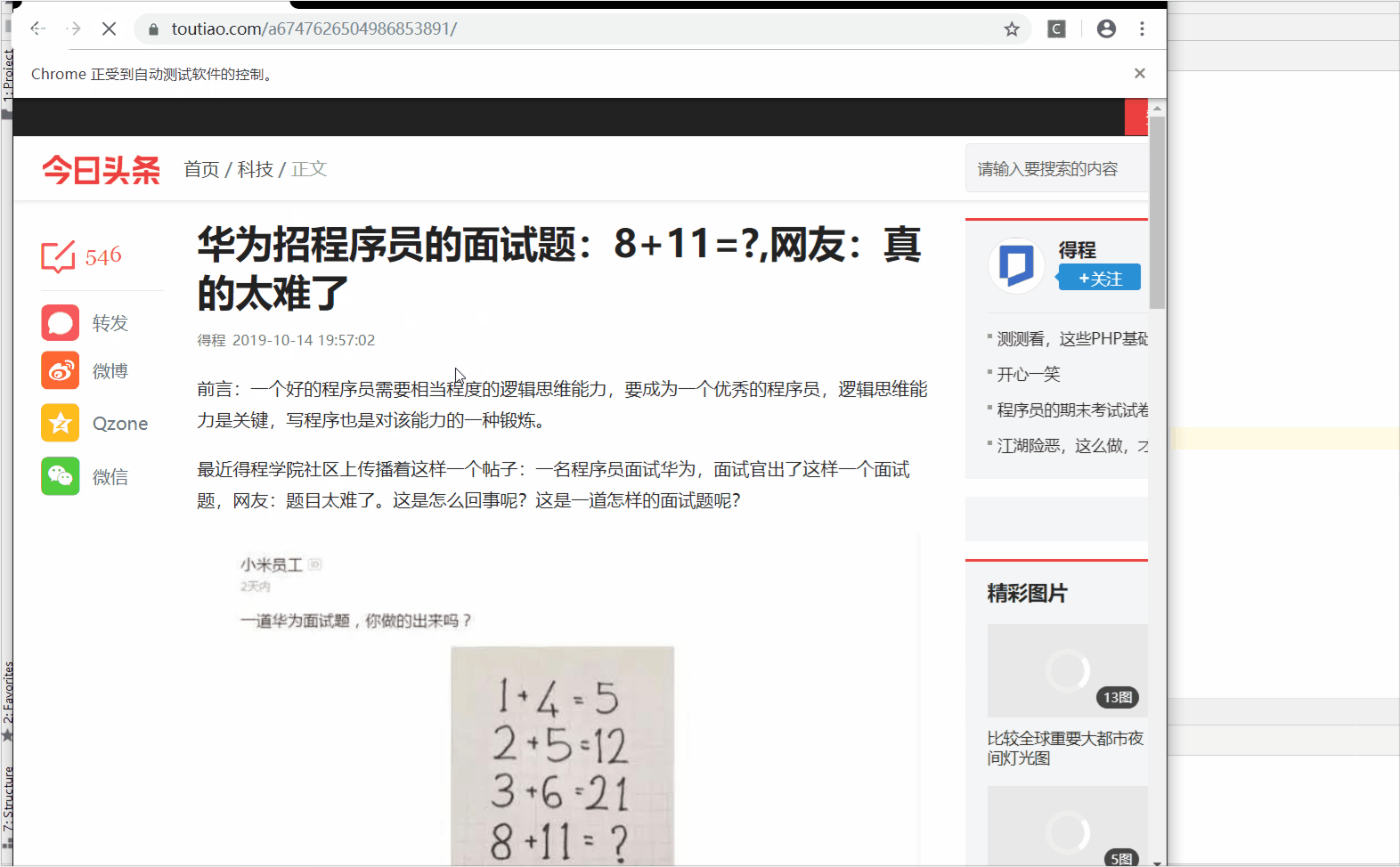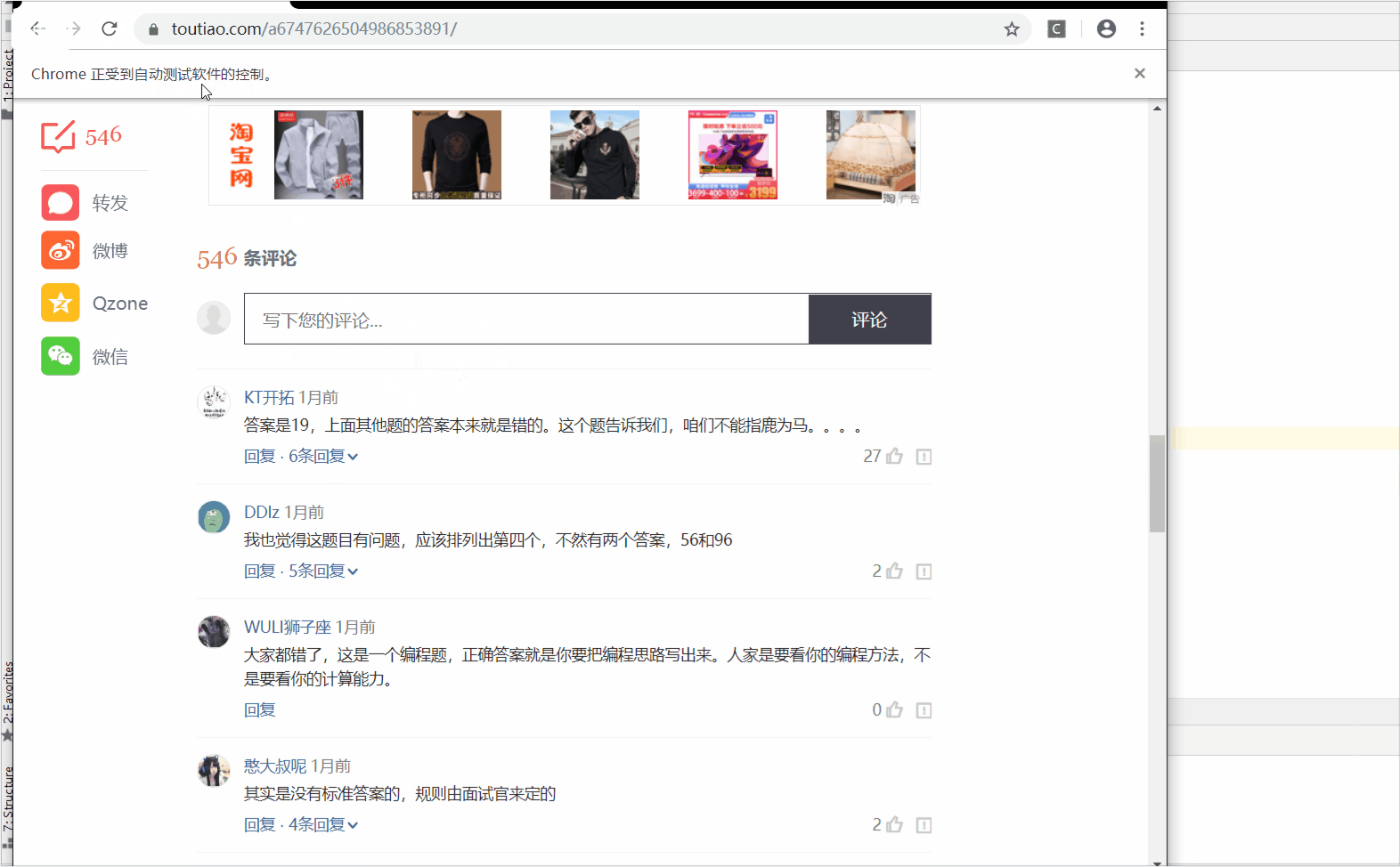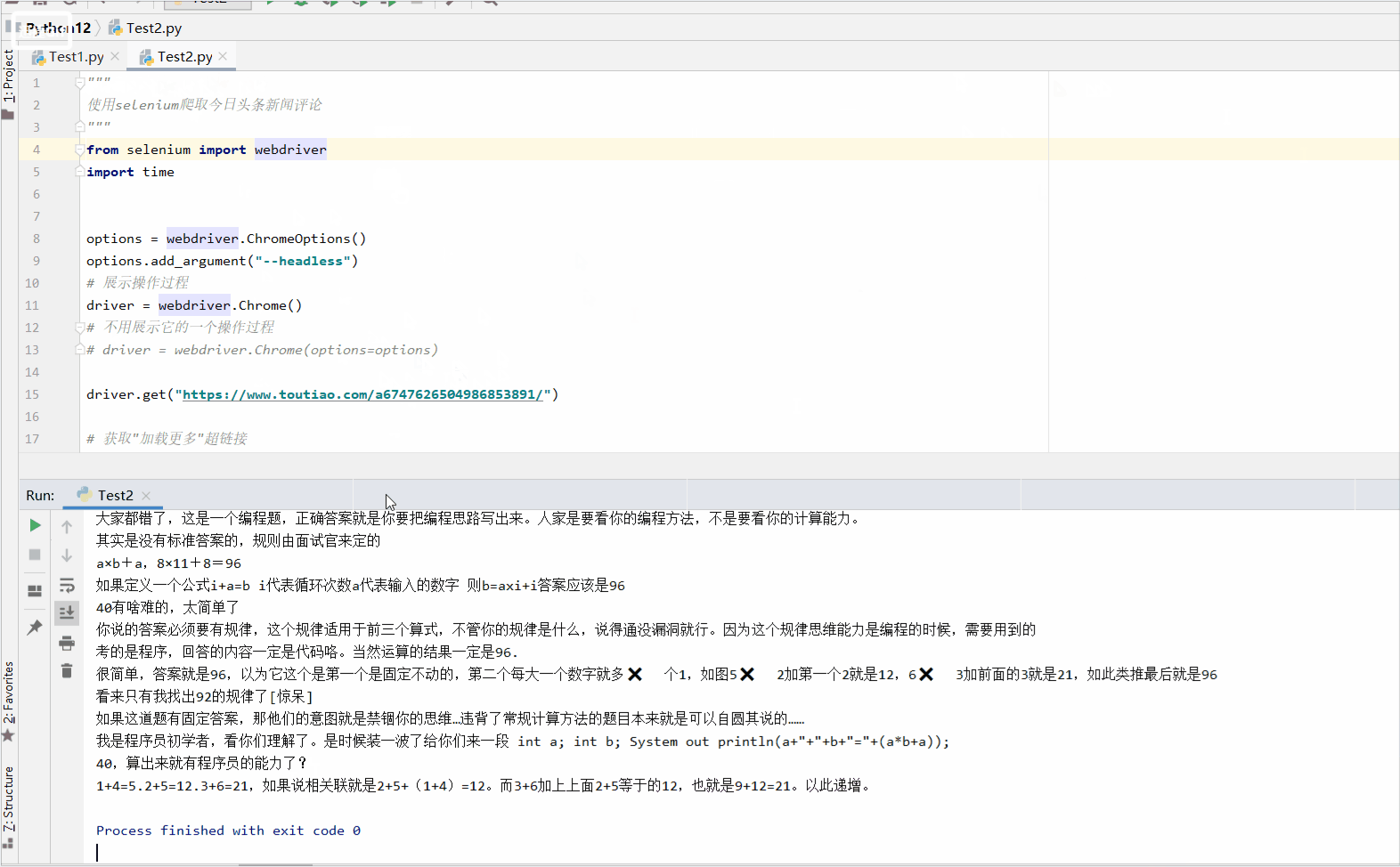
额,获取到了吧,嘿嘿
房源案例(仅供参考!!!,也许爬不了了)
"""
综合案例:
使用selenium爬取 airbnb房源信息
一个房源所有的信息:_gig1e7
名称:_qhtkbey
类型及大小:_fk7kh10里边的span
价格:_1ixtnfc里面的span
_1dir9an
"""
from selenium import webdriver
import time
options = webdriver.ChromeOptions()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
for page in range(18):
print(f"第{page+1}页数据:")
driver.get(f"https://www.airbnb.cn/s/长沙/homes?refinement_paths%5B%5D=%2Fhomes¤t_tab_id=home_tab&selected_tab_id=home_tab&screen_size=large&hide_dates_and_guests_filters=false&place_id=ChIJxWQcnvM1JzQRgKbxoZy75bE&s_tag=vaaWeg7D§ion_offset=4&items_offset={page*18}&last_search_session_id=7d2afba3-cc47-434c-92be-65bac7643d3b")
houseAll = driver.find_elements_by_css_selector("div._gig1e7")
i = 1
for house in houseAll:
# 名称
name = house.find_element_by_css_selector("div._qhtkbey").text
# 价格
price = house.find_element_by_css_selector("div._1ixtnfc").text
newprice = price.replace("价格", "").replace("\n", "")
# 类型及大小
typeSize = house.find_element_by_css_selector("span._fk7kh10").text
type = typeSize.split(" · ")[0]
size = typeSize.split(" · ")[1]
print(f"{i} {name} {newprice} {type} {size}")
time.sleep(2)
i = i + 1
time.sleep(5)
上面内容只能慢慢思考问题了
但是这还有一个selenium的使用方法:


后记
还是那句话,好好的分析网页结构
如果感觉本章写的还不错的话,不如。。。。。(~ ̄▽ ̄)~ ,(´▽`ʃ♡ƪ)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号