python网络爬虫之入门(requests模块)[一]
@
前言
hello,接下来就学习如何使用Python爬虫功能。
在接下来的章节中可以给大家整理一个完整的学习要点,当然都是一个简单的知识点,
喔,本人认为就是一个入门,不会讲的特别深入,因为接下来的一章中可能有多个知识点,
不过自主的学习才是王道
奥力给!!!
废话不多说,先整理一下本次内容:
1、探讨什么是python网络爬虫?
2、一个针对于网络传输的抓包工具fiddler
3、学习request模块来爬取第一个网页
一、探讨什么是python网络爬虫?
相信大家如果是刚学python或是刚学java的各位来说的话,一定会有来自灵魂深处的四问。。。
我是谁?,我在那?.....额,不是
咳咳,是这个:
1、什么是网络爬虫?
2、为什么要学网络爬虫?
3、网络爬虫用在什么地方?
4、网络爬虫是否合法?
哟西,放马过来,一个一个来。
1、什么是网络爬虫?
如果说网络就是一张网的话,那么网络爬虫就是可以在网上获取食物的蜘蛛(spider)

2、为什么要学网络爬虫?
这个的话,就感觉是在问你为什么要学习python一样。。(~ ̄▽ ̄)~
嘛,总的来说就是教你可以在网上爬取到什么样的数据以及学到神马东西。
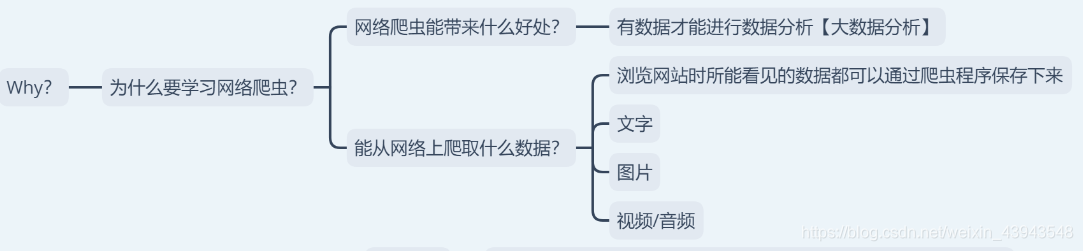
3、网络爬虫用在什么地方?
额,用在什么地方,什么地方都能用到哦,比如:在找工作的时候把所有的招聘信息爬取下来,然后再自己慢慢解析,又比如:爬取某些网站的图片.....

4、网络爬虫是否合法?
enn,先说好啊,本章博客是用来学习博客,不会用来做任何商业用途
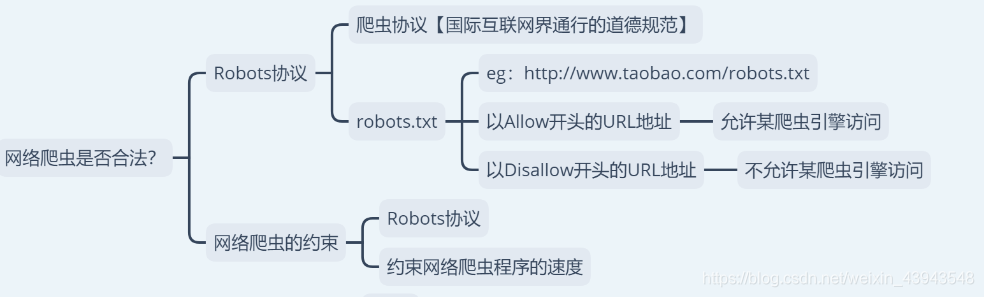
5、最后说一下,接下来会学习的内容,不过可能会有些变动
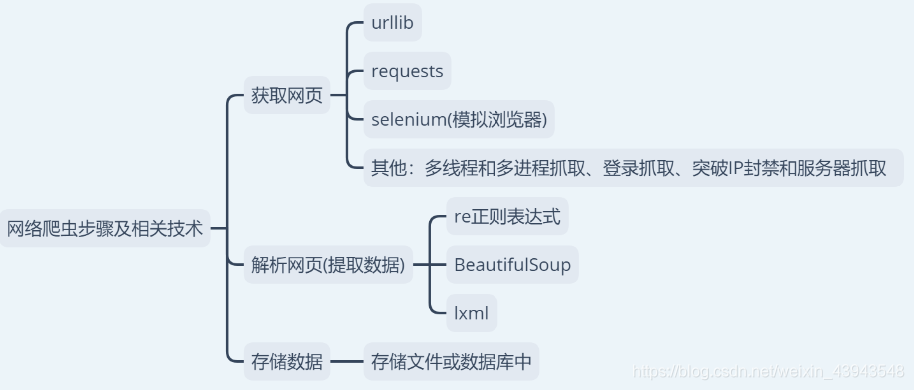
let`go
二、一个针对于网络传输的抓包工具fiddler
这个我就不讲了,因为之前做过之类的博客。额,有不懂的可以私信
直接上传送门:Fiddler抓包工具
三、学习request模块来爬取第一个网页
喔,因为我没有整理其他的比如:python解释器的安装之类的,额,不懂的暂时先可以去看看基础之类的。
python入门【一】
这个内容可能比较的枯燥啊。
1、下载requesets模块
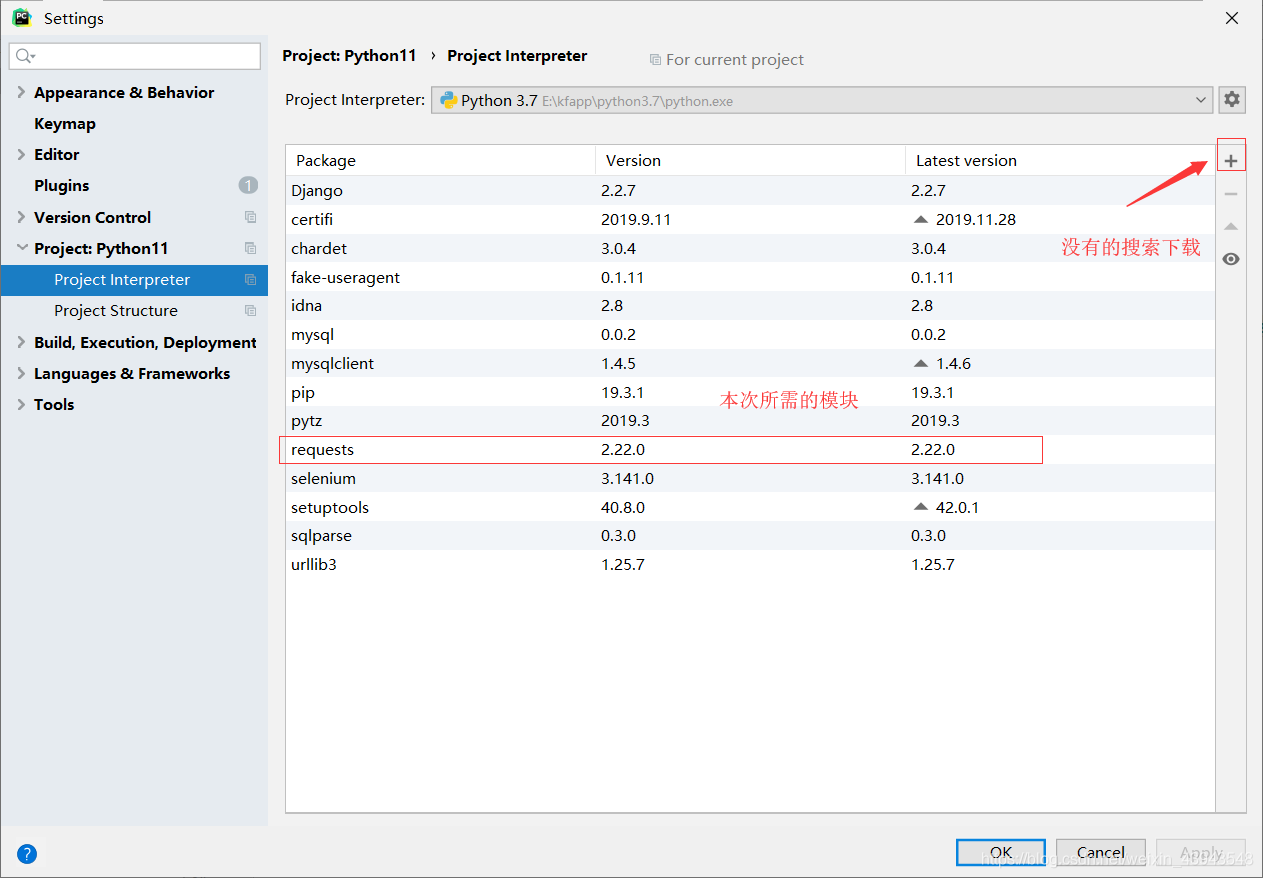
没有的话就下载
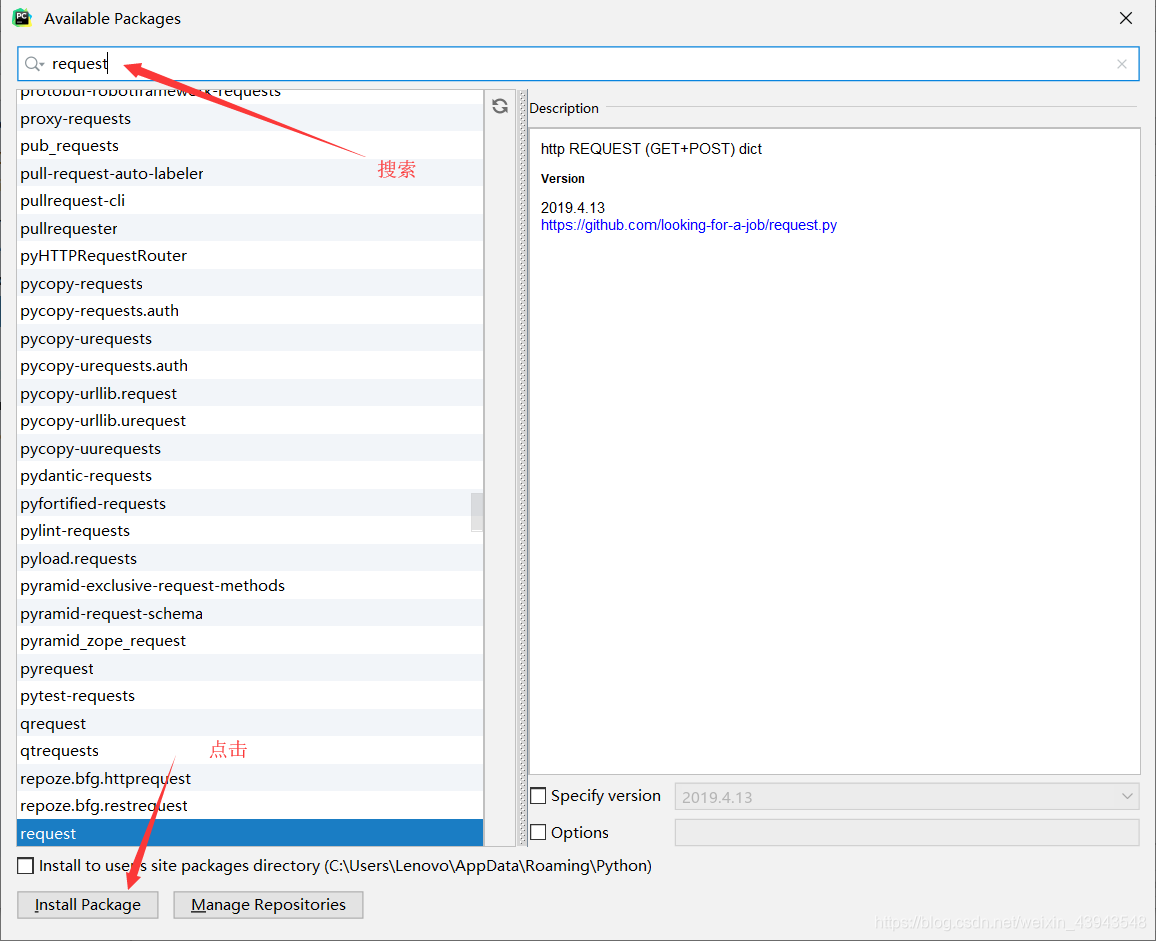
2、对网页的解析(百度www.baidu.com)
按F进入坦克...
额,不是 按F12进入开发者模式
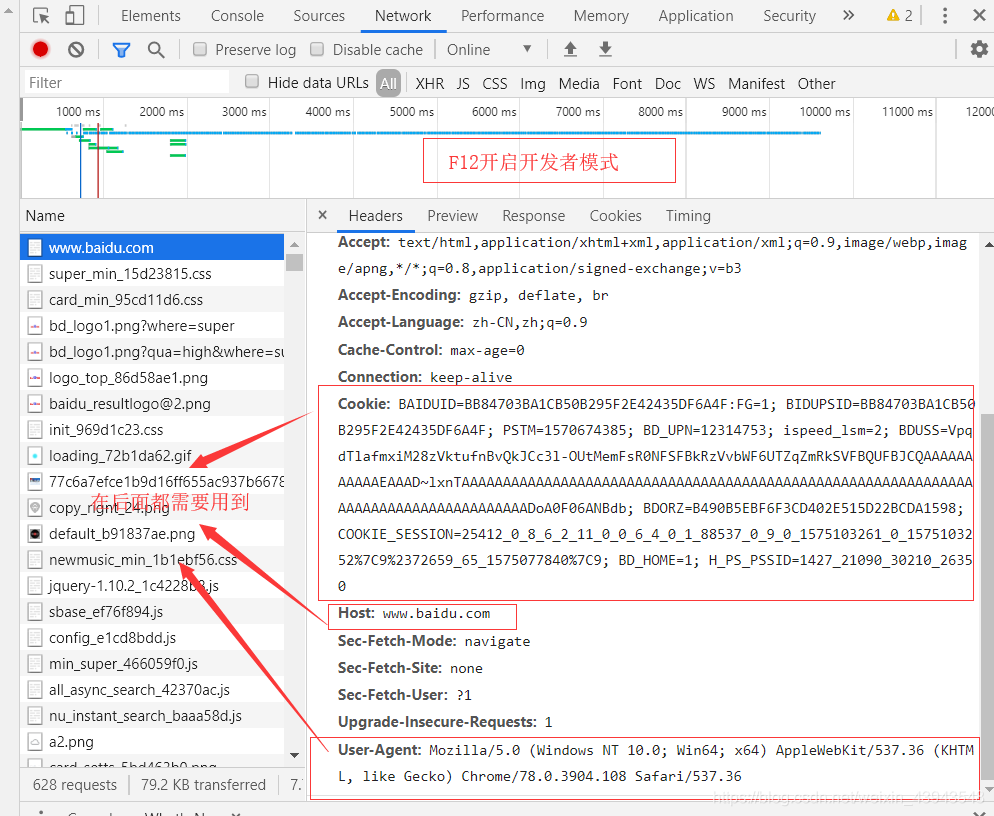
搜索"中国"
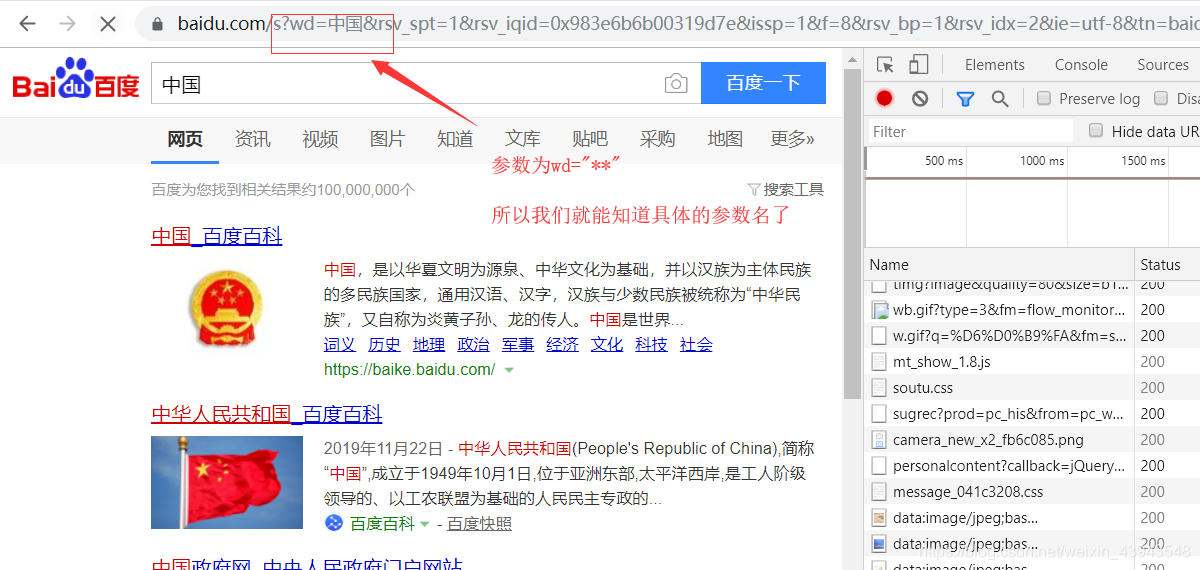
3、开始爬取(嘿嘿,因为本人感觉一个一个放上去忒麻烦了吧,一张图给你解决)
其实有很多注解了的,多看看,当然对一个网页的分析尤为重要
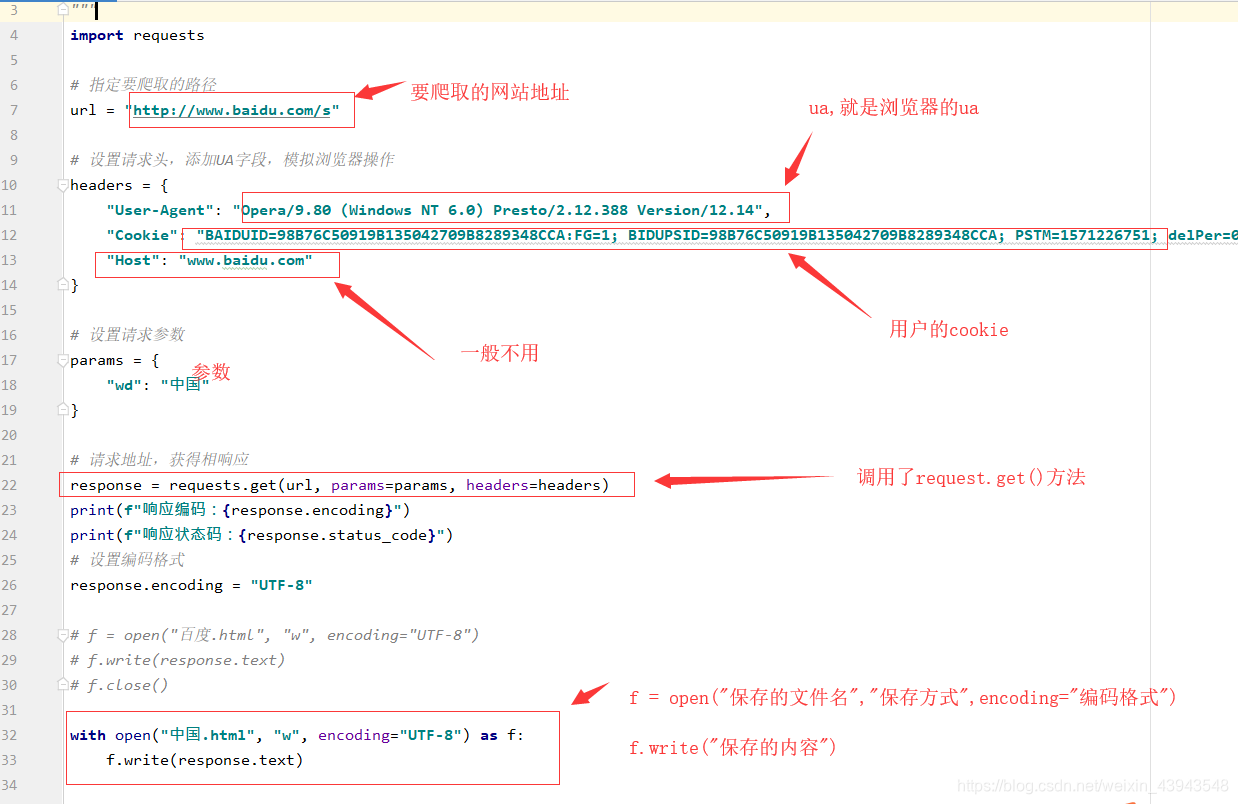
具体代码实现:
import requests
# 标明要请求的路径
url = "http://www.baidu.com/s?"
headers = {
"Cookie": "BAIDUID=BB84703BA1CB50B295F2E42435DF6A4F:FG=1; BIDUPSID=BB84703BA1CB50B295F2E42435DF6A4F; PSTM=1570674385; BD_UPN=12314753; ispeed_lsm=2; BDUSS=VpqdTlafmxiM28zVktufnBvQkJCc3l-OUtMemFsR0NFSFBkRzVvbWF6UTZqZmRkSVFBQUFBJCQAAAAAAAAAAAEAAAD~lxnTAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADoA0F06ANBdb; pgv_pvi=5531878400; COOKIE_SESSION=98297_6_9_8_4_26_0_3_8_7_10_8_18582_21681_0_0_1574259377_1574259241_1574591094%7C9%2321663_55_1574259212%7C9; BD_HOME=1; H_PS_PSSID=1427_21090_29567_29221_26350"
,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
, "Host": "www.baidu.com"
}
params = {
"wd": "中国"
}
# 得到请求后的响应
response = requests.get(url,params=params,headers=headers)
response.encoding = "UTF-8"
print(f"响应的编码:{response.encoding}")
print(f"响应的状态码:{response.status_code}")
print(response.text)
with open("中国.html", "w", encoding="UTF-8") as f:
f.write(response.text)
* 扩展内容(爬取top250的网页)
因为重点代码都在上面讲了,所以就放如何解析网页;
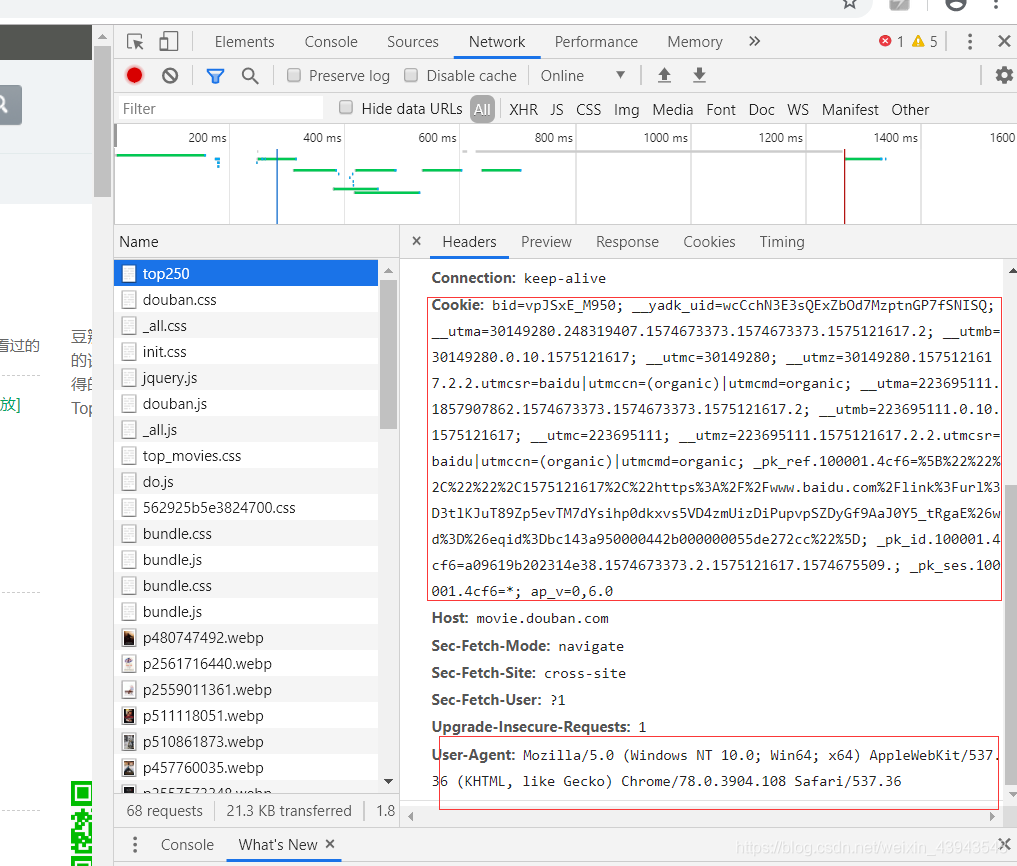
第一页的数据
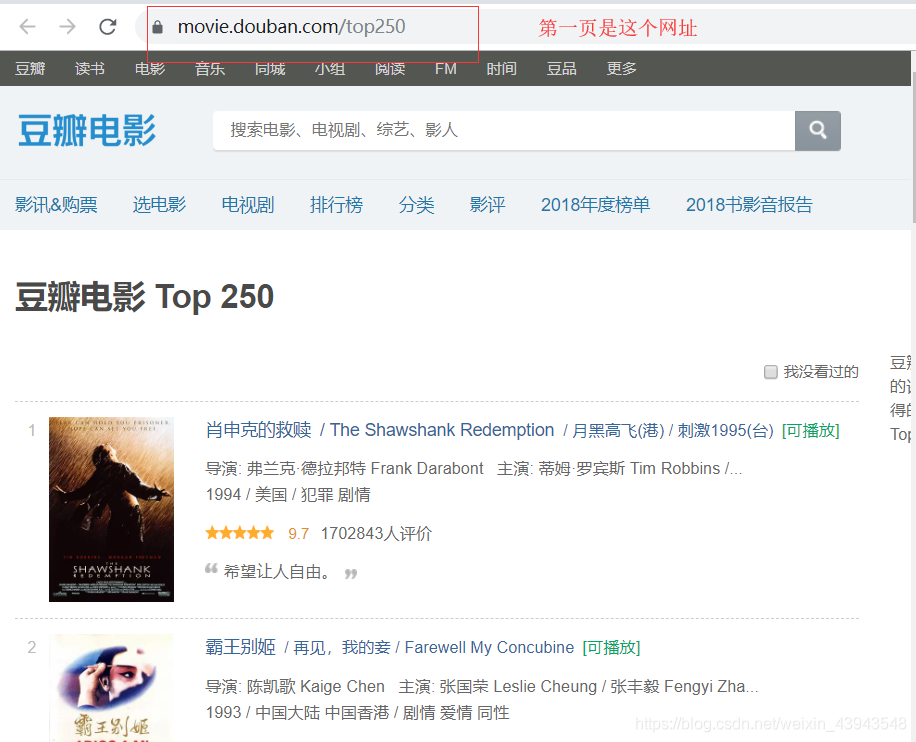
第一页的猜测网址:结果没问题。
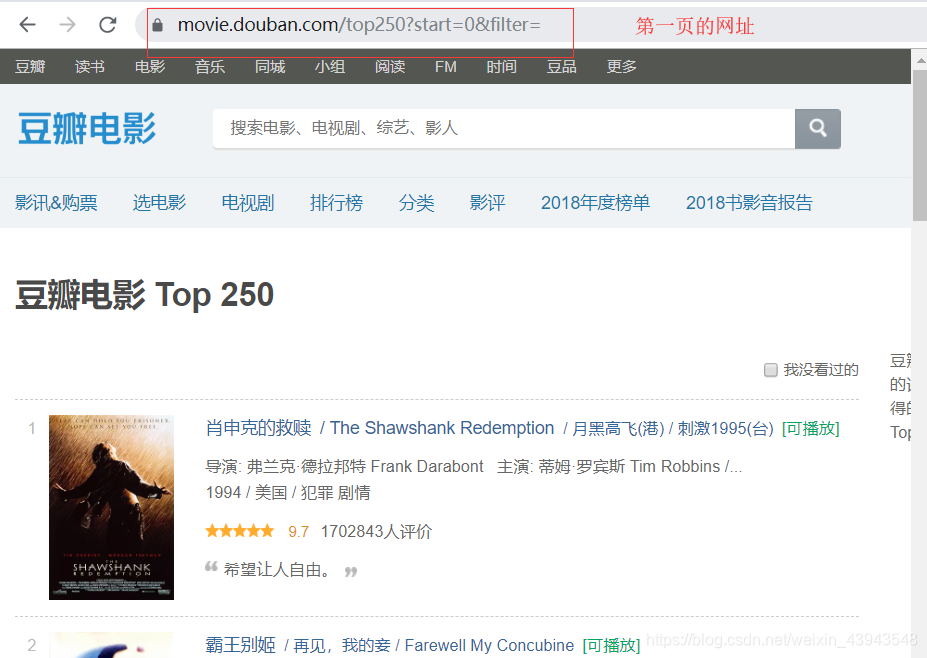
可以直接点击第二页就看看网址,
然后就可以分析分析网址了
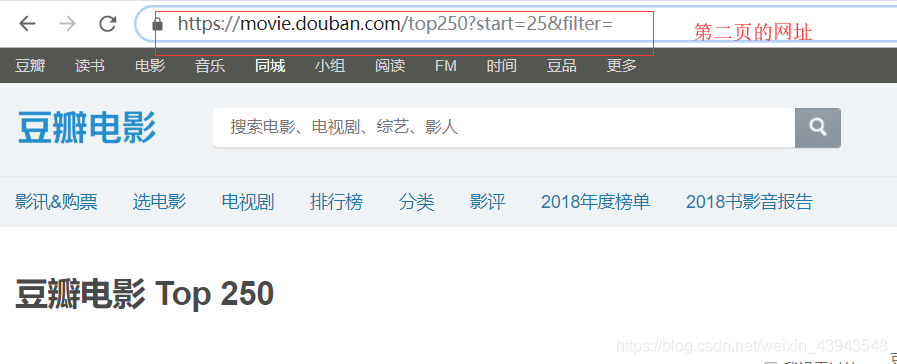
所以我们的一个代码就是这个
"""
爬取豆瓣电影TOP250,分页保存电影数据
"""
import requests
import time
headers = {
"User-Agent": "Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14"
}
for i in range(10):
url = f"https://movie.douban.com/top250?start={i*25}"
response = requests.get(url, headers=headers, verify=False)
print(response.status_code)
if response.status_code == 200:
# 获取网页数据
with open(f"第{i+1}页.txt", "w", encoding="UTF-8") as f:
f.write(response.text)
print(f"{url} 保存成功")
time.sleep(2)
后记
爬虫重点在于分析
如果感觉本章写的还不错的话,不如。。。。。(~ ̄▽ ̄)~ ,(´▽`ʃ♡ƪ)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号