1.2 MySQL笔记-隔离级别&锁
一.隔离级别
|
隔离级别 |
含义 |
读数据一致性 |
脏读 |
不可重复读 |
幻读 |
|---|---|---|---|---|---|
|
读未提交(Read Uncommitted) |
事务中的修改,即使没有提交,对其他事务都是可见的 |
最低级别,只能保证不读取物理上损坏的数据 |
是 |
是 |
是 |
|
读已提交(Read Committed) |
事务从开始到提交之前,所做的修改对其他事务都不可见 |
语句级 |
否 |
是 |
是 |
|
可重复读(Repeatable read)InnoDB默认的隔离级别 |
同一事务中多次读取同样的记录结果是一致的 |
事务级 |
否 |
否 |
是 |
|
可序列化(Serializable) |
在读取的每一行数据上加锁,强制事务串行执行 |
最高级别,事务级 |
否 |
否 |
否 |
概念:
-
脏读:一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并据此做进一步的处理,就会产生未提交的数据依赖关系,这种现象被称为“脏读”
-
幻读:一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象被称为“幻读”
举例:

我们来看看在不同的隔离级别下,事务A会有哪些不同的返回结果,也就是图里面V1、V2、V3的返回值分别是什么。
-
若隔离级别是“读未提交”, 则V1的值就是2。这时候事务B虽然还没有提交,但是结果已经被A看到了。因此,V2、V3也都是2。
-
若隔离级别是“读提交”,则V1是1,V2的值是2。事务B的更新在提交后才能被A看到。所以, V3的值也是2。
-
若隔离级别是“可重复读”,则V1、V2是1,V3是2。之所以V2还是1,遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的。
-
若隔离级别是“串行化”,则在事务B执行“将1改成2”的时候,会被锁住。直到事务A提交后,事务B才可以继续执行。所以从A的角度看, V1、V2值是1,V3的值是2。
|
事务A |
事务B |
事务C |
|---|---|---|
|
begin; select * from Test where a=5 for update/*Q1*/ result:(5,5,5) |
||
|
update Test set a=5 where id=0; |
||
|
select * from Test where a=5 for update/*Q2*/ result:(0,5,5)(5,5,5) |
||
|
inset into Test values(1,5,5); |
||
|
select * from Test where a=5 for update/*Q3*/ result:(0,5,5)(1,5,5)(5,5,5) |
||
|
commit; |
Q3读到了id=1这一行,就叫“幻读”。
二.锁

2.1按照锁粒度划分锁
2.1.1全局锁
全局锁就是对整个数据库实例加锁。MySQL提供了一个加全局读锁的方法,命令是 Flush tables with read lock (FTWRL)。当你需要让整个库处于只读状态的时候,可以使用这个命令,之后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。
全局锁的典型使用场景是,做全库逻辑备份。
2.1.2表锁
MySQL里面表级别的锁有两种:一种是表锁,一种是元数据锁(meta data lock,MDL)。
表锁就是对数据表进行锁定,锁定粒度很大,同时发生锁冲突的概率也会较高,数据访问的并发度低。不过好处在于对锁的使用开销小,加锁会很快。
表锁的语法是 lock tables … read/write。与FTWRL类似,可以用unlock tables主动释放锁,也可以在客户端断开的时候自动释放。需要注意,lock tables语法除了会限制别的线程的读写外,也限定了本线程接下来的操作对象。
另一类表级的锁是MDL(metadata lock)。MDL不需要显式使用,在访问一个表的时候会被自动加上。MDL的作用是,保证读写的正确性。你可以想象一下,如果一个查询正在遍历一个表中的数据,而执行期间另一个线程对这个表结构做变更,删了一列,那么查询线程拿到的结果跟表结构对不上,肯定是不行的。
因此,在MySQL 5.5版本中引入了MDL,当对一个表做增删改查操作的时候,加MDL读锁;当要对表做结构变更操作的时候,加MDL写锁。
-
读锁之间不互斥,因此你可以有多个线程同时对一张表增删改查。
-
读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行。
2.1.3行锁
行锁就是针对数据表中行记录的锁。这很好理解,比如事务A更新了一行,而这时候事务B也要更新同一行,则必须等事务A的操作完成后才能进行更新。行锁锁定力度小,发生锁冲突概率低,可以实现的并发度高,但是对于锁的开销比较大,加锁会比较慢,容易出现死锁情况。(题外话:间隙锁和行锁合称next-key lock,前开后闭)
在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
2.2共享锁和排他锁
两种锁:共享锁(shared lock)和排他锁(exclusive lock),也叫读锁(read lock)和写锁(write lock)。
读锁是共享的,或者说是相互不阻塞的。多个客户在同一时刻可以同时读取同一个资源,而互不干扰。写锁则是排他的,也就是说一个写锁会阻塞其他的写锁和读锁,这是出于安全策略的考虑,只有这样才能确保在给定的时间里,只有一个用户执行写入,并防止其他用户读取正在写入的同一资源。
附:
共享锁:SELECT * FROM s_user WHERE user_id = 912178 LOCK IN SHARE MODE
排他锁:SELECT * FROM s_user WHERE user_id = 912178 FOR UPDATE
意向锁(Intent Lock),简单来说就是给更大一级别的空间示意里面是否已经上过锁,如果我们给某一行数据加上了排它锁,数据库会自动给更大一级的空间,比如数据页或数据表加上意向锁,告诉其他人这个数据页或数据表已经有人上过排它锁了,这样当其他人想要获取数据表排它锁的时候,只需要了解是否有人已经获取了这个数据表的意向排他锁即可。
意向锁是指未来某个时刻,事务要加共享/排他锁了,提前声明个意向。
-
意向共享锁(IS):事务有意向对表中某几行加S锁
-
意向排他锁(IX):事务有意向对表中某几行加X锁
意向锁协议:
-
事务要获得某些行的S锁,必须先获得表的IS锁
-
事务要获得某些行的X锁,必须先获得表的IX锁
2.3乐观锁和悲观锁
乐观锁和悲观锁是一种思想,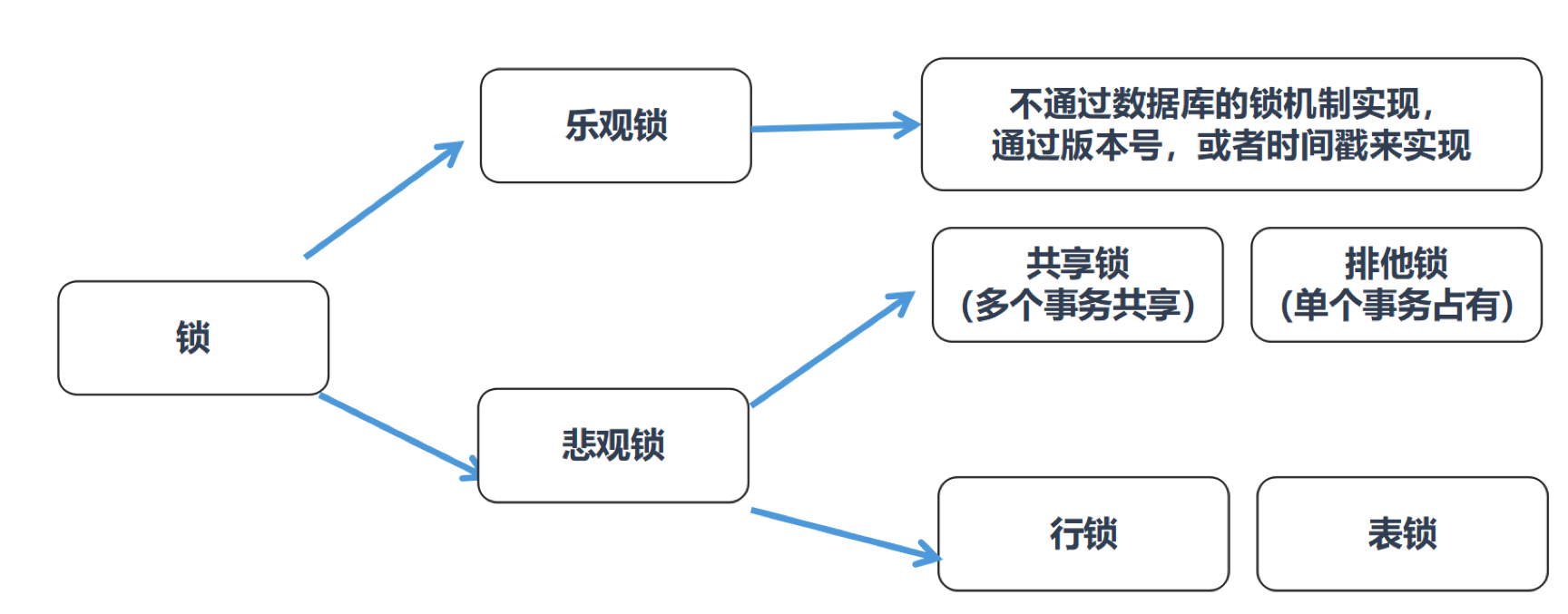
三.InnoDB锁算法
3.1记录锁Record Locks
单个行记录上的锁,用来封锁索引记录。
如:假设Test表有主键id和唯一索引列a,已经有了(1,1)这条记录,执行select * from Test where id=1 for update;
会在id=1的索引记录上加锁,以阻止其他事物插入更新、删除id=1这一行。
3.2间隙锁Gap Locks
锁定一个范围,但不包含记录本身。
封锁索引记录中的间隙,确保索引记录的间隙不变。间隙锁是针对事务隔离级别为可重复读(RR)或以上级别而已的,如果隔离级别降级为读提交(RC),间隙锁会自动失效。间隙锁往间隙中插入一个记录才会冲突,间隙锁之间不存在冲突关系。
四.加锁规则
-
原则1:加锁的基本单位是next-key lock。希望你还记得,next-key lock是前开后闭区间。
-
原则2:查找过程中访问到的对象才会加锁。
-
优化1:索引上的等值查询,给唯一索引加锁的时候,next-key lock退化为行锁。
-
优化2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock退化为间隙锁。
-
一个bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
五.具体案例
案例一:等值查询间隙锁
第一个例子是关于等值条件操作间隙:

图1 等值查询的间隙锁
由于表t中没有id=7的记录,所以用我们上面提到的加锁规则判断一下的话:
-
根据原则1,加锁单位是next-key lock,session A加锁范围就是(5,10];
-
同时根据优化2,这是一个等值查询(id=7),而id=10不满足查询条件,next-key lock退化成间隙锁,因此最终加锁的范围是(5,10)。
所以,session B要往这个间隙里面插入id=8的记录会被锁住,但是session C修改id=10这行是可以的。
案例二:非唯一索引等值锁
第二个例子是关于覆盖索引上的锁:
(案例2复现注意事项:session A select id 。。。。;如果是selct * 是不会复现的)
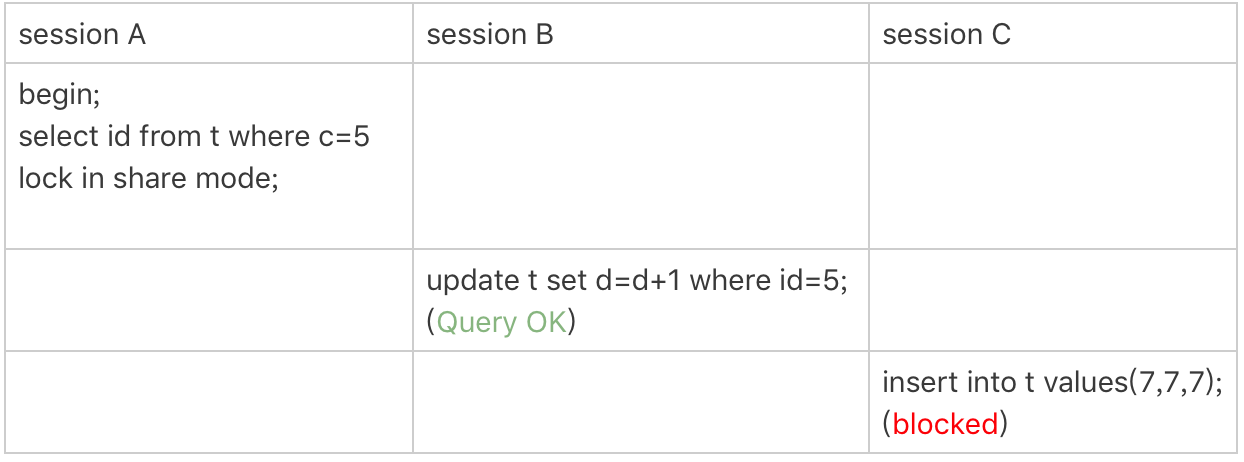
图2 只加在非唯一索引上的锁
看到这个例子,你是不是有一种“该锁的不锁,不该锁的乱锁”的感觉?我们来分析一下吧。
这里session A要给索引c上c=5的这一行加上读锁。
-
根据原则1,加锁单位是next-key lock,因此会给(0,5]加上next-key lock。
-
要注意c是普通索引,因此仅访问c=5这一条记录是不能马上停下来的,需要向右遍历,查到c=10才放弃。根据原则2,访问到的都要加锁,因此要给(5,10]加next-key lock。
-
但是同时这个符合优化2:等值判断,向右遍历,最后一个值不满足c=5这个等值条件,因此退化成间隙锁(5,10)。
-
根据原则2 ,只有访问到的对象才会加锁,这个查询使用覆盖索引,并不需要访问主键索引,所以主键索引上没有加任何锁,这就是为什么session B的update语句可以执行完成。
但session C要插入一个(7,7,7)的记录,就会被session A的间隙锁(5,10)锁住。
需要注意,在这个例子中,lock in share mode只锁覆盖索引,但是如果是for update就不一样了。 执行 for update时,系统会认为你接下来要更新数据,因此会顺便给主键索引上满足条件的行加上行锁。
这个例子说明,锁是加在索引上的;同时,它给我们的指导是,如果你要用lock in share mode来给行加读锁避免数据被更新的话,就必须得绕过覆盖索引的优化,在查询字段中加入索引中不存在的字段。比如,将session A的查询语句改成select d from t where c=5 lock in share mode。你可以自己验证一下效果。
案例三:主键索引范围锁
第三个例子是关于范围查询的。
举例之前,你可以先思考一下这个问题:对于我们这个表t,下面这两条查询语句,加锁范围相同吗?
mysql> select * from t where id=10 for update; mysql> select * from t where id>=10 and id<11 for update;
你可能会想,id定义为int类型,这两个语句就是等价的吧?其实,它们并不完全等价。
在逻辑上,这两条查语句肯定是等价的,但是它们的加锁规则不太一样。现在,我们就让session A执行第二个查询语句,来看看加锁效果。

图3 主键索引上范围查询的锁
现在我们就用前面提到的加锁规则,来分析一下session A 会加什么锁呢?
-
开始执行的时候,要找到第一个id=10的行,因此本该是next-key lock(5,10]。 根据优化1, 主键id上的等值条件,退化成行锁,只加了id=10这一行的行锁。
-
范围查找就往后继续找,找到id=15这一行停下来,因此需要加next-key lock(10,15]。
所以,session A这时候锁的范围就是主键索引上,行锁id=10和next-key lock(10,15]。这样,session B和session C的结果你就能理解了。
这里你需要注意一点,首次session A定位查找id=10的行的时候,是当做等值查询来判断的,而向右扫描到id=15的时候,用的是范围查询判断。
案例四:非唯一索引范围锁
接下来,我们再看两个范围查询加锁的例子,你可以对照着案例三来看。
需要注意的是,与案例三不同的是,案例四中查询语句的where部分用的是字段c。
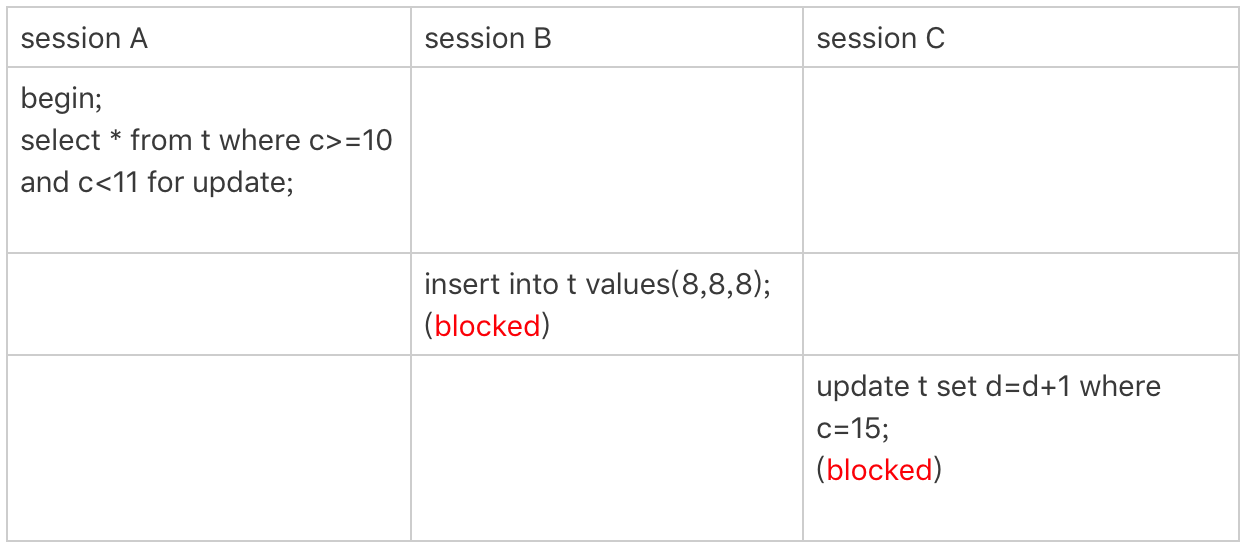
图4 非唯一索引范围锁
这次session A用字段c来判断,加锁规则跟案例三唯一的不同是:在第一次用c=10定位记录的时候,索引c上加了(5,10]这个next-key lock后,由于索引c是非唯一索引,没有优化规则,也就是说不会蜕变为行锁,因此最终sesion A加的锁是,索引c上的(5,10] 和(10,15] 这两个next-key lock。
所以从结果上来看,sesson B要插入(8,8,8)的这个insert语句时就被堵住了。
这里需要扫描到c=15才停止扫描,是合理的,因为InnoDB要扫到c=15,才知道不需要继续往后找了。
案例五:唯一索引范围锁bug
前面的四个案例,我们已经用到了加锁规则中的两个原则和两个优化,接下来再看一个关于加锁规则中bug的案例。
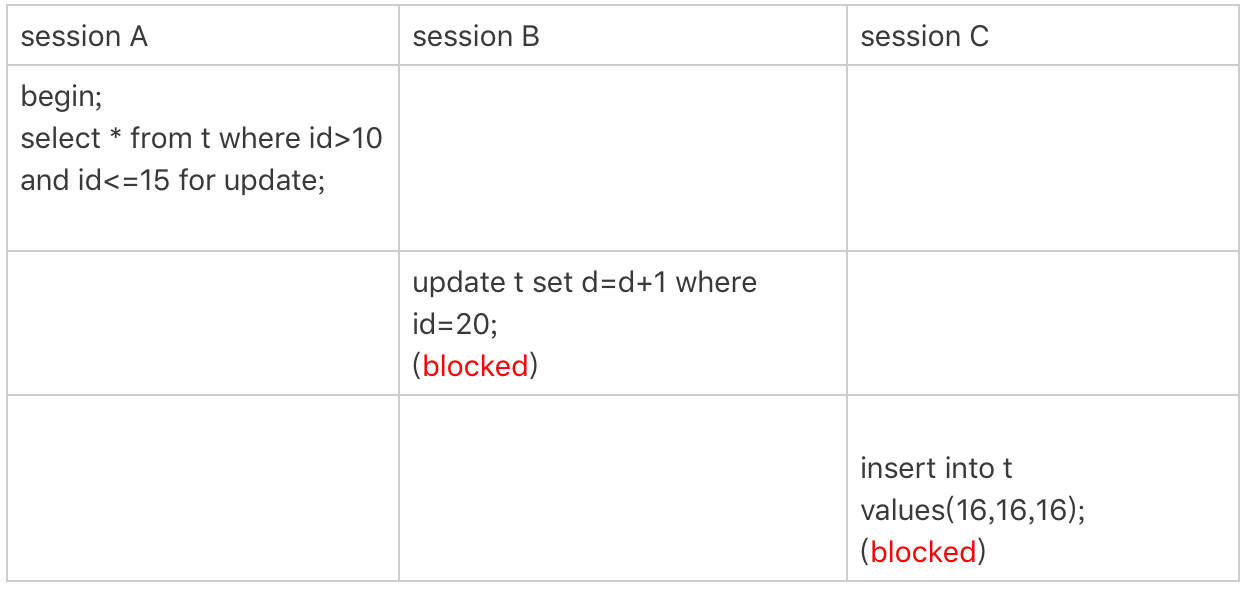
图5 唯一索引范围锁的bug
session A是一个范围查询,按照原则1的话,应该是索引id上只加(10,15]这个next-key lock,并且因为id是唯一键,所以循环判断到id=15这一行就应该停止了。
但是实现上,InnoDB会往前扫描到第一个不满足条件的行为止,也就是id=20。而且由于这是个范围扫描,因此索引id上的(15,20]这个next-key lock也会被锁上。
所以你看到了,session B要更新id=20这一行,是会被锁住的。同样地,session C要插入id=16的一行,也会被锁住。
照理说,这里锁住id=20这一行的行为,其实是没有必要的。因为扫描到id=15,就可以确定不用往后再找了。但实现上还是这么做了,因此我认为这是个bug。
我也曾找社区的专家讨论过,官方bug系统上也有提到,但是并未被verified。所以,认为这是bug这个事儿,也只能算我的一家之言,如果你有其他见解的话,也欢迎你提出来。
案例六:非唯一索引上存在"等值"的例子
接下来的例子,是为了更好地说明“间隙”这个概念。这里,我给表t插入一条新记录。
mysql> insert into t values(30,10,30);
新插入的这一行c=10,也就是说现在表里有两个c=10的行。那么,这时候索引c上的间隙是什么状态了呢?你要知道,由于非唯一索引上包含主键的值,所以是不可能存在“相同”的两行的。
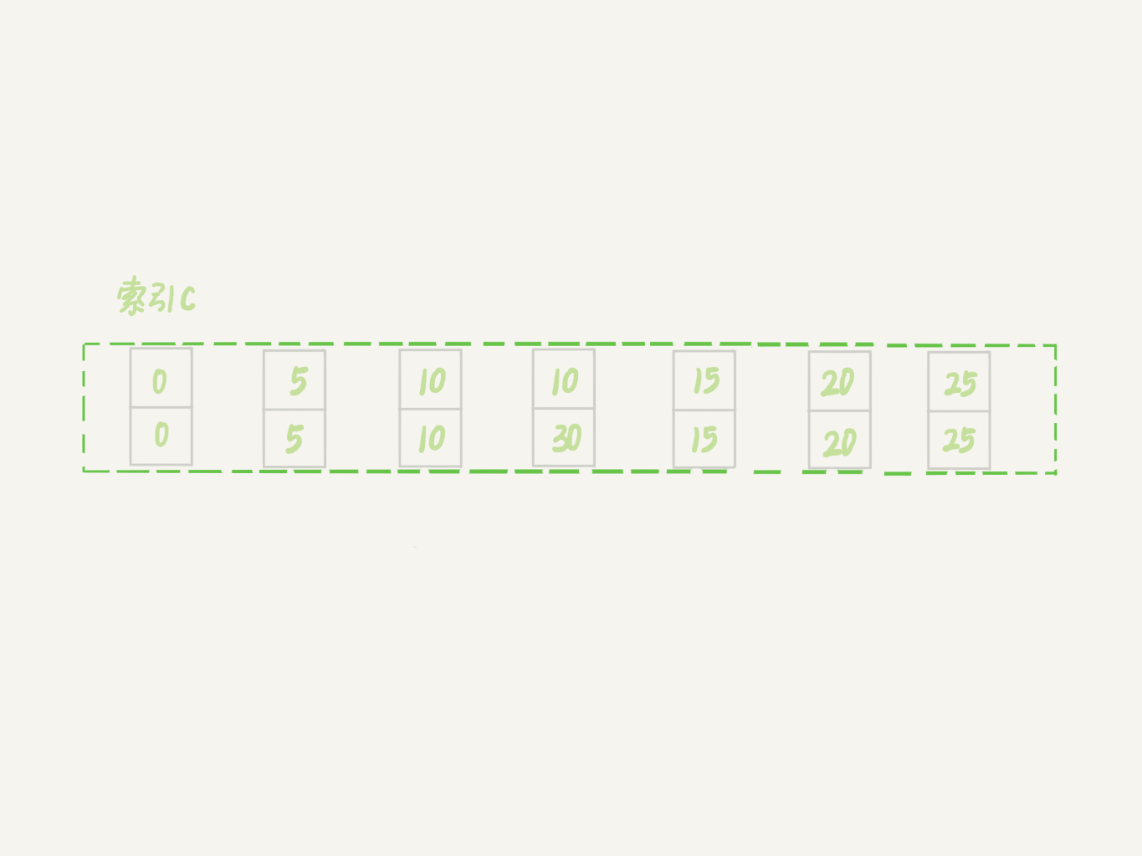
图6 非唯一索引等值的例子
可以看到,虽然有两个c=10,但是它们的主键值id是不同的(分别是10和30),因此这两个c=10的记录之间,也是有间隙的。
图中我画出了索引c上的主键id。为了跟间隙锁的开区间形式进行区别,我用(c=10,id=30)这样的形式,来表示索引上的一行。
现在,我们来看一下案例六。
这次我们用delete语句来验证。注意,delete语句加锁的逻辑,其实跟select ... for update 是类似的,也就是我在文章开始总结的两个“原则”、两个“优化”和一个“bug”。
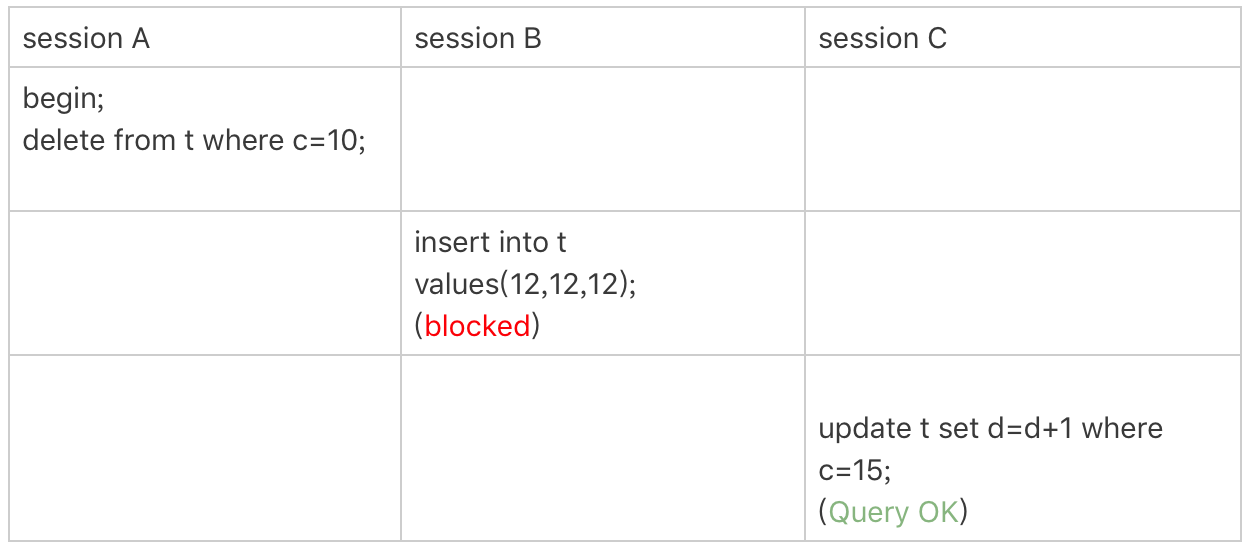
图7 delete 示例
这时,session A在遍历的时候,先访问第一个c=10的记录。同样地,根据原则1,这里加的是(c=5,id=5)到(c=10,id=10)这个next-key lock。
然后,session A向右查找,直到碰到(c=15,id=15)这一行,循环才结束。根据优化2,这是一个等值查询,向右查找到了不满足条件的行,所以会退化成(c=10,id=10) 到 (c=15,id=15)的间隙锁。
也就是说,这个delete语句在索引c上的加锁范围,就是下图中蓝色区域覆盖的部分。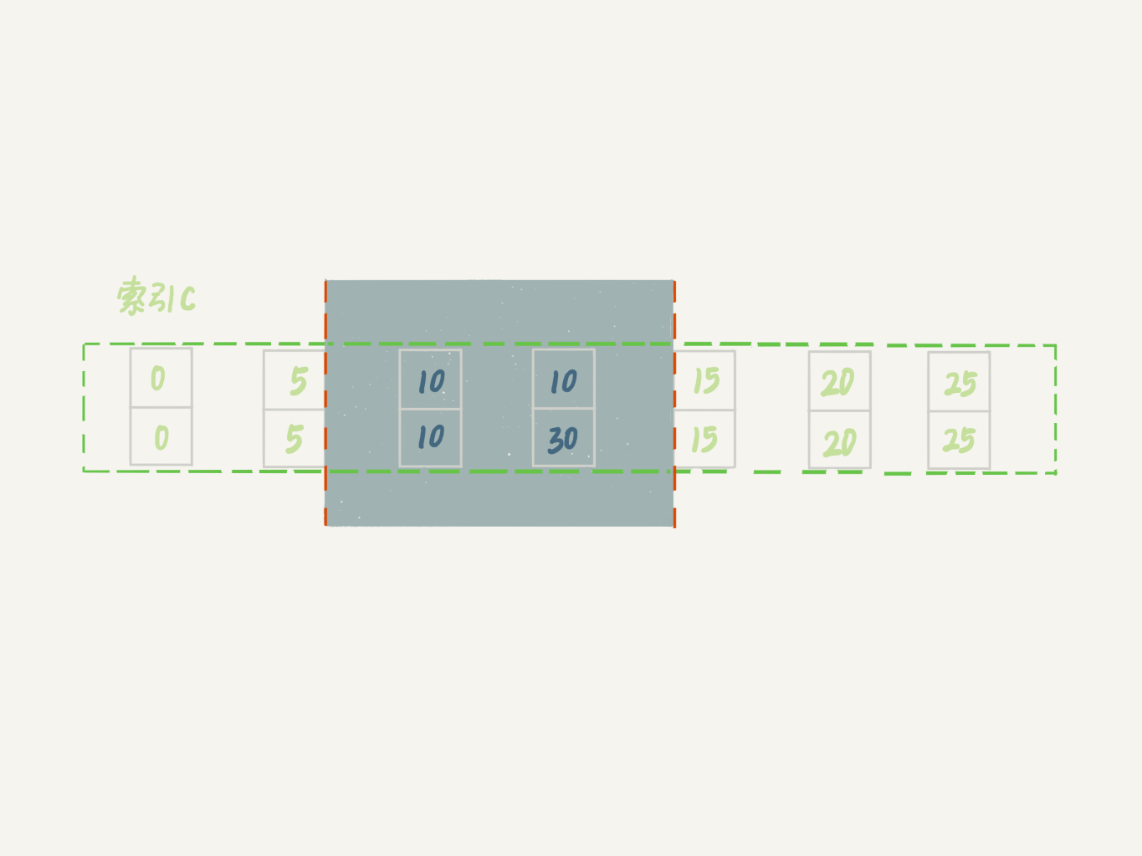
图8 delete加锁效果示例
这个蓝色区域左右两边都是虚线,表示开区间,即(c=5,id=5)和(c=15,id=15)这两行上都没有锁。
案例七:limit 语句加锁
例子6也有一个对照案例,场景如下所示:

图9 limit 语句加锁
这个例子里,session A的delete语句加了 limit 2。你知道表t里c=10的记录其实只有两条,因此加不加limit 2,删除的效果都是一样的,但是加锁的效果却不同。可以看到,session B的insert语句执行通过了,跟案例六的结果不同。
这是因为,案例七里的delete语句明确加了limit 2的限制,因此在遍历到(c=10, id=30)这一行之后,满足条件的语句已经有两条,循环就结束了。
因此,索引c上的加锁范围就变成了从(c=5,id=5)到(c=10,id=30)这个前开后闭区间,如下图所示: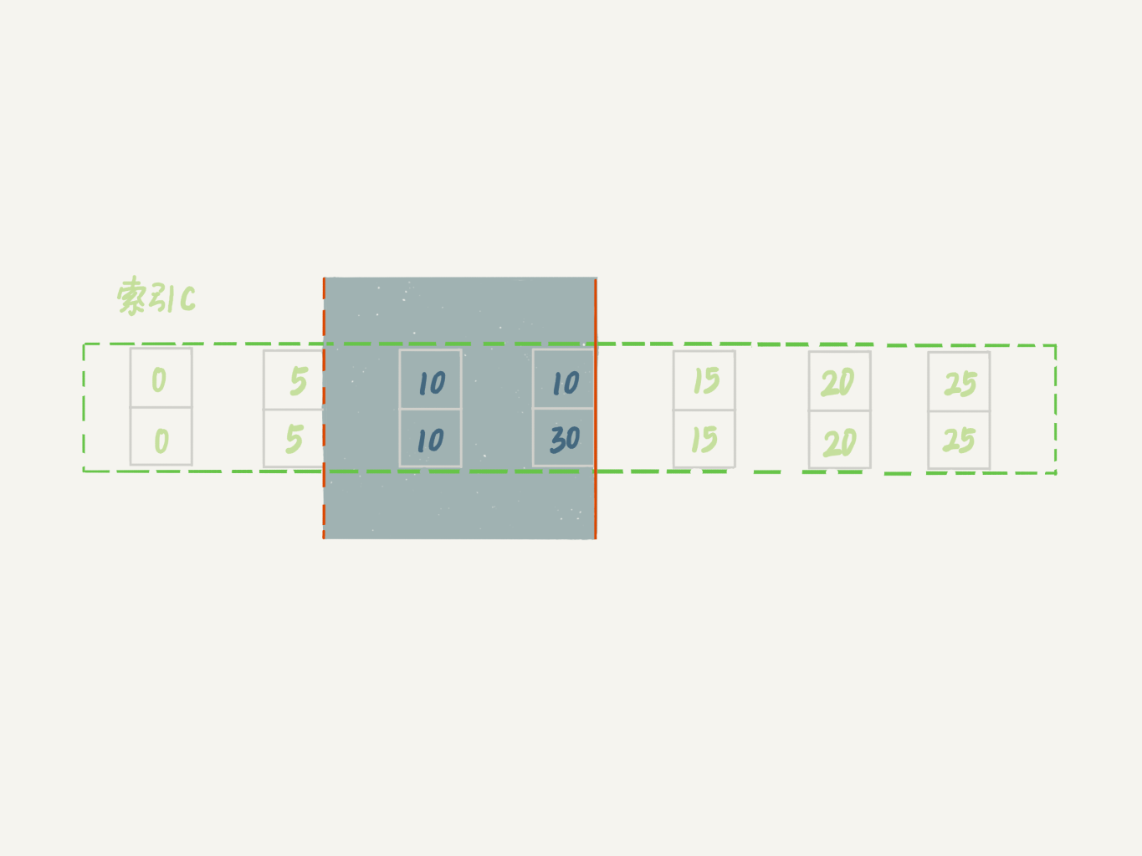
图10 带limit 2的加锁效果
可以看到,(c=10,id=30)之后的这个间隙并没有在加锁范围里,因此insert语句插入c=12是可以执行成功的。
这个例子对我们实践的指导意义就是,在删除数据的时候尽量加limit。这样不仅可以控制删除数据的条数,让操作更安全,还可以减小加锁的范围。
案例八:一个死锁的例子
前面的例子中,我们在分析的时候,是按照next-key lock的逻辑来分析的,因为这样分析比较方便。最后我们再看一个案例,目的是说明:next-key lock实际上是间隙锁和行锁加起来的结果。
你一定会疑惑,这个概念不是一开始就说了吗?不要着急,我们先来看下面这个例子:

图11 案例八的操作序列
现在,我们按时间顺序来分析一下为什么是这样的结果。
-
session A 启动事务后执行查询语句加lock in share mode,在索引c上加了next-key lock(5,10] 和间隙锁(10,15);
-
session B 的update语句也要在索引c上加next-key lock(5,10] ,进入锁等待;
-
然后session A要再插入(8,8,8)这一行,被session B的间隙锁锁住。由于出现了死锁,InnoDB让session B回滚。
你可能会问,session B的next-key lock不是还没申请成功吗?
其实是这样的,session B的“加next-key lock(5,10] ”操作,实际上分成了两步,先是加(5,10)的间隙锁,加锁成功;然后加c=10的行锁,这时候才被锁住的。
也就是说,我们在分析加锁规则的时候可以用next-key lock来分析。但是要知道,具体执行的时候,是要分成间隙锁和行锁两段来执行的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号