


python基础4 函数参数引用 python内置函数 filter map open处理文件
一 作业点回顾
1 判断对象是否属于某个类 对应题:比如 列表有个数字,但是循环列表就判断长度,用len 会报错。 因为int不支持len ,所以先判断 属于某类,再进行if判断。

# isinstance(对象,类名) 判断变量输入的对象是否是属于这个类 # 方法1: temp = [11, 22, "", " ", []] print(isinstance(temp, (str, list, tuple))) # 一旦对象属于这个后面元组的类中的任何一个 就返回true # 方法2: a = type(temp) is list print(a)
二 函数 参数引用 知识点
写在前面:
python中 函数传参,传引用 ,形参其实是指针映射到 实际参数的的内存地址中的。一旦更改形参对应的值,实际参数也会改。
而 java c# 是可以改的,形参 实际参数都 生成一份数据 ,这个功能要想完成只需在 形参处 加一个ref out /再创建一份值
python 函数形参 是指针向实际参数的。
python中 直接 copy一份就行
函数参数 引用 1 :修改 或删除形参的 值 ,实际参数值也变化
函数调用,而实际参数传入的是一个列表, 这样就是 形式参数args = 实际参数li = [1,2] 由下图表示
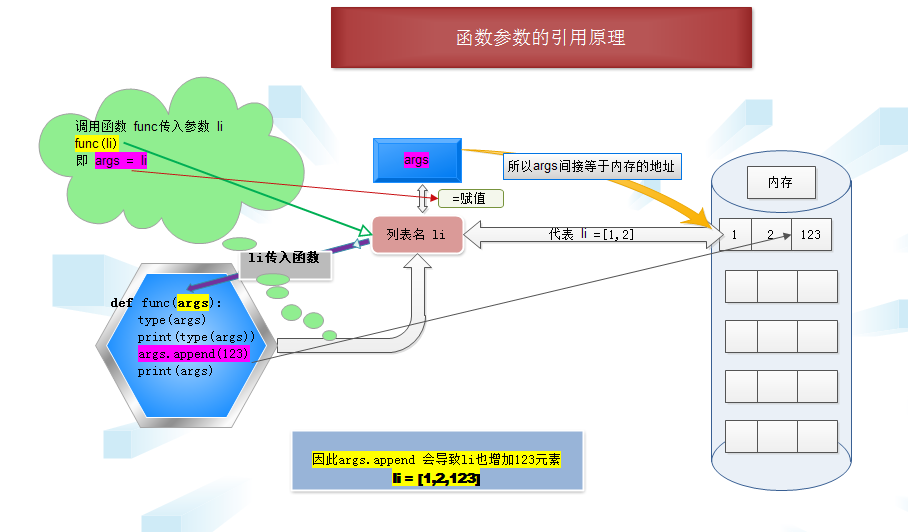
def func(args):
type(args)
print(type(args))
args.append(123)
print(args)
li = [1, 2]
func(li)
print(li)
删除 也删除 其实 li = [] args=li 原理一样 def func(args): del args[2:] li=[1,2,3,4] a=func(li) print(li) #结果[1, 2]
函数 参数引用2 : 形式参数 赋值 另开辟内存
尽管 传入实际参数 li 使得 args =li ,但是 函数主体 args=123 重新赋值 相当于args重新开辟了一段 内存空间,而原li还是原来的值 如果是同一个变量名 重新赋值,原来占用内存的那个 变量空间 python会定时回收

赋值 尽管 函数调用时候 args=li 但是重新赋值,等于申请了新的内存空间。 def func(args): args=123 li=[1,2,3,4] a=func(li) print(li) #结果 [1,2,3,4]
三 lambda 匿名函数
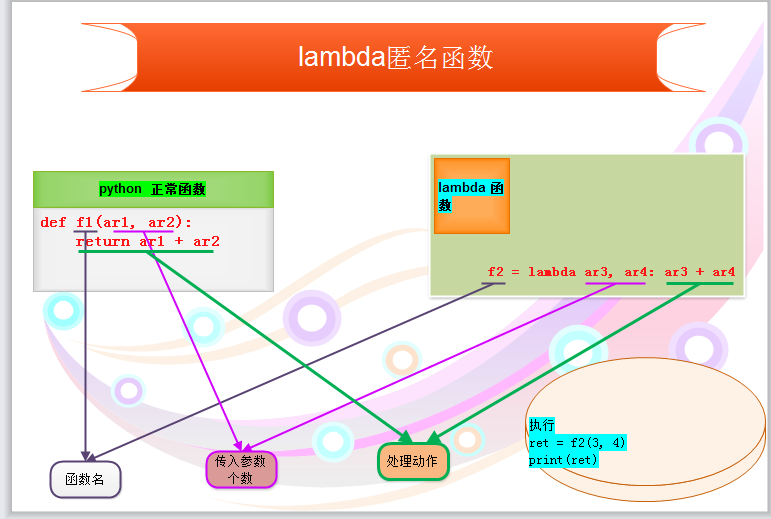
# lambda 匿名函数
def f1(ar1, ar2):
return ar1 + ar2
f2 = lambda ar3, ar4: ar3 + ar4
ret = f2(3, 4)
print(ret)
学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即:
1 # 普通条件语句 2 if 1 == 1: 3 name = 'wupeiqi' 4 else: 5 name = 'alex' 6 7 # 三元运算 8 name = 'wupeiqi' if 1 == 1 else 'alex'
对于简单的函数,也存在一种简便的表示方式,即:lambda表达式
1 # ###################### 普通函数 ###################### 2 # 定义函数(普通方式) 3 def func(arg): 4 return arg + 1 5 6 # 执行函数 7 result = func(123) 8 9 # ###################### lambda ###################### 10 11 # 定义函数(lambda表达式) 12 my_lambda = lambda arg : arg + 1 13 14 # 执行函数 15 result = my_lambda(123)
四 python的内置函数

注:查看详细猛击这里
1 大部分函数
abs()返回一个数字的绝对值。如果给出复数,返回值就是该复数的模。
>>>print abs(-100) 100 >>>print abs(1+2j) 2.2360679775
1 # 内置函数: 2 # 1 abs() 绝对值 3 a = 123 4 b = -123 5 print(abs(a)) 6 print(abs(b))
all() 所有为真才为真,只要有一个假就是假
判断假的条件:
任何一种都为假: 0 None 空值(字符串 列表 元组 字典)
li = [1, 2, 3, "", False] print(all(li))
any() 一个为真就为真 同all相反,只有有真就返回True 真: 非0 非None 非空
1 li = [1, 2, 3, "", False] 2 print(any(li))
ascii() 用法:ascii(对象) ===去类中找 __repr__ 方法,获取返回值
1 class Foo(object): 2 def __repr__(self): 3 return "hello repr" 4 5 6 li = Foo() 7 n = ascii(li) 8 print(n)
bin oct int hex 二进制 八进制 十进制 十六进制
1 # bin() 可以将 八 十 十六 进制 转换成二进制 2 print(bin(10), bin(0o13), bin(0x14)) 3 # oct() 可以将 二 十 十六 进制 转换为八进制 4 print(oct(10), oct(0b101), oct(0x14)) 5 # int() 可以将 二 八 十六进制转换为十进制 6 print(int(0o13), int(0b101), int(0x14)) 7 # hex() 可以将 二 八 十 进制转换为十六进制 8 print(hex(0b101), hex(110), hex(0o12))
bool 判断真假
看到上面的结果了没?是True。突然记起Python中除了''、""、0、()、[]、{}、None为False之外,其他的都是True。也就是说上面的'False'就是一个不为空的字符串,所以结果就为True了
1 >>> bool('False')
2 True
将一个值转化成布尔值,使用标准的真值测试例程。如果x为假或者被忽略它返回False;否则它返回True。bool也是一个类,它是int的子类。bool不能被继承。它唯一的实例就是False和True。
# 7 bytes bytearray 字节列表
byte在前面已经介绍过了 bytes('str',encoding='')
bytearray([source[, encoding[, errors]]])
1 返回一个新的字节数组。bytearray类型是一个可变的整数序列,整数范围为0 <= x < 256(即字节)。 它有可变序列的大多数方法,参见Mutable Sequence Types,同时它也有str类型的大多数方法,参见String Methods。 2 3 source参数可以以不同的方式来初始化数组,它是可选的: 4 5 如果是string,必须指明encoding(以及可选的errors)参数;bytearray()使用str.encode()将字符串转化为字节数组。 6 如果是integer,生成相应大小的数组,元素初始化为空字节。 7 如果是遵循buffer接口的对象,对象的只读buffer被用来初始化字节数组。 8 如果是iterable,它的元素必须是整数,其取值范围为0 <= x < 256,用以初始化字节数组。 9 如果没有参数,它创建一个大小为0的数组。
>>> a = bytearray(3)
>>> a
bytearray(b'\x00\x00\x00')
>>> a[0]
>>> a[1]
>>> a[2]
>>> b = bytearray("abc")
>>> b
bytearray(b'abc')
>>> b[0]
>>> b[1]
>>> b[2]
>>> c = bytearray([1, 2, 3])
>>> c
bytearray(b'\x01\x02\x03')
>>> c[0]
>>> c[1]
>>> c[2]
>>> d = bytearray(buffer("abc"))
>>> d
bytearray(b'abc')
>>> d[0]
>>> d[1]
>>> d[2]
chr ord 转换 ascii对应的字符与十进制整数转换 可以百度 ascii 对照表
返回一个单字符字符串,字符的ASCII码为整数i。例如,chr(97)返回字符串'a'。 它是ord()的逆运算。参数的取值范围为[0..255]的闭区间;如果i超出取值范围,抛出ValueError。参见unichr()。
1 c = chr(65)
2 i = ord("A")
3 print(c, i)
打印 字母 数字
# 随机验证码 程序: # 65 -90 A - Z # 而 random.randrange(num1,num2) 大于等于num1 小于num2 的随机数 import random tmp = "" for i in range(6): num = random.randrange(0, 4) # 0-3 随机 if num == 2 or num == 3: # 随机数字时候 赋值随机数字 rad1 = random.randrange(0, 9) rad1 = str(rad1) #转换字符串 tmp += rad1 #字符串拼接 else: rad2 = random.randrange(65, 91) rad2 = chr(rad2) tmp += rad2 print("本次验证码:", tmp)
我自己写的验证码 数字 大小写字母
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
import randomprint(random.random())print(random.randint(1, 2)) # 返回列表的值[1,2] 因此 start 和end 都能访问到'''def randint(self, a, b): """Return random integer in range [a, b], including both end points. """ return self.randrange(a, b+1)'''print(random.randrange(1, 10)) # randrange(self, start, stop=None, step=1, _int=int)temp =""flag = 1for i in range(6): num = random.randint(65,90) for n in range(4): if len(temp) >= 6: flag = 0 break x = random.randint(0,9) if x < n: temp += str(x) elif x == n: #temp += chr(num).swapcase() # 大写变小写,小写变大写到 temp += chr(num).lower() # 大写变小写,小写变大写到 if len(temp) >= 6: flag = 0 break if flag == 0: break temp += chr(num)print(temp) |
callable(object)
检查某个对象是否可以被执行 即 对象()
如果object参数可调用,返回True;否则返回False。如果返回真,对其调用仍有可能失败;但是如果返回假,对object的调用总是失败。注意类是可调用的(对类调用返回一个新实例);如果类实例有__call__()方法,则它们也是可调用的。
# 10 classmethod 后面讲 重要
# 11 compile 编译 默认读文件都是字符串,经过编译变成代码
#!usr/bin/env python
#coding:utf-8
namespace = {'name':'wupeiqi','data':[18,73,84]}
code = '''def hellocute():return "name %s ,age %d" %(name,data[0],) '''
func = compile(code, '<string>', "exec")
exec func in namespace
result = namespace['hellocute']()
print result
hasattr getattr delattr 反射 后面单独讲
# hasattr() getattr() delattr() # >>> hasattr(list, 'append') # True # >>> hasattr(list, 'add') # False
# 12 complex 复数
创建一个复数,它的值为real + imag*j;或者将一个字符串/数字转化成一个复数。如果第一个参数是个字符串,它将被解释成复数,同时函数不能有第二个参数。
第二个参数不能是字符串。每个参数必须是数值类型(包括复数)。如果imag被忽略,它的默认值是0,这时该函数就像是int(),long()和float()这样的数值转换函数。
如果两个参数都被忽略,返回0j。 注意 当从字符串转化成复数的时候,字符串中+或者-两边不能有空白。例如,complex('1+2j')是可行的,但complex('1 + 2j')会抛出ValueError异常。 在Numeric Types — int, float, long, complex中有对复数的描述。
# dir 显示类的方法
如果没有参数,返回当前本地作用域内的名字列表。如果有参数,尝试返回参数所指明对象的合法属性的列表。
如果对象有__dir__()方法,该方法被调用且必须返回一个属性列表。这允许实现了定制化的__getattr__()或者__getattribute__()函数的对象定制dir()报告对象属性的方式。
如果对象没有提供__dir__(),同时如果对象有定义__dict__属性,dir()会先尝试从__dict__属性中收集信息,然后是对象的类型对象。结果列表没有必要是完整的,如果对象有定制化的__getattr__(),结果还有可能是不准确的。
对于不同类型的对象,默认的dir()行为也不同,因为它尝试产生相关的而不是完整的信息:
- 如果对象是模块对象,列表包含模块的属性名。
- 如果对象是类型或者类对象,列表包含类的属性名,及它的基类的属性名。
- 否则,列表包含对象的属性名,它的类的属性名和类的基类的属性名。
返回的列表按字母顺序排序。例如:
1 >>> import struct 2 >>> dir() # show the names in the module namespace 3 ['__builtins__', '__doc__', '__name__', 'struct'] 4 >>> dir(struct) # show the names in the struct module 5 ['Struct', '__builtins__', '__doc__', '__file__', '__name__', 6 '__package__', '_clearcache', 'calcsize', 'error', 'pack', 'pack_into', 7 'unpack', 'unpack_from'] 8 >>> class Shape(object): 9 def __dir__(self): 10 return ['area', 'perimeter', 'location'] 11 >>> s = Shape() 12 >>> dir(s) 13 ['area', 'perimeter', 'location']
注意
因为dir()主要是为了在交互式环境下使用方便,它尝试提供有意义的名字的集合,而不是提供严格或一致定义的名字的集合,且在不同的版本中,具体的行为也有所变化。例如,如果参数是一个类,那么元类属性就不会出现在结果中。
# 14 divmod(10,3) 显示商和余数
# 分页 :余数大于0 商+1 为页数
在长整数除法中,传入两个数字(非复数)作为参数,返回商和余数的二元组。
对于混合的操作数类型,应用二元算术运算符的规则。对于普通整数或者长整数,结果等同于(a // b, a % b)。对于浮点数结果是(q, a % b),q一般是math.floor(a / b),但也可能比那小1。
不管怎样,q * b + a % b非常接近于a,如果a % b非0,它和b符号相同且0 <= abs(a % b) < abs(b)。
# 15 enumerate 序列
enumerate(sequence, start=0)
返回一个枚举对象。sequence必须是个序列,迭代器iterator,或者支持迭代的对象。enumerate()返回的迭代器的next()方法返回一个元组,它包含一个计数(从start开始,默认为0)和从sequence中迭代得到的值:
1 >>> seasons = ['Spring', 'Summer', 'Fall', 'Winter'] 2 >>> list(enumerate(seasons)) 3 [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] 4 >>> list(enumerate(seasons, start=1)) 5 [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
等同于:
def enumerate(sequence, start=0):
n = start
for elem in sequence:
yield n, elem
n += 1
# 16 eval # 字符串 转算 执行表达式 有返回值
eval(expression[, globals[, locals]])
参数是Unicode或者Latin-1编码的字符串,全局变量和局部变量可选。如果有全局变量,globals必须是个字典。如果有局部变量,locals可以是任何映射类型对象。
改变于版本2.4:在此之前locals需要是个字典。
expression参数被当作Python表达式来解析并演算(技术上来说,是个条件列表),使用globals和locals字典作为全局和局部的命名空间。如果globals字典存在,且缺少‘__builtins__’,在expression被解析之前,当前的全局变量被拷贝进globals。这意味着一般来说expression能完全访问标准__builtin__模块,且受限的环境会传播。如果locals字典被忽略,默认是globals字典。如果都被忽略,表达式在eval()被调用的环境中执行。返回值是被演算的表达式的结果。语法错误报告成异常。例子:
>>> x = 1
>>> print eval('x+1')
2
a = "1 + 3"
n = eval(a)
print(n)
ret = eval("a+60", {"a": 88})
print(ret)
该函数也能执行任意的代码对象(如compile()返回的结果)。 在这种情况下,传递代码对象而不是字符串。如果代码对象编译时mode参数为'exec',eval()返回None。
提示:exec语句支持动态的语句执行。execfile()函数支持执行文件中的语句。globals()和locals()函数返回当前的全局变量和局部变量的字典,可以传递给eval()或者execfile()。
参见ast.literal_eval(),该函数能安全演算只含字面量的表达式的字符串。
# 17 exec 将字符串 执行 complie 编译功能 结合是 模板引擎
exec("for i in range(3):print(i)")
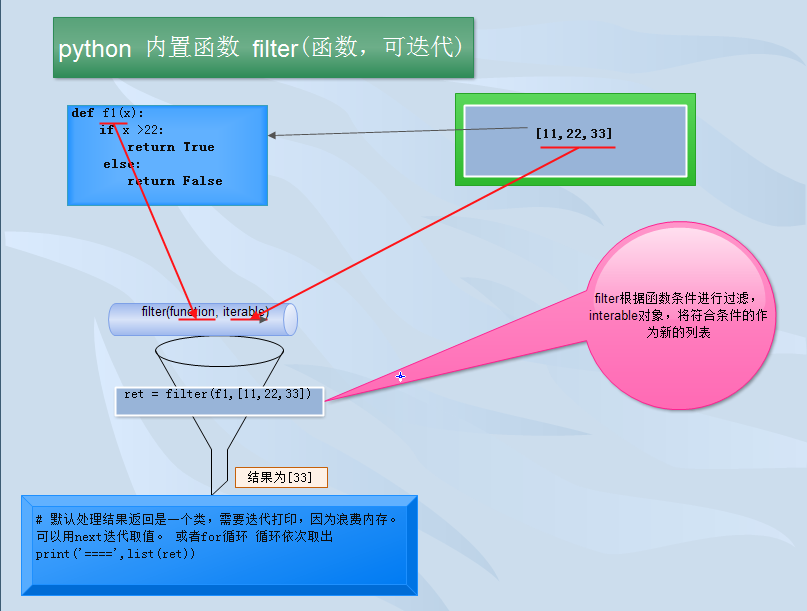
# 18 filter map reduce # filter(函数,可迭代的对象)
1 def f1(x): 2 if x >22: 3 return True 4 else: 5 return False 6 ret = filter(f1,[11,22,33]) 7 # 默认处理结果返回是一个类,需要迭代打印,因为浪费内存。 可以用next迭代取值。 或者for循环 循环依次取出 8 print(next(ret))
print(list(ret))
1 #filter 实现 2 def myfilter(fuc,seq): 3 new_li = [] 4 for i in seq: 5 #print(i) 6 ret = fuc(i) 7 if ret: 8 new_li.append(i) 9 return new_li 10 def f1(x): 11 if x > 22: 12 return True 13 else: 14 return False 15 li = [11,22,33,44] 16 new=myfilter(f1,li) 17 print(new)
filter(function, iterable)
构造一个列表,列表的元素来自于iterable,对于这些元素function返回真。iterable可以是个序列,支持迭代的容器,或者一个迭代器。如果iterable是个字符串或者元组,则结果也是字符串或者元组;否则结果总是列表。如果function是None,使用特性函数,即为假的iterable被移除。
注意,在function不为None的情况下, filter(function, iterable) 等同于 [item for item in iterable if function(item)]; 否则等同于 [item foritem in iterable if item](function为None)。
# filter中 lambda 函数替换 函数f1
1 ret1 = filter(lambda x:x>22,[11,22,33,44]) 2 print(list(ret1))
# map map(函数,可迭代的对象
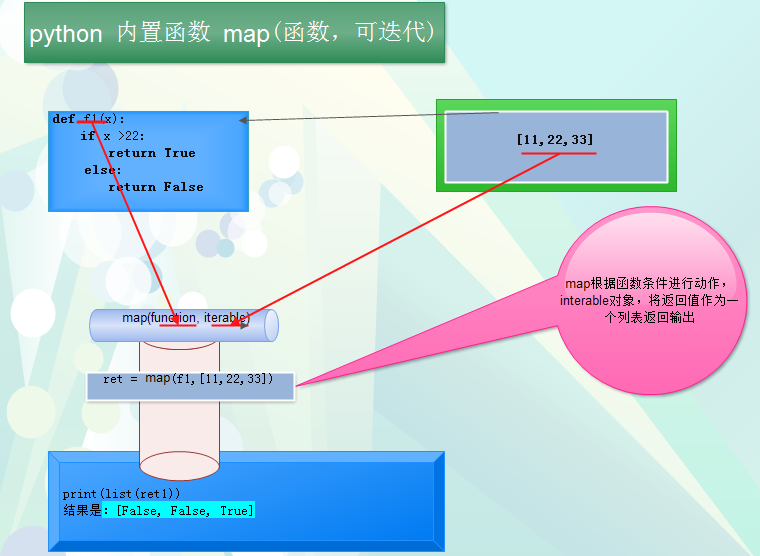
1 # map 实现 2 def mymap(fuc,seq): 3 n_li = [] 4 for i in seq: 5 n_i=fuc(i) 6 n_li.append(n_i) 7 # print(n_li) 8 return n_li 9 def f2(x): 10 return x+10 11 li = [11,22,33,44] 12 13 ret = mymap(f2,li) 14 print(ret)
1 def f1(x): 2 if x >22: 3 return True 4 else: 5 return False 6 ret1 = map(f1,[11,22,33,44]) 7 print(list(ret1)) 8 结果是:[False, False, True, True] 9 10 ret1 = map(lambda x:x+22,[11,22,33,44]) 11 print(list(ret1)) 12 结果是:[33, 44, 55, 66]
# format 格式化 字符串拼接+ 性能低
后面讲
# globals() 获取所有的全局变量
#local() #获取所有局部变量
# hash(对象) 获取对象hash 内存优化
返回对象的hash(哈希/散列)值(如果有的话)。hash值是整数。它被用于在字典查找时快速比较字典的键。相同的数值有相同的hash(尽管它们有不同的类型,比如1和1.0)。
# isinstance(对象,类)
上面有讲 判断对象是否是某个类创建的 父类的话也成立
# issubclass 是否是子类 后面讲
# iter 迭代器 后面讲
obj = iter([11,22,33,44]) ret = next(obj) print(ret)
# yield 生成器
后面讲
# max 最大 min
li = [11,22,33,44] max(li)
# pow求次方
a= pow(2,10) print(a)
# repr() === ascii()
# round 四舍五入
round()方法返回 x 的小数点四舍五入到n个数字。
语法 以下是round()方法的语法: round( x [, n] ) 参数 x --这是一个数值表达式 n --这也是一个数值表达式 返回值 该方法返回 x 的小数点四舍五入到n个数字 例子 下面的例子显示了round()方法的使用 #!/usr/bin/python print "round(80.23456, 2) : ", round(80.23456, 2) print "round(100.000056, 3) : ", round(100.000056, 3) print "round(-100.000056, 3) : ", round(-100.000056, 3) 当我们运行上面的程序,它会产生以下结果: round(80.23456, 2) : 80.23 round(100.000056, 3) : 100.0 round(-100.000056, 3) : -100.0
# slice 对象切片
在python中,list, tuple以及字符串等可以遍历访问的类型都可以应用slice访问。slice本身的意思是指切片,在这些可以遍历访问的类型中截取其中的某些部分。
#sum 求和
sum(iterable[, start])
将start以及iterable的元素从左向右相加并返回总和。start默认为0。iterable的元素通常是数字,start值不允许是一个字符串。
对于某些使用场景,有比sum()更好的选择。连接字符串序列的首选和快速的方式是调用''.join(sequence)。如要相加扩展精度的浮点数,请参阅math.fsum()。若要连接一系列的可迭代量,可以考虑使用itertools.chain()。
其实sum()的参数是一个list 例如: sum([1,2,3]) sum(range(1,11)) 还有一个比较有意思的用法 a = range(1,11) b = range(1,10) c = sum([item for item in a if item in b]) print c 输出: 45
# supper 找到父类
super
(
type[, object-or-type])
返回一个代理对象,这个对象指派方法给一个父类或者同类. 这对进入类中被覆盖的继承方法非常有用。搜索顺序和 getattr() 一样。而它自己的 类型则被忽略
# vars 对象的变量个数
# zip 拉链 将两个列表合起来,做成一个列表,元素为数组
>>> a = range(5,10) >>> a [5, 6, 7, 8, 9] >>> b =(1,5) >>> b (1, 5) >>> b =range(1,5) >>> b [1, 2, 3, 4] >>> b.append(0) >>> b [1, 2, 3, 4, 0] >>> zip(a,b) [(5, 1), (6, 2), (7, 3), (8, 4), (9, 0)] >>> b.pop() 0 >>> b [1, 2, 3, 4] >>> a [5, 6, 7, 8, 9] >>> zip(a,b) [(5, 1), (6, 2), (7, 3), (8, 4)]
sort 函数
sorted(iterable[, cmp[, key[, reverse]]])
依据iterable中的元素返回一个新的列表。
可选参数cmp、key和reverse与list.sort()方法的参数含义相同(在可变的序列类型一节描述)。
cmp指定一个自定义的带有两个参数的比较函数(可迭代的元素),它应该根据第一个参数是小于、等于还是大于第二个参数返回负数、零或者正数:cmp=lambda x,y: cmp(x.lower(), y.lower())。默认值是None。
key指定一个带有一个参数的函数,它用于从每个列表元素选择一个比较的关键字:key=str.lower。默认值是None(直接比较元素)。
reverse是一个布尔值。如果设置为True,那么列表元素以反向比较排序。
通常情况下,key和reverse转换处理比指定一个等同的cmp函数要快得多。这是因为cmp为每个元素调用多次但是key和reverse只会触摸每个元素一次。使用functools.cmp_to_key()来转换旧式的cmp函数为key函数。
关于排序的实例和排序的简明教程,请参阅Sorting HowTo。
>>> sorted([5, 2, 3, 1, 4])
[1, 2, 3, 4, 5]
>>> a = [5, 2, 3, 1, 4]
>>> a.sort()
>>> a
[1, 2, 3, 4, 5]
sorted 默认值对列表排序故字典只对key排序
>>> sorted({1: 'D', 2: 'B', 3: 'B', 4: 'E', 5: 'A'})
[1, 2, 3, 4, 5]
key 函数
>>> sorted("This is a test string from Andrew".split(), key=str.lower)
['a', 'Andrew', 'from', 'is', 'string', 'test', 'This']
lambda
>>> student_tuples = [
('john', 'A', 15),
('jane', 'B', 12),
('dave', 'B', 10),
]
>>> sorted(student_tuples, key=lambda student: student[2]) # sort by age
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
The same technique works for objects with named attributes. For example:
>>> class Student:
def __init__(self, name, grade, age):
self.name = name
self.grade = grade
self.age = age
def __repr__(self):
return repr((self.name, self.grade, self.age))
def weighted_grade(self):
return 'CBA'.index(self.grade) / float(self.age)
>>> student_objects = [
Student('john', 'A', 15),
Student('jane', 'B', 12),
Student('dave', 'B', 10),
]
>>> sorted(student_objects, key=lambda student: student.age) # sort by age
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
更多详见 https://wiki.python.org/moin/HowTo/Sorting/
五 open() 函数 处理文件,单独拿出来讲解
open函数,该函数用于文件处理
操作文件时,一般需要经历如下步骤:
- 打开文件
- 操作文件
一、打开文件
文件句柄 = open('文件路径', '模式')
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
1 文件句柄 = open('文件路径','打开模式')
文件句柄相当于于变量名,文件路径可以写为绝对路径也可以写为相对路径。
文件句柄可以循环 每次1行
for line in 文件句柄:
文件句柄.write("新文件")
打开文件的模式有:
- r ,只读模式【默认】
- w,只写模式【不可读;不存在则创建;存在则清空内容;】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【不可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型
文件 hello.txt
Hello Word!
123
abc
456
abc
789
abc
刘建佐
代码 :
f = open("hello.txt",'rb') # 用到b模式的时候 就不能跟 编码了。
data = f.read()
f.close()
print(data)
输出
C:\Python35\python3.exe E:/py_test/s5/open.py
b'Hello Word!\r\n123\r\nabc\r\n456\r\nabc\r\n789\r\nabc\r\n\xe5\x88\x98\xe5\xbb\xba\xe4\xbd\x90'
python open函数 r 和rb区别

下面着重讲解下用"+" 同时读写某个文件的操作
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# r+形式 写的时候在末尾追加,指针移到到最后# 大家一定要清楚的明白读写的时候指针指向的位置,下面的这个例子一定要懂# f.tell() 读取指针的位置# f.seek(0) 设置指针的位置with open('1.txt','r+',encoding='utf-8') as f: print(f.tell()) #打印下 文件开始时候指针指向哪里 这里指向 0 print(f.read()) #读出文件内容'字符串', print(f.tell()) #文件指针指到 9,一个汉子三个字符串,指针是以字符为单位 f.write('科比') #写入内容'科比',需要特别注意此时文件指到文件末尾去了 print(f.read()) #指针到末尾去了,所以读取的内容为空 print(f.tell()) #指针指到15 f.seek(0) #将指针内容指到 0 位置 print(f.read()) #因为文件指针指到开头去了,所以可以读到内容 字符串科比 # w+形式 存在的话先清空 一写的时候指针到最后with open('1.txt','w+') as f: f.write('Kg') #1.txt存在,所以将内面的内容清空,然后再写入 'kg' print(f.tell()) #此时指针指向2 print(f.read()) #读不到内容,因为指针指向末尾了 f.seek(0) print(f.read()) #读到内容,因为指针上一步已经恢复到起始位置 # a+打开的时候指针已经移到最后,写的时候不管怎样都往文件末尾追加,这里就不再演示了,读者可以自己试一下# x+文件存在的话则报错,也不演示了 |
Python文件读取方式
| 模式 | 说明 |
| read([size]) | 读取文件全部内容,如果设置了size,那么就读取size字节 |
| readline([size]) | 一行一行的读取 |
| readlines() | 读取到的每一行内容作为列表中的一个元素 |
二、操作
 2.x Code 3.x
2.x Code 3.x操作示例:
测试的文件名是 "hello.txt" ,文件内容为:
Hello Word! 123 abc 456 abc 789 abc
read 方法
代码:
# 以只读的方式打开文件hello.txt
f = open("hello.txt","r")
# 读取文件内容赋值给变量c
c = f.read()
# 关闭文件
f.close()
# 输出c的值
print(c)
输出结果
C:\Python35\python3.exe E:/py_test/s5/open.py
Hello Word!
123
abc
456
abc
789
abc
readline
代码:
# 以只读模式打开文件hello.txt
f = open("hello.txt","r")
# 读取第一行 strip 去除空行
c1 = f.readline().strip()
# 读取第二行
c2 = f.readline().strip()
# 读取第三行
c3 = f.readline().strip()
# 关闭文件
f.close()
# 输出读取文件第一行内容
print(c1)
# 输出读取文件第二行内容
print(c2)
# 输出读取文件第三行内容
print(c3)
C:\Python35\python.exe F:/Python_code/sublime/Day06/file.py
Hello Word!
123
abc
readlines 获取到的是列表,每行是列表的元素
用法
# 以只读的方式打开文件hello.txt
f = open("hello.txt","r")
# 将文件所有内容赋值给c
c = f.readlines()
# 查看数据类型
print(type(c))
# 关闭文件
f.close()
# 遍历输出文件内容 # n.strip()去除空行
for n in c:
print(n.strip())
Python文件写入方式
| 方法 | 说明 |
| write(str) | 将字符串写入文件 ,原文件内容存在则清空,不存在新建 |
| writelines(sequence or strings) | 写多行到文件,参数可以是一个可迭代的对象,列表、元组等 |
write
代码:
# 以只读的模式打开文件write.txt,没有则创建,有则覆盖内容
file = open("write.txt","w")
# 在文件内容中写入字符串test write
file.write("test write")
# 关闭文件
file.close()
writeline
代码:
# 以只读模式打开一个不存在的文件wr_lines.txt
f = open("wr_lines.txt","w",encoding="utf-8")
# 写入一个列表
f.writelines(["11","22","33"])
# 关闭文件
f.close()
wr_lines.txt 文件内容:
112233
Python文件操作所提供的方法
close(self):
关闭已经打开的文件
f.close()
fileno(self):
文件描述符
f = open("hello.txt",'rb')
data = f.fileno()
f.close()
print(data)
输出结果
C:\Python35\python3.exe E:/py_test/s5/open.py
3
flush(self):
刷新缓冲区的内容到硬盘中
f.flush() #在r+ 或者 rb+模式下还没有 f.close() 或者之后,flush方法 就会将内存的数据写入硬盘。 否则在其他地方调用这个文件的新内容会找不到
isatty(self):
判断文件是否是tty设备,如果是tty设备则返回 True ,否则返回 False
f = open("hello.txt","r")
ret = f.isatty()
f.close()
print(ret)
返回结果:
C:\Python35\python.exe F:/Python_code/sublime/Day06/file.py False
readable(self):
是否可读,如果可读返回 True ,否则返回 False
f = open("hello.txt","r")
ret = f.readable()
f.close()
print(ret)
返回结果:
C:\Python35\python.exe F:/Python_code/sublime/Day06/file.py True
readline(self, limit=1):
每次仅读取一行数据
f = open("hello.txt","r")
print(f.readline())
print(f.readline())
f.close()
返回结果:
C:\Python35\python.exe F:/Python_code/sublime/Day06/file.py Hello Word! 123
readlines(self, hint=1):
把每一行内容当作列表中的一个元素
f = open("hello.txt","r")
print(f.readlines())
f.close()
返回结果:
C:\Python35\python.exe F:/Python_code/sublime/Day06/file.py ['Hello Word!\n', '123\n', 'abc\n', '456\n', 'abc\n', '789\n', 'ab c']
tell(self):
获取指针位置
f = open("hello.txt","r")
print(f.tell())
f.close()
返回结果:
C:\Python35\python.exe F:/Python_code/sublime/Day06/file.py 0
seek(self, offset, whence=io.SEEK_SET):
指定文件中指针位置
f = open("hello.txt","r")
print(f.tell())
f.seek(3)
print(f.tell())
f.close()
执行结果
C:\Python35\python.exe F:/Python_code/sublime/Day06/file.py 0 3
seekable(self):
指针是否可操作
f = open("hello.txt","r")
print(f.seekable())
f.close()
执行结果
C:\Python35\python.exe F:/Python_code/sublime/Day06/file.py True
writable(self):
是否可写
f = open("hello.txt","r")
print(f.writable())
f.close()
执行结果
C:\Python35\python.exe F:/Python_code/sublime/Day06/file.py False
writelines(self, lines):
写入文件的字符串序列,序列可以是任何迭代的对象字符串生产,通常是一个 字符串列表 。
f = open("wr_lines.txt","w")
f.writelines(["11","22","33"])
f.close()
执行结果
112233
read(self, n=None):
读取指定字节数据,后面不加参数默认读取全部
f = open("wr_lines.txt","r")
print(f.read(3))
f.seek(0)
print(f.read())
f.close()
执行结果
C:\Python35\python.exe F:/Python_code/sublime/Day06/file.py 112 112233
write(self, s):
往文件里面写内容
f = open("wr_lines.txt","w")
f.write("abcabcabc")
f.close()
文件内容
abcabcabc
练习题: 2版本 操作 文件内容替换
View Code
三、管理上下文
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
1 with open('log','r') as f:
2
3 ...
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 及以后,with又支持同时对多个文件的上下文进行管理,即:
1 with open('log1') as obj1, open('log2') as obj2:
2 pass
1 # 文件句柄可以循环,每次1句,写入 另一个文件
2 with open('hello.txt','r') as obj1 ,open('log2','w') as obj2:
3 for line in obj1:
4 obj2.write(line)
open fileinput 练习 更改文本内容 增删改查用户 以及注册登陆
1 #!/usr/bin/env python
2 # _*_ coding:utf-8 _*_
3 __author__ = 'liujianzuo'
4
5
6 def login(username,password):
7 """
8 用户验证
9 :param username: 用户名
10 :param password: 密码
11 :return: true 成功 false 失败
12 """
13 f = open("db",'r')
14 for line in f:
15 line=line.strip()
16 line=line.split(":")
17 if username == line[0] and password == line[1]:
18 return True
19 return False
20
21 def register(temp):
22 """
23 注册写入
24 :param temp: 写入的用户名密码
25 :return: true是注册成功
26 """
27 with open('db','a+',encoding='utf-8') as f:
28 f.write(temp)
29 return True
30 def user_exist(username):
31 """
32 判断用户存在并调用注册
33 :param username:
34 :return: true 是注册成功 false 是用户存在
35 """
36 with open('db','r',encoding='utf-8') as f:
37 for line in f:
38 if username == line.strip().split(':')[0]:
39 #print("exist")
40 return False
41 else:
42 pwd = input("pls input pwd:")
43 temp = "\n"+username+":"+pwd
44 a = register(temp)
45 if a:
46 #print("register success")
47 return True
48
49 def changepwd():
50 """
51 改密码
52 :return: True 改成功了 False 用户不存在
53 """
54 # import fileinput
55 # username = input("input ur username:")
56 # f = open('db','r+',)
57 # #print(type(username))
58 # for line in f:
59 # line = line.strip().split(':')
60 # #print(type(line[1]))
61 # #line[1] = str(line[1])
62 # if line[0] == username:
63 # pwd = input("chage ur 原来的 passwd:")
64 # if line[1] != pwd:
65 # print("not creect")
66 # return "原密码不对"
67 # f.close()
68 #
69 # new_pwd = input('chage ur new pwd:')
70 # # print(username+":"+new_pwd)
71 # # exit()
72 # for n in fileinput.input('db',inplace=1):
73 # #x = n.strip().split(':')
74 # n = n.replace(username+":"+pwd,username+":"+new_pwd).strip()
75 # print(n)
76 # return True
77 f = open('db','r')
78 data = f.readlines()
79 f.close()
80 username = input("pls input username:")
81 #print(data)
82 for i in range(len(data)):
83 if username == data[i].split(":")[0]:
84 pwd = input("input new passwd:")
85 data[i] = username+":"+pwd+"\n"
86 n = open('db','w+')
87 n.writelines(data)
88 return True
89
90 def dele():
91 """
92 删除用户
93 :return:
94 """
95 f = open('db','r')
96 data = f.readlines()
97 f.close()
98 username = input("pls input username:")
99 #print(data)
100 for i in range(len(data)):
101 if username == data[i].split(":")[0]:
102 #pwd = input("input new passwd:")
103 del data[i]
104 n = open('db','w+')
105 n.writelines(data)
106 return True
107
108 def chs(chose):
109 """
110 选择菜单
111 :param chose:
112 :return:
113 """
114 if chose == 1:
115 user = input("pls input username:")
116 pwd = input("pls input password:")
117
118 ret = login(user,pwd)
119 if ret:
120 print("登陆成功")
121 else:
122 print("登陆失败")
123 elif chose == 2:
124 user = input("register name:")
125 n = user_exist(user)
126 if n:
127 print("regist success")
128 else:
129 print("usernaem exist")
130 elif chose == 3:
131 ret = changepwd()
132 if ret:
133 print("修改成功")
134
135 elif chose == 4:
136 ret = dele()
137 if ret:
138 print("删除成功")
139
140 else:
141 print("chose not correct")
142 def confirm(chose):
143 """
144 判断输入
145 :param chose:
146 :return:
147 """
148 while True:
149 if len(chose) == 0:
150 print("\033[31;1mnot empty!!!!\033[0m")
151 chose = input("\033[35;1mpls input ur chose ,quit for leave:\033[0m")
152 continue
153 elif chose == 'quit':
154 return True
155 elif chose.isdigit() != True:
156 print("\033[31;1minput digit!!!!\033[0m")
157 chose = input("\033[35;1mpls input ur chose ,quit for leave:\033[0m")
158 continue
159 else:
160 break
161
162 def main():
163 print("""\033[32;1m
164 1 login
165 2 register
166 3 忘记密码
167 4 删除用户
168 \033[0m""")
169 chose = input("\033[35;1mpls input ur chose ,quit for leave:\033[0m")
170 ret = confirm(chose)
171 if ret:
172 print("will quit")
173 return ret
174 chose=int(chose)
175 chs(chose)
176
177 if __name__ == "__main__":
178 main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号