Deep Learning.ai学习笔记_第五门课_序列模型
目录
第一周 循环序列模型
在进行语音识别时,给定一个输入音频片段X,并要求输出对应的文字记录Y,这个例子中输入和输出数据就是序列模型。
音乐生产问题也是使用序列数据的一个例子。
在自然语言处理中,首先需要决定怎样表示一个序列里单独的单词,解决办法式创建一个词典。然后每个单词的序列表示可以使用该词典长度的一维数组来表示,匹配的位置数据为1,其它位置数据为0。
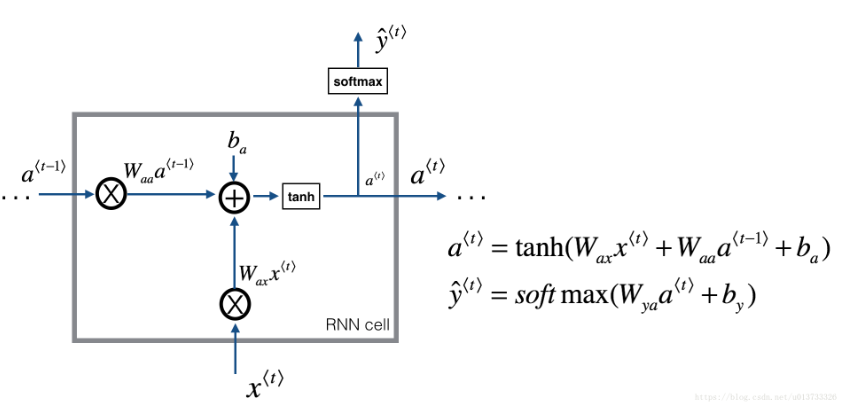
下面看一个循环神经网络模型:

RNN反向传播示意图:

如何构建一个语言模型呢?
首先需要一个训练集,包含一个很大的英文文本语料(corpus)或者其它的语言,你想用于构建模型的语言的语料库。语料库是自然语言处理的一个专有名词,意思就是很长的或者说数量众多的英文句子组成的文本。
下图是一个RNN构建序列的概率模型:

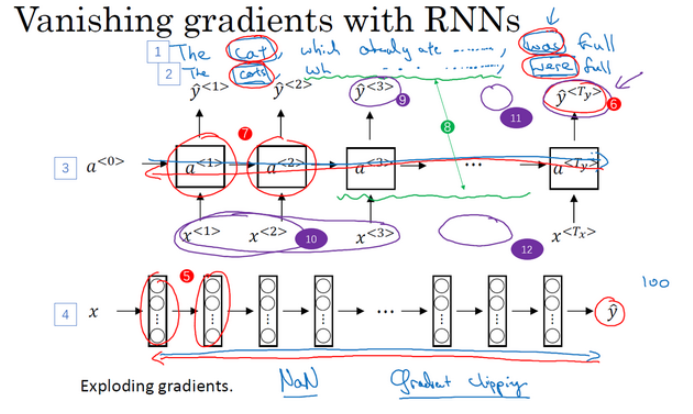
RNN的梯度消失:
GRU单元:
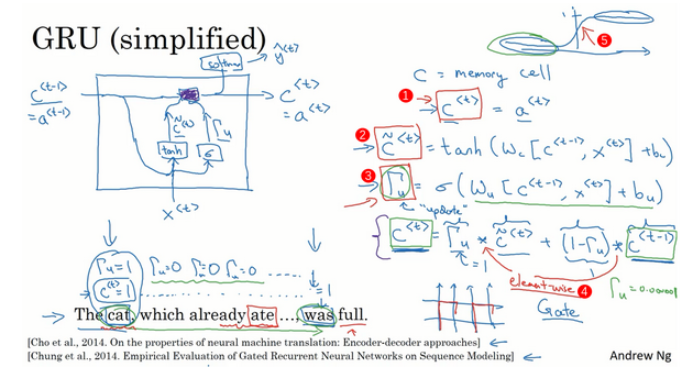
LSTM主要公式:

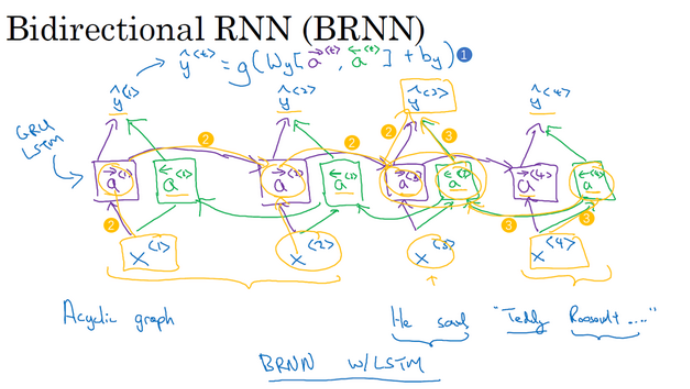
双向RNN:
深层循环神经网络(Deep RNNs)

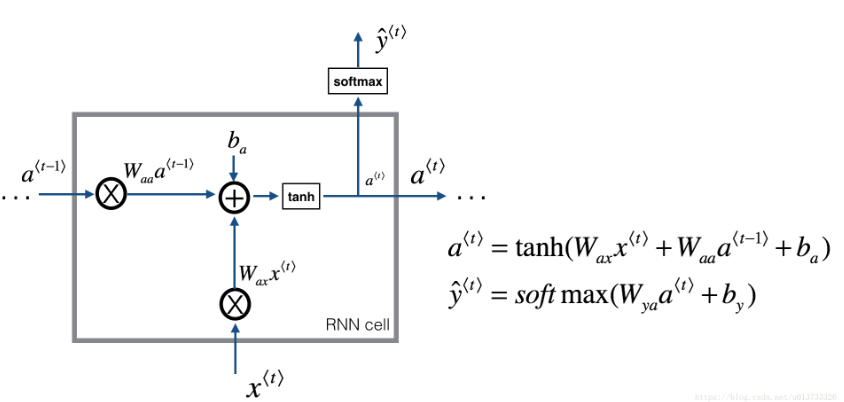
下面看一下RNN单元:
LSTM模型可以更好地解决梯度消失问题,能够更好地记住一条信息,并且可以在很多时间步中保存。
下面看下LSTM模块:
第二周 自然语言处理与词嵌入
在对单词进行向量化表示的时候,可以对其特征进行标志学习,例如学习apple的相关特性后,可以依据orange与apple的相似程度,推断出orange也会有相关的特性。一般可以定义一个多维的特征向量,每一维表示一个特性判断。
使用词潜入,能够有效解决一些同类型词特性识别问题,其中该词在训练集中出现较少或者就没有出现过。 当你的任务的训练集相对较小时,词嵌入的作用最明显,所以它广泛用于NLP领域。
词嵌入的特性
如果你学习一些词嵌入,通过算法来找到使得相似度最大化的单词w,你确实可以得到完全正确的答案。例如,man和women的差值,求出king对应的差值单词,比较理想的单词是queen。
词嵌入的一个显著成果就是,可学习的类比关系的一般性。举个例子,它能学会man对于woman相当于boy对于girl,因为man和woman之间和king和queen之间,还有boy和girl之间的向量差在gender(性别)这一维都是一样的。
如何建立神经网络来预测序列中的下一个单词?如下图模型

CBOW是从原始语句推测目标字词;而Skip-Gram正好相反,是从目标字词推测出原始语句。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。 (下图左边为CBOW,右边为Skip-Gram)

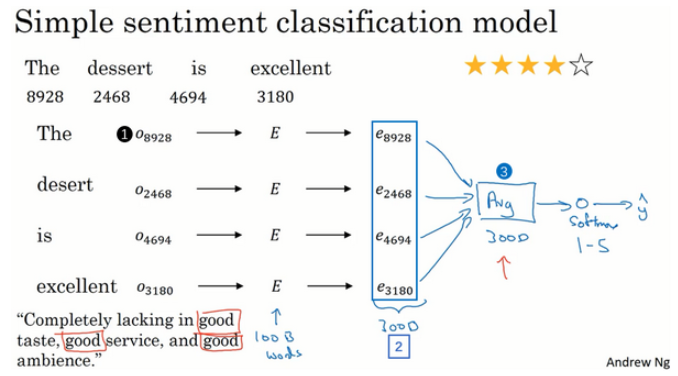
情感分类任务就是看一段文本,然后分辨这个人是否喜欢他们在讨论的这个东西,这是NLP中最重要的模块之一,经常用在许多应用中(PS:例如,从用户对某店铺的评价留言信息,分析出是正面评价还负面评价,并给出最终的打分衡量数据)。 情感分类一个最大的挑战就是可能标记的训练集没有那么多。下图是一个简单的模型:
第三周 序列模型和注意力机制
目前,深度学习技术可以借助seq2seq模型实现不同语言的互译,以及识别图片,给出图片中物体的描述。如下图,识别图中猫,给出文字描述:

集束搜索算法能够让机器翻译的记过更加贴近原意,而且语法也能够尽量规整。
长度归一化(Length normalization)是对集束搜索算法稍作调整的一种方式,帮助得到更好的结果。
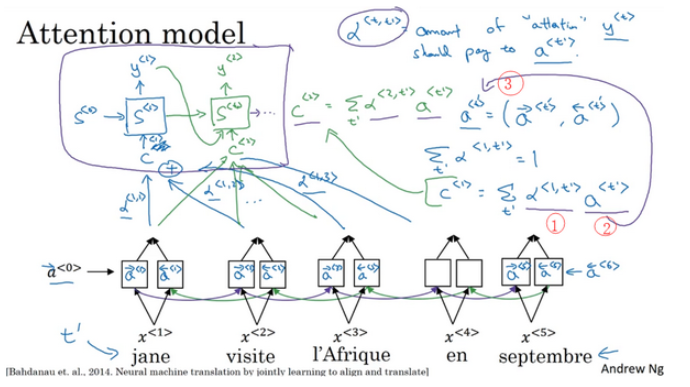
当你使用RNN读一个句子,于是另一个会输出一个句子。我们要对其做一些改变,称为注意力模型(the Attention Model),并且这会使它工作得更好。注意力模型或者说注意力这种思想(The attention algorithm, the attention idea)已经是深度学习中最重要的思想之一,下图是其运行模式:

注意力模型能够让一个神经网络只注意到一部分的输入句子,当它生成句子的时候,更像人类翻译。模型如下图:
参考资料:
1.https://blog.csdn.net/u013733326/article/details/80890454

 浙公网安备 33010602011771号
浙公网安备 33010602011771号