TensorFlow实战Google深度学习框架8-9章学习笔记
目录
第8章 循环神经网络
循环神经网络的主要用途是处理和预测序列数据。循环神经网络的来源就是为了刻画一个序列当前的输出与之前信息的关系。也就是说,循环神经网络的隐藏层之间的节点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。下面给出一个长度为2的RNN前向传播示例代码:
import numpy as np X = [1,2] state = [0.0, 0.0] w_cell_state = np.asarray([[0.1, 0.2], [0.3, 0.4]]) w_cell_input = np.asarray([0.5, 0.6]) b_cell = np.asarray([0.1, -0.1]) w_output = np.asarray([[1.0], [2.0]]) b_output = 0.1 for i in range(len(X)): before_activation = np.dot(state, w_cell_state) + X[i] * w_cell_input + b_cell state = np.tanh(before_activation) final_output = np.dot(state, w_output) + b_output print ("before activation: ", before_activation) print ("state: ", state) print ("output: ", final_output)
运行结果:
before activation: [0.6 0.5] state: [0.53704957 0.46211716] output: [1.56128388] before activation: [1.2923401 1.39225678] state: [0.85973818 0.88366641] output: [2.72707101]
循环神经网络可以很好地利用传统神经网络结构不能建模的信息,但同时,这也带来了更大的技术挑战——长期依赖问题。在这些问题中,模型仅仅需要短期内的信息来执行当前的任务。但同样也会有一些上下文场景更加复杂的情况。因此,当预测位置和相关信息之间的文本间隔变得很大时,简单的循环神经网络有可能会丧失学习到距离如此远的信息的能力。或者在复杂语言场景中,有用信息的间隔有大有小、长短不一,循环神经网络的性能也会受到限制。
长短时记忆网络(LSTM)的设计就是为了解决这个问题,在很多任务上,采用LSTM结构的循环神经网络比标准的循环神经网络表现更好。LSTM是一种拥有三个门结构的特殊网络结构,分别为输入门、遗忘门和输出门。
LSTM靠一些“门”的结构让信息有选择性地影响循环神经网络中每一个时刻的状态。所谓“门”的结构就是一个使用sigmoid神经网络和一个按位做乘法的操作,这两个操作合在一起就是一个“门”的结构。之所以该结构叫做“门”,是因为使用sigmoid作为激活函数的全连接神经网络层会输出一个0到1之间的数值,描述当前输入有多少信息量可以通过这个结构。于是这个结构的功能就类似于一扇门,当门打开时(sigmoid神经网络层输出为1时),全部信息都可以通过;当门关上时(sigmoid神经网络层输出为0时),任何信息都无法通过。
第9章 自然语言处理
假设一门语言中所有可能的句子服从某一个概率分布,每个句子出现的概率加起来为1,那么”语言模型”的任务就是预测每个句子在语言中出现的概率。很多生成自然语言文本的应用都依赖语言模型来优化输出文本的流畅性,生成的句子在语言模型中的概率越高,说明其越有可能是一个流畅、自然的句子。
那么,如何计算一个句子的概率呢?首先一个句子可以被看成是一个单词序列:
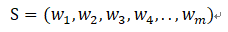
其中m为句子的长度,那么它的概率可以表示为:
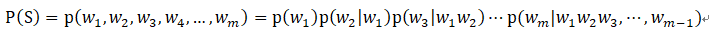
为了控制参数数量,n-gram模型做了一个有限历史假设:当前单词的出现概率仅仅于前面的n-1个单词相关,因此以上公式可以近似为:
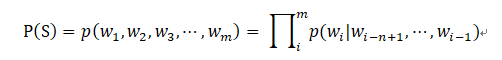
n-gram模型里的n指的是当前单词依赖它前面的单词的个数。通常n可以取1、2、3、4,其中n取1、2、3时分别称为unigram、bigram和trigram。当n越大时,n-gram模型在理论上越准确,但也越复杂,需要的计算量和训练语料数据量也就越大,因此n取大于等于4的情况非常少。
n-gram模型的参数一般采用最大似然估计(Maximum Likelihood Estimation, MLE)方法计算:
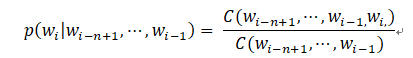
语言模型效果好坏的常用评价指标是复杂度(perplexity),在一个测试集上得到的perplexity越低,说明建模的效果越好。计算perplexity的公式如下:
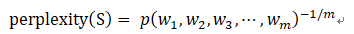
在语言模型的训练中,通常采用perplexity的对数表达形式:
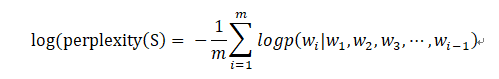
在预测下个单词时,n-gram模型只能考虑前n个单词的信息,这就对语言模型的能力造成了很大的限制。与之相比,循环神经网络可以将任意长度的上文信息存储在隐藏状态中,因此使用循环神经网络作为语言模型有着天然的优势。
基于循环神经网络的神经语言模型相比于正常的循环神经网络,在NLP的应用中主要多了两层:词向量层(embedding)和softmax层。
在输入层,每一个单词用一个实数向量表示,这个向量被称为“词向量”(word embedding)。词向量可以形象地理解为将词汇表嵌入到一个固定维度的实数空间里。将单词编号转化为词向量主要有两大作用:降低输入的维度和增加语义信息。
Softmax层的作用是将循环神经网络大的输出转化为一个单词表中每个单词的输出概率。
Seq2Seq模型的基本思想非常简单——使用一个循环神经网络读取输入句子,将整个句子的信息压缩到一个固定维度的编码中;再使用另一个循环神经网络读取输入句子,将整个句子的信息压缩到一个固定维度的编码中;再使另一个循环神经网络读取这个编码,将其“解压”为目标语言的一个句子。这两个循环神经网络分别称为编码器(Encoder)和解码器(Decoder),这个模型也称为encoder-decoder模型。
在Seq2Seq模型中,编码器将完整的输入句子压缩到一个维度固定的向量中,然后解码器根据这个向量生成输出句子。当输入句子较长时,这个中间向量难以存储足够的信息,就成为这个模型的一个瓶颈。注意力(“Attention”)机制就是为了解决这个问题而设计的。注意力机制允许解码器随时查阅输入句子的部分单词或片段,因此不需要在中间向量中存储所有信息。
解码器在解码的每一步将隐藏状态作为查询的输入来“查询”编码器的隐藏状态,在每个输入的位置计算一个反映与查询输入相关程度的权重,再根据这个权重对输入位置的隐藏状态求加权平均。加权平均后得到的向量称为“context”,表示它时与翻译当前单词最相关的原文信息。在解码下一个单词时,将context作为额外信息输入到循环神经网络中,这样循环神经网络可以时刻读取原文中最相关的信息,而不必完全依赖于上一时刻的隐藏状态。计算j时刻的context的方法如下:
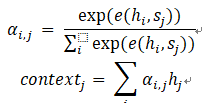
其中 是计算原文各单词与当前解码器状态的“相关度”的函数。最常用的 函数定义是一个带有单个隐藏层的前馈神经网络:
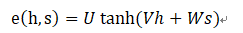

 浙公网安备 33010602011771号
浙公网安备 33010602011771号