python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐
前言
大家好,我是“持之以恒_liu”,之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何。接下来,就讲一讲今天的正题了,运用python爬虫爬取网易云音乐,之前小编尝试了爬取QQ音乐、酷狗音乐、酷我音乐,但是觉得爬取网易云音乐是最难的一个。为什么这样讲呢?除了它是post请求之外,就是它的加密了。原本小编早就打算尝试爬取它了,但是苦于对浏览器断点操作一直不知怎么做,现在知道了,并且成功实现爬取网易云音乐。
小编在这里提醒读者一下, 文明爬虫
即:1.不要在网址用户使用高的时段运行本程序,以免影响网址的正常运行;
2.本程序代码仅供学习,且莫用于商业活动,一经被相关人员发现,本小编概不负责!希望读者牢记!

1.了解网易云音乐的加密
小编通过多次尝试,个人觉得网易云音乐的加密原理是这样的。我们需要爬取的那个网址是post,而post请求需要请求参数,网易云音乐是先将请求参数进行加密,然后再发起请求(防止反爬),这样看起来的请求数据也就是读者看不懂的那一大串字符串。

既然它加密请求,我们也可以模拟加密操作呀!不过需要知道开始的请求参数和加密算法,如果这两样都知道,那么其实爬取这个网址也没有大家想象的那么难了。

2.找到发起请求的初始参数
那么怎样找到初始请求参数呢?小编以下举例
一开始搜索一首歌曲
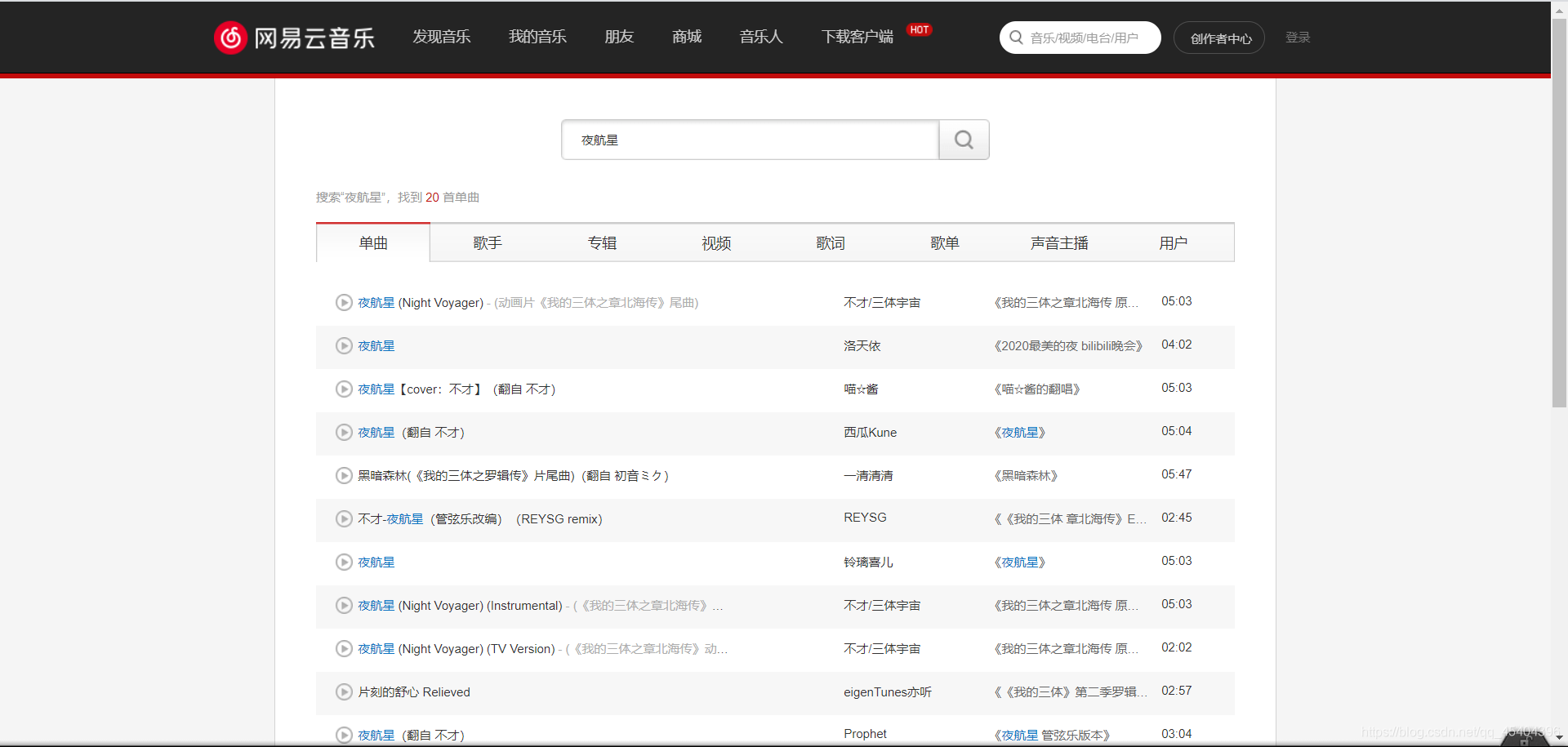
可以发现这个是动态网址,直接根据这个网址根本无法得到这些歌曲名称和歌曲id哈!按电脑键盘的F12键或者鼠标点击右键,来到浏览器的开发者模式。
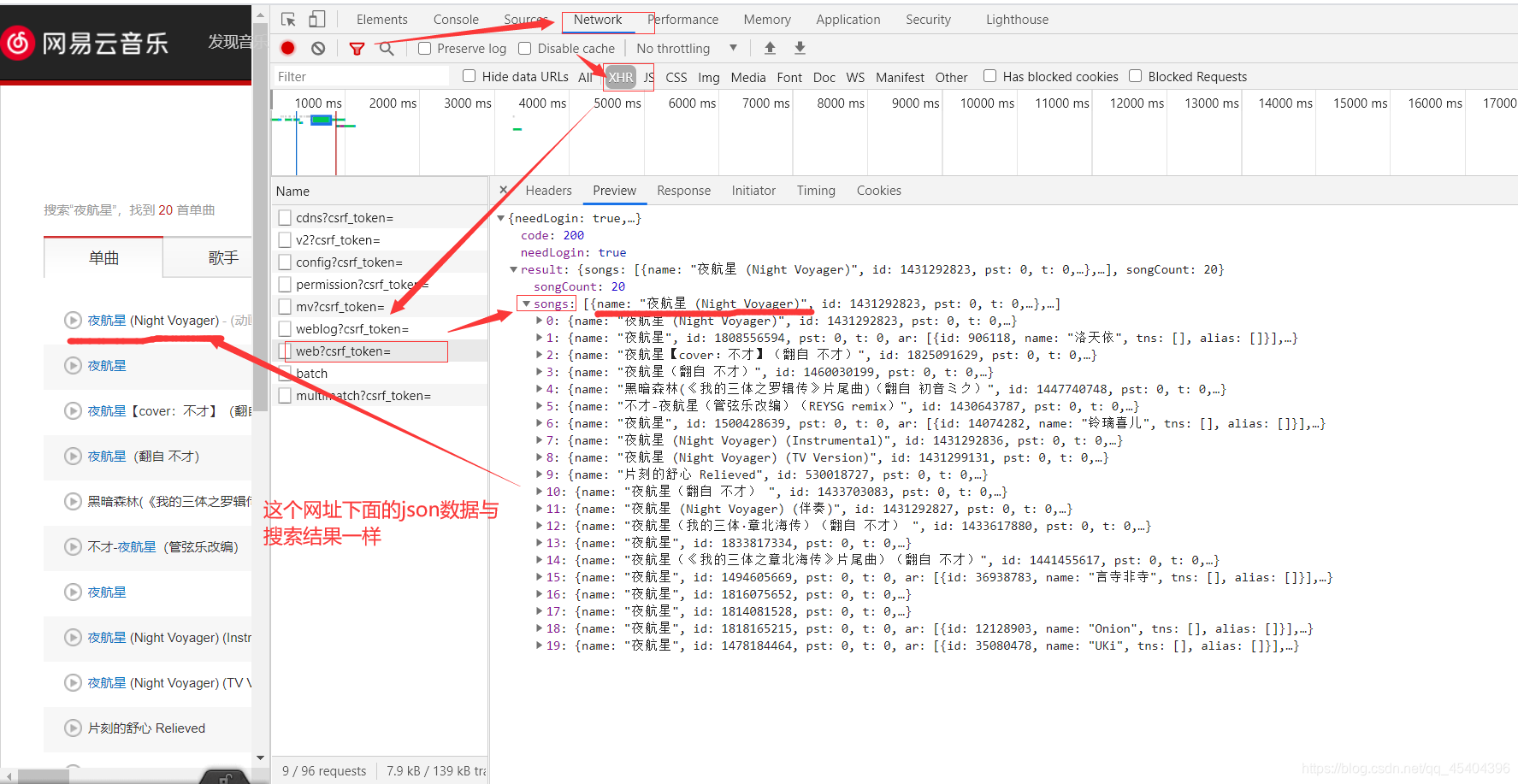
来到以上界面,可以发现这个网址为:https://music.163.com/weapi/cloudsearch/get/web?csrf_token= ,这个网址下面就是这些歌曲的名称和id,由于这是一个post请求,并且请求参数也是进行了加密,怎样获得初始请求参数呢?
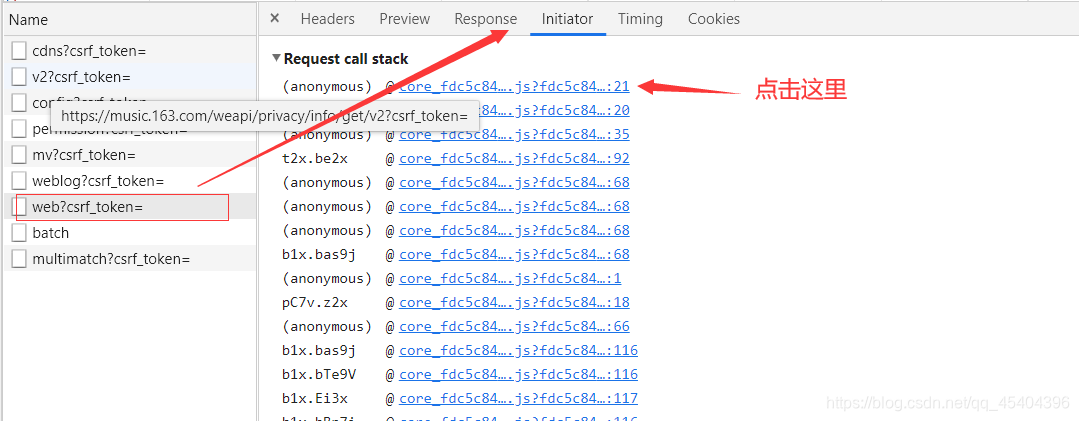
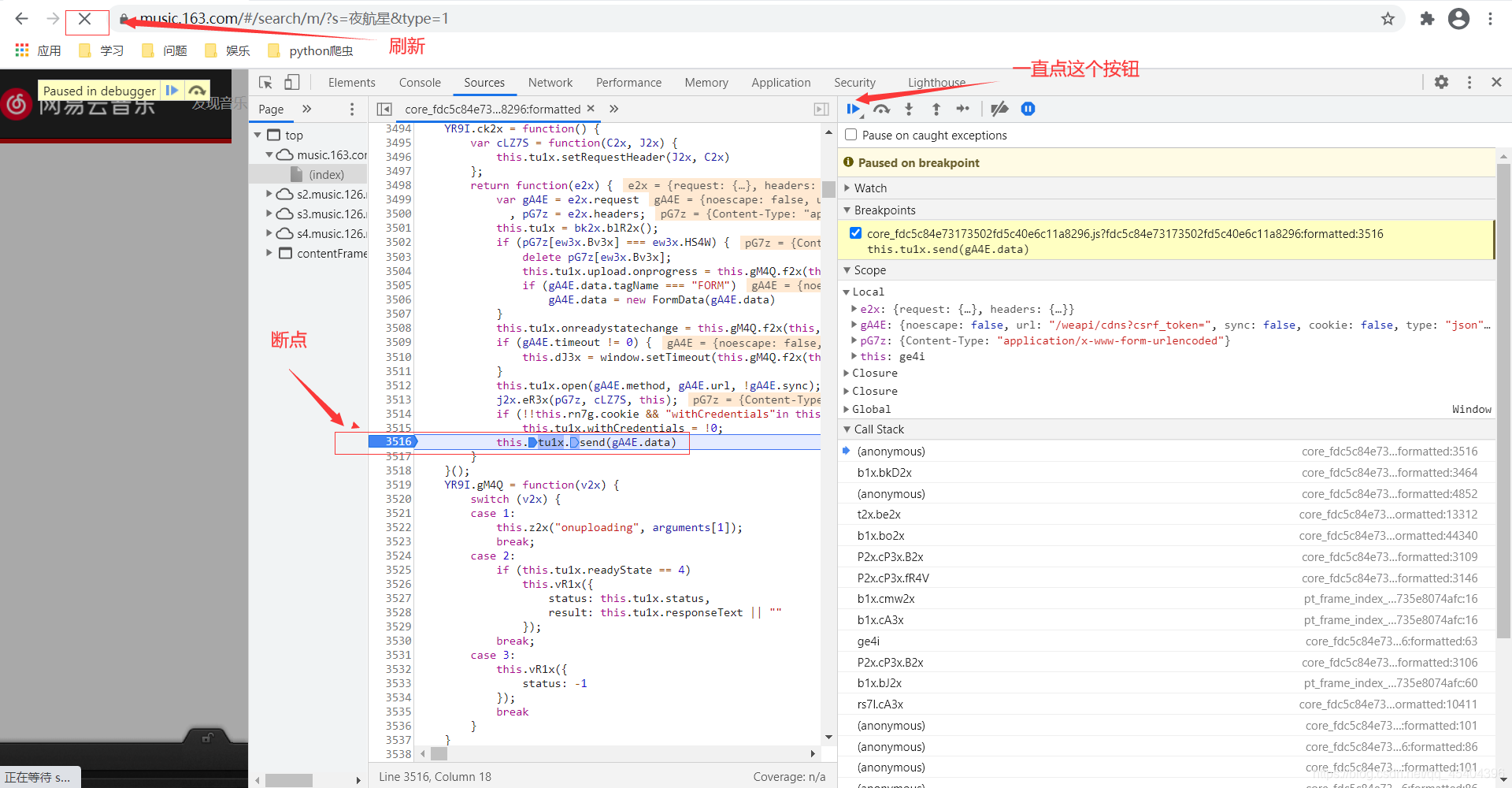
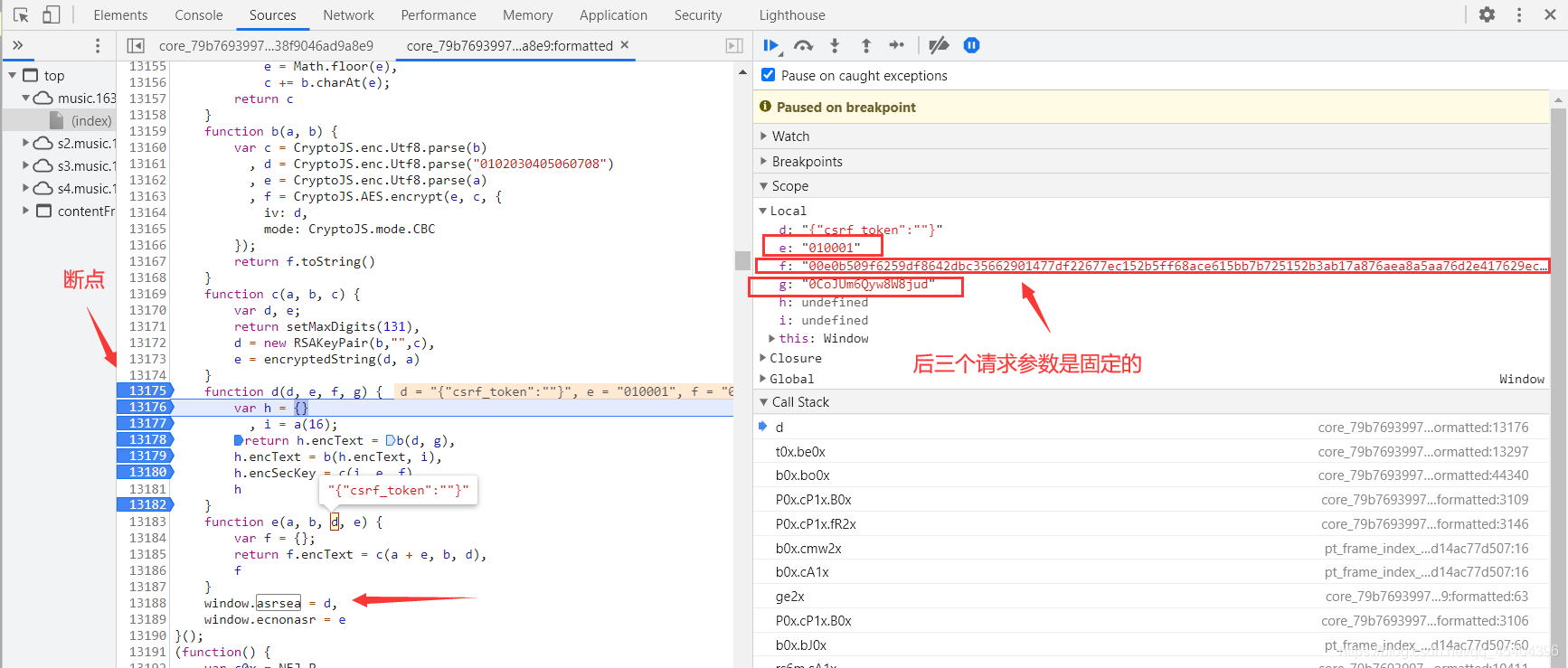
我们可以进行如上操作,首先断点,然后刷新,查看Scope这个下面是否出现小编上面提到的那个网址。没有出现的话,一直点小编图上标的那个符号,直到出现那个网址为止。
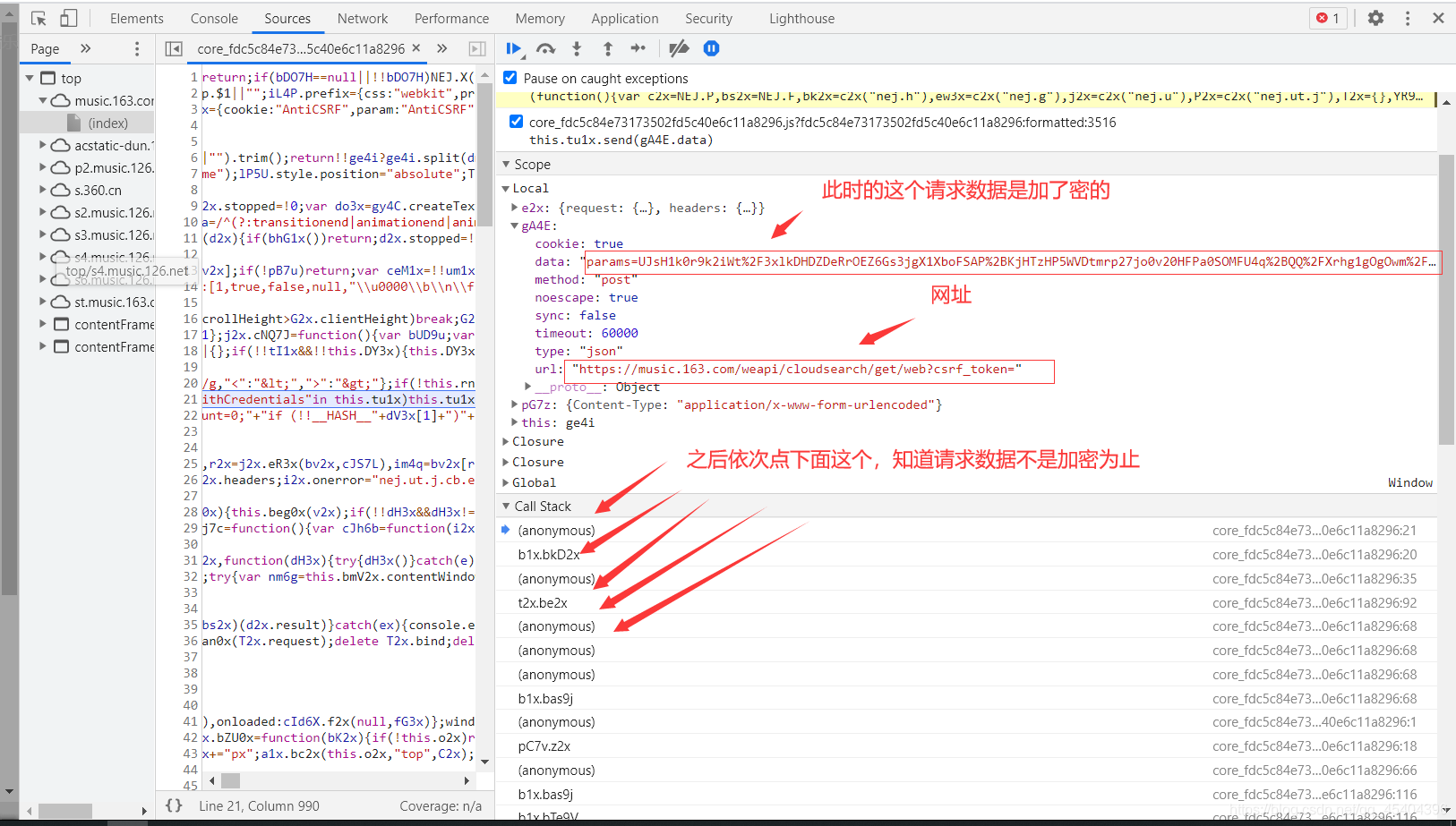
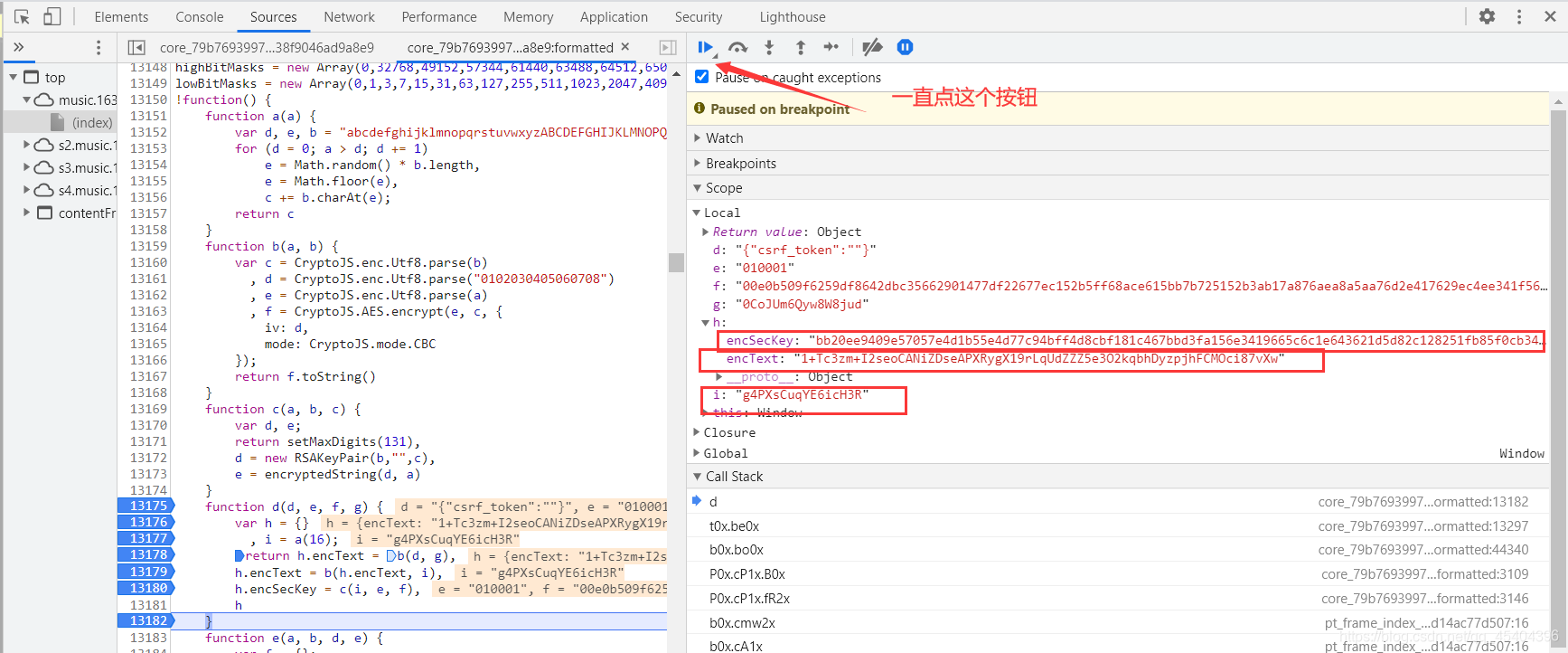
可以发现,此时这张图片上有上面的那个网址,但是那个请求参数是加了密的,之后一直点Call Stack下面的内容,直到请求参数出现没有加密时为止,此时的请求参数就是开始没有进行加密的那个参数了(小编推测)。
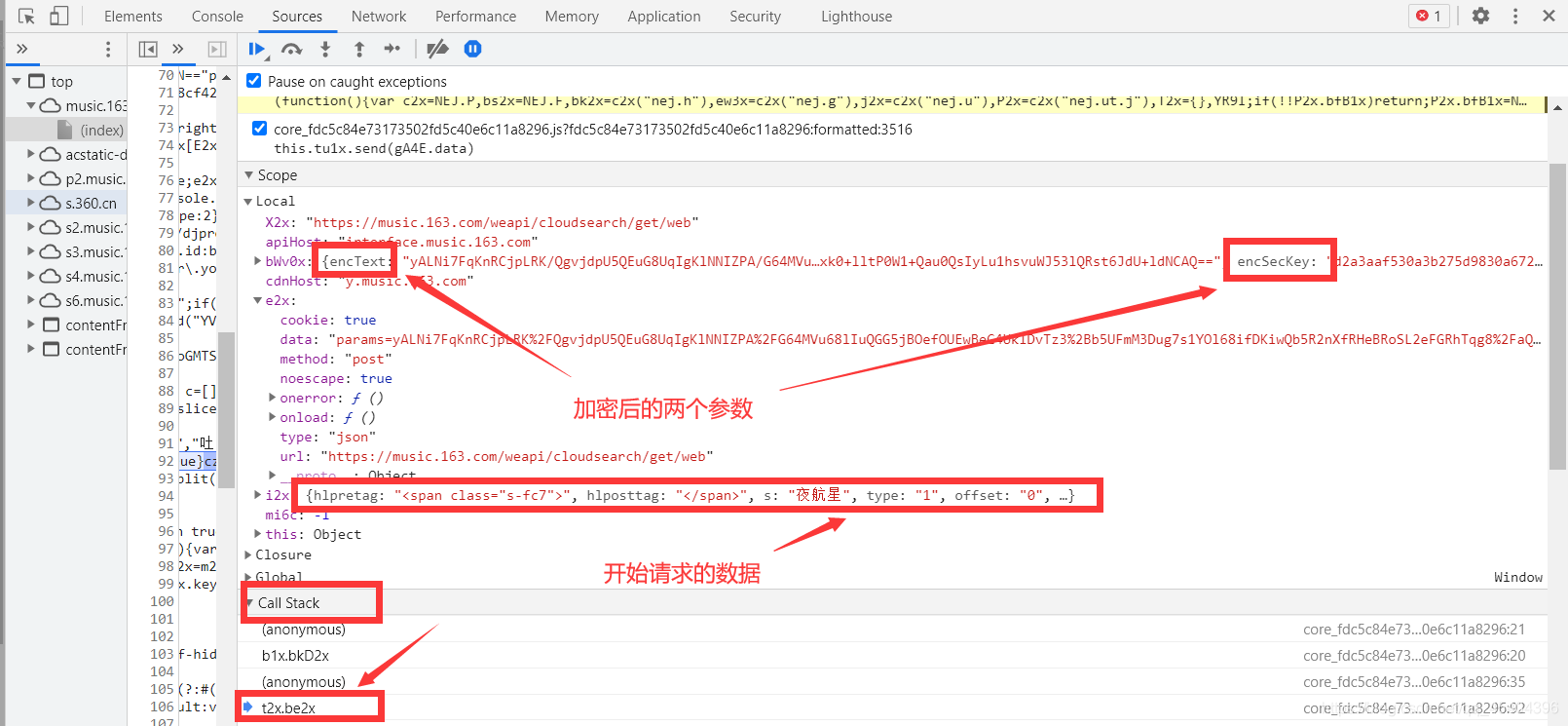
我们把图上的小编标明的那两个加了密的参数发起请求一下,
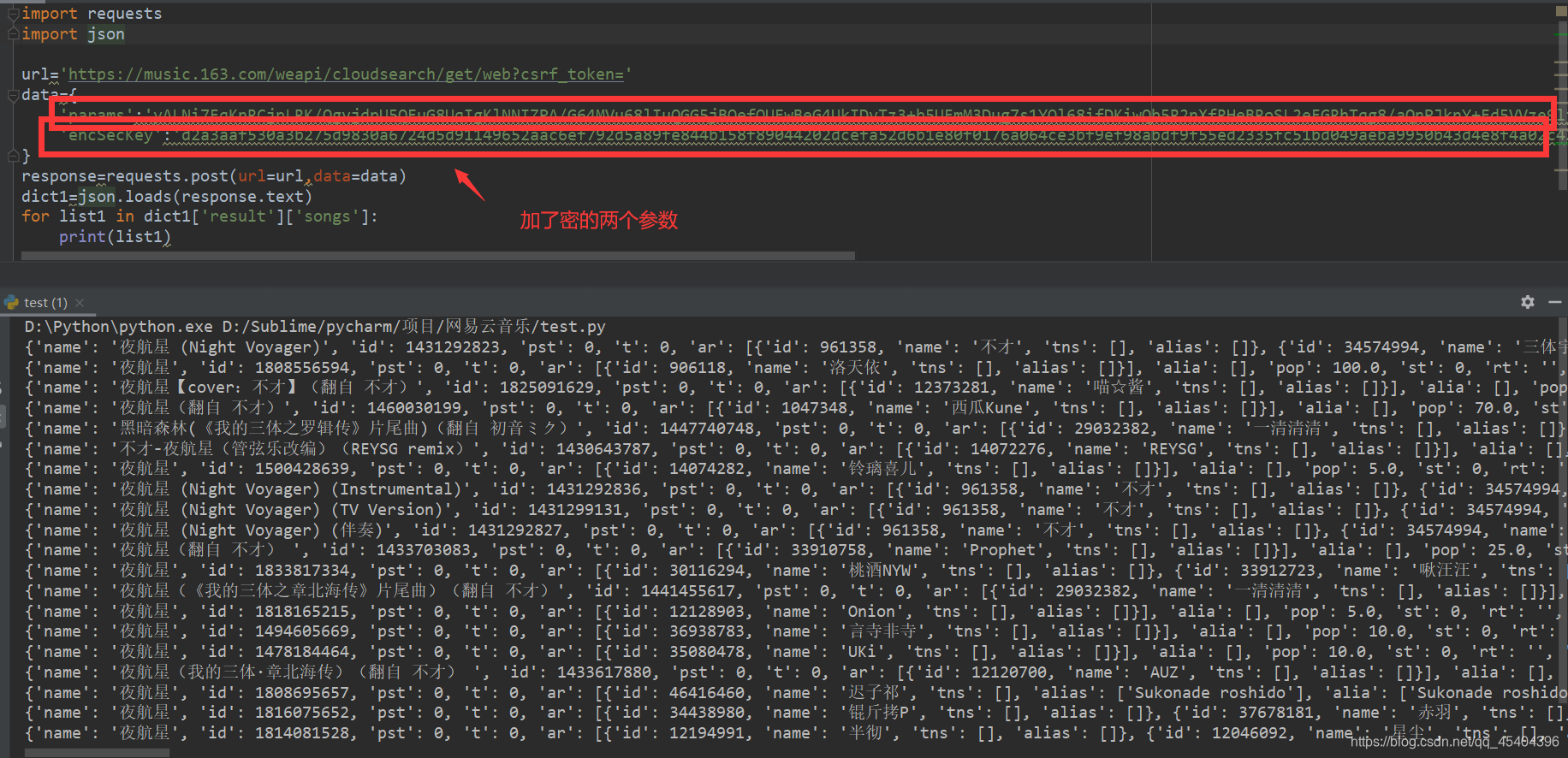
可以得到请求数据了,现在开始请求的参数有了,具体为
{"hlpretag": "<span class="s-fc7">", "hlposttag": "", "s": 歌曲名, "type": "1", "offset": "0",
"total": "true", "limit": "30", "csrf_token": ""}
3.了解加密算法
那么它的加密算法是怎样的呢?
我们在刚才的那个JS代码里面搜索 params 这个参数
可以发现这里有请求参数的两个key值
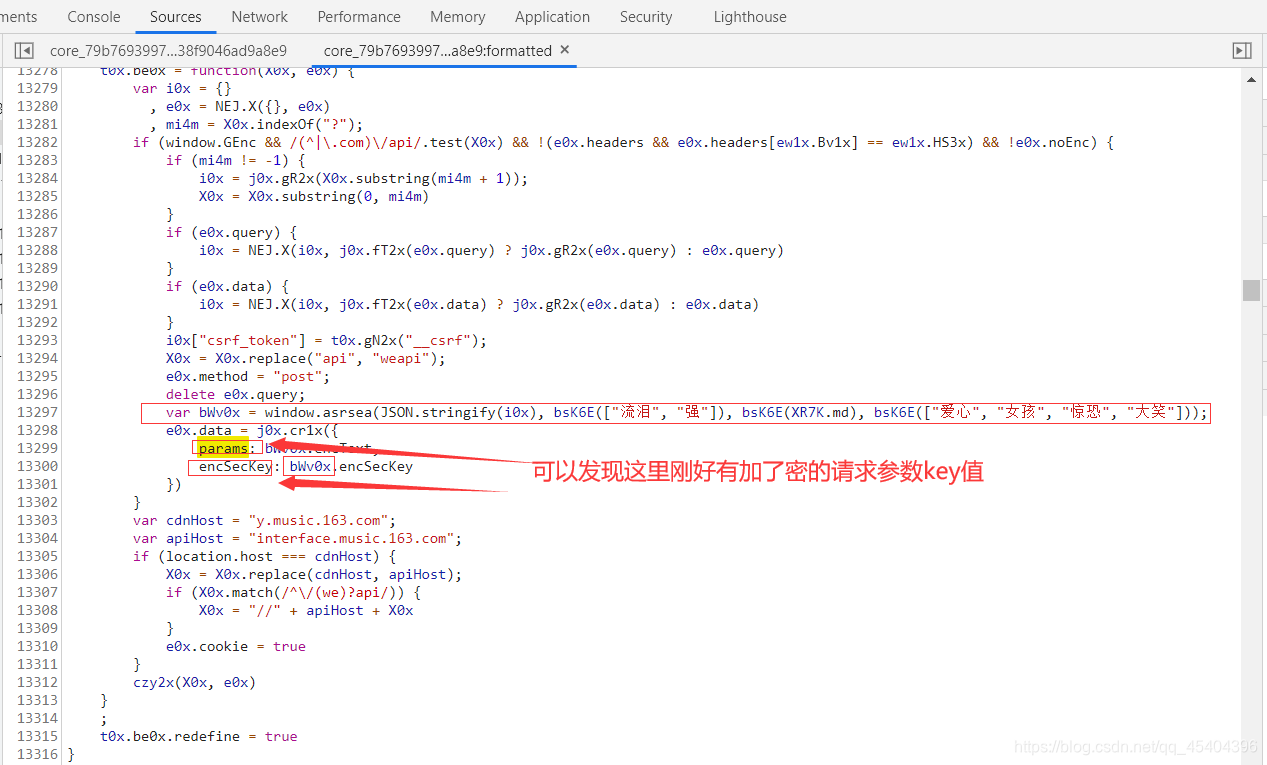
它们俩的值分别为 bWv0x.encText,bWv0x.encSecKey,
而
bWv0x = window.asrsea(JSON.stringify(i0x), bsK6E(["流泪", "强"]), bsK6E(XR7K.md), bsK6E(["爱心", "女孩", "惊恐", "大笑"]));
这个window.asrsea()是一个函数,里面四个是参数,bsK6E()也是一个函数,但是里面的参数都是固定的。


而bsK6E()就是返回输入的字符串数组中字符串(key)对应的value值,比如bsK6E(["流泪", "强"])="010001"

我们ctrl+F查找asrsea这个函数的定义,可以发现在如下这里
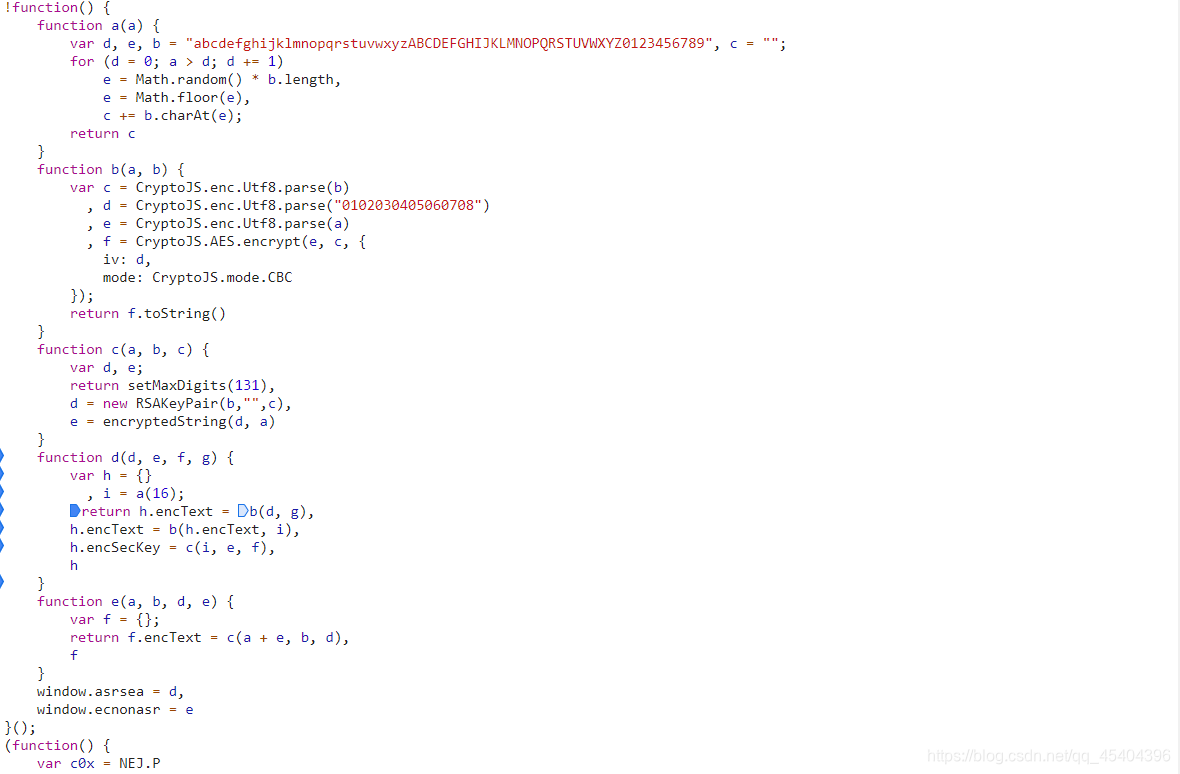
通过分析上面的a、b、c、d函数,可以发现a函数其实就是取随机长度的字符串,b函数小编有点看不懂,猜想应该是加密操作吧!c函数小编看不懂是什么操作,但是小编觉得如果传进去的三个参数如果是固定的,那么它的返回值应该也是固定的,而encSecKey的值等于它的返回值,也就是说encSecKey可以是固定的。而i值是随机生成的,那么怎样才能把它取为固定的呢?其实就是取它的一个返回值即可,让它代表所有。之后看b函数,小编的确看不懂,于是百度了一下。

发现如果要用python代码实现同样的效果也是可以的,但是需要下载一个包,具体在cmd
上输入 pip install pycryptodome
即可,具体加密算法读者可以看看这位博主这篇文章:python—AES加密
小编改了一下,
def to_16(data):
len1=16-len(data)%16
data+=chr(len1)*len1
return data
def encryption(data,key):
iv = '0102030405060708'
aes = AES.new(key=key.encode('utf-8'),IV=iv.encode('utf-8'),mode=AES.MODE_CBC)
data1 = to_16(data)
bs=aes.encrypt(data1.encode('utf-8'))
return str(b64encode(bs),'utf-8')
def get_enc(data):
param4 = '0CoJUm6Qyw8W8jud'
#enc='NA5SxhePf6dxIxX7'
#enc='GLvjERPvSFUw6EVQ'
enc='g4PXsCuqYE6icH3R'
first=encryption(data,param4)
return encryption(first,enc)
代码里面enc值就是我上面说的i值,上面讲的b函数就是里面的encryption函数。
这样我们就可以显示上述运行同样的结果了。
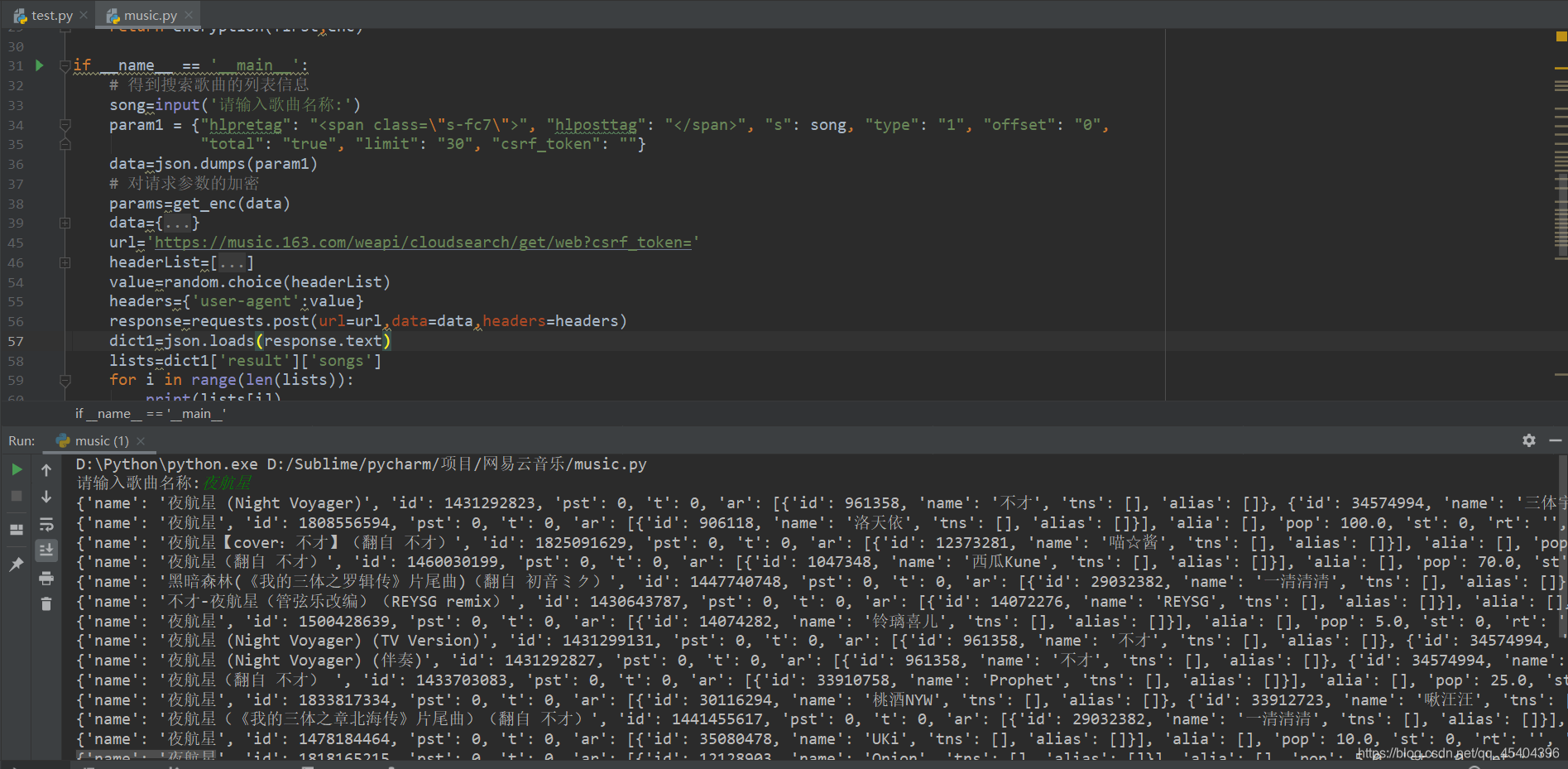
这里小编只需得到一首歌曲的id即可,为后续做准备。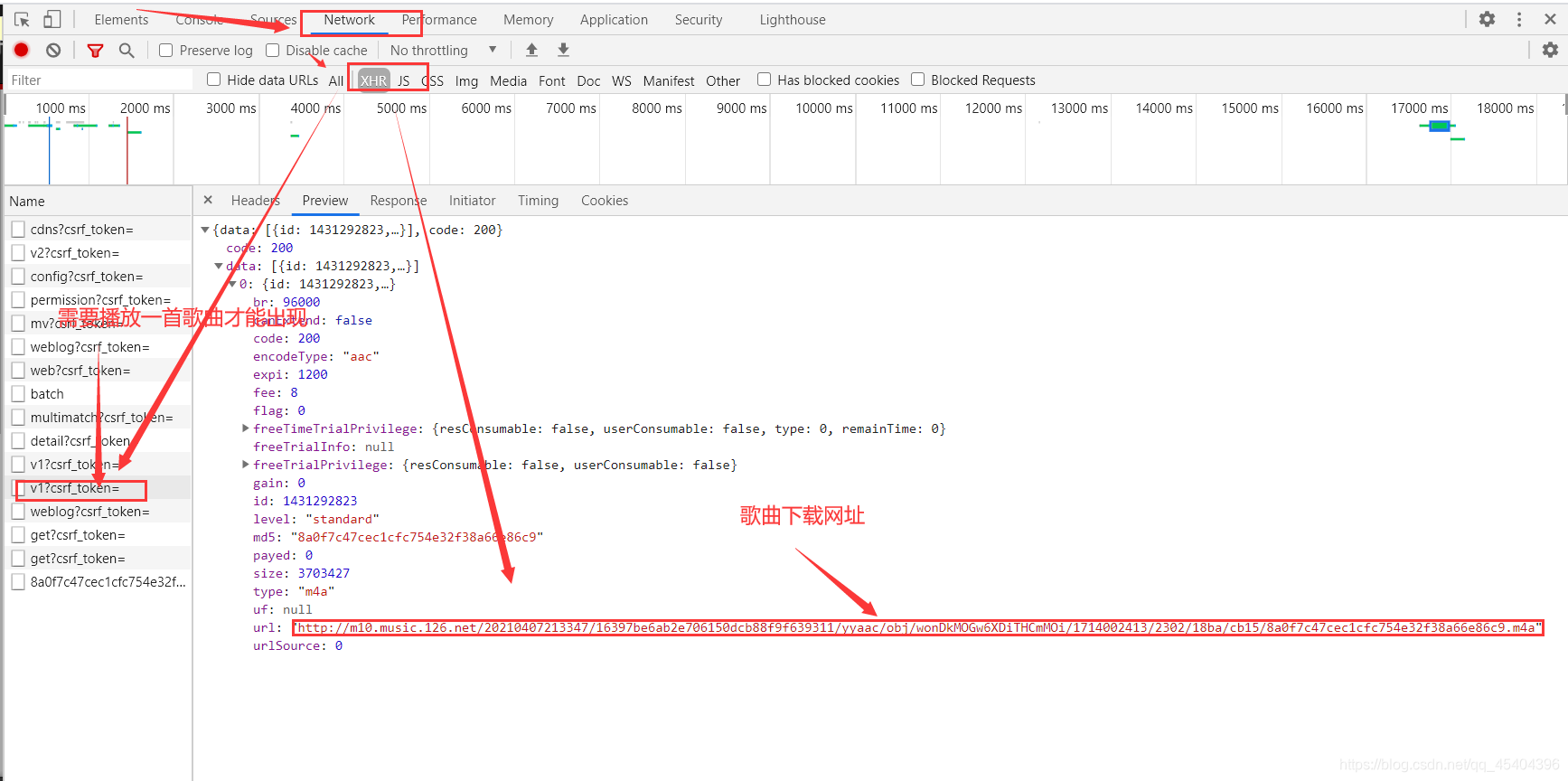
可以发现歌曲下载网址就是上面小编标的那个,它是post请求,并且请求参数也是加了密的,同样我们也需要得到它的原始请求参数值,操作和上述一样,这里小编就不一一讲述了,反正这个比较麻烦,小编花费很多时间,终于得到了它的初始请求参数为:
{"ids": "[歌曲id]".format(song_id), "level": "standard", "encodeType": "aac", "csrf_token": ""}
加密算法和上述一样的。
4.实现爬取代码
from Crypto.Cipher import AES
from base64 import b64encode
import requests
import random
import json
import os
def to_16(data):
len1=16-len(data)%16
data+=chr(len1)*len1
return data
def encryption(data,key):
iv = '0102030405060708'
aes = AES.new(key=key.encode('utf-8'),IV=iv.encode('utf-8'),mode=AES.MODE_CBC)
data1 = to_16(data)
bs=aes.encrypt(data1.encode('utf-8'))
return str(b64encode(bs),'utf-8')
def get_enc(data):
param4 = '0CoJUm6Qyw8W8jud'
#enc='NA5SxhePf6dxIxX7'
#enc='GLvjERPvSFUw6EVQ'
enc='g4PXsCuqYE6icH3R'
first=encryption(data,param4)
return encryption(first,enc)
if __name__ == '__main__':
# 得到搜索歌曲的列表信息
song=input('请输入歌曲名称:')
param1 = {"hlpretag": "<span class=\"s-fc7\">", "hlposttag": "</span>", "s": song, "type": "1", "offset": "0",
"total": "true", "limit": "30", "csrf_token": ""}
data=json.dumps(param1)
# 对请求参数的加密
params=get_enc(data)
data={
'params': params,
#'encSecKey': 'c2bcf219b2d727ff351d8fc4e5cbb86b09c32055345c098b8a8faf9c1c8b2bc506623ffc2b45db3e72cf040c750848f4408147c881a494c99dc8596415ce27d7b8ff7128e41a2b987bc9b78b3f4d4e0f0f5925b9ae24d99d1923a0d0c5cae5a3ebaf83c1097cfc3fd876f77582f38b79bbd03718cc562c15877abe9628e89ff1'
#'encSecKey':'cd99d0f0c4210c9dfbd2fafec8640dae914f5d359e593338f699d98c0643dcc385a3889c89c98b3dcbe8f389aa91f47608ec236cd204adbd0236aae23125776c294f28d1753b685710e0173349e71715153e76c93a100ad682eab00033d3ebf3b5001a0046994800332cfc43445e59f28f5e874cb1dc04482d57da9cc67f6e8e'
'encSecKey':'bb20ee9409e57057e4d1b55e4d77c94bff4d8cbf181c467bbd3fa156e3419665c6c1e643621d5d82c128251fb85f0cb34d4f08c88407b4148924ffa818f59a64b3814784e7e3837bad4f6f9690cb2cf721d9ea1af12c16a32a9df00be710b70ee8ed32036cc6a465b28ef43f4382cbcb4595b3121be75ecba9171876b611b8fc'
}
url='https://music.163.com/weapi/cloudsearch/get/web?csrf_token='
headerList=[ # user-agent列表,用于构造随机取值
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'
]
value=random.choice(headerList)
headers={'user-agent':value}
response=requests.post(url=url,data=data,headers=headers)
dict1=json.loads(response.text)
lists=dict1['result']['songs']
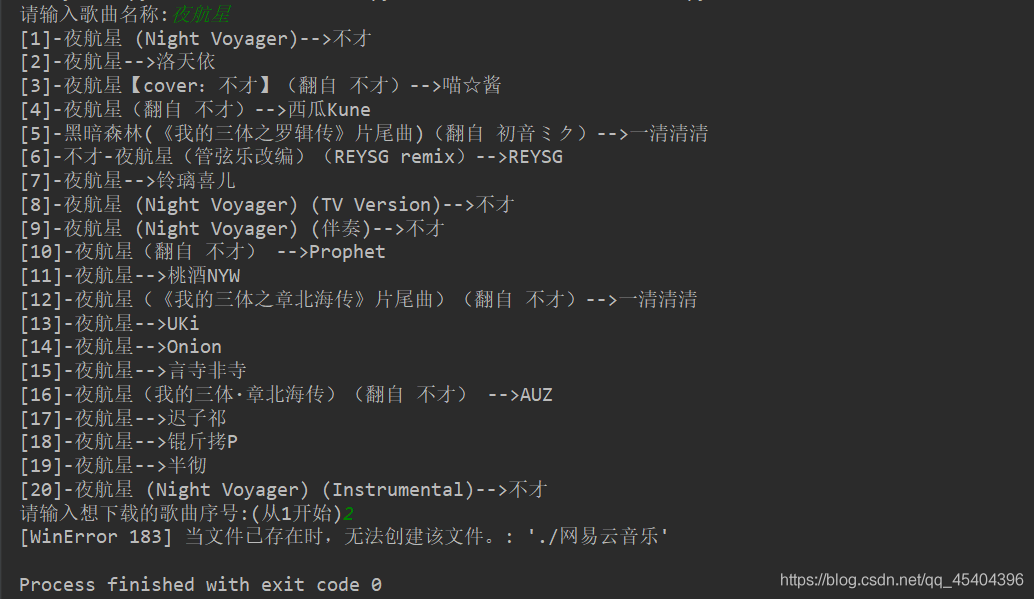
for i in range(len(lists)):
print('[{}]-{}-->{}'.format(i+1,lists[i]['name'],lists[i]['ar'][0]['name']))
id=int(input('请输入想下载的歌曲序号:(从1开始)'))
song_id=lists[id-1]['id']
song_name=lists[id-1]['name']+"_"+lists[id-1]['ar'][0]['name'] # 歌曲名称
# 下面代码为下载歌曲的代码
url2='https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token='
param2= {"ids": "[{}]".format(song_id), "level": "standard", "encodeType": "aac", "csrf_token": ""} # post请求的参数
data2=json.dumps(param2)
params=get_enc(data2)
data['params']=params
headers['user-agent']=random.choice(headerList)
response2=requests.post(url=url2,data=data,headers=headers)
dict2=json.loads(response2.text)
downloadUrl=dict2['data'][0]['url']
downloadDir='./网易云音乐'
try: # 自动创建文件夹
os.mkdir(downloadDir)
except Exception as e:
print(e)
# 下载歌曲代码
response3=requests.get(url=downloadUrl,headers=headers)
# 以二进制的形式写入到文件中
with open(file='{}/{}.mp3'.format(downloadDir,song_name),mode='wb') as f:
f.write(response3.content)
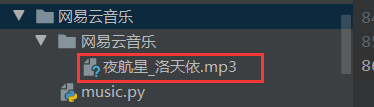
运行结果:
下载完成之后,可以发现在和运行文件的同一级目录下面多出一个网易云音乐的文件夹,下载的音乐就在这个文件夹里面。
5.总结
小编觉得或许上述有部分言语没有讲的很清晰,希望有问题的读者可以下面的评论区里进行评论,当然读者如果有兴趣的话,可以区看看小编的其他文章。
1.python自动化:实现自动回复QQ消息
2.运用Java制作一个属于自己的音乐播放软件
3.Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章
4.selenium模块太强大了,网易云音乐都可下载 这篇文章是小编运用selenium模块爬取的网易云音乐哈!
5.Python多线程爬虫教你如何快速下载表情包,告别斗图斗不赢的烦恼!
6.王者荣耀壁纸上面的英雄太酷了,为什么不把它们下载下来呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号