Python 应用爬虫下载QQ音乐
Python应用爬虫下载QQ音乐
目录:
1.简介怎样实现下载QQ音乐的过程;
2.代码
1.下载QQ音乐的过程
首先我们先来到QQ音乐的官网: https://y.qq.com/,在搜索栏上输入一首歌曲的名称;
如我在上输入最美的期待,按回车来到这个画面
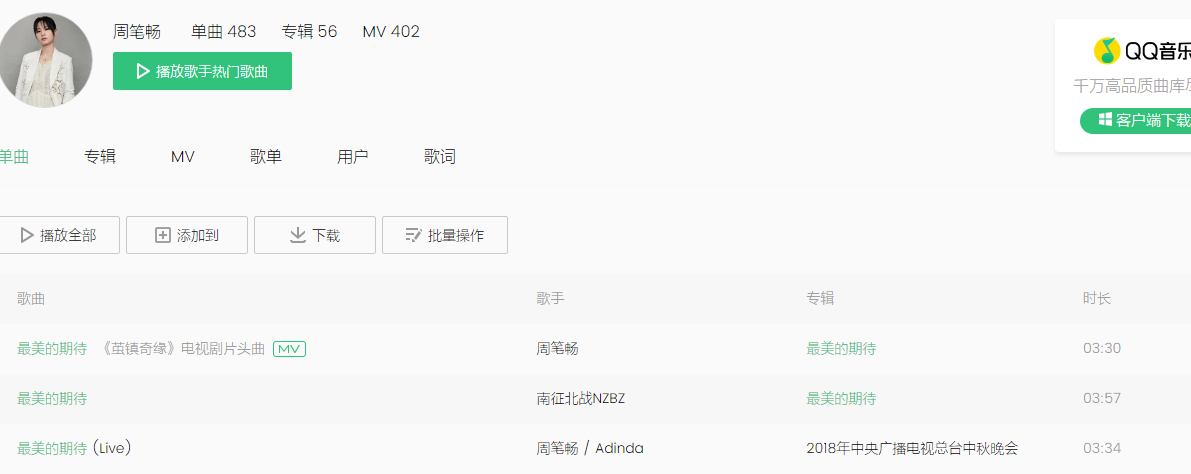
我们首先要得到这些歌曲名称和其他一些信息
鼠标右键查看源代码发现这些数据应该应用了反爬虫
鼠标右键点击检查,点击NetWork,然后点击XHR,按F5刷新,然后点击 https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=66920929169890801&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E6%9C%80%E7%BE%8E%E7%9A%84%E6%9C%9F%E5%BE%85&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0这个网址,如下图:

发现这里好像有我们需要的数据

那么这个网址要怎样才能得到呢!其实也不难发现,就下面的那个w=不同而已,对于不同歌曲。
而这个w=后面的那个数据好像就是我输入的歌曲名,最美的期待,只不过这里对于这个进行了编码罢了。
我们只要这样输入就可以了
from urllib import parse
w=parse.urlencode({'w':input('输入歌名:')})
url='https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=63229658163010696&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&%s&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'%(w)
print(url)
这样我们就得到了这个url
这样得到的数据是一个字符串,这个字符串类似‘{'key':{'key_1':1}}’,我们可以导入json模块,来处理它,这样我们得到的数据就是一个字典了。
我们点击其中的一首歌试听,来到这个界面
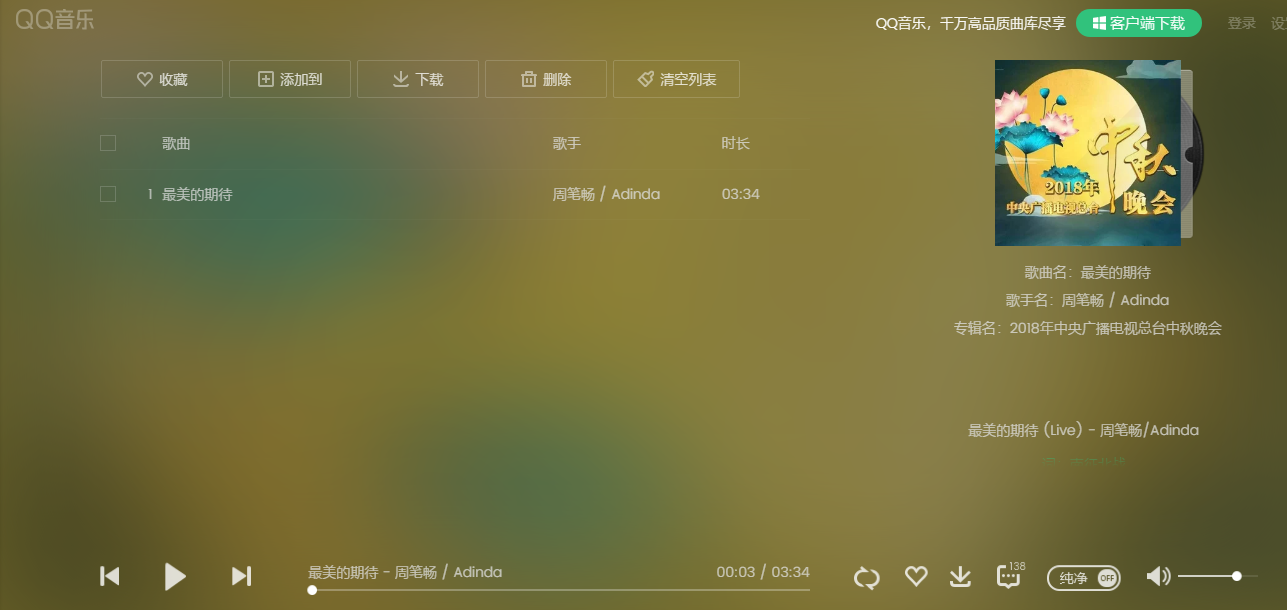
右击鼠标,点击检查,点击NetWork,点击XHR,找到下面这个网址发现
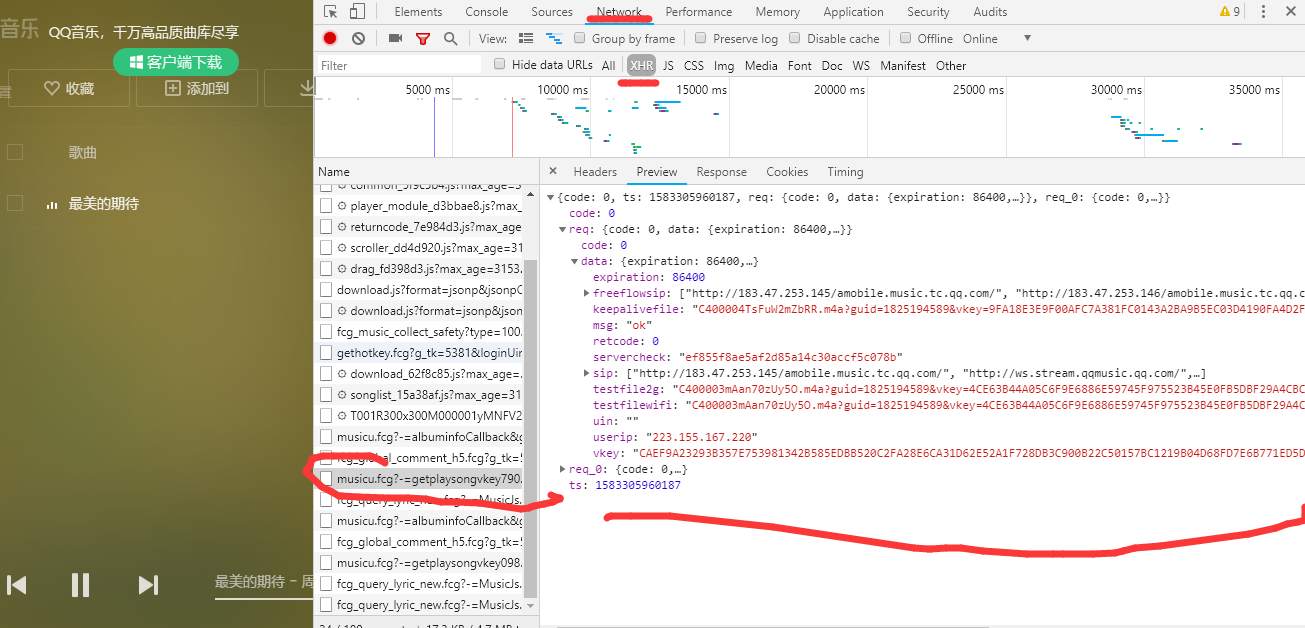
在这里我们可以发现有这首歌曲的下载地址,发现purl下面的一个参数是上面得到的那个数据中的’mid‘,只要将两者结合起来,就可以下载这首歌曲了。
代码如下:
import urllib.parse as parse from urllib.request import urlretrieve import requests import json import os import time import sys def Time_1(): # 进度条函数 for i in range(1,51): sys.stdout.write('\r') sys.stdout.write('{0}% |{1}'.format(int(i%51)*2,int(i%51)*'■')) sys.stdout.flush() time.sleep(0.125) sys.stdout.write('\n') print(''' 声明:本小程序仅供娱乐和学习,切莫用于商业用途,一经发现,概不负责! ''') w=parse.urlencode({'w':input('输入歌名:')}) url='https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=63229658163010696&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&%s&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'%(w) content=requests.get(url=url) str_1=content.text dict_1=json.loads(str_1) song_list=dict_1['data']['song']['list'] str_3='''https://u.y.qq.com/cgi-bin/musicu.fcg?-=getplaysongvkey5559460738919986&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"1825194589","calltype":0,"userip":""}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"1825194589","songmid":["%s"],"songtype":[0],"uin":"0","loginflag":1,"platform":"20"}},"comm":{"uin":0,"format":"json","ct":24,"cv":0}}''' url_list=[] music_name=[] for i in range(len(song_list)): music_name.append(song_list[i]['name']+'-'+song_list[i]['singer'][0]['name']) print('{}.{}-{}'.format(i+1,song_list[i]['name'],song_list[i]['singer'][0]['name'])) url_list.append(str_3 % (song_list[i]['mid'])) id=int(input('请输入你想下载的音乐序号:')) content_json=requests.get(url=url_list[id-1]) dict_2=json.loads(content_json.text) url_ip=dict_2['req']['data']['freeflowsip'][1] purl=dict_2['req_0']['data']['midurlinfo'][0]['purl'] downlad=url_ip+purl try: os.mkdir('./QQ音乐') except: pass finally: try: print('开始下载...') urlretrieve(url=downlad,filename='./QQ音乐/{}.mp3'.format(music_name[id-1])) Time_1() print('{}.mp3下载完成!'.format(music_name[id-1])) except Exception as e: print(e,'对不起,你没有该歌曲的版权!')
运行结果:
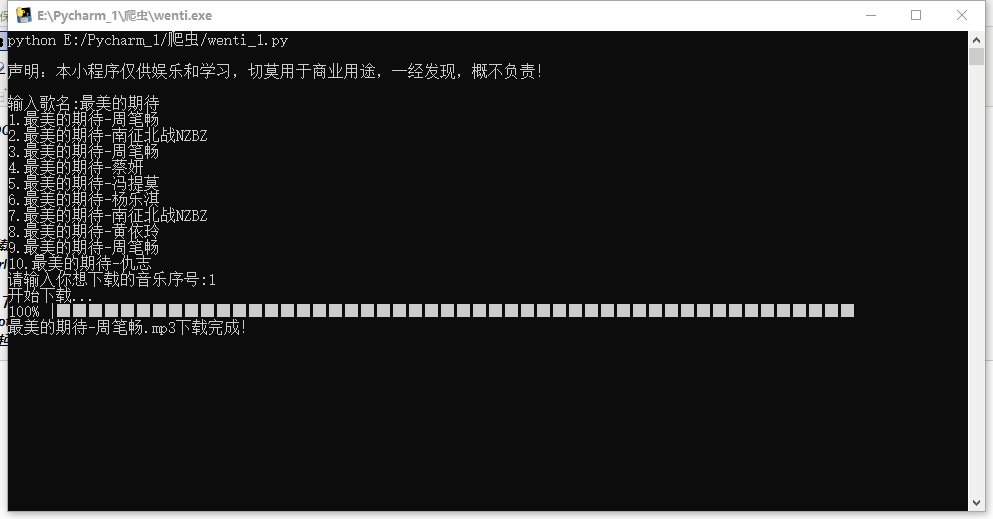
下载完成后,会在同一个文件下面多了一个QQ音乐的文件夹,所下载的歌曲就在这里面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号