
RabbitMQ
引入
什么是消息队列
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
为什么用消息队列
从上面的描述中可以看出消息队列是一种应用间的异步协作机制,那什么时候需要使用 MQ 呢?
以常见的订单系统为例,用户点击【下单】按钮之后的业务逻辑可能包括:扣减库存、生成相应单据、发红包、发短信通知。在业务发展初期这些逻辑可能放在一起同步执行,随着业务的发展订单量增长,需要提升系统服务的性能,这时可以将一些不需要立即生效的操作拆分出来异步执行,比如发放红包、发短信通知等。这种场景下就可以用 MQ ,在下单的主流程(比如扣减库存、生成相应单据)完成之后发送一条消息到 MQ 让主流程快速完结,而由另外的单独线程拉取MQ的消息(或者由 MQ 推送消息),当发现 MQ 中有发红包或发短信之类的消息时,执行相应的业务逻辑。
RabbitMQ
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。
rabbitMQ是一款基于AMQP协议的消息中间件,它能够在应用之间提供可靠的消息传输。在易用性,扩展性,高可用性上表现优秀。使用消息中间件利于应用之间的解耦,生产者(客户端)无需知道消费者(服务端)的存在。而且两端可以使用不同的语言编写,大大提供了灵活性。
Rabbit安装


1 rabbitmq 源码安装 2 3 官网地址:rabbitmq 4 http://www.rabbitmq.com/releases/rabbitmq-server/ 5 官网地址:erlang 6 http://erlang.org/download/ 7 8 一、概念: 9 Broker:简单来说就是消息队列服务器实体。 10 Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。 11 Queue:消息队列载体,每个消息都会被投入到一个或多个队列。 12 Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。 13 Routing Key:路由关键字,exchange根据这个关键字进行消息投递。 14 vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。 15 producer:消息生产者,就是投递消息的程序。 16 consumer:消息消费者,就是接受消息的程序。 17 channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。 18 19 二、安装RabbitMQ 20 CentOS: 21 1.先安装erlang 22 # PS: 注意安装操作首先要切换到root工作环节中 23 # 在命令 如果$ 表示是普通用户, 24 yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel 25 yum -y install ncurses-devel 26 yum install ncurses-devel 27 wget http://erlang.org/download/otp_src_19.3.tar.gz 28 tar -xzvf otp_src_19.3.tar.gz 29 cd otp_src_19.3 30 ./configure --prefix=/usr/local/erlang --with-ssl --enable-threads --enable-smp-support --enable-kernel-poll --enable-hipe 31 make && make install 32 配置erlang环境 33 vi /etc/profile #在最后添加下文 34 PATH=$PATH:/usr/local/erlang/bin 35 使环境变量生效 36 source /etc/profile 37 测试一下是否安装成功,在控制台输入命令erl 38 crt+z 退出 39 2.安装rabbitmq 40 41 wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.5.8/rabbitmq-server-3.5.8.tar.gz 42 tar -zxvf rabbitmq-server-3.5.8.tar.gz 43 cd abbitmq-server-3.5.8 44 make 45 make TARGET_DIR=/usr/local/rabbitmq SBIN_DIR=/usr/local/rabbitmq/sbin MAN_DIR=/usr/local/rabbitmq/man DOC_INSTALL_DIR=/usr/local/rabbitmq/doc install 46 配置erlang环境 47 vi /etc/profile #在最后添加下文 48 PATH=$PATH:/usr/local/erlang/bin:/usr/local/rabbitmq/sbin 49 使环境变量生效 50 source /etc/profile 51 3. 启动:rabbitmq-server 52 rabbitmq-server start 53 4. 检查服务启动状态 54 [root@node01 ~]# netstat -lnpt|grep beam 55 tcp 0 0 0.0.0.0:5672 0.0.0.0:* LISTEN 19733/beam 56 tcp 0 0 0.0.0.0:25672 0.0.0.0:* LISTEN 19733/beam 57 tcp 0 0 0.0.0.0:15672 0.0.0.0:* LISTEN 19733/beam 58 [root@node01 ~]# 59 # 表示启动成功 60 三、管理命令 61 启动:rabbitmq-server start 62 关闭:rabbitmqctl stop 63 状态:rabbitmqctl status 64 65 四、插件 66 启动web管理插件 67 rabbitmq-plugins enable rabbitmq_management 68 如果报错 69 错误解决: 70 Error: {cannot_write_enabled_plugins_file,"/etc/rabbitmq/enabled_plugins", enoent} 71 mkdir /etc/rabbitmq 72 重新启动输入地址:localhost:15672,帐号默认为guest,密码guest,此帐号默认只能在本机访问。不建议打开远程访问。你可以创建一个帐户,并设置可以远程访问的角色进行访问。 73 如: 74 rabbitmqctl add_user supery 123 # 创建用户supery 75 76 rabbitmqctl set_user_tags supery administrator # 给创建的supery用户administrator角色 77 78 五、用户管理 79 默认的guest帐户相当于root帐户 80 rabbitmqctl add_user username password 添加帐户 81 rabbitmqctl change_password username newpassword 修改密码 82 rabbitmqctl delete_user username 删除帐户 83 rabbitmqctl list_users 列出所有帐户 84 rabbitmqctl set_user_tags User Tag 设置角色(administrator、monitoring、policymaker、management、其它) 85 立即生效,不需重启 86 87 六、创建配置文件 88 [root@node01 ~]# ll /etc/rabbitmq/ 89 total 8 90 -rw-r--r-- 1 root root 23 Mar 5 10:07 enabled_plugins 91 -rw-r--r-- 1 root root 51 Mar 5 10:12 rabbitmq.config 92 [root@node01 ~]# cat /etc/rabbitmq/rabbitmq.config 93 [{rabbit, [{loopback_users, ["root","supery"]}]}]. 94 95 操作步骤: 96 vi /etc/rabbitmq/rabbitmq.config 97 将[{rabbit, [{loopback_users, ["root","supery"]}]}]. 复制到文件中即可 98 99 100 101 esc 102 :x 保存并退出 103 104 七、重启rabbitmq-server并测试访问 105 rabbitmqctl stop 106 rabbitmqctl start 107 浏览器访问 108 1. 查看自己的服务器ip地址 109 ifconfig 110 # inet addr:172.24.129.3 ===> 服务器ip地址 111 2. 浏览器访问 112 http://39.104.109.159:15672 ===> 输入用户密码登录即可 113 114 登录成功!完成
RabbitMQ工作模型
简单模式
# ######################### 生产者 #########################
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters( host='118.25.231.23'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='我是生产者发来的消息!')
connection.close()
# ########################## 消费者 ##########################
import pika
# 使用pika模块建立与 RabbitMQ服务器的连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='118.25.231.23'))
# 从连接中获取一个操作频道
channel = connection.channel()
# 声明一个 hello 队列
# 在生产者和消费者都进行声明的目的是:无法确定 生产者还是消费者哪个先启动,不管哪个先启动,都进行声明,后者再进行声明则不起到作用
channel.queue_declare(queue='hello')
# 从队列中取到消息要执行的回调函数
def callback(ch, method, properties, body):
print("接收到的消息为:%r" % body.decode('utf-8'))
channel.basic_consume(callback,
# 监听取消息的队列
queue='hello',
# 在接收到消息之后不对服务端发送应答信号
no_ack=True)
print('等待接收来自生产者的消息....')
# 开始接收绑定了队列中的消息
channel.start_consuming()
参数说明
(1)no-ack = False,如果消费者遇到情况(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。
- 回调函数中的
ch.basic_ack(delivery_tag=method.delivery_tag) - basic_comsume中的
no_ack=False
这样做的目的是:确保消费者从RabbitMQ服务器队列中获取到的数据已经被消费者处理完成,只有当消费者将接收来的消息处理完成之后才向服务端发送应答信号,此时服务端才会将队列中的该消息从队列删除,否则不会删除。
此时的消费者代码:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='10.211.55.4'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
# 发送响应完成信号,服务端删除队列中的该消息
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
(2) durable=True
在实际生产环境中,rabbitmq服务端难免会因为各种情况而宕机。而durable=True时,对入队的消息都会进行持久化操作。以保证在服务器重启之后能够保留宕机之前的消息队列。
# 生产者
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
channel = connection.channel()
# make message persistent
channel.queue_declare(queue='hello', durable=True)
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
print(" [x] Sent 'Hello World!'")
connection.close()
# 消费者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
channel = connection.channel()
# make message persistent
channel.queue_declare(queue='hello', durable=True)
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
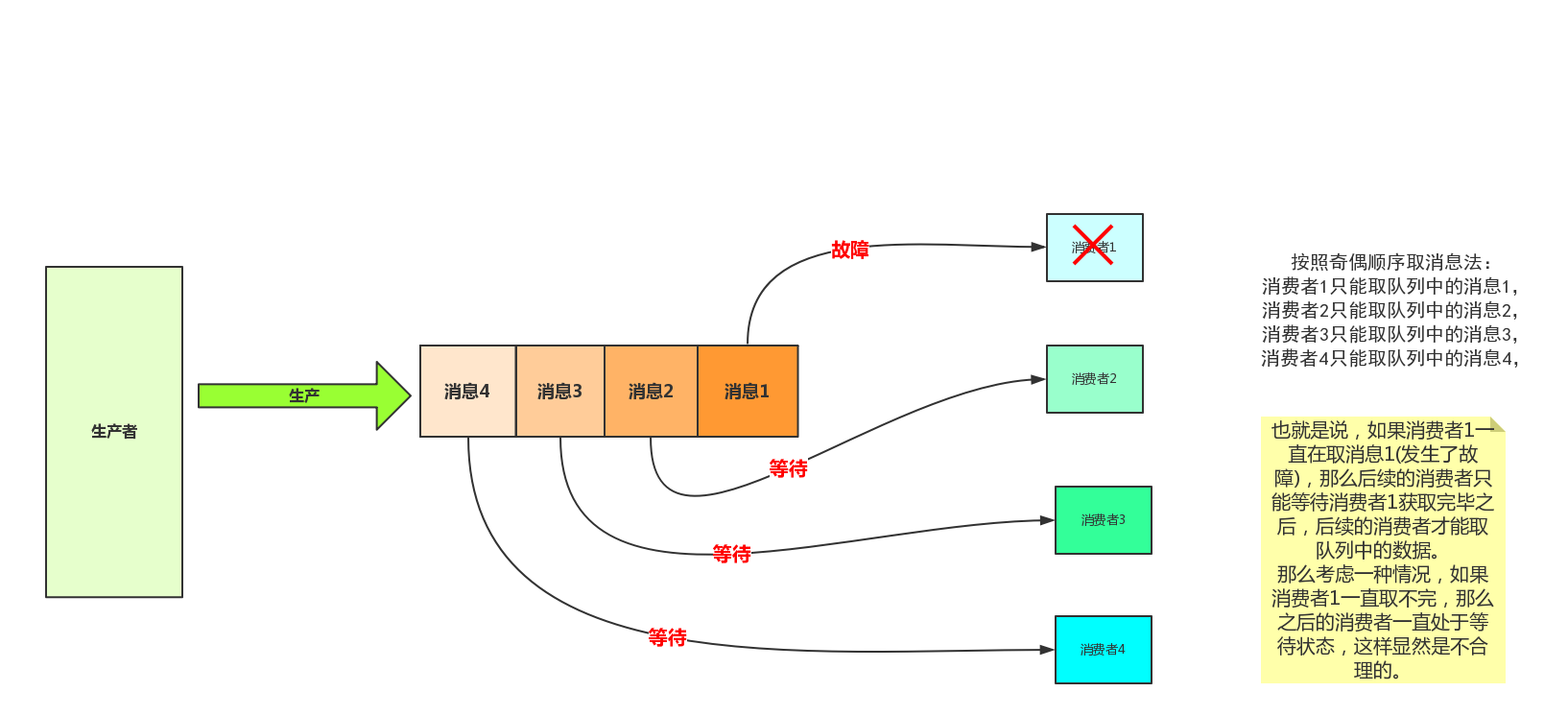
(3) 消息获取顺序
消息队列里的数据默认情况下是按照顺序被拿走,也就是说,队列中的数据与消费者形成了一一对应的关系,形成这样的关系显示是不合理的,因为一旦某个消费者发生故障,后续的消费者会被阻塞,且发生故障消费者要获取的队列数据也没有获取到。
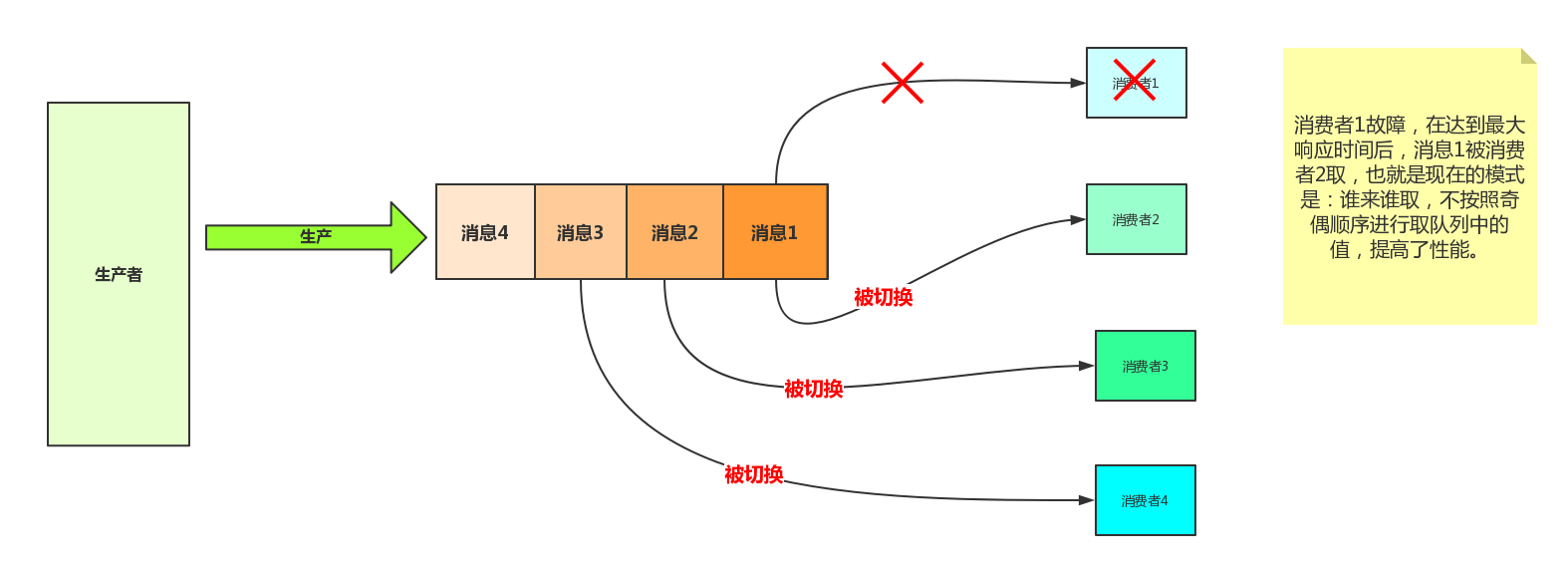
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
未设置参数之前:
 设置参数之后:
设置参数之后:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
channel = connection.channel()
# make message persistent
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
exchange模型
发布订阅
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
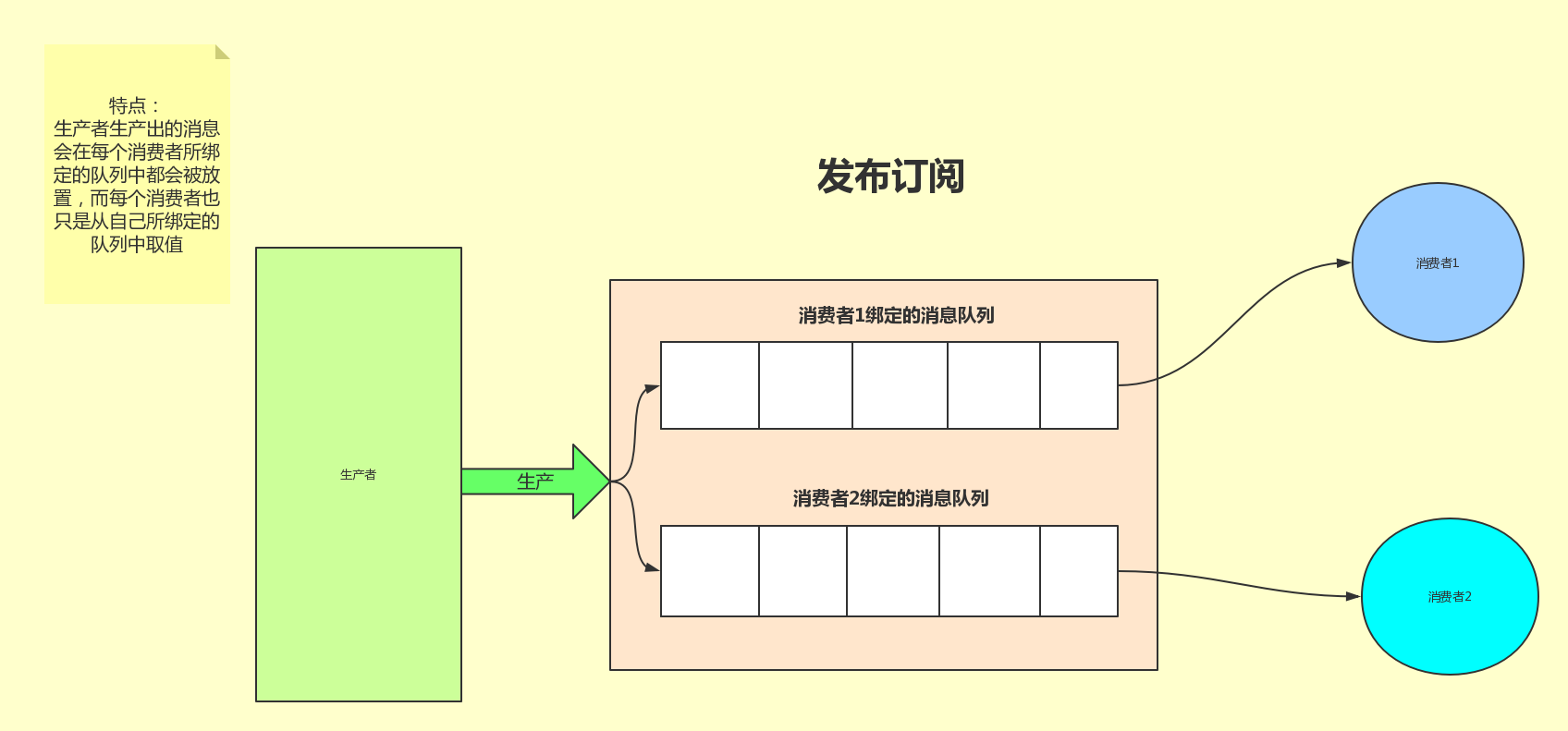
exchange type = fanout
# 生产者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
# 声明一个名为logs的交换机
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
# 定义的消息
message ="info: Hello World!"
# 差值
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()
# 消费者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
# 声明一个名为logs的交换机
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
print(queue_name)# 一个队列名称
# 将队列绑定到交换机上
channel.queue_bind(exchange='logs',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
关键字发送
对于之前的模式,生产者每生产一个消息所有的消费者都可以接收到,而关键字模式则会根据某消息队列所绑定的关键字进行接收来自生产者的消息。在该模式下,生产者将消息发送至交换机exchange,exchange根据关键字发送至指定关键字的消息队列中。
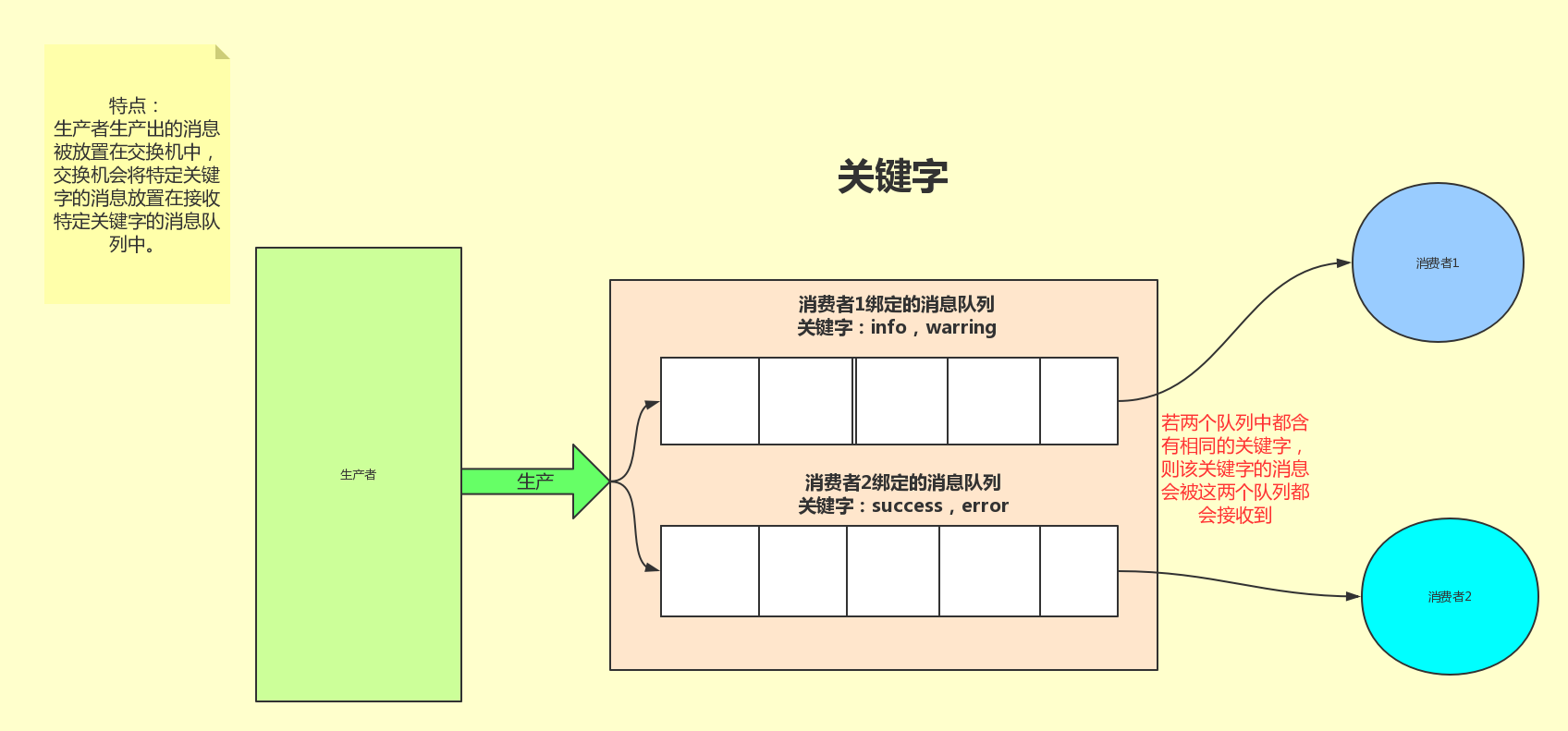
exchange type = direct
# 生产者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='118.25.231.23'))
channel = connection.channel()
# 声明一个交换机,该交换机的名字为 direct_logs,交换机的类型为 direct
channel.exchange_declare(exchange='direct_logs',
# 交换类型为:direct
exchange_type='direct')
# 定义发送的消息
message ="dayanjing de yuchao"
# 将消息发送至direct_logs交换机
channel.basic_publish(exchange='direct_logs',
# 指定发送消息的关键字
routing_key='info',
# 发送的内容
body=message)
print(" [x] Sent %r" % message)
connection.close()
# 消费者
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='118.25.231.23'))
channel = connection.channel()
# 声明一个交换机,该交换机的名字为 direct_logs,交换机的类型为 direct
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
# 创建一个队列
result = channel.queue_declare(exclusive=True)
# 获取创建队列的名称
queue_name = result.method.queue
for i in ["error","warning","info"]:
# 为创建的队列循环绑定 error warning info 关键字
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=i)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
模糊匹配
exchange type = topic
发送者路由值 队列中 old.boy.python old.* -- 不匹配 old.boy.python old.# -- 匹配
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
- # 表示可以匹配 0 个 或 多个 单词
- * 表示只能匹配 一个单词
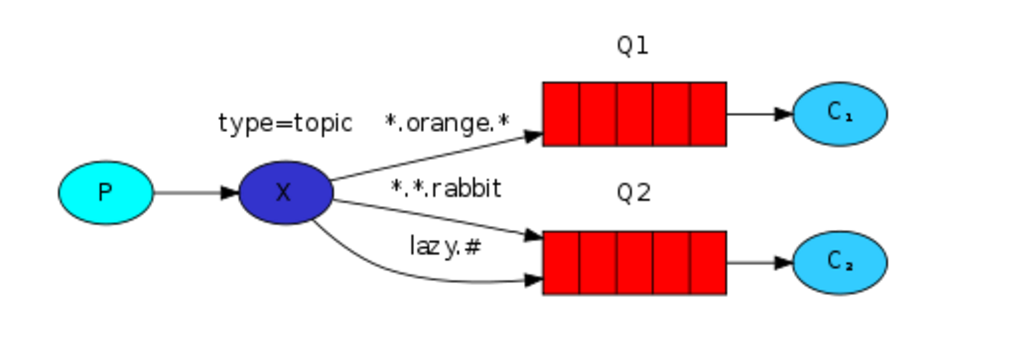
# 生产者
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
# 声明一个名为logs的交换机
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
# 定义的消息
message ="dayanjing de yuchao"
# 差值
channel.basic_publish(exchange='topic_logs',
routing_key='alex.apple.sb',
body=message)
print(" [x] Sent %r" % message)
connection.close()
# 消费者
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key="*.apple.*")
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号