

【2020暑假学习】第四次作业:卷积神经网络 part3
第四次作业:卷积神经网络 part3
【第一部分】 代码练习
-
1. HybridSN 高光谱分类网络
class HybridSN(nn.Module): def __init__(self): super(HybridSN, self).__init__() self.conv1 = nn.Conv3d(1, 8, (7, 3, 3), stride=1, padding=0) self.conv2 = nn.Conv3d(8, 16, (5, 3, 3), stride=1, padding=0) self.conv3 = nn.Conv3d(16, 32, (3, 3, 3), stride=1, padding=0) self.conv4 = nn.Conv2d(576, 64, kernel_size=3, stride=1, padding=0) self.fc1 = nn.Linear(18496, 256) self.dropout = nn.Dropout(p=0.4) self.fc2 = nn.Linear(256, 128) self.fc3 = nn.Linear(128, class_num) def forward(self, x): out = F.relu(self.conv1(x)) out = F.relu(self.conv2(out)) out = F.relu(self.conv3(out)) out = out.reshape(out.shape[0], -1, 19, 19) out = F.relu(self.conv4(out)) out = out.view(-1, 64 * 17 * 17) out = self.dropout(F.relu(self.fc1(out))) out = self.dropout(F.relu(self.fc2(out))) out = self.fc3(out) return outaccuracy:97.71% 97.93% 96.55%
加入bn层
accuracy:98.56% 98.74% 98.55%
关于bn、relu、dropout的相关顺序
Batch Normalization 层插入在 Conv 层或全连接层之后,在 ReLU等激活层之前。而对于 dropout 则应当置于 activation layer 之后。
-
2. SENet 实现
class SELayer(nn.Module): def __init__(self, inplanes): super(SELayer, self).__init__() self.avgpool = nn.AdaptiveAvgPool2d(1) self.fc1 = nn.Linear(inplanes, inplanes//16) self.fc2 = nn.Linear(inplanes//16, inplanes) def forward(self, x): out = self.avgpool(x) out = out.view(x.size(0), x.size(1)) out = F.relu(self.fc1(out)) out = self.fc2(out) out = out.sigmoid() out = out.view(x.size(0), x.size(1), 1, 1) out = out * x return outaccuracy:98.36% 98.28% 98.35%
class SELayer2(nn.Module): def __init__(self, inplanes): super(SELayer2, self).__init__() self.avgpool = nn.AdaptiveAvgPool2d(1) self.fc1 = nn.Conv2d(inplanes, inplanes//16, kernel_size=1) self.fc2 = nn.Conv2d(inplanes//16, inplanes, kernel_size=1) def forward(self, x): out = self.avgpool(x) out = F.relu(self.fc1(out)) out = self.fc2(out) out = out.sigmoid() out = out * x return outaccuracy:98.36% 98.31% 98.42%
问题:
- nn.Conv2d及nn.Linear中,bias的设置对网络有什么影响?
- FC层Linear和Conv2d的两种实现有什么区别?
添加了SE模块后准确率有所提升。SE模块对各个特征图赋予权重,不再是简单的相加,而是加权求和,强调重要的部分,忽略不重要的部分。不仅建模了图像的空间信息,也建模了通道之间的信息。
nn.ReLU(inplace=True)
对于inplace的不同设置计算结果不会有影响。利用in-place计算可以节省内(显)存,同时还可以省去反复申请和释放内存的时间。但是会对原变量覆盖,只要不带来错误就可以使用。
参考:nn.ReLU() 和 nn.ReLU(inplace=True)区别
tensor.expand_as()
把一个tensor变成和函数括号内一样形状的tensor。对于out.expand_as(x),out.expand_as(x)和x大小是一样的。
但torch.Tensor中,a与b做*乘法,原则是如果a与b的size不同,则以某种方式将a或b进行复制,使得复制后的a和b的size相同,然后再将a和b做element-wise的乘法。
所以无需令out = out.expand_as(x) * x
【第二部分】 视频学习
-
1. 语义分割中的自注意力机制和低秩重建 李夏
语义分割对图中每个像素输出一个label,输出更为密集。
FCN 全卷积网络进行语义分割的问题:语义分割任务需要较大的感知域,感知域太小,靠卷积难以完成狗和猫腿的区分。
怎么扩大感知域?
使用带洞卷积或PSPNet。
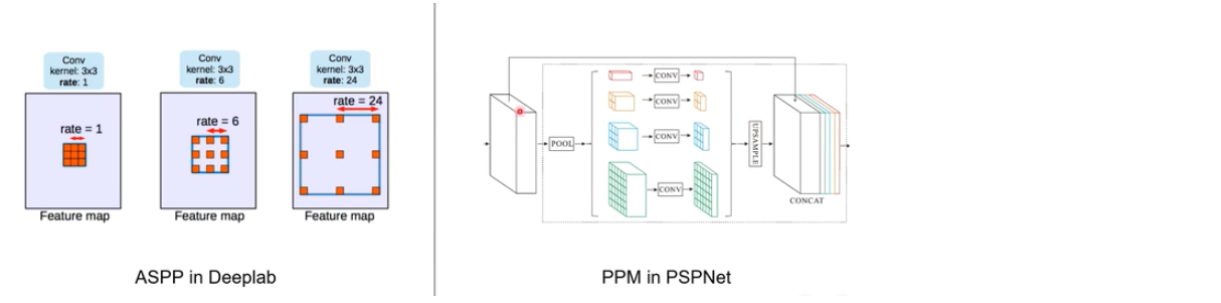
Pooling可以有效增加感知域。在特征图上,使用金字塔池化模块来收集上下文信息。使用4层金字塔结构,池化内核覆盖了图像的全部、一半和小部分。它们被融合为全局先验信息。
PSPNet为像素级场景解析提供了有效的全局上下文先验。金字塔池化模块可以收集具有层级的信息,比全局池化更有代表性。
![]()
Nonlocal Neural Networks
用于捕获长距离依赖,建立图像上两个有一定距离的像素之间的联系,建立视频里两帧的联系。
![]()
可以在任意已经训练好的模型结构中插入Non-local Block,不需要改变原有的网络结构。如果将Wz权重矩阵初始化为0的话,模型就和原始的结构一致,然后进行下一步训练。
输入:T-视频帧数,H×W-空间分辨率,1024-通道数。f遵循非局部均值和双边滤波。
使用数量512,大小为1×1×1的卷积进行三个分支的卷积。每一步操作与公式对照如图所示。
参考视频:https://www.bilibili.com/video/BV1Wk4y1B7yb/?spm_id_from=333.788.videocard.4
-
2. 图像语义分割前沿进展 程明明
语义分割需要的尺度范围非常广泛。
Res2Net
![]()
对经过1x1输出后的特征图按通道数均分为4块,每一部分做3*3卷积或融合后进行卷积,这样可以得到不同感受野大小的输出。


【第三部分】 论文学习
-
1. SKNet
SENet:feature map做一个全局池化,变成C维向量。用两个全连接层,特征向量乘原feature map,相当于对原feature map加了权重。
sigmoid用来分配权重,特征向量经过sigmoid后变成0-1之间的数。
![]()
SKNet:softmax得到的分类维度的向量,几个值加起来的和是1。SKNet中使用softmax,向量a+b=1。
Select:每一层在黄色和绿色两种卷积核中选择更重要的一个进行加和。
-
2. SPM
为了同时得到全局和细节信息。
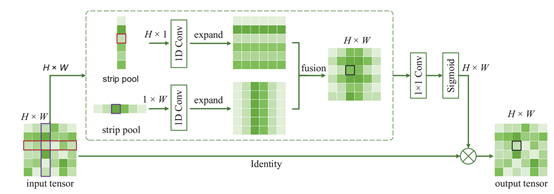
使用Hx1和1xW尺寸的条状池化核进行操作,对池化核内的元素值求平均,并以该值作为池化输出值。Hx1和1xW池化核处理后,对两个输出feature map分别沿着左右和上下进行扩容,扩容后两个feature map尺寸相同,进行fusion(element-wise上的add)。采用element-wise multiplication的方式对原始数据和sigmoid处理后的结果进行处理,sigmoid得到0-1之间的权重,乘回feature map。
![img]()
-
3. HRNet
高分辨率网络
图像分类低分辨率即可,关注全局,并不关注每个像素是什么标签。但特征点标定、人体姿态需要高分辨率。
U-Net、SegNet、DeconvNet、Hourglass等,都是从高分辨率到低分辨率再到高分辨率。从高到低再恢复高的过程会导致空间位置信息的丢失。
HRNet提出高分辨率网络,整个过程保持高分辨率。将高分辨率和低分辨率并联,其间三个卷积有交互。低分辨率的感受野较大,语义特征比较强,需要低分辨率的语义特征帮助高分辨率。
为什么保持高分辨率参数还没有爆炸?宽度为32、48,和ResNet(256)比起来小得多。参数量计算量与ResNet类似。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号