
深度学习之卷积神经网络
由于在看这类文章时专业名词较多,所以在正式开始前,我先介绍一些同义专业名词,各名词具体含义以及之间的关系在文中介绍。
卷积层 = C层
采样层 = 池化层(pooling层),S层
平面 = 特征图(feature map),通道,map
卷积核 = 权向量,滤波器
神经元 = 特征,结点,单元,像素点,patch
局部感受野的大小 = 滤波器的大小
1、 引入
在人工神经网络中,当网络层数增多时,网络中的权值以成倍的速度在增长。比如当输入为一个1000*1000图片时(假如网络总共有6层,每层100个节点)则需要的权值数为:1000*1000*100+100*100*4,这么多的权值数目严重影响了网络的训练速度,为了训练好模型同时也需要更多的训练样例,同时过于复杂的模型也易导致过拟合的发生。
在上例中,主要是前面的输入层到第一层的权重参数太多,那么如何解决呢?传统的方法就是人工从图像中抽取较少特征,然后再放入全连接的神经网络中,但这种方法存在两个问题,一个问题是人工抽取特征效率较低,其次是抽取的特征不一定准确。
现在我们需要想个方法能自动的抽取图像中的特征,将高维的图像转化为低维度的特征。那么我们必须在神经网络前面加上一个处理层,在此我们称为卷积层,通过在人工神经网络前面添加卷积层来先将高维的图像转成低维度的特征,然后再使用全连接的神经网络,这样就会达到很好的性能。我们称这种添加了卷积层的网络为卷积神经网络。
卷积神经网络属于有监督的学习算法,是深度神经网络中的一种特殊情况,它相比于深度人工神经网络具有权值数量少,训练速度快等优点。并且它在图形识别方面已经取得了很好的效果。
2、卷积网络介绍
卷积神经网络是由多层神经网络所组成,每层又有多个二维平面,每个二维平面有多个独立的神经元。神经元又分成简单元(又叫S元)和复杂元(又叫C元),由简单元聚集的平面称为S面,由S面聚集的层称为S层(又叫抽样层);同理,由复杂元聚集的面叫C面,C面聚集的层叫C层(又叫卷积层)。
在上面的分析中,我们知道6层网络需要的权值数为:1000*1000*100+100*100*4。其中输入层到隐藏第一层所需的权值数为:1000*1000*100。那么在卷积神经网络中如何减小权值数呢?我们主要通过两种方式
1)局部感受野。我们将输入的图像划分成很多的小方阵,每个小方阵我们称为局部感受野。然后第一个隐藏层的神经元不需要和输入层的所有单元相连,而只需要与其对应的局部感受野的节点连接即可,此时每个神经元需要的权重参数个数为滤波器的大小。通过局部感受野,我们可以将权值个数从原来的1000*1000*100减少到100*10000。数目还是有点多,于是就有了第二种方法。
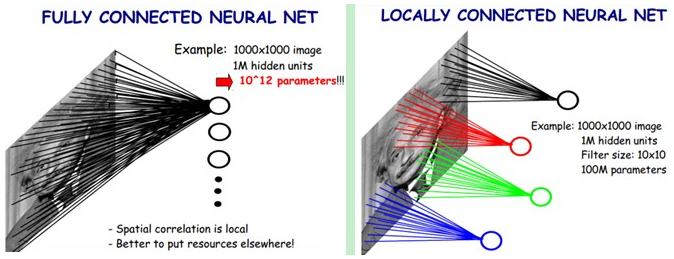
图2.1 全连接和局部连接的权值数[6]
2)权值共享。若我们将上面的所有的神经元共享相同的权值向量,那我们只需要10*10个权值,但是只有一个权向量,很明显特征提取的不够充分,信息失真较大。为了提取更多的特征,于是我们将上面提到的所有神经元放在一个特征图中。在每一层设置多个特征图,不同特征图中的权向量不同,这样,当一层有100个特征图时,总共需要的权值数为:10*10*100。这相比原来的1000*1000*100减少了一万倍。
在卷积网络中,中间的隐藏层都是卷积层和抽样层交叉出现。随着逐层的深入,每一层的特征图会越来越多,同时每个特征图内的神经元会越来越少,直到神经元的个数为1. 当每个特征图中的神经元个数为1时,网络的连接变成了全连接,这相当于经典的人工神经网络。更通俗的说,卷积层就是从二维图像中抽取出一维特征后接入经典的人工神经网络中,主要起降维的作用。
另外,在网络的最开始几层,往往越倾向于只学习图像的局部特征,随着层次的深入,慢慢会学到更加高层的特征,到最后学习全局特征。
3、模型介绍
卷积网络与人工神经网络最大的不同就是在网络的前面添加了卷积区。其中卷积区主要是卷积层和抽样层交叉出现。
1)卷积层(C层)。
在进行卷积操作之前,首先需要确定滤波器的大小,对于上一层的局部感受野中的一个特征xi,我们使用卷积核kernelij来对其进行加权得到xi*kernelij,然后对其求和后加偏移。其计算公式如下:
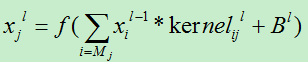
Mj:神经元j对应的局部感受野,
Kernelijl:第l层的神经元i的第j个输入对应的权值。(一个平面内的所有神经元共享同一个卷积核。)
Bl:第l层的唯一偏移。
卷积过程分析:
特征图的数目会有所增加,但是每次增加多少?这个问题类似人工神经网络中每层隐藏节点的数目一样,应该还没有一种非常科学的方法来计算,只能进行大概的估计。另外,局部感受野的区域可以发生重叠。假如上一层的特征图的大小为S*S,滤波器的大小为k*k,则需要满足S>=k。每个神经元可以从上一层的特征图的选择方式有(S-k+1)*(S-k+1)种。当k=S时,此时的特征图只有一个神经元。
另外,C层中的一个神经元只能从上一个特征图中提取特征,而不能从多个特征图同时提取特征,当然,同一平面不同的神经元可以从不同的特征图提取特征。在尽可能的情况下,C层的每个特征图的从上一层的几个特征图中选取局部感受野,它不会只在一个特征图,也不会在所有的特征图中选择特征,这样能保持连接的非对称性从而抽取不同的特征,并且也控制了连接数量。
2)抽样层,又称为:池化层(pooling层)。
抽样层主要采用下采样的方法。下采样是指对信号进行抽取(连续-->离散),上采样是下采用的逆过程,(离散-->连续),其中上采样又称增取样,内插。
在此处的下采样的方法中,主要有三种方式:
A)max-pooling(最大池化):选择局部感受野中值最大的点。
B)mean-pooling(均值池化):将局部感受野中的所有值求均值。
C)Stachastic-pooling(随机池化):从局部感受野中随机取出一个值。
采用这种抽样方法的理论依据在于图像的局部性原理,图像每个像素点(或者说特征)周围应该和该点具有较大的相似度。通过抽样的方法能减少很多的特征,但同时也会损失不少的有用信息。在抽样中,滤波器的大小一般取2*2比较合适,因为过大的滤波器会导致损失的信息较大。
假如我们使用mean-pooling的采样方法,即均值池化。然后将采样出的信息乘以可训练参数,再加上可训练偏置,将得到的结果通过激活函数计算即可得到当前神经元的输出。其中激活函数可以采用sigmoid函数或者tanh函数。
第l层的输出计算公式为:

其中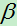 :第l层的可训练参数。
:第l层的可训练参数。
Bl:为可训练偏置
Mj:为神经元j对于的局部感受野。
down(x):表示对x进行下采样。
若下采样为mean-pooling,则:
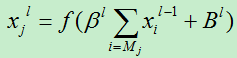
其中激活函数可以使用:
Sigmoid函数: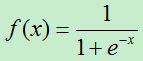
或者tanh函数:
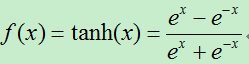
池化(采样)过程分析:在抽样的过程中,特征图的数量保持不变,并且局部感受野无重叠,滤波器的大小一般为2*2,因为太大的滤波器会导致信息损失过多。假如上一层每个特征图的大小为C*C,滤波器的大小为k*k,则经过池化后的特征图的大小为:(C/k)* (C/k)。
卷积层和池化层(抽样层)的过程可以描述可以参考图3.1。图中的符号与上面公式中的符号有所差异。

图3.1 卷积和抽样过程[3]
4、卷积网络样例分析
在此我们使用Yann lecun大神论文[1]中介绍卷积网络的例子进行分析。由于原图字迹模糊,故而此图的文字经本人重新编辑。
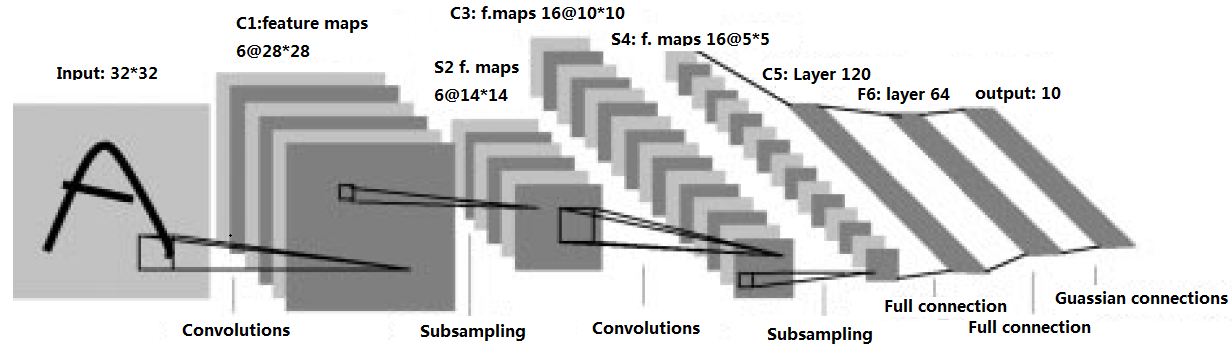
图 4.1 卷积神经网络结构[1]
下面,讨论一下图4.1中网络各层之间的处理过程
0)输入层到S1层的工作
在图4.1.中没有该过程,因为输入的图片已经是规格化的,但是在有些情况下需要这个步骤的。即当输入为彩色图像,或图像大小不规范时,我们需要先对图像进行一些预处理操作,比如将图像进行灰度化,归一化处理等。通过预处理后的图像就可以进行下一步的卷积操作。
1)输入层到C1层
此过程被称为卷积操作。在输入层,有一个大小为32*32的图像,我们通过第一层卷积操作,得到C1层。在C1层,我们的每个神经元与输入层中大小为5*5的局部感受野相连。这时,在输入层的32*32大小的特征图中有(32-5+1)*(32-5+1)=28*28种不同的选择,我们将这28*28中不同的组合全部选择加入到C1的特征图中。
在C1层共有6个特征图,其中权值的个数为:(5*5+1)*6个。
2)从C1层到S2层
此过程被称为池化过程,又称抽样过程(下采样)。此过程主要的目的在于减少上一层的特征数量。设滤波器大小为2,则经过池化过程,特征的数量减少2*2倍。在上一层特征图的大小为28*28,故而经过此层抽样后得到的特征图大小为14*14。另外,抽样过程一般不会增加特征图的数量,只有卷积过程会增加特征图的数目。、
此过程需要的权值个数为:(1+1)*6,因为在将局部感受野作为输入通过均值池化乘以可训练参数再加上可训练偏置,这只有两个权值变量。总共6个特征图,故而需要的权值数为:12个。
3)从S2层到C3层
此过程类似输入层到C1层,我们将滤波器大小设为5*5,将C3层的特征图的大小设为10*10。从S2中的每个特征图中,有(14-5+1)*(14-5+1)=10*10种选择,但是,我们将C3中的一个特征图中所有的神经元从S2的不同特征图中选取局部感受野,而不是将C2中的一个特征图的全部可能选择加入到C3中的一个特征图中(有点拗口,理解就好)。简单来说,就是C3中的每个特征面从S2的不同的特征面抽取特征,这样可以抽取到不同类型的特征,也能控制连接的数量。
此时需要的权值个数为:(5*5+1)*16=416个。
4)从C3层到S4层
此层为典型的池化(抽样)过程,基本和C1层到S2层的过程类似。此层有16个特征图,滤波器大小为2*2。通过此次抽样,每个特征图缩小了2*2=4倍,此过程需要权值个数为:(1+1)*16=32个。
5)从S4层到C5层
C5层共有120个特征图,每个特征图的大小为1*1,滤波器的大小为5*5。这相当于C5层的神经元与S4层中的一个特征图是全连接的。
至此,我们已经将原来的32*32个维度的图像转化成了只有120个特征的向量,这时可以使用人工神经网络来进行处理。
6)从C5层到F6层
此过程类似人工神经网络的权值连接,连接过程为全连接。在F6层共84个神经元,为何是84个,这和输出层的节点数目有关,具体是啥关系本人尚未研究。
7)从F6层到输出层
输出层共10个节点,每个输出节点是一个RBF(Radial Basis Function)单元,每个RBF单元计算输入向量和参数向量之间的欧氏距离。输入离参数向量越远,则RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。[1,3]
对于图4.1的详细分析过程请参看文献[1]。
另外,为了加深理解,大家可以在研究一下DeepID的卷积过程,DeepID是香港中文大学的Sun Yi开发出来用来学习人脸特征的卷积神经网络。这也是一个关于卷积神经网络非常好的一个样例,在此就不做分析。
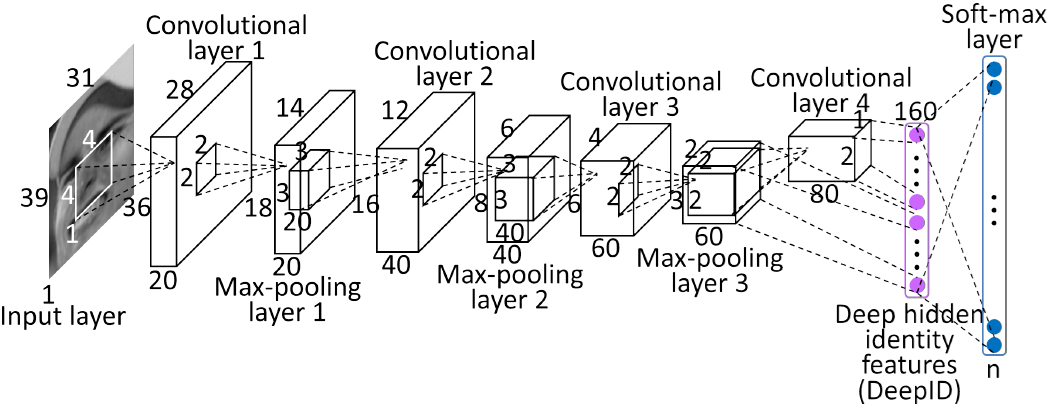
图 4.2 DeepID网络结构图
5、卷积训练过程
网络的训练过程和人工神经网络有点类似,只是一些计算公式存在一些区别。具体训练过程如下:[4]
1)初始化。初始化权值,将所有权值初始化为一个较小的随机数。
2)从训练集中取出一个样例X输入到网络中,并给出它的目标输出向量D。(训练集通常是一个图片库)
3)从前向后依次计算得到网络的输出Y。对于不同层的计算方法如下:
A)对于卷积层,使用公式:
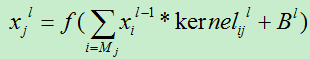
//此处的kernel为卷积核,其实就相当于权向量。
说明:关于卷积层的输出值,最终需要添加sigmoid函数进行非线性话变换。
B)对于抽样层,其计算公式为:
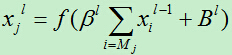
C)对于全连接层,可以直接使用多层人工神经网络的方法计算即可。
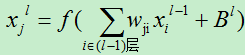
其中f(x)为sigmoid函数。
4)反向依次计算各层的误差项。
A)输出层的误差。
假如输出层共有M个结点,则对输出层的结点k的误差项为:
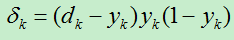
其中dk为结点k的目标输出,yk为结点k的预测输出。
B)中间全连接层的误差。
假如当前层为第l层,共L个结点,第l+1层共M个节点。则对于第l层的节点j的误差项为:
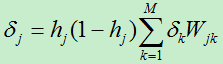
其中:hj为结点j的输出,Wjk为第l层的结点j到第l+1层的节点k的权值。
C)对于卷积区的误差项
此处的误差项的计算参考全连接层。
5)从后向前逐层依次计算出各权值的调整量,在第n轮迭代的节点j的第k个输入的权向量的改变量为:

//式中的N为当前的输入变量个数。
//对于输出层和中间层,权值的改变量的计算公式相同。
阀值的改变量为:
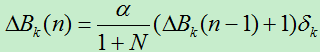
6)调整各权值,更新后的权值为:
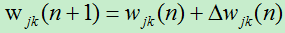
更新后的阀值为:
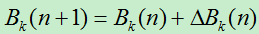
7)重复上面2)~6),直到误差函数小于设定的阀值。其中误差函数为:
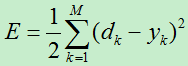
6、误差分析[2,8]
此部分见下一篇文章:“卷积网络误差分析”
7、总结
卷积网络是个比较抽象的东西,里面有较多的专业名字,理解起来比较费力,所以在文中最开始的地方就将一些同义不同名的专业名词进行了整理,以便下文的理解。网络中各层之间的关系看起来简单,但要把里面真正弄清楚还是需要花较多的时间。
总的来说卷积网络相比神经网络在权值数目上确实减少了很多,权值数量的减少意味着模型复杂度变得更加简单,也使得模型不那么容易过拟合。
本文断断续续的写了很长时间,写得有点混乱,不清楚的看我的参考文献吧,另外,由于本人水平有限,若发现文中错误请指出!
参考文献:
[1] Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[C]// Proceedings of the IEEE1998:2278--2324.
[2] Bouvrie J. Notes on Convolutional Neural Networks[J]. Neural Nets, 2006.
[3] zouxy09, http://blog.csdn.net/zouxy09/article/details/8781543
[4] 徐姗姗. 卷积神经网络的研究与应用[D]. 南京林业大学, 2013.
[5] nan355655600, http://blog.csdn.net/nan355655600/article/details/17690029
[6] 雨石, http://blog.csdn.net/stdcoutzyx/article/details/41596663
[7] loujiayu, http://www.cnblogs.com/loujiayu/p/3545155.html?utm_source=tuicool
[8] zouxy09, http://blog.csdn.net/zouxy09/article/details/9993371

 浙公网安备 33010602011771号
浙公网安备 33010602011771号