
mysql数据结构
1.聚集索引和非聚集索引的创建
表中的所有数据按照 B+ 树排序只能产生一张表也就是主表,这张主表也就是聚簇索引或者非聚簇索引。根据索引键建立的辅助索引就是另外一张表,如果查询的数据正好是这样辅助索引的中的字段,就是索引覆盖,直接返回数据就可以,但是如果查询的数据在辅助索引表中没有,就需要根据辅助索引查询到的主键再去主表中查询需要的数据(回表)。一张物理表可以建立多张辅助索引。
聚簇索引: 非叶子结点存储主键索引,叶子结点存放数据行记录。
非聚簇索引: 非聚族索引的叶子结点存储主键值,然后在通过主键值去聚簇索引树中回表查询数据。
2.B+树
B+树的结构:B+ 树中各个页之间是通过双向链表连接的,叶子节点通过单向链表连接的。
如果我们的 B+ 树一个节点可以存储 1000 个关键字,那么 3 层 B+ 树可以存储 1000×1000×1000=10 亿个数据。一般根节点是常驻内存的,所以一般我们查找 10 亿数据,只需要 2 次磁盘 IO。
B+ 树非叶子节点上是不存储数据的,仅存储关键字,这样B+树会更加矮胖,一次IO可以加载更多的索引数据
2. myisam和innodb区别
MyISAM 中的 B+ 树索引的叶子节点并不存储数据,而是存储数据的文件地址。innodb的叶子节点存储数据
MyISAM:数据插入速度更快,因为数据顺序写入到MYD文件中。新插入的数据只更新MYI索引文件,所以myisam速度更快。
innodb新插入一行数据需要数据和索引都做变动。
3.数据库三大范式
1.字段具有原子性,不能再拆分。
2.一张表必须有主键,被唯一区分。
3.一张表中不能包含关联表中的非关键字段信息,没有冗余信息。
4.柔性事务
如果将实现了 ACID 的事务要素的事务称为刚性事务的话,那么基于 BASE 事务要素的事务则称为柔性事务。BASE 是基本可用、柔性状态和最终一致性这 3 个要素的缩写。
在 ACID 事务中对一致性和隔离性的要求很高,在事务执行过程中,必须将所有的资源占用。柔性事务的理念则是通过业务逻辑将互斥锁操作从资源层面上移至业务层面。通过放宽对强一致性和隔离性的要求,只要求当整个事务最终结束的时候,数据是一致的。而在事务执行期间,任何读取操作得到的数据都有可能被改变。这种弱一致性的设计可以用来换取系统吞吐量的提升。Saga 和 TCC 都是典型的柔性事务实现方案。
5. varchar和char区别
varchar是可变长度,char是固定长度。比如,存储字符串“abc,对于CHAR (20),表示你存储的字符将占20个字节(包括17个空字符),而同样的VARCHAR (20)则只占用3个字节的长度,20只是最大。
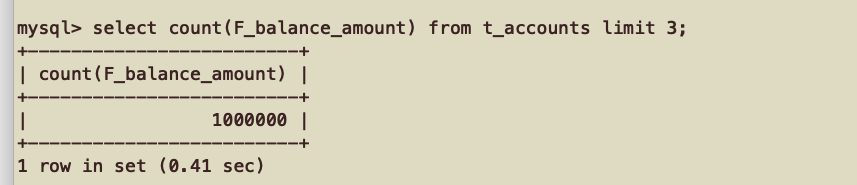
6. count(*) count(1)效率比较
cout(1) > cout(*)>count(主键)
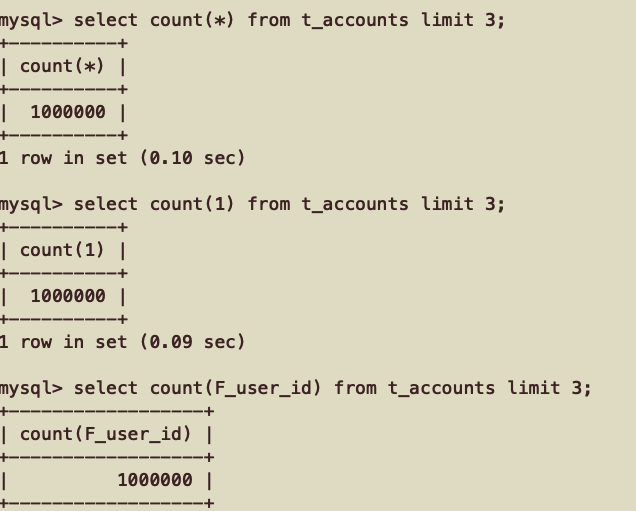
非主键
count(1)和count(主键) 这两个只扫描主键Index就可以得到数据,
count(*)是扫描表的。
所以count(1)和count(主键)这两个效率高。
7. mysql修改表字段方法
100万行数据耗时9.38秒,会阻塞线上数据的写入

修改保留字段,会阻塞线上数据写入

在线更改字段步骤:
创建一个与原始表结构相同的备份表:不阻塞线上写入
create table XXX_bak like XXX
备份数据:不阻塞线上写入,快照读不阻塞写入。
mysql> create table t_accounts_bak1 select * from t_accounts; Query OK, 1307115 rows affected (3.31 sec) Records: 1307115 Duplicates: 0 Warnings: 0
修改表名称:不阻塞线上写入
RENAME TABLE 表名 TO 新表名;
8. mysql changebuffer用于缓存更新操作,当更新数据时会先将更新缓存到change buffer中,然后定期刷新到磁盘中,减少了随机写。写log会顺序写入磁盘。
9. 哈希索引
对于每一行数据,存储引擎都会对索引列计算一个哈希码,只有精确匹配才能定位行数据。
哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。
无法进行排序和范围查找。哈希索引也不支持部分索引列匹配查找,哈希码是根据所有的列进行的hash计算。
10. 数据库优化
1.对常用字段加索引
2.分库分表,读写分离
3.优化慢查询语句优化,查看是否存在索引失效。
11. 事务——查询
- 如果一次执行单条查询语句,则没有必要启用事务支持,数据库默认支持SQL执行期间的读一致性,不需要担心批量查询的数据被修改。
- 如果一次执行多条查询语句,例如统计查询,报表查询,在这种场景下,多条查询SQL必须保证整体的读一致性,否则,在前条SQL查询之后,后条SQL查询之前,数据被其他用户改变,则该次整体的统计查询将会出现读数据不一致的状态, 此时,应该启用事务支持。
10. 行锁
innoDB行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁。
11. mysql 锁调优:
delete from tb where num<1000000 调优后:delete from tb where num<1000000 limit 5000,分批执行避免锁占用时间过长。
行锁:会出现死锁,并发高,锁冲突概率低。避免死锁:
- 一种策略是,直接进入等待,直到超时。这个超时时间可以通过参数 innodb_lock_wait_timeout 来设置。默认50秒。
- 将参数 innodb_deadlock_detect 设置为 on,来进行主动死锁检测,发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。对同一行的更新如果并发量过高会使死锁检测消耗大量的cpu。解决思路是对相同行的更新在中间件控制并发量,或者进行排队。
- 减小事务大小,避免锁定资源时间过长。
- 使用索引键来加锁,否则会升级为表级锁,增加锁冲突。
提高数据insert速度:一条sql语句插入多条数据,原因是减少事务日志刷盘次数,减少sql解析次数,减少网络io,受限于sql本身的长度,默认1M;开启事务,在事务内部进行数据插入,避免插入时系统默认自动开启事务,事务太大会降低效率,事务到达配置参数前需要commit;数据按照主键有序插入,有序的数据会减小索引的维护成本,如果插入的记录在索引中间,需要B+tree进行分裂合并等处理。
mysql :
查询缓存:一张表中对应一个查询缓存,只要表有一条数据更新,整个缓存失效。查询缓存一般在查询静态表时使用。
链接器:mysql长链接,随着查询增多,长链接占用的内存会越来越多,需要定期断开长链接释放内存。
分析器:语法分析,词法分析。
优化器:索引选择,join链接顺序。
执行器:校验权限,操作存储引擎返回结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号