信息论
A mathematical theory of communication
Audio学习: https://www.youtube.com/watch?v=SgcU9nl9oAM&list=PLWDB4efc1BVY_OzzdeYStpxd2hVe35mVC
背景
目前21世纪所处的时代是信息时代,信息时代的最主要特征是不确定性。以前的靠某个规律或者通过简单的几条生活智慧活好一辈子的时代已经一去不复返了。(比如说把钱存银行吃利息就稳赚,但是目前看并不是,而且你的钱投资到哪里都有着非常大的不确定性)
信息论是人类和不确定性抗衡的最有效的方法。
详细内容
视频一 导论
1. 利用信息,消除不确定性
2. 不确定性一直都有,只是
2.1: 以前的不确定性是偏连续的,现在的不确定性是跳跃的。
2.2: 以前人类连确定的事情都没解决,对于解决不确定性的问题会回避
3. 学习大纲
3.1: 信息产生: 面对大量的信息,如何降噪
3.2: 信息传播: 传播最有效的信息
3.3: 信息应用: 提前抓住新机遇
视频二 导论
1. 宇宙是从一个无限小,温度无限高的质点产生的 --- 宇宙大爆炸理论
2. 普朗克时间,可以度量的最小时间单位,大约是10^(-44)次方秒
视频三 导论
1. 现在的公司都从重研究方法,到从重数据收集的改变
2. 四类信息轮解决问题的案例
----2.1 利用大数据解决人工智能问题(语音识别),贾里尼克放弃所有语言学专家,把语音识别转换成 信息传播中的 编码和解码的模型。重视收集数据统计各种参数
----2.2 利用大数据进行精准服务,比如搜索乔丹,需要根据用户的癖好来决定出什么结果。不能说10条中5条A,5条B,这样不能满足所有用户的需要
----2.3 利用大数据动态调整做事情策略,滴滴公司根据用户数据动态安排(如果有足够多的数据、在理论有保障的情况下,只要调整次数足够多,就能调整出最佳匹配)
----2.4 利用大数据发现不知道的规律,研究一款新药需要20年的成本,太慢了。方法: 让各种药和各种疾病重新匹配,由于药的毒性以前已经验证过了,所以实验周期可以减少
视频四 信息量
1. 信息源(information sources)
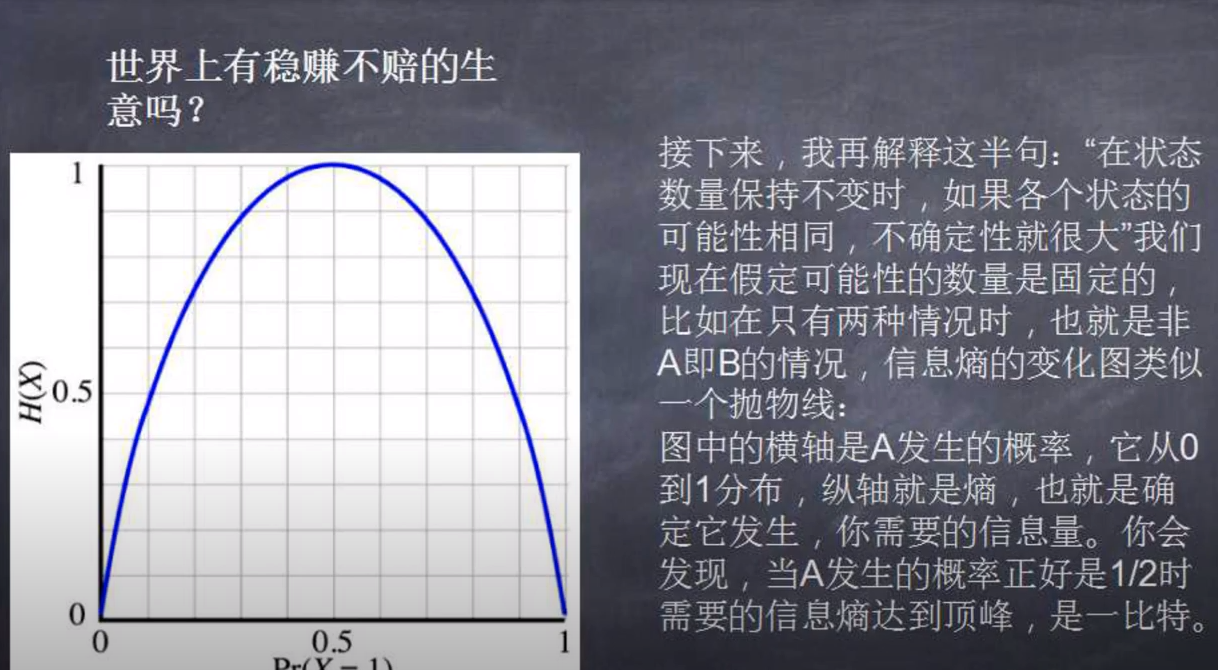
2. 信息的单位: bit, 如果一个黑盒子中有两种可能,A和B。出现的概率一样。那么需要搞清楚A还是B,所需要的信息量就是1bit
3. 黑盒子---信息源,里面的不确定性---信息熵,信息就是用来消灭这种不确定性的,需要的信息量就等于里面的信息熵
问题: 如果你和一个非常会玩石头剪刀布的人玩,什么策略才是最优的
视频五 人类如何使用语言和数字编码克服不确定性
1. 数字和文字是人类用来消除信息不确定性的编码系统,各种编码系统,其实都是在编码长度和编码复杂性之间做权衡,编码复杂度越高,编码长度就越低。比如我们使用每一个符号来代表1--100,编码长度只有1,但是编码复杂度会很高。
2. 香浓第一定律,只要编码设计的足够巧妙,我们就可以找出最短的编码。编码长度 >= 信息熵/编码复杂度,而且总有一种方法使得这个等号成立
3. 信息的熵是确定的,在一个编码系统内解决不了的事情,换了一套编码系统同样也是解决不了的
问题: 编码是在长度和编码复杂性做权衡,那么人类日常也有很多权衡的东西,比如有那些呢?
视频六 有效编码
如何设计很好的编码
好的编码系统
1. 有很好的辨析度,比如不好老是出现形近字
2. 有效性,十个手指头能代表1024个数字,因为使用二进制。假如一个手指头设定三种状态,那么就很难辨认
3. 有效编码就是让理论最佳值在应用上落地
问题: 记得学以致用
视频七、最短编码
1. 哈夫曼编码
问题: 假定你有五天的时间去玩,有些经典热门但是人比较多,有些不热门但是人少,怎么安排这五天呢
视频八 信息的矢量化
1. 矢量化,比如所有英文文字都可以分类,分成词根,prefix, suffix,这样就是用三个维度衡量出所有单词。这就是一个矢量化的过程
问题: 如果你是人事经历,需要对员工进行度量,怎么样使用矢量化原则来评判一个人
视频九 信息的冗余度
1. 冗余度 = (信息的编码长度 - 其信息量) / 信息的编码长度
好处
----1.1 冗余度便于理解阅读(比如小说
----1.2 冗余度消除了很多歧义性,比如中文没有时态,需要通过上下文来恢复了
----1.3 冗余度可以带来信息的容错性
坏处
----2.1 过多冗余的信息可能带来错误(变成噪声,比如史记中很多人物有多种描述
----2.2 冗余会带来存储和传输的浪费
总结
3.1 讲话的时候需要带点冗余,帮助别人理解,说 “换句话说,比如说等”
3.2 说话的时候要一致性,不要说一些无用的话或者和主要思想矛盾的话
3.3 在脑子记东西的时候要进行编码
问题: 太简单的文字和太啰嗦的文字读起来都比较花时间,那么怎样写文章才能使读者更容易接受
视频十 信息的等价性
1. 我们获取信息,可以根据问题的等价性得到结论。比如想得到人体结果 --> 人体的细胞有水 --> 水有氢原子 --> 氢原子带电 --> 使用磁场排序 --> 加入和氢原子共振的脉冲 --> 核磁共振氢谱图
问题: 你是如何通过信息的等价性得到难题的答案的
视频十一 信息的相关性 ---> 信息的压缩和增量编码
1. 视频的压缩是使用主帧 + 辅助帧的做法,
2. google搜索把全部网页存起来,是使用过压缩的,就是利用各种信息的index相关性
问题: 视频有主帧的概念,后面加上各种辅助帧,保证压缩数据的同时。尽可能的减少主帧的次数,保证最好的容错性。在生活中什么东西是充当主帧的概念呢。
视频十二 信息的失真率
1. 香浓第一定律指出,任何编码长度都不会少于信息熵,假如小于,就是出现失去信息的情况
2. 失真度 = (压缩前信息 - 压缩后信息)的平方
3. 有损压缩就是把一些特别的信息,或者把高频的东西处理掉了
问题: 有很多人喜欢无损的压缩音乐或者电影,听起来真的有那么大区别吗
视频十三 信息的正交性 --> 信息的决策
1. 面临决策时,越多的信息反而更乱
2. 信息和能量不同,信息是不守恒的,相同的信息share给别人,你的信息并不会丢失
3. 信息使用两次是无效的
4. 力在同一方向中叠加效果最佳,但是信息要选垂直正交的,也就是需要从多个维度看问题
5. 10个技能选择3个的时候,最好是排序选择第一个,再一次重新评估,选取第二个。再重新评估,直到最后
6. 举一个例子就是图像识别,本来识别率是97%,后来可以通过网络上的大数据进行后处理修复匹配,使得正确率大增。
问题: 生活中是如何选取正交信息的。
视频十四 互信息
0. 相关不是因果,世界上更多是相关,而不是因果
1. 相当于条件概率,如果A和B同时发生的概率是P(A) * P(B),那么互信息就是为0,是说他们没有什么关系。
2. 知道信息A,能推出信息B,那么B这个信息是无用的
3. 我们生活中就是要找到很强的互信息,这样有助于我们找到规律。然而很强的互信息会让人觉得是因果关系,但是谁是因,谁是果得区分清楚。比如乌鸦到、丧事到。虽然有联系,但是只是因为丧事有了,才吸引乌鸦过来。
一句话就是想要探讨A能推出B的概率,可以也反过来思考一下是否由于B猜得到的A
问题: 经济好的国家政治制度都比较好,那么谁是因,谁是果?或者两者有没关系?
视频十五 怎么衡量你给出的信息价值
1. 在别人的眼里,不确定性是H(x),假如你有了条件Y,那么你的不确定性是H(x|y),也就是条件熵
----1.1 H(x|y) <= H(x),取等号的条件是y对你没用
----1.2 然后y肯定是需要你知道,别人不知道才成立
2. 信息增益(information gain)
----2.1 IG(y) = H(x) - H(x|y)
3. 科研水平
----3.1 论文的引用数
问题:第一个用鲜花比喻美女的是天才、第二个是庸才、第三个是蠢材、现实生活中还有什么例子呢
视频十六 置信度(帮你衡量一个信息是否可靠)
1. 什么是置信度,就是你一条信息中可信度。比如我抛了10次硬币,6次朝上,4次朝下。那么我得出银币不均匀,这个信息的置信度其实是很低的
----1.1 置信度一般需要达到95%才认为有用
----1.2 置信度可以使用z测试或者t测试测出来
----1.3 比如基金说10年来高于大盘1.1%,这个只是一个事实,但是不能证明他是一个好基金,因为置信度太低
2. 人们常范的错误是,老是相信置信度不高的信息,对于能够重复的信息、要被检验足够多次以后,置信度才高,对于难以重复的事情(比如一次偶然的成功)需要用其他方法验证
3. 问题:有经常复盘的情况吗,那些复盘中可以被称之为经验(可重复验证)、那些可以被称之为经历(不可重复验证)
视频十七 交叉熵
1. 代价函数:库尔贝乐交叉熵(K-L divergence),代表的是误判时的损失
----1.1 P(x) = (0.3, 0.7),代表真实情况X发生的概率,0.3诺曼底登陆,0.7在其他地方
---------Q(x) = (0.7, 0.3),代表我们的猜测,刚好相反
---------DKL(P | Q) = -sigma P(x) * log(Q(x) / P(x)),假如这条公式结果是1 bit,那么代价就是两倍的损失
---------该考虑的事情而完全不去考虑,最后事情发生了,损失是无穷大的
2. 除非100%猜对,否则任何决定都是有损的。所以在人工智能里面,搜索结果的时候往往会保留所有情况,那么置信度很低都需要保留,因为怕像赵括一样估计错误,类似于all in
3. 对于一些很少概率发生,但是又不能完全抛弃不思考的情况,可以使用古德-图灵估计
4. 问题: 说一下自己随机应变把事情做成的经历,或者all in做事的经历,再回顾一下,看看是否有新的决策
视频十八 如何识别误导人的信息
三大特征:
1. 一些耸人听闻的信息
----1.1 将他们放去更大的时空来考虑
----1.2 要看信息的一致性,防止标题党
----1.3 考虑信息抽取时的失真率
2.
posted on 2021-05-30 00:24 stupid_one 阅读(1025) 评论(1) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号