mapreduce 实现矩阵乘法
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MatrixMultiply { /** mapper和reducer需要的三个必要变量,由conf.get()方法得到 **/ public static int rowM = 0; public static int columnM = 0; public static int columnN = 0; public static class MatrixMapper extends Mapper<Object, Text, Text, Text> { private Text map_key = new Text(); private Text map_value = new Text(); /** * 执行map()函数前先由conf.get()得到main函数中提供的必要变量, 这也是MapReduce中共享变量的一种方式 */ public void setup(Context context) throws IOException { Configuration conf = context.getConfiguration(); columnN = Integer.parseInt(conf.get("columnN")); rowM = Integer.parseInt(conf.get("rowM")); } public void map(Object key, Text value, Context context) throws IOException, InterruptedException { /** 得到输入文件名,从而区分输入矩阵M和N **/ FileSplit fileSplit = (FileSplit) context.getInputSplit(); String fileName = fileSplit.getPath().getName(); if (fileName.contains("M")) { String[] tuple = value.toString().split(","); int i = Integer.parseInt(tuple[0]); String[] tuples = tuple[1].split("\t"); int j = Integer.parseInt(tuples[0]); int Mij = Integer.parseInt(tuples[1]); for (int k = 1; k < columnN + 1; k++) { map_key.set(i + "," + k); map_value.set("M" + "," + j + "," + Mij); context.write(map_key, map_value); } } else if (fileName.contains("N")) { String[] tuple = value.toString().split(","); int j = Integer.parseInt(tuple[0]); String[] tuples = tuple[1].split("\t"); int k = Integer.parseInt(tuples[0]); int Njk = Integer.parseInt(tuples[1]); for (int i = 1; i < rowM + 1; i++) { map_key.set(i + "," + k); map_value.set("N" + "," + j + "," + Njk); context.write(map_key, map_value); } } } } public static class MatrixReducer extends Reducer<Text, Text, Text, Text> { private int sum = 0; public void setup(Context context) throws IOException { Configuration conf = context.getConfiguration(); columnM = Integer.parseInt(conf.get("columnM")); } public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { int[] M = new int[columnM + 1]; int[] N = new int[columnM + 1]; for (Text val : values) { String[] tuple = val.toString().split(","); if (tuple[0].equals("M")) { M[Integer.parseInt(tuple[1])] = Integer.parseInt(tuple[2]); } else N[Integer.parseInt(tuple[1])] = Integer.parseInt(tuple[2]); } /** 根据j值,对M[j]和N[j]进行相乘累加得到乘积矩阵的数据 **/ for (int j = 1; j < columnM + 1; j++) { sum += M[j] * N[j]; } context.write(key, new Text(Integer.toString(sum))); sum = 0; } } /** * main函数 * <p> * Usage: * * <p> * <code>MatrixMultiply inputPathM inputPathN outputPath</code> * * <p> * 从输入文件名称中得到矩阵M的行数和列数,以及矩阵N的列数,作为重要参数传递给mapper和reducer * * @param args 输入文件目录地址M和N以及输出目录地址 * * @throws Exception */ public static void main(String[] args) throws Exception { if (args.length != 3) { System.err .println("Usage: MatrixMultiply <inputPathM> <inputPathN> <outputPath>"); System.exit(2); } else { String[] infoTupleM = args[0].split("_"); rowM = Integer.parseInt(infoTupleM[1]); columnM = Integer.parseInt(infoTupleM[2]); String[] infoTupleN = args[1].split("_"); columnN = Integer.parseInt(infoTupleN[2]); } Configuration conf = new Configuration(); /** 设置三个全局共享变量 **/ conf.setInt("rowM", rowM); conf.setInt("columnM", columnM); conf.setInt("columnN", columnN); Job job = new Job(conf, "MatrixMultiply"); job.setJarByClass(MatrixMultiply.class); job.setMapperClass(MatrixMapper.class); job.setReducerClass(MatrixReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(args[0]), new Path(args[1])); FileOutputFormat.setOutputPath(job, new Path(args[2])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
下面是从http://blog.fens.me/hadoop-mapreduce-matrix/及http://blog.csdn.net/xyilu/article/details/9066973截取的两张图:
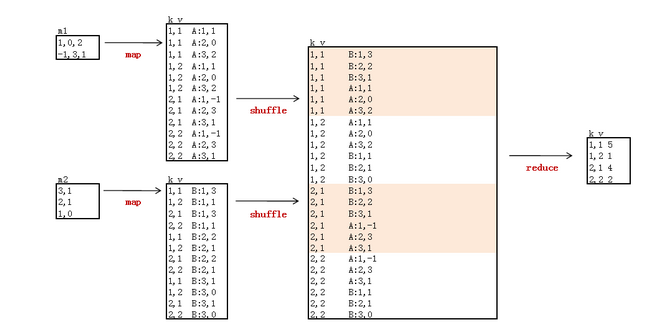
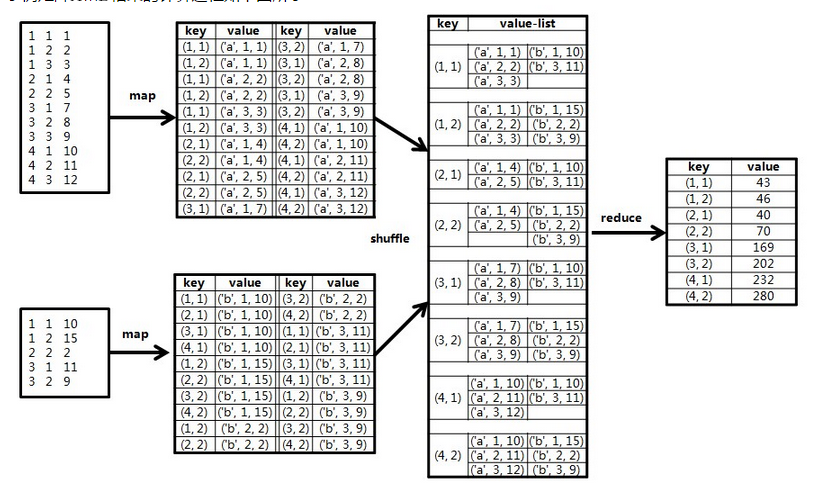

 浙公网安备 33010602011771号
浙公网安备 33010602011771号