从系统的角度分析影响程序执行性能的因素
前言:
博客是对本课程的一个总结,在此感谢孟老师和李老师的悉心教导,在本次Linux操作系统分析课程学习过程中,老师带领着我们先对Linux建立了一个整体的模型架构,然后再由点及面,深入学习Linux的一些关键部分和设计思想,犹如“庖丁解牛”一般,把整个Linux的全局图描绘在大家的脑海中。“天下⼤事必作于细,天下难事必作于易”,表面看起来极其复杂而庞大的Linux系统,如果我们能从简单的地方入手,掌握其设计思想,再去学习,就会容易很多。所以下面我将从一个精简的Linux系统概念模型入手,介绍Linux操作系统。
一、精简的Linux系统概念模型
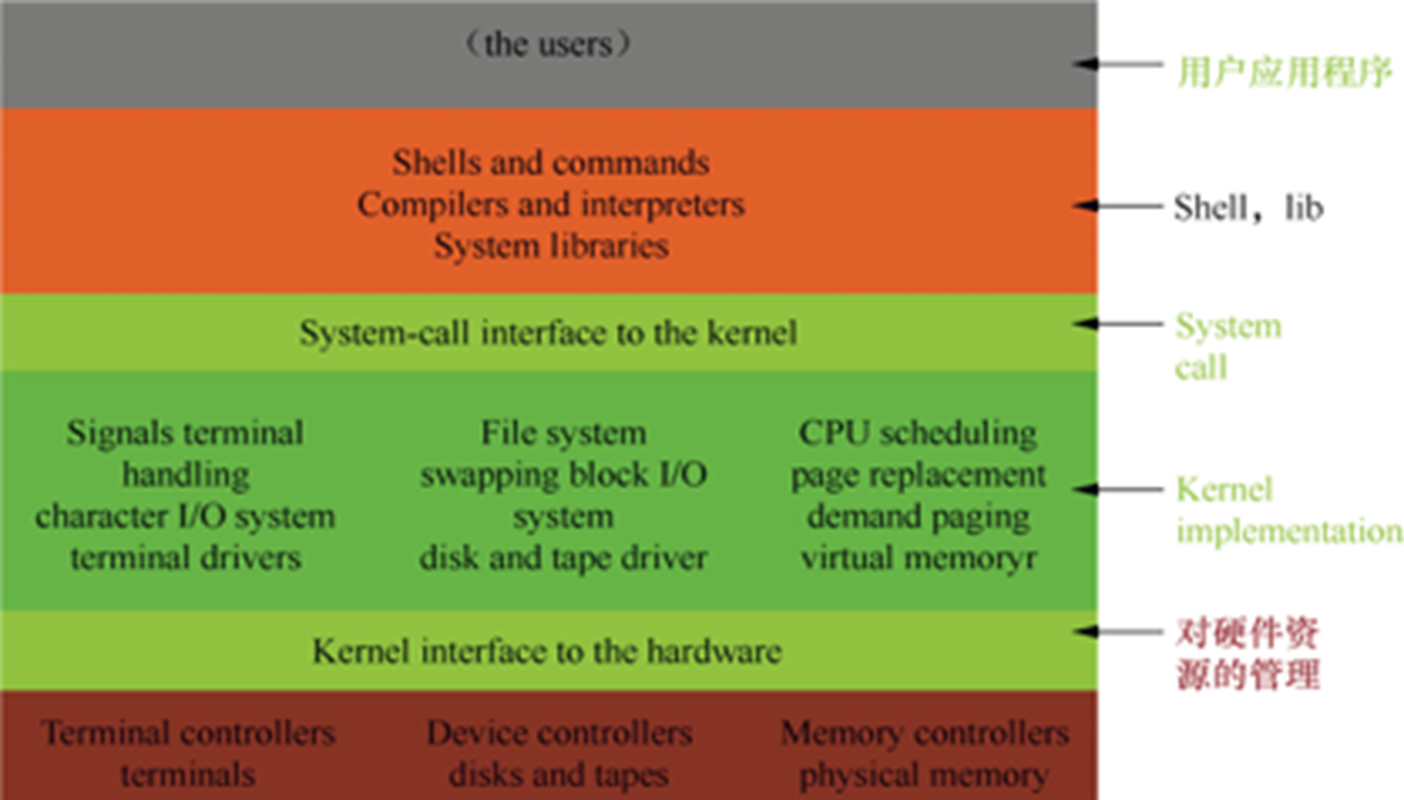
如上图所示,从宏观上来看,Linux操作系统的体系架构分为用户态和内核态。内核从本质上看是一个提供系统服务的程序,并提供上层应用程序运行的环境。用户态即上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源,包括CPU资源、存储资源、I/O资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用。系统调用是操作系统提供给用户的一种服务,程序设计人员在编写程序的时候可以用来请求操作系统的服务。再往底层走,就是内核的一些驱动程序,这些驱动程序往下连接着硬件资源,以便更好的为上层提高服务。
二、举例:对上述精简的模型进行举例说明
拿平常我们经常会碰到的一个例子,文件的读操作,所涉及到的底层系统工作原理。在Linux中,读文件大致可以分为以下几个步骤:
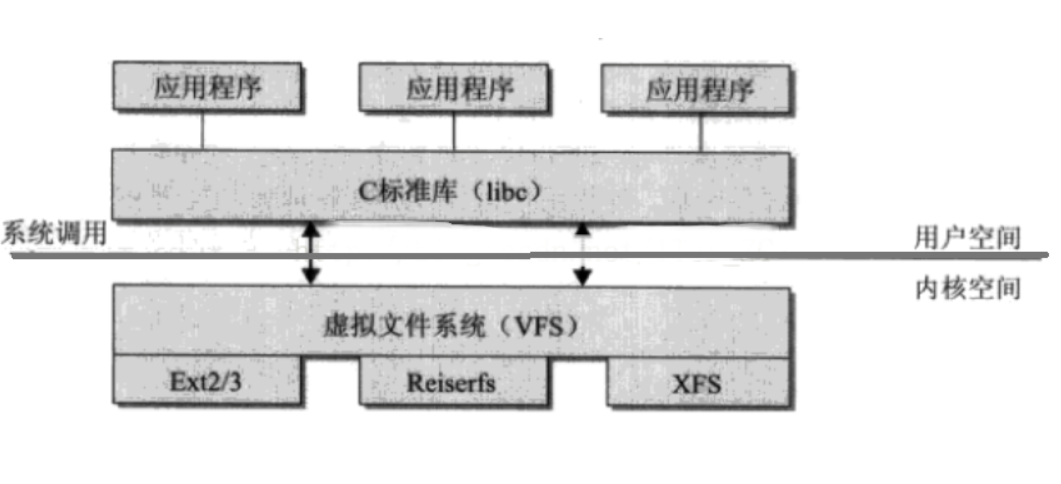
1、进程调用库函数向内核发起读文件请求;
这时会涉及到内陷和系统调用,首先用户会调用读文件的系统调用函数,从用户态内陷到内核态。
2、系统硬件此时会保存中断上下文,即保存现场,其中包括保存相关寄存器的值,进而,根据系统调用号找到对应的系统调用函数
然后,内核通过检查进程的文件描述符定位到虚拟文件系统的已打开文件列表表项;
3、调用该文件可用的系统调用函数read()
也就是说,read()函数在用户处于用户态的时候是没法随意调用的,因为read()函数的使用涉及到操作系统一些重要资源,如果由用户态随意调用,会引发一些系统错误。
4、read()函数通过文件表项链接到目录项模块,根据传入的文件路径,在目录项模块中检索,找到该文件的inode;
在inode中,通过文件内容偏移量计算出要读取的页,通过inode找到文件对应的address_space;
5、在address_space中访问该文件的页缓存树,查找对应的页缓存结点:
(1)如果页缓存命中,那么直接返回文件内容;
(2)如果页缓存缺失,那么产生一个页缺失异常,异常本质上也是一种中断,是一种软中断,然后中断处理函数会创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页;重新进行第6步查找页缓存;
6、文件内容读取完毕后,系统会检查是否需要进程切换,没有的话,系统调用函数就会返回。
接着是中断现场的恢复,将一些寄存器等恢复到中断前的状态。
三、梳理系统模型中影响应用程序性能表现的因素
本案例,通过stress工具来检测影响系统性能的因素,首先安装stress工具:
阶段一:模拟CPU密集型进程
1. 查看当前系统负荷

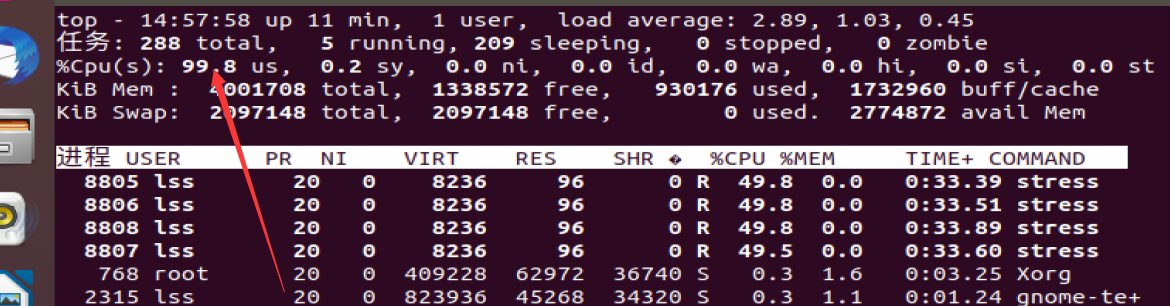
2.然后通过stress -c 4来模拟四个进程

3.观察结果:如下图,发现此时CPU占有率已经非常高了
阶段二:模拟IO和磁盘读写密集型进程
1.下面的命令创建一个进程不断的在磁盘上创建 10M 大小的文件并写入内容:

2. 下面是 iostat 2 的输出,此时 iowait比较高,瓶颈是写磁盘:
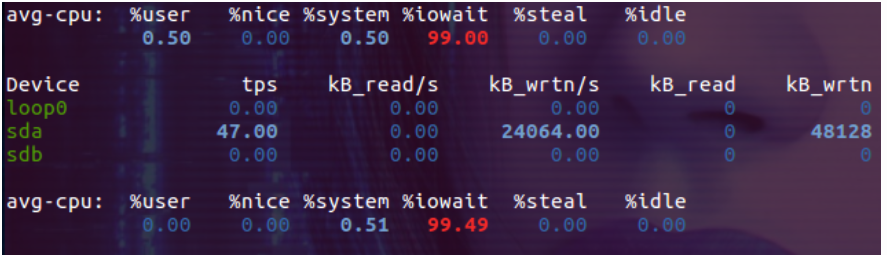
3.使用 top 命令查看 CPU 的状态如下,而此时的 CPU 主要消耗在内核态:

结论:
由上述操作可知,影响应用程序的因素有多种,比如CPU资源的占有率,I/O磁盘读写,内存分配等。
1. 如果系统中CPU密集型进程过多,则此时影响应用程序的瓶颈主要在CPU资源。
2. 如果I/O进程较多,此时影响应用程序的瓶颈主要在IOwait上,即IO等待时间上,但是此时
CPU资源也是有一定的消耗的,如果IO进程无限制的增多,最后CPU资源也会被消耗完,成为
影响应用程序的因素。
四、进一步理解系统调用
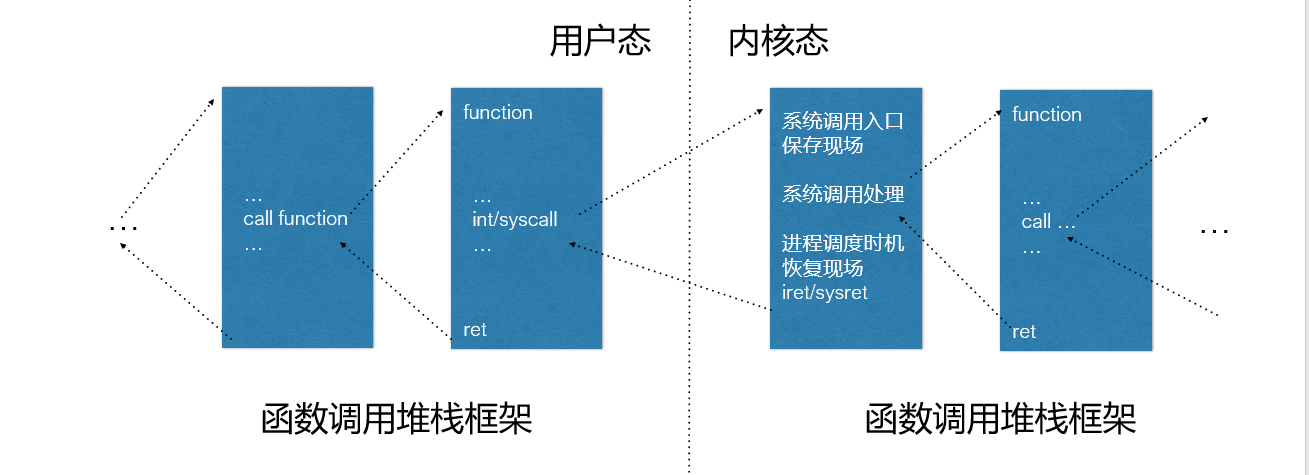
计算机系统的基本⼯作原理总结起来就是计算机有"3⼤法宝"和操作系统有“两把宝剑”,这其中的三大法宝是 存储程序计算机、函数调⽤堆栈、中断,而两大宝剑便是中断上下⽂和进程上下⽂。本节要介绍的系统调用与上述的原理就有很深的渊源。
首先,介绍一下我自己对用户态和内核态的理解:
内核态:进程运行在内核空间;管理系统的所有资源,比如读写磁盘文件,分配回收内存,从网络接口读写数据等等。
用户态:进程运行在用户空间。比如一些应用程序。
内核如何调用硬件资源的:内核空间中的代码控制了硬件资源的使用权。
用户态如何调用硬件资源:用户空间中的代码只有通过内核暴露的系统调用接口(System Call Interface)才能使用到系统中的硬件资源。
户态与内核态的转换:用户态必须切换成内核态才能使用系统资源;
用户态转换成内核态的方法:系统调用,软中断和硬件中断。
系统调用的基本概念:
系统调用其实是一种特殊的中断,中断分外部中断(硬件中断)和内部中断(软件中断),内部中断又称为异常(Exception),异常又分为故障(fault)和陷阱(trap)。系统调用就是利用陷阱(trap)这种软件中断方式主动从用户态进入内核态的。一般来说,从用户态进入内核态是由中断触发的,可能是硬件中断,在用户态进程执行时,硬件中断信号到来,进入内核态,就会执行这个中断对应的中断服务例程。也可能是用户态程序执行过程中,调用了一个系统调用,陷入了内核态,叫作陷阱(trap)(系统调用是特殊的中断)。
五、进程的描述,创建以及进程的切换
我认为这一节也是尤为重要的一个知识点,现在的计算机系统,无论是Linux还是windows等操作系统,都无法绕开这个知识点。下面将从三个方面来介绍关于进程的内容:
进程的描述:
进程的描述有提纲挈领的作用,它可以把内存管理、文件系统、进程间通信等内容串起来,在Linux内核中用一个数据结构struct task_struct来描述进程,它主要包括以下几部分内容:
标示符 : 描述本进程的唯⼀一标⽰示符,⽤用来区别其他进程。
状态 :任务状态,退出代码,退出信号等。
优先级 :相对于其他进程的优先级。
程序计数器:程序中即将被执⾏行的下⼀一条指令的地址。
内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
上下⽂文数据:进程执⾏行时处理器的寄存器中的数据。
I/O状态信息:包括显⽰示的I/O请求,分配给进程的I/O设备和被进程使⽤用的⽂文件列表。
记账信息:可能包括处理器时间总和,使⽤用的时钟数总和,时间限制,记账号等
进程的创建:
在Linux中,init_task为第一个进程(0号进程)的进程描述符结构体变量,它的初始化是通过硬编码方式固定下来的。除此之外,所有其他进程的初始化都是通过do_fork复制父进程的方式初始化的。正所谓“道生一,一生二,二生三”,1号和2号进程的创建是start_kernel初始化到最后由rest_ init通过kernel_thread创建了两个内核线程:一个是kernel_init,最终把用户态的进程init给启动起来,是所有用户进程的祖先;另一个是kthreadd内核线程,kthreadd内核线程是所有内核线程的祖先,负责管理所有内核线程。
说到进程的创建,我们不得不提到一个函数,fork()函数,这是一个非常有用和奇妙的系统调用函数,我们都知道通过fork()系统调用我们可以创建一个和当前进程印象一样的新进程.我们通常将新进程称为子进程,而当前进程称为父进程.而子进程继承了父进程的整个地址空间,其中包括了进程上下文,堆栈地址,内存信息进程控制块(PCB)等。一般的函数调用,只需要返回一次,但是fork()系统调用函数会在父进程返回一次,然后在新创建的子进程中再返回一次。
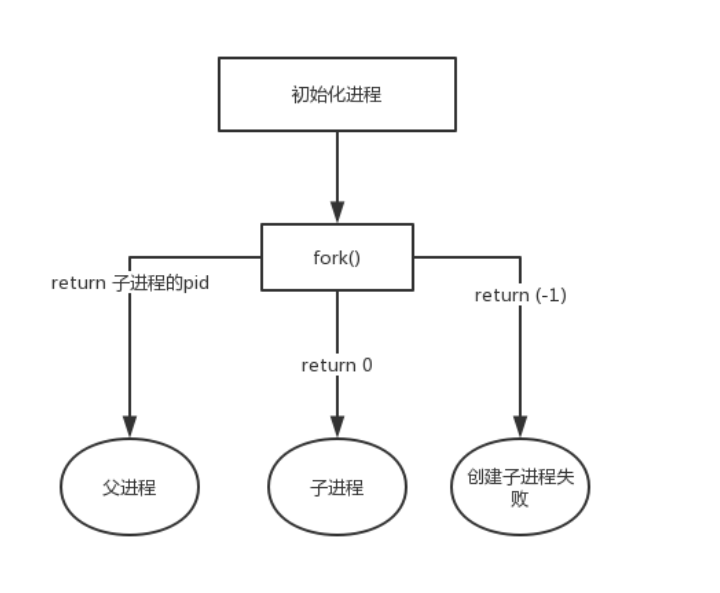
在介绍fork()系统调用函数时,我们需要了解另外一个函数_do_fork()函数,它是真正起到创建一个新进程的关键函数,以下是_do_fork()函数的主要步骤: 如果把进程的创建比作生育一个孩子的话,那么
1. dup_task_struct()函数的执行就类似与基因的复制,dup_task_struct()函数会负责把父进程的进程描述符等相关信息复制给子进程,当然,这里并不是完全复制,而是先复制一份,然后再修改其中的信息,比如进程的pid肯定是要进行修改的。
2. 然后,copy_thread_tls vs. copy_thread就类似与传授子进程生存的技能,用于适应社会,在Linux中,copy_thread_tls vs. copy_thread主要负责把父进程中的内核堆栈信息传递给子进程。
3. wake_up_new_task类似于子进程学会了生存本领,准备踏入到社会中开始奋斗。在Linux中,wake_up_new_task代表子进程已经创建完毕,加入到了等待队列中,等待CPU的调度。
进程的切换:
首先介绍一下,进程切换到的时机,先从中断说起,因为进程调度的时机很多都与中断相关。从用户程序的角度看进程调度的时机一般都是中断处理后和中断返回前的时机点进行,只有内核线程可以直接调用schedule函数主动发起进程调度和进程切换。中断处理后,会检查一下是否需要进程调度。需要则切换进程(本质上是切换两个进程的内核堆栈和thread),不需要则一路顺着函数调用堆栈正常中断返回iret,这样就自然回到原进程继续运行了。简单总结一下进程调度时机。
1. 用户进程上下文中主动调用特定的系统调用进入中断上下文,系统调用返回用户态之前进行进程调度。
2. 内核线程或可中断的中断处理程序,执行过程中发生中断进入中断上下文,在中断返回前进行进程调度。
3. 内核线程主动调用schedule函数进行进程调度。
然后,介绍进程切换的一个关键函数switch_to(), 以下是switch的关键代码以及注释:
Pushfl //sava flags
pushl %ebp //s0 准备工作
prev->thread.sp=%esp //s1
%esp=next->thread.sp //s2
prev->thread.ip=$1f //s3
push next->thread.ip //s4
jmp _switch_to //s5
1f:
popl %%ebp //s6,与s0对称,重置%ebp
Popfl //重置flags
六、总结
通过本科Linux课程的学习,使我对Linux操作系统有了一个全面的理解。这其中包括,Linux操作系统的基本工作原理,Linux操作系统的系统调用,进程的描述和进程的创建,以及可执行程序的工作原理。除此之外,在课程中,老师带领我们对linux的一些源码进行了学习,使我明白了可执行程序的工作原理,以及程序的编译调试和启动过程。任何复杂的系统必然是由简单的东西堆砌而成的,所以只要我们抓住系统的整体架构,就可以如“庖丁解牛”般的学习整个系统了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号