Adaboost算法流程及示例
1. Boosting提升方法(源自统计学习方法)
提升方法是一种常用的统计学习方法,应用十分广泛且有效。在分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能。提升算法基于这样一种思路:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家独断的判断好。实际上,就是“三个臭皮匠顶个诸葛亮”的道理。
历史上,Kearns和Valiant首先提出了“强可学习(Strongly learnable)”和“弱可学习(Weekly learnable)”的概念。支出:在概率近似正确(probably approximately correct,PAC)学习框架中,一个概念(一个分类),如果存在一个多项式的学习算法能够学习它,并且正确率很好,那么就称这个概念是强可学习的;一个概念(一个分类),如果存在一个多项式的学习算法能够学习它,但学习的正确率仅比随机猜测略好,那么就称这个概念是弱可学习的。非常有趣的是Schapire后来证明强可学习与弱可学习是等价的,也就是说,在PAC学习框架下,一个概念是强可学习的充要条件是这个概念是弱可学习的。
这样一来,问题便成为,在学习中,如果已经发现了“弱学习算法”,那么能否将它提升(boost)为“强学习算法”。大家知道,发现弱学习算法通常要比发现强学习算法容易得多。那么如何具体实施提升,便成为开发提升方法时所要解决的问题。关于提升方法的研究很多,有很多算法被提出,最具代表性的是AdaBoost算法(Adaboost algorithm)。
对与分类问题而言,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确的分类规则(强分类器)容易得多。提升方法就是从弱学习算法出发,反复学习,得到一系列分类器,然后组合这些分类器,构成一个强分类器。
这样,对于提升算法来说,有两个问题需要回答:一是在每一轮如何改变训练数据的权值分布;二是如何将弱分类器组合成一个强分类器。
Boosting算法要涉及到两个部分,加法模型和前向分步算法。
(1) 加法模型就是说强分类器由一系列弱分类器线性相加而成。一般组合形式如下:
$F_M(x;P)=\sum_{m=1}^n\alpha _mh(x;\theta_m)$
其中$h(x;\theta_m)$是一个个的弱分类器,$\theta_m$是弱分类器学习到的最优参数;$\alpha_m$就是若学习在强分类器中所占的比重;$P$是所有$\alpha_m$和$\theta_m$的组合。这些弱分类器线性相加组成强分类器。
(2) 前向分布就是说在训练过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的。也就是可以协成这样的形式:
$F_m (x)=F_{m-1}(x)+\alpha _mh(x;\theta_m)$
由于采用的损失函数不同,Boosting算法也因此有了不同的类型,AdaBoost就是损失函数为指数损失的Boosting算法。
2. Adaboost算法
Adaboost算法思想:
1) 提高那些被前一轮弱分类器错误分类的样本的权值,降低那些被正确分类的样本的权值;
2) 采用加权多数表决的方法。具体的,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用;减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
Adaboost算法流程:
输入:训练数据集$T=\{(x_1, y_1),(x_2, y_2),(x_3, y_3),...(x_n, y_n)\}$,其中$x_i\in X\subseteq \mathbb{R}^{n},y_i\in Y=\{-1,+1\}$,$Y=\{-1, +1\}$是弱分类算法。
输出:最终分类器$G_m(x)$
初始化:假定第一次训练时,样本均匀分布权值一样。
$D_1=(w_{11}, w_{12},w_{13}......w_{1n})$
其中$w_{1i}=\frac{1}{n},i=1,2,3...n$
循环:m=1,2,3...M,
(a) 使用具有权值分布$D_m$的训练数据集学习,得到基本分类器$G_m$(选取让误差率最低的阈值来设计基本分类器):
$G_m(x):\chi \rightarrow \{-1, +1\}$
(b) 计算$G_m(x)$在训练集上的分类误差率$e_m$
$e_m=P(G_m(x_i)\neq y_i)=\sum_{i=1}^{n}w_{mi}I(G_m(x_i)\neq y_i)$
$I(G_m(x_i)\neq y_i)$:当$G_m(x_i)$与$y_i$相等时,函数取值为0;当$G_m(x_i)$与$y_i$不相等时,取值为1;。
由上述式子可知,$G_m(x)$在训练数据集上的误差率$e_m$就是被$G_m(x)$误分类样本的权值之和。
(c) 计算$G_m(x)$的系数$\alpha_m$,$\alpha_m$表示$G_m(x)$在最终分类器中的重要程度:
$\alpha_m = \frac{1}{2}ln\frac{1-e_m}{e_m}$
【注】显然$e_m <= 1/2$时,$\alpha_mam >= 0$,且$\alpha_m$随着$e_m$的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大
此时分类器为:$f_m(x)=\alpha_mG_m(x)$
(d) 更新训练数据集的权值分布,用于下一轮迭代。
$D_{m+1}=(w_{m+1,1},w_{m+1,2},w_{m+1,3},...w_{m+1,n})$
$w_{m+1,i}=\frac{w_{mi}}{Z_m}exp(-y_i\alpha_mG_m(x_i))$,$i=1,2,3,...n$
其中$Z_m$是规范化因子,使得$D_{m+1}$成为一个概率分布。
$Z_m=\sum_{i=1}^{n}w_{mi}exp(-y_i\alpha_mG_m(x_i))$
循环结束条件:
$e_m$小于某个阈值(一般是0.5),或是达到最大迭代次数。
AdaBoost 方法中使用的分类器可能很弱(比如出现很大错误率),但只要它的分类效果比随机好一点(比如两类问题分类错误率略小于0.5),就能够改善最终得到的模型。
组合分类器:
$f(x)=\sum_{m=1}^{M}\alpha_mG_m(x)$
最终分类器:
$G_m(x)=sign(f(x))=sign(\sum_{i=1}^{M}\alpha_mG_m(x))$
3. Adaboost示例
假定给出下列训练样本。
| 序号 | i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
初始化:$w_{1i}=\frac{1}{n}=0.1$,n=10(样本个数)
| 序号 |
i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 初始权值 | $w_{1i}$ | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
阈值猜测:观察数据,可以发现数据分为两类:-1和1,其中数据“0,1,2”对应“1”类,数据“3,4,5”对应“-1”类,数据“6,7,8”对应“1”类,数据“9”对应“"1”类。抛开单个的数据“9”,可以找到对应的数据分界点(即可能的阈值),比如:2.5、5.5、8.5(一般0.5的往上加,也可以是其他数)。然后计算每个点的误差率,选最小的那个作为阈值。
但在实际操作中,可以每个数据点都做为阈值,然后就算误差率,保留误差率最小的那个值。若误差率有大于0.5的就取反(分类换一下,若大于取1,取反后就小于取1),再计算误差率。
迭代过程1:m=1
1> 确定阈值的取值及误差率
- 当阈值取2.5时,误差率为0.3。即 x<2.5 时取 1,x>2.5 时取 -1,则数据6、7、8分错,误差率为0.3(简单理解:10个里面3个错的,真正误差率计算看下面的表格 )
- 当阈值取5.5时,误差率最低为0.4。即 x<5.5 时取1,x>5.5 时取 -1,则数据3、4、5、6、7、8分错,错误率为0.6>0.5,故反过来,令 x>5.5 取 1,x<5.5 时取 -1,则数据0、1、2、9分错,误差率为0.4
- 当阈值取8.5时,误差率为0.3。即 x<8.5 时取1,x>8.5 时取 -1,则数据3、4、5分错,错误率为0.3
由上面可知,阈值取2.5 或8.5时,误差率一样,所以可以任选一个作为基本分类器。这里选2.5为例。
$G_1(x)=\begin{cases}1, &x<2.5 \\-1, & x>2.5 \end{cases}$
计算误差率:
| 序号 | i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 分类器结果 | $G_1(x)$ | 1 | 1 | 1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 |
| 分类结果 | 对 | 对 | 对 | 对 | 对 | 对 | 错 | 错 | 错 | 对 |
从上可得$G_1(x)$在训练数据集上的误差率(被分错类的样本的权值之和):
$e_1=P(G_1(x_i)\neq y_i)=\sum_{G_1(x_i)\neq y_i}w_{1i}=0.1+0.1+0.1=0.3$
2> 计算$G_1(x)$的系数:
$\alpha_1=\frac{1}{2}ln\frac{1-e_1}{e_1}=\frac{1}{2}ln\frac{1-0.3}{0.3}\approx 0.42365$
这个$\alpha_1$代表$G_1(x)$在最终的分类函数中所占的比重约为0.42365
3> 分类函数
$f_1(x)=\alpha_1G_1(x)=0.42365G_1(x)$
4> 更新权值分布:
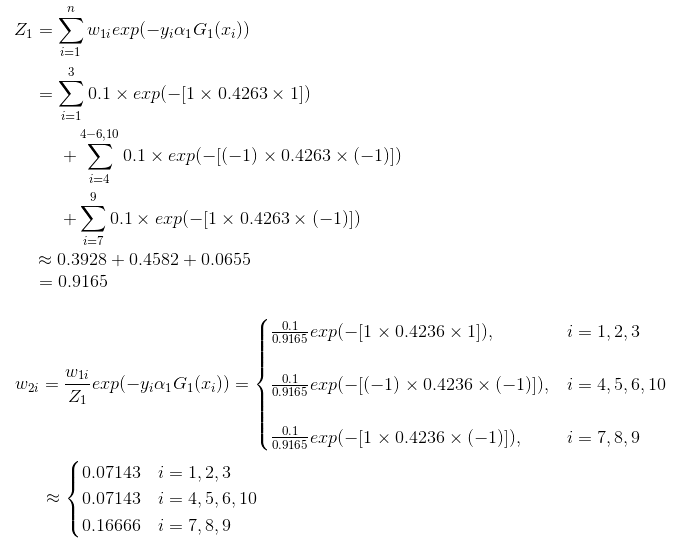
| 序号 |
i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 初始权值1 | $w_{1i}$ | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| 更新权值2 | $w_{2i}$ | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.16666 | 0.16666 | 0.16666 | 0.07143 |
由上面可以看出,因为数据“6,7,8”被$G_1(x)$分错了,所以它们的权值由初始的0.1增大到了0.16666;其他的数据由于被分对了,所以权值由0.1减小到0.07143。
迭代过程2:m=2
1> 确定阈值的取值及误差率
- 当阈值取2.5时,误差率为0.49998。即 x<2.5 时取 1,x>2.5 时取 -1,则数据6、7、8分错,误差率为0.16666*3(取过,不列入考虑范围)
- 当阈值取5.5时,误差率最低为0.28572。即 x<5.5 时取1,x>5.5 时取 -1,则数据3、4、5、6、7、8分错,错误率为0.07143*3+0.16666*3=0.71427>0.5,故反过来,令 x>5.5 取 1,x<5.5 时取 -1,则数据0、1、2、9分错,误差率为0.07143*4=0.28572
- 当阈值取8.5时,误差率为0.21429。即 x<8.5 时取1,x>8.5 时取 -1,则数据3、4、5分错,错误率为0.07143*3=0.21429
由上面可知,阈值取8.5时,误差率最小,所以:
$G_2(x)=\begin{cases}1, &x<8.5 \\-1, & x>8.5 \end{cases}$
计算误差率:
| 序号 | i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 权值分布 | $w_{2i}$ | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.16666 | 0.16666 | 0.16666 | 0.07143 |
| 分类器结果 | $G_2(x)$ | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | -1 |
| 分类结果 | 对 | 对 | 对 | 错 | 错 | 错 | 对 | 对 | 对 | 对 |
从上可得$G_2(x)$在训练数据集上的误差率(被分错类的样本的权值之和):
$e_2=P(G_2(x_i)\neq y_i)=\sum_{G_2(x_i)\neq y_i}w_{2i}=0.07143+0.07143+0.07143=0.21429$
2> 计算$G_2(x)$的系数:
$\alpha_2=\frac{1}{2}ln\frac{1-e_2}{e_2}=\frac{1}{2}ln\frac{1-0.21429}{0.21429}\approx 0.64963$
这个$\alpha_2$代表$G_2(x)$在最终的分类函数中所占的比重约为0.649263
3> 分类函数
$f_2(x)=\alpha_2G_2(x)=0.64963G_2(x)$
4> 更新权值分布:

| 序号 |
i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 初始权值1 | $w_{1i}$ | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| 权值2 | $w_{2i}$ | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.16666 | 0.16666 | 0.16666 | 0.07143 |
| 更新权值3 | $w_{3i} | 0.04546 | 0.04546 | 0.04546 | 0.16667 | 0.16667 | 0.16667 | 0.10606 | 0.10606 | 0.10606 | 0.04546 |
迭代过程3:m=3
1> 确定阈值的取值及误差率
- 当阈值取2.5时,误差率为0.31818。即 x<2.5 时取 1,x>2.5 时取 -1,则数据6、7、8分错,误差率为0.10606*3=0.31818(取过,不列入考虑范围)
- 当阈值取5.5时,误差率最低为0.18184。即 x<5.5 时取1,x>5.5 时取 -1,则数据3、4、5、6、7、8分错,错误率为0.16667*3+0.10606*3=0.81819>0.5,故反过来,令 x>5.5 取 1,x<5.5 时取 -1,则数据0、1、2、9分错,误差率为0.04546*4=0.18184
- 当阈值取8.5时,误差率为0.13638。即 x<8.5 时取1,x>8.5 时取 -1,则数据3、4、5分错,错误率为0.04546*3=0.13638(取过,不列入考虑范围)
由上面可知,阈值取8.5时,误差率最小,但8.5取过了,所以取5.5:
$G_3(x)=\begin{cases}-1, &x<5.5 \\1, & x>5.5 \end{cases}$
计算误差率:
| 序号 | i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 权值分布 | $w_{3i}$ | 0.04546 | 0.04546 | 0.04546 | 0.16667 | 0.16667 | 0.16667 | 0.10606 | 0.10606 | 0.10606 | 0.04546 |
| 分类器结果 | $G_3(x)$ | -1 | -1 | -1 | -1 | -1 | -1 | 1 | 1 | 1 | 1 |
| 分类结果 | 错 | 错 | 错 | 对 | 对 | 对 | 对 | 对 | 对 | 错 |
从上可得$G_3(x)$在训练数据集上的误差率(被分错类的样本的权值之和):
$e_3=P(G_3(x_i)\neq y_i)=\sum_{G_3(x_i)\neq y_i}w_{3i}=0.04546+0.04546+0.04546+04546=0.18184$
2> 计算$G_3(x)$的系数:
$\alpha_3=\frac{1}{2}ln\frac{1-e_3}{e_3}=\frac{1}{2}ln\frac{1-0.18188}{0.18184}\approx 0.75197$
这个$\alpha_3$代表$G_3(x)$在最终的分类函数中所占的比重约为0.75197
3> 分类函数
$f_3(x)=\alpha_3G_3(x)=0.75197G_3(x)$
4> 更新权值分布:

| 序号 |
i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 数据 | x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 类别标签 | y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
| 初始权值1 | $w_{1i}$ | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| 权值2 | $w_{2i}$ | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.07143 | 0.16666 | 0.16666 | 0.16666 | 0.07143 |
| 权值3 | $w_{3i} | 0.04546 | 0.04546 | 0.04546 | 0.16667 | 0.16667 | 0.16667 | 0.10606 | 0.10606 | 0.10606 | 0.04546 |
| 更新权值4 | $w_{4i} | 0.12500 | 0.12500 | 0.12500 | 0.10185 | 0.10185 | 0.10185 | 0.06481 | 0.06481 | 0.06481 | 0.12500 |
迭代过程4:m=4
此时观察数据,每次迭代被分错的数据都已经重新分配过权值,按其他参考资料来说,此时的误差率为0,所以迭代可以到此结束。
最终分类器:
$G_m(x)=sign(0.42365G_1(x)+0.64963G_2(x)0.75197G_3(x))$
---------------------
参考文献:
原文:https://blog.csdn.net/gyqjn/article/details/45501185


 浙公网安备 33010602011771号
浙公网安备 33010602011771号