

数据采集实践大项目
注:由于models较大,无法直接上传到git中,我们将models上传至github上。若需要运行系统请点击.gitattributes,使用git lfs依次将相应文件下载到本地并存放在相应文件夹中,位置如.gitattributes中链接所示。
github链接:https://github.com/liuliuliuliu617-maker/-/tree/master
(一)项目准备:
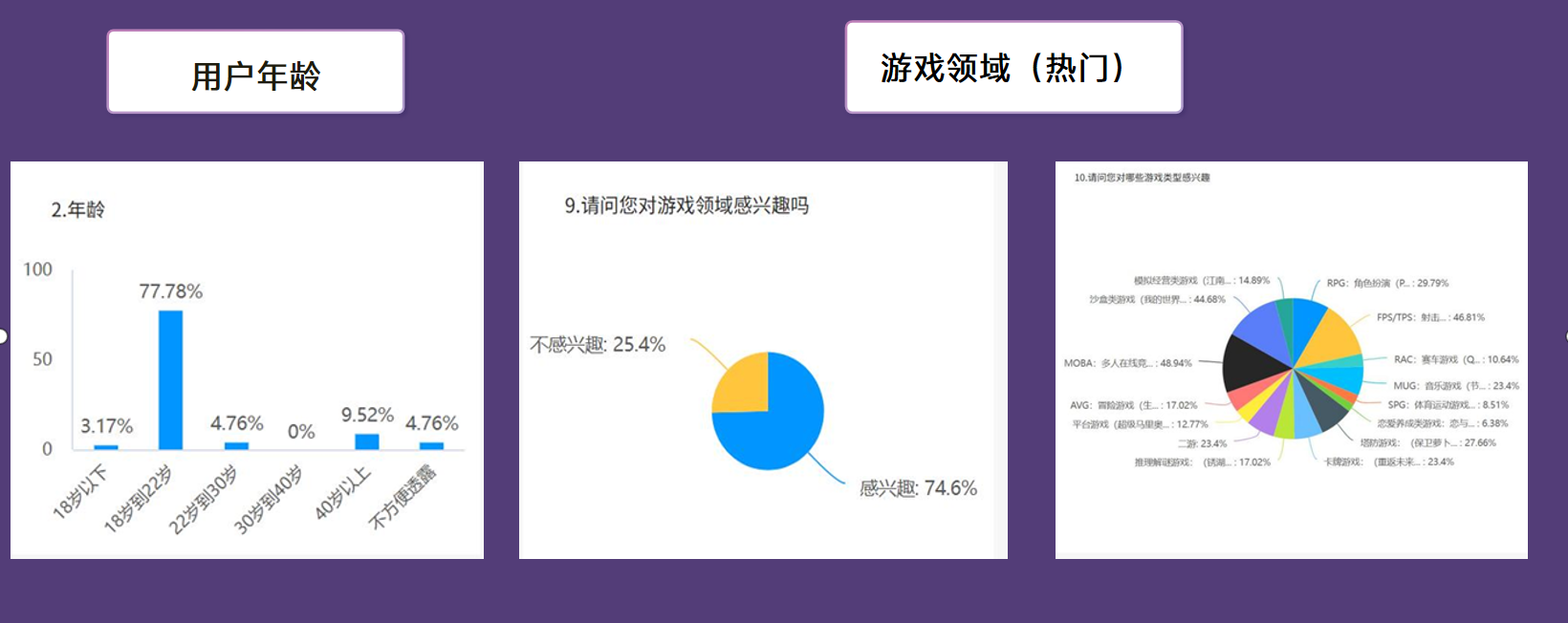
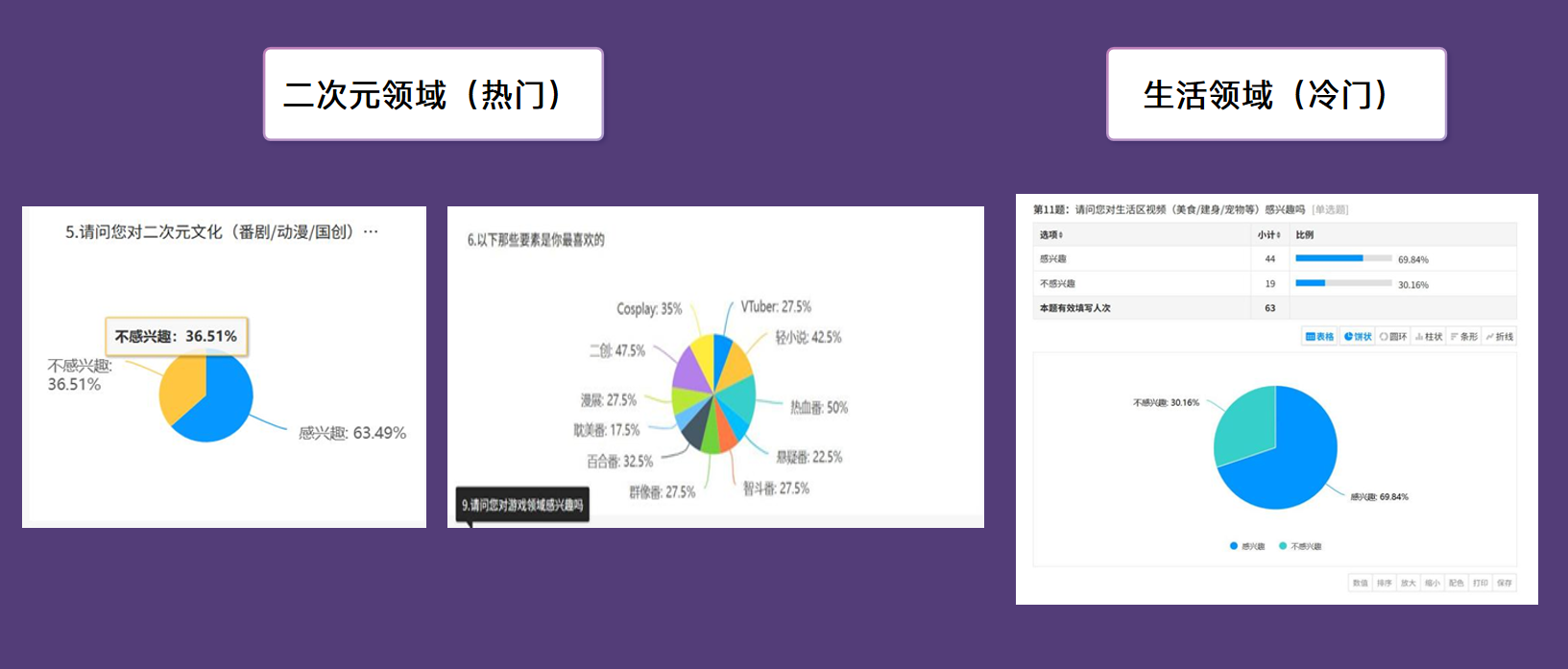
我们使用问卷星对项目用户群体进行调研,覆盖面广,目标用户明确,分别调研出用户年龄和使用领域,并对热门领域(如游戏邻域)进行细分,为接下来我们将对这些领域依次进行模型训练进行准备。
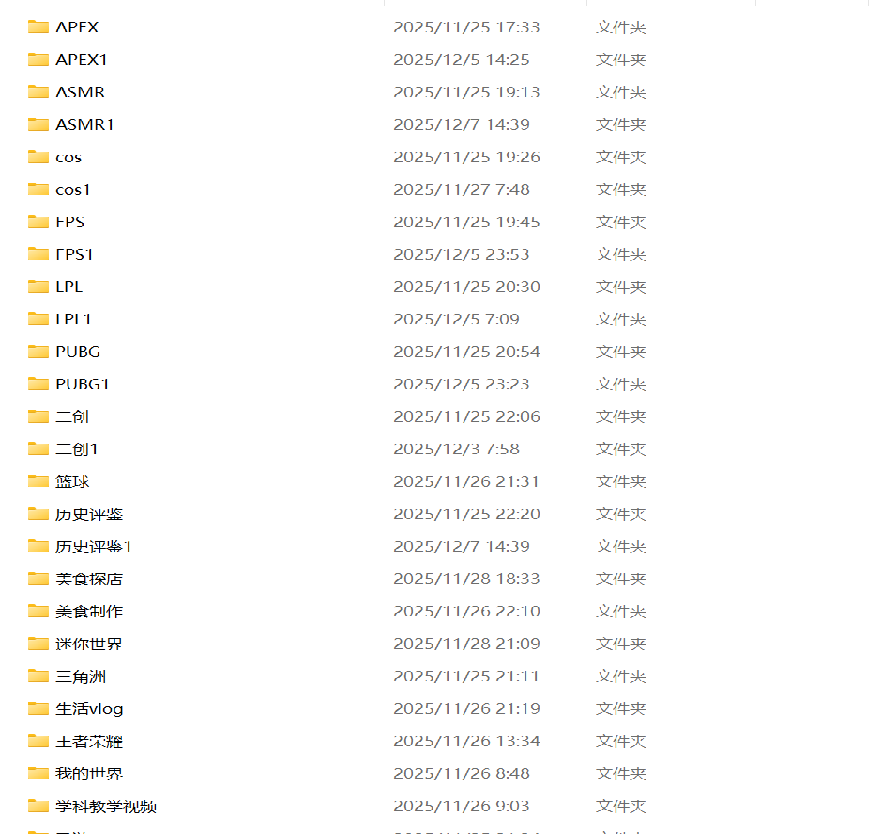
这些文件夹是我们从多平台爬取的评论,包含其内部的表情包等图片信息。每一个文件夹下面都有至少1000条数据,为接下来我们搭建训练评论分类模型做准备。
(二)系统搭建:
为了让模型训练有个好的结果,我们将Qwen2.5-3B-instruct模型部署到本地,并加入我们之前爬取的评论数据对大模型进行微调,接下来是我们的相应代码:
1. --Qwen2.5_train.py: 模型训练代码,可使用本地数据对模型进行训练
我们采用以下方法进行训练:
(1)LoRA(Low-Rank Adaptation)方法:
该代码通过集成LoRA配置,在预训练模型上进行微调。LoRA是一种高效的参数调整方法,通过引入低秩矩阵来减少微调时的参数量。

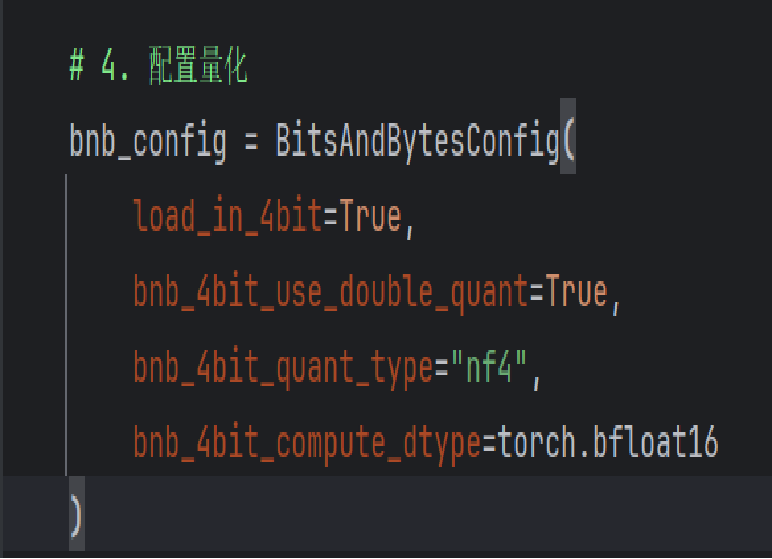
(2)量化(Quantization):
在模型加载时,代码配置了量化选项(使用4位量化)。这使得模型在训练时可以节省显存,同时加速推理过程,尤其对于大规模语言模型(如3B参数量的Qwen2.5)而言,量化是重要的优化手段。
2. --pinglun: 前端代码文件夹,使用了一个基于 React 和 React Router 的前端应用结构。主要功能包括登录、注册、用户中心、评论概览等模块,每个功能通过独立的组件进行管理。使用 React Router 实现页面导航,使得在单页应用中可以动态加载不同页面,提升用户体验。组件化设计使得每个模块独立且可复用,便于维护和扩展。每个组件配有独立的 CSS 文件,实现样式的局部管理,避免样式冲突。通过 Navigate 组件实现路径重定向,确保访问根路径时会自动跳转到登录页。使用时请确保使用pycharm打开并在本地下载node.js
3.--models:模型存放处
4.后端:****
--db.py :所有数据库访问逻辑(用户、视频、评论、关键词、v_cnt 统计)。
--server.py :Flask 服务入口,登录/注册接口、爬取接口 /api/process、关键词接口 /api/keywords、用户视频管理接口 /api/user/videos、/api/user/video_comments,以及页面路由。
--back.sql:数据库 back 的表结构(user / video / comments / keyword),要和db.py配套。
--预测.py:加载本地 Qwen 模型并对评论进行分类(结合关键词规则和大模型),输出类别 ID 和中文标签,供后端入库和展示使用。
5.华为云平台部署:
(1)云端服务器部署:
(2)启动数据库并创建back数据库
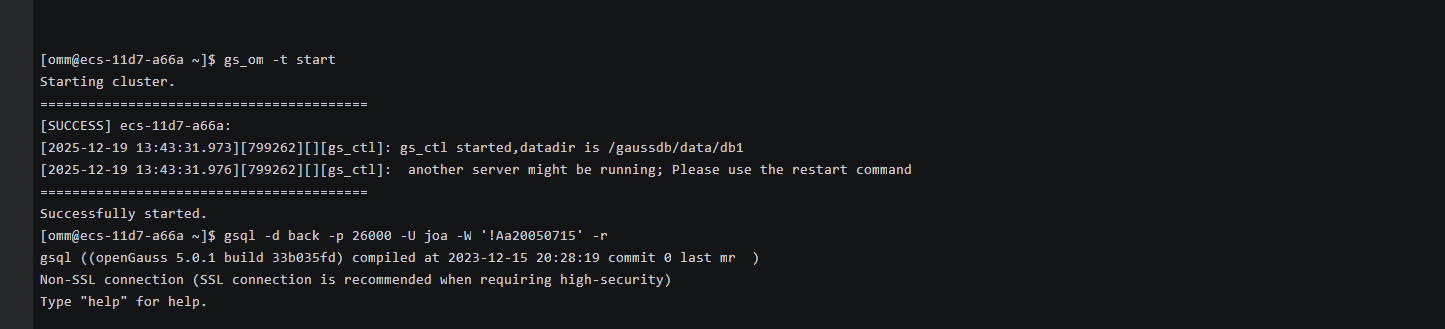
(3)创建comments,keyword,users,video表(之前创建的没截图,这里直接显示我们之前创建的)
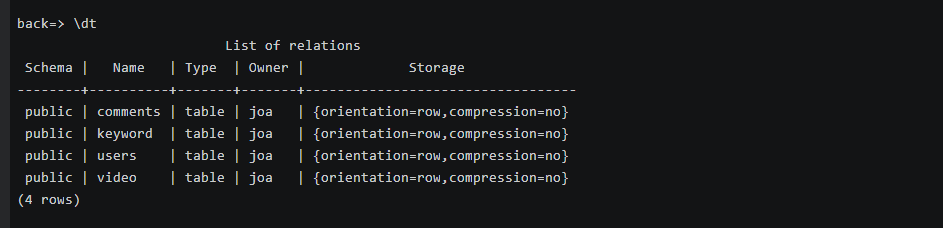
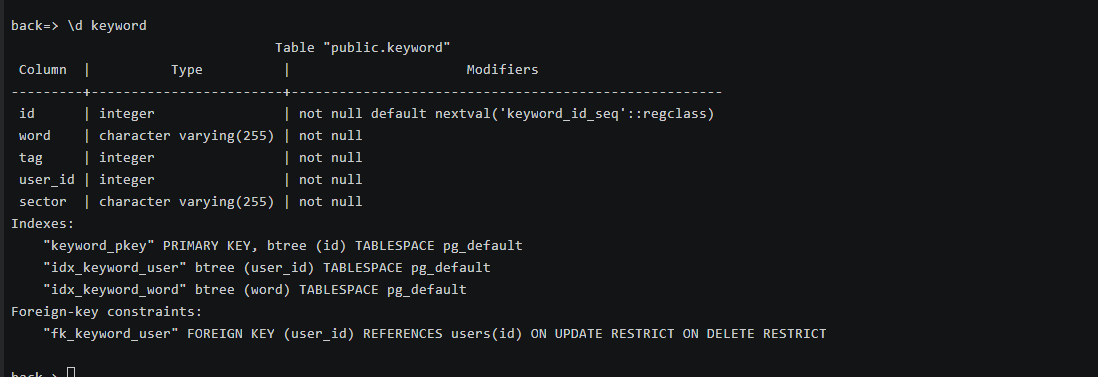
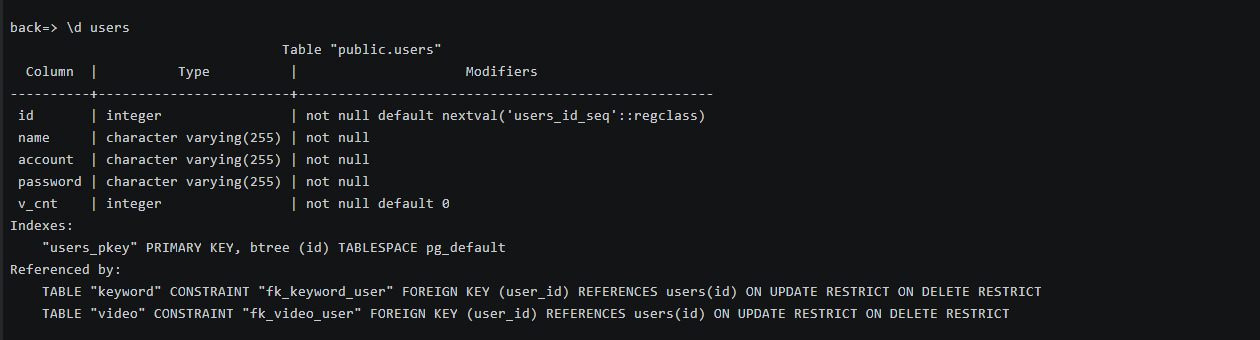
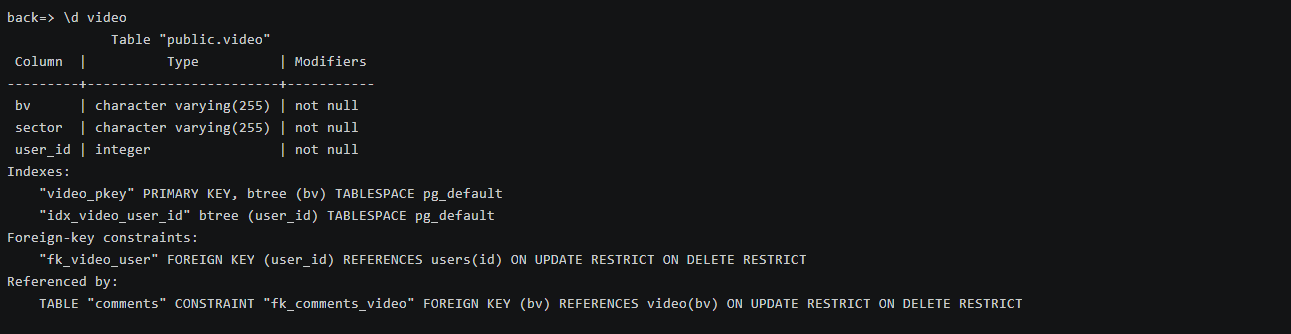
(4)创建各表信息:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号