
作业4
作业①:
要求: 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board 输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,调用库函数
1.selenium:模拟真实用户打开浏览器、渲染页面,并从渲染好的 HTML 中提取数据2.time:主要用于 time.sleep(),给网页渲染留出缓冲时间,同时也起到一定的防反爬作用
3.mysql.connector:用于 Python 与 MySQL 数据库之间的通信
实验思路
1.环境准备与数据库初始化:浏览器与数据库配置,设置数据库列名点击查看代码
# --- MySQL 数据库配置--
SERVER_CONFIG = {
'host': 'localhost',
'user': 'root',
'password': '123iop12',
}
TARGET_DB_NAME = 'stock_db'
TARGET_TABLE_NAME = 'stock_data'
DB_CONFIG_FOR_CRAWLER = {
'host': 'localhost',
'user': 'root',
'password': '123iop12',
'database': TARGET_DB_NAME,
'charset': 'utf8mb4'
}
# --- 数据库操作函数---
def create_database_and_table():
conn = None
try:
conn = mysql.connector.connect(**SERVER_CONFIG)
if conn.is_connected():
cursor = conn.cursor()
try:
cursor.execute(
f"CREATE DATABASE IF NOT EXISTS {TARGET_DB_NAME} CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;")
print(f"数据库 '{TARGET_DB_NAME}' 已创建或已存在。")
except Error as err:
print(f"创建数据库 '{TARGET_DB_NAME}' 失败: {err}")
return False
cursor.execute(f"USE {TARGET_DB_NAME};")
print(f"已切换到数据库 '{TARGET_DB_NAME}'。")
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {TARGET_TABLE_NAME} (
id INT AUTO_INCREMENT PRIMARY KEY,
boardName VARCHAR(50) NOT NULL COMMENT '板块名称,例如:沪深A股, 上证A股, 深证A股',
bStockNo VARCHAR(10) NOT NULL COMMENT '股票代码',
bStockName VARCHAR(50) NOT NULL COMMENT '股票名称',
latestPrice DECIMAL(10, 3) COMMENT '最新报价',
changeRate DECIMAL(8, 2) COMMENT '涨跌幅 %',
changeAmount DECIMAL(10, 3) COMMENT '涨跌额',
tradeVolume VARCHAR(50) COMMENT '成交量',
tradeAmount VARCHAR(50) COMMENT '成交额',
amplitude DECIMAL(8, 2) COMMENT '振幅 %',
highestPrice DECIMAL(10, 3) COMMENT '最高',
lowestPrice DECIMAL(10, 3) COMMENT '最低',
openPrice DECIMAL(10, 3) COMMENT '今开',
prevClosePrice DECIMAL(10, 3) COMMENT '昨收',
crawlTime DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '爬取时间',
UNIQUE KEY (bStockNo, boardName, crawlTime)
);
"""
try:
cursor.execute(create_table_sql)
print(f"表 '{TARGET_TABLE_NAME}' 已创建或已存在。")
except Error as err:
print(f"创建表 '{TARGET_TABLE_NAME}' 失败: {err}")
return False
try:
cursor.execute(f"CREATE INDEX idx_bStockNo ON {TARGET_TABLE_NAME} (bStockNo);")
cursor.execute(f"CREATE INDEX idx_boardName ON {TARGET_TABLE_NAME} (boardName);")
cursor.execute(f"CREATE INDEX idx_crawlTime ON {TARGET_TABLE_NAME} (crawlTime);")
print("索引已添加或已存在。")
except Error as err:
if "Duplicate entry" in str(err) or "already exists" in str(err) or "Duplicate key name" in str(err):
print(f"索引已存在 (警告): {err}")
else:
print(f"添加索引失败: {err}")
return True
except Error as e:
print(f"连接MySQL或执行数据库操作失败: {e}")
return False
finally:
if conn and conn.is_connected():
cursor.close()
conn.close()
def connect_db():
try:
conn = mysql.connector.connect(**DB_CONFIG_FOR_CRAWLER)
return conn
except mysql.connector.Error as err:
print(f"Error connecting to MySQL: {err}")
return None
def insert_stock_data(cursor, stock_data):
sql = """
INSERT INTO stock_data (boardName, bStockNo, bStockName, latestPrice, changeRate, changeAmount,
tradeVolume, tradeAmount, amplitude, highestPrice, lowestPrice,
openPrice, prevClosePrice, crawlTime)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
boardName = VALUES(boardName),
bStockName = VALUES(bStockName),
latestPrice = VALUES(latestPrice),
changeRate = VALUES(changeRate),
changeAmount = VALUES(changeAmount),
tradeVolume = VALUES(tradeVolume),
tradeAmount = VALUES(tradeAmount),
amplitude = VALUES(amplitude),
highestPrice = VALUES(highestPrice),
lowestPrice = VALUES(lowestPrice),
openPrice = VALUES(openPrice),
prevClosePrice = VALUES(prevClosePrice),
crawlTime = VALUES(crawlTime);
"""
try:
cursor.execute(sql, stock_data)
return True
except mysql.connector.Error as err:
print(f"Error inserting data: {err}")
print(f"Data causing error: {stock_data}")
return False
2.爬取主循环:
(1)遍历 BOARD_MAP 中定义的三个板块(沪深A股、上证A股、深证A股)通过哈希(#)切换板块。并使用 WebDriverWait 等待
(2)数据提取:定位表格中的每一行 (tr),提取每一列 (td) 的文本(由F12可知数据在td元素中,如之前作业),并使用 parse_price 函数处理无效数据(如 '-' 或 'nan')
(3)翻页逻辑:代码循环执行抓取。当一页抓取完后,它会寻找“下一页”按钮(XPath 定位 title='下一页',如图所示),使用Selenium 点击按钮。

点击查看代码
def crawl_board(board_name, board_hash, driver_instance):
"""
爬取指定板块的股票数据。
"""
print(f"--- 开始爬取 {board_name} ---")
full_url = f"{BASE_URL}{board_hash}"
driver_instance.get(full_url)
# --- XPath Selector ---
TABLE_CONTAINER_XPATH = "//div[@class='quotetable']"
TABLE_BODY_XPATH = f"{TABLE_CONTAINER_XPATH}/table/tbody"
PAGINATE_CONTAINER_XPATH = f"{TABLE_CONTAINER_XPATH}/div[@class='qtpager']"
# 延长等待时间并添加更精确的等待条件
try:
# 等待表格tbody元素出现
WebDriverWait(driver_instance, 20).until(
EC.presence_of_element_located((By.XPATH, TABLE_BODY_XPATH))
)
# 等待tbody内部至少有一行数据出现
WebDriverWait(driver_instance, 20).until(
EC.presence_of_element_located((By.XPATH, f"{TABLE_BODY_XPATH}/tr"))
)
# 等待分页器出现
WebDriverWait(driver_instance, 20).until(
EC.presence_of_element_located((By.XPATH, PAGINATE_CONTAINER_XPATH))
)
print(f"{board_name} 板块页面加载成功,表格和分页器可见。")
except TimeoutException:
print(f"Error: 加载 {board_name} 页面超时,未能找到关键元素(股票表格或分页器)。")
try:
screenshot_path = f"error_screenshot_{board_name}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.png"
driver_instance.save_screenshot(screenshot_path)
print(f"已保存超时页面的截图到: {screenshot_path}")
except Exception as e:
print(f"保存截图失败: {e}")
return []
# 获取总页数
total_pages = 1
try:
WebDriverWait(driver_instance, 10).until(
EC.presence_of_element_located((By.XPATH, PAGINATE_CONTAINER_XPATH))
)
# 页码链接直接选择分页器div下的所有a标签
# 页码是直接在div.qtpager下,没有title class,就取所有a标签
page_links = driver_instance.find_elements(By.XPATH, f"{PAGINATE_CONTAINER_XPATH}/a")
if page_links:
max_page_num = 0
for link in page_links:
try:
page_text = link.text.strip()
if page_text.isdigit():
max_page_num = max(max_page_num, int(page_text))
except ValueError:
pass
if max_page_num > 0:
total_pages = max_page_num
print(f"总页数: {total_pages}")
else:
print("未能找到页码链接,默认为1页。")
except Exception as e:
print(f"获取总页数时发生错误: {e},默认为1页。")
current_page = 1
all_stocks_data = []
last_first_stock_no = None
while len(all_stocks_data) < MAX_STOCKS_PER_BOARD and current_page <= total_pages:
print(f"正在爬取 {board_name} 的第 {current_page}/{total_pages} 页... (当前已获取 {len(all_stocks_data)} 条)")
try:
# 确保页面在切换页码后数据已经刷新
if current_page > 1:
try:
# 等待第一支股票代码变化,这更能表明页面数据已更新
WebDriverWait(driver_instance, 15).until(
lambda d: d.find_element(By.XPATH,
f"{TABLE_BODY_XPATH}/tr[1]/td[2]").text.strip() != last_first_stock_no
)
time.sleep(1) # 额外等待,确保页面渲染完成
except TimeoutException:
print(f"Warning: 等待 {board_name} 第 {current_page} 页第一支股票代码刷新超时,可能页面未按预期更新或数据未变。继续尝试获取当前页数据。")
table_body = WebDriverWait(driver_instance, 15).until(
EC.presence_of_element_located((By.XPATH, TABLE_BODY_XPATH))
)
# 再次确认数据行已加载
WebDriverWait(driver_instance, 15).until(
EC.presence_of_element_located((By.XPATH, f"{TABLE_BODY_XPATH}/tr"))
)
time.sleep(1) # 短暂等待,确保所有数据行都已渲染
rows = table_body.find_elements(By.TAG_NAME, "tr") #直接找tr即可
if rows:
first_row_cols = rows[0].find_elements(By.TAG_NAME, "td")
if len(first_row_cols) >= 2:
last_first_stock_no = first_row_cols[1].text.strip()
for row in rows:
if len(all_stocks_data) >= MAX_STOCKS_PER_BOARD:
break
cols = row.find_elements(By.TAG_NAME, "td")
if len(cols) >= 14: # 确保有足够的列
try:
stock_no = cols[1].text.strip()
stock_name = cols[2].text.strip()
latest_price = parse_price(cols[3].text.strip())
change_rate = parse_price(cols[4].text.strip().replace('%', ''))
change_amount = parse_price(cols[5].text.strip())
trade_volume = parse_volume_amount(cols[6].text.strip())
trade_amount = parse_volume_amount(cols[7].text.strip())
amplitude = parse_price(cols[8].text.strip().replace('%', ''))
highest_price = parse_price(cols[9].text.strip())
lowest_price = parse_price(cols[10].text.strip())
open_price = parse_price(cols[11].text.strip())
prev_close_price = parse_price(cols[12].text.strip())
all_stocks_data.append((
board_name,
stock_no,
stock_name,
latest_price,
change_rate,
change_amount,
trade_volume,
trade_amount,
amplitude,
highest_price,
lowest_price,
open_price,
prev_close_price,
datetime.now()
))
except Exception as e:
print(f"解析行数据时发生错误: {e}, 行数据: {row.text}")
if len(all_stocks_data) >= MAX_STOCKS_PER_BOARD:
print(f"已达到最大股票数限制 ({MAX_STOCKS_PER_BOARD} 条),停止爬取。")
break
current_page += 1
if current_page <= total_pages:
next_page_button = None
try:
next_page_button = WebDriverWait(driver_instance, 10).until(
EC.element_to_be_clickable((By.XPATH,
f"{PAGINATE_CONTAINER_XPATH}/a[@title='下一页' and text()='>']"))
)
except TimeoutException:
print(f"未找到 {board_name} 的“下一页”按钮或已是最后一页 (超时)。")
break
except NoSuchElementException:
print(f"未找到 {board_name} 的“下一页”按钮或已是最后一页 (元素不存在)。")
break
if next_page_button: # 只要找到按钮,就点击
driver_instance.execute_script("arguments[0].click();", next_page_button)
time.sleep(3) # 点击后等待页面加载
else:
print(f"{board_name} 已达到最后一页或无下一页按钮。")
break
else:
break
except StaleElementReferenceException:
print(f"StaleElementReferenceException: 页面元素已失效,可能页面已刷新或数据已更新。尝试重新定位。")
print("为避免复杂性,暂时跳过当前板块的后续页。")
break
except TimeoutException:
print(f"Error: 等待 {board_name} 第 {current_page} 页数据超时。")
try:
screenshot_path = f"error_screenshot_{board_name}_page_{current_page}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.png"
driver_instance.save_screenshot(screenshot_path)
print(f"已保存超时页面的截图到: {screenshot_path}")
except Exception as e:
print(f"保存截图失败: {e}")
break
except Exception as e:
print(f"爬取 {board_name} 第 {current_page} 页时发生未知错误: {e}")
import traceback
traceback.print_exc()
break
print(f"--- {board_name} 爬取完成,共获取 {len(all_stocks_data)} 条数据 ---")
return all_stocks_data
实验结果
用mysql表格展示,分别为沪深A股,上证A股,深圳A股数据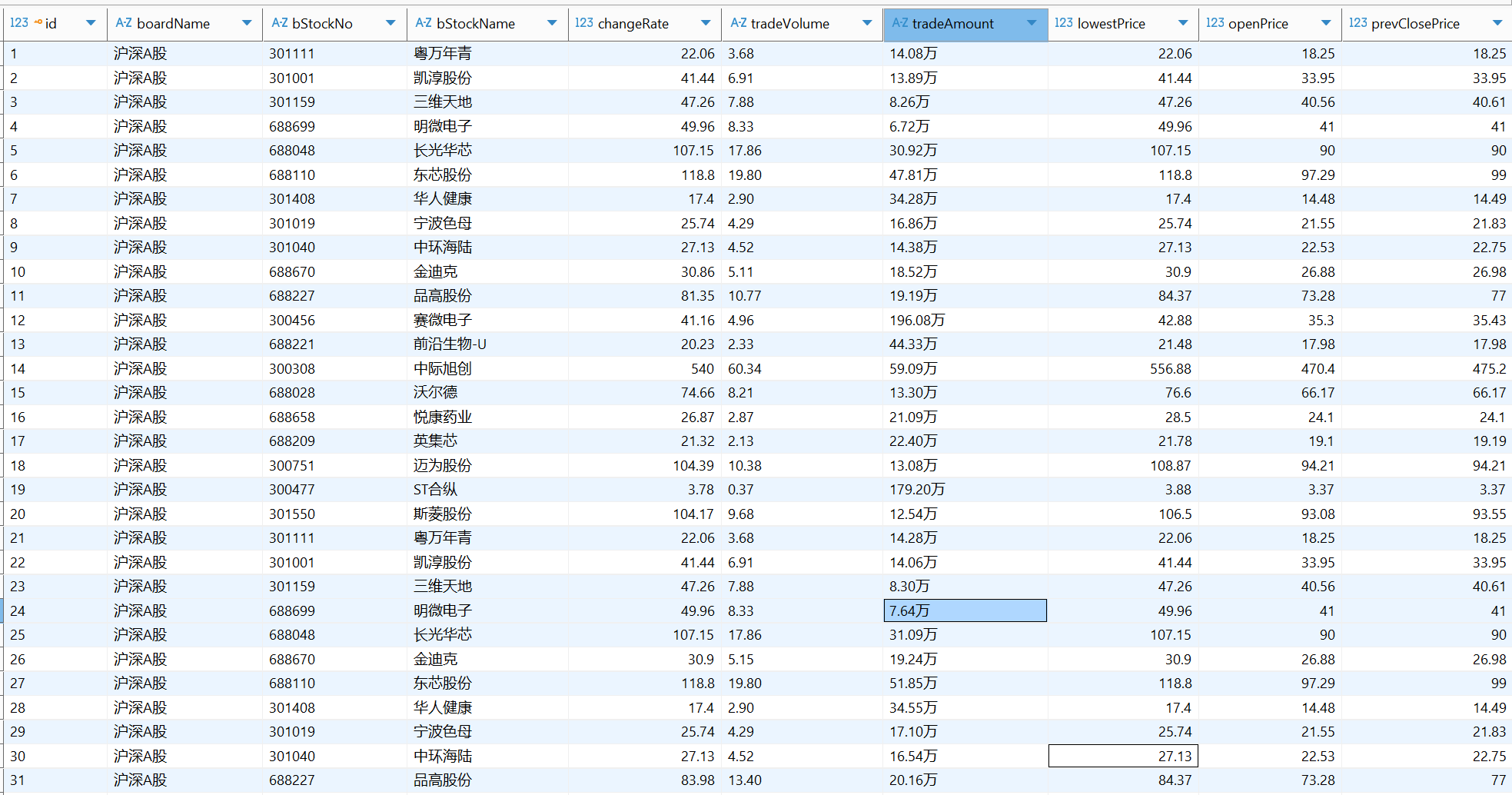
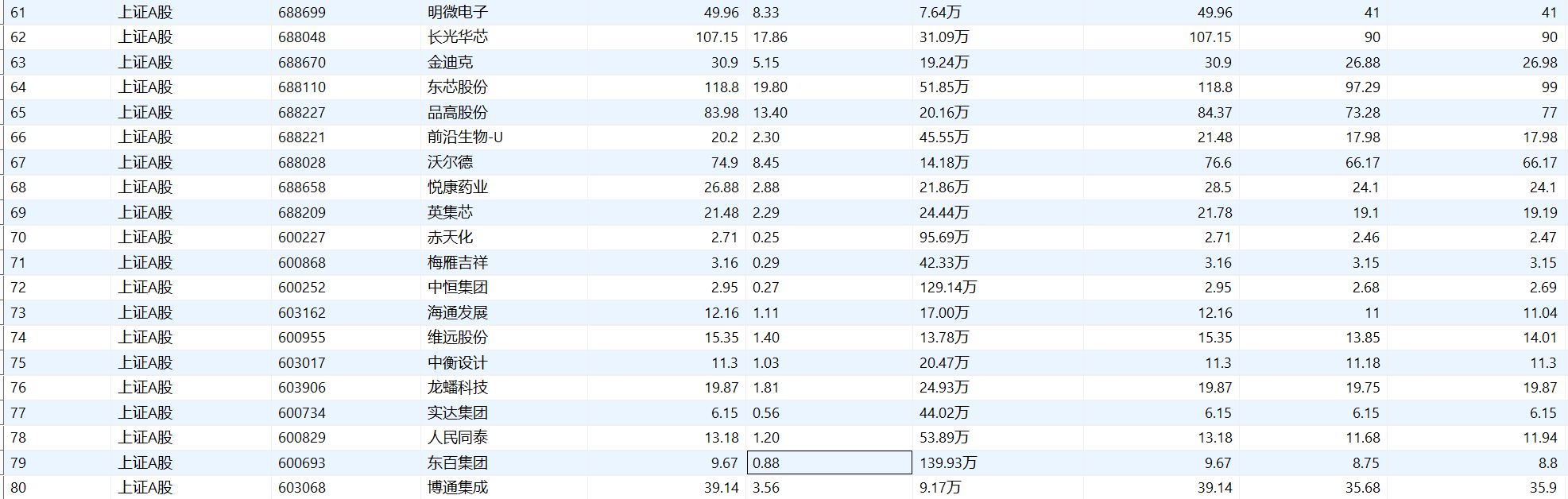
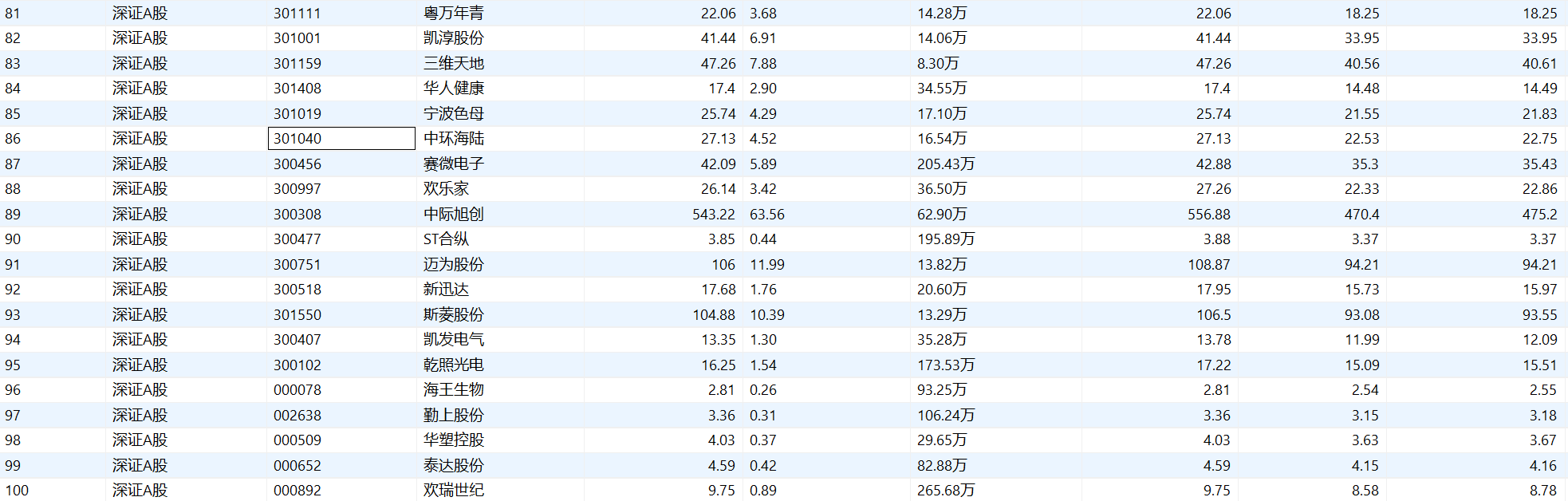
实验心得
1.在初次运行时出现浏览器无法相应的问题,发现时本机webdriver版本与chrome不匹配问题,重新下载driver后解决。
2.寻找翻页操作符所属位置找了很久,最后发现要class=‘下一页’且内容为‘>’才能锁定,这部分也耗费了很长时间。
作业②:
要求: 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介) 候选网站:中国mooc网:https://www.icourse163.org 输出信息:MYSQL数据库存储和输出格式调用库函数
1.Selenium:作用如作业1
2.pymysql:连接 MySQL 数据库的接口
3.re:正则表达式库,用于字符串的高级匹配和提取,负责从复杂的 URL提取课程id
实验思路
1,数据库交互点击查看代码
def save_to_mysql(data):
conn = pymysql.connect(**db_config)
try:
with conn.cursor() as cursor:
# 查重
cursor.execute("SELECT id FROM courses WHERE c_course_id = %s", (data['course_id'],))
if cursor.fetchone():
print(f" -> [已存在] 跳过: {data['name']}")
return
sql = """
INSERT INTO courses
(c_course_id, c_course_name, c_college, c_teacher, c_team, c_count, c_process, c_brief)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(sql, (
data['course_id'], data['name'], data['college'],
data['teacher'], data['team'], data['count'],
data['process'], data['brief']
))
conn.commit()
print(f" -> [成功入库] {data['name']}")
except Exception as e:
print(f" -> 数据库错误: {e}")
conn.rollback()
finally:
conn.close()
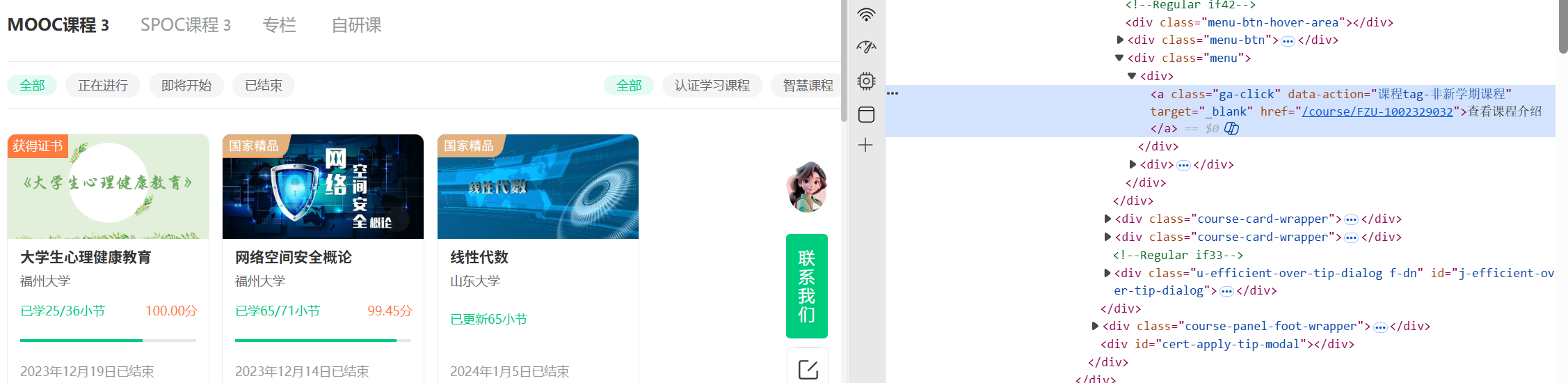
2.链接提取策略:这里我直接在个人中心中爬取课程信息(直接在主页中爬取会因为课程动态更新有干扰,且主页内容复杂,不容易用xpath提取有关信息)。使用 XPath //*[contains(@class, 'menu')]//a。这是针对网易云课堂卡片菜单结构的精准打击,提取菜单内的详情链接。(由下图知)
3.详情页采集:在采集具体字段(如学校、教师)时,定义了内部函数 get_text 和 get_attr,由其在html中位置使用css进行匹配。
点击查看代码
def scrape_my_course_menu():
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_argument(
'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36')
options.add_experimental_option('excludeSwitches', ['enable-logging'])
driver = webdriver.Chrome(options=options)
driver.maximize_window()
try:
# ==========================================
# 1. 登录检测
# ==========================================
print("1. 启动浏览器,进入个人中心...")
driver.get("https://www.icourse163.org/home.htm")
wait = WebDriverWait(driver, 300)
print("\n" + "=" * 50)
print("请手动登录!")
print(" 脚本正在监测 URL 变化...")
print("=" * 50 + "\n")
# 等待 URL 变成 home.htm 且不含 login
try:
wait.until(lambda d: "home.htm" in d.current_url and "login" not in d.current_url)
print("登录成功!等待页面完全加载 (30秒)...")
time.sleep(30) # 多给点时间让 JS 渲染出菜单
except:
print("登录超时或失败。")
return
# ==========================================
# 2. 针对“Menu”结构的深度挖掘
# ==========================================
course_links = []
print("2. 开始挖掘课程链接...")
# 动作:先向下滚动几次,确保所有卡片都渲染出来
for _ in range(3):
driver.execute_script("window.scrollBy(0, 500);")
time.sleep(0.5)
# --- 找 class 包含 'menu' 的元素下的链接 ---
print(" -> 正在扫描所有包含 'menu' 字样的区域...")
try:
# 查找所有 class 包含 'menu' 的 div/ul/li 下的 a 标签
menu_links = driver.find_elements(By.XPATH, "//*[contains(@class, 'menu')]//a")
for elem in menu_links:
href = elem.get_attribute("href")
cleaned = clean_url(href)
if cleaned and cleaned not in course_links:
course_links.append(cleaned)
print(f" [Menu策略] 发现: {cleaned}")
except Exception as e:
print(f" 出错: {e}")
# --- 结果汇总 ---
# 截取前5个
final_links = course_links[:5]
print("-" * 50)
print(f"最终锁定 {len(final_links)} 个有效课程链接:")
for l in final_links: print(f" > {l}")
print("-" * 50)
if not final_links:
print("依然没有找到链接。")
print("调试建议:请查看浏览器界面,确认页面上是否真的显示了课程卡片?")
return
# ==========================================
# 3. 爬取详情
# ==========================================
for i, url in enumerate(final_links):
print(f"\n[{i + 1}/{len(final_links)}] 正在爬取: {url}")
driver.get(url)
data = {}
try:
# 等待标题
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, "course-title")))
time.sleep(1)
# 辅助函数:安全获取文本
def get_text(selectors):
for selector in selectors:
try:
elem = driver.find_element(By.CSS_SELECTOR, selector)
if elem.text.strip(): return elem.text.strip()
except:
continue
return "未知"
def get_attr(selectors, attr):
for selector in selectors:
try:
return driver.find_element(By.CSS_SELECTOR, selector).get_attribute(attr)
except:
continue
return "未知"
# 提取数据 (使用多组选择器增强成功率)
data['course_id'] = url.split("/")[-1]
data['name'] = get_text([".course-title", "h1"])
# 学校
data['college'] = get_text([".school-box .school-name", ".m-teachers a"])
if data['college'] == "未知":
data['college'] = get_attr([".m-teachers img"], "alt")
# 教师
data['teacher'] = get_attr([".m-teachers_teacher-list .u-teacher-name"], "title")
if data['teacher'] == "未知":
data['teacher'] = get_attr([".m-teachers_teacher-list img"], "alt")
# 团队
data['team'] = get_attr([".m-teachers_teacher-list .u-teacher-name"], "title")
if data['team'] == "未知":
data['team'] = get_attr([".m-teachers_teacher-list img"], "alt")
# 人数
data['count'] = get_text([".course-enroll-info_course-info_term-progress .count",
".course-enroll-info_course-info_term-num"])
# 进度
data['process'] = get_text([".course-enroll-info_course-info_term-info_term-time"])
# 简介
raw_brief = get_text(["#j-rectxt2", ".m-infotxt", ".u-course-intro"])
data['brief'] = raw_brief[:800]
save_to_mysql(data)
except Exception as e:
print(f" ->爬取失败: {e}")
time.sleep(2)
except Exception as main_e:
print(f"主程序错误: {main_e}")
finally:
print("\n任务结束,关闭浏览器")
driver.quit()
实验结果

实验心得
1.这题我是半自动化做完的,先加入30秒缓冲时间以便我个人账户登录,在使用脚本代码实现对我个人中心相关课程信息的爬取,也是会了新的方法。作业③:
要求: 掌握大数据相关服务,熟悉Xshell的使用 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。 环境搭建: 任务一:开通MapReduce服务 实时分析开发实战: 任务一:Python脚本生成测试数据 任务二:配置Kafka 任务三: 安装Flume客户端 任务四:配置Flume采集数据 输出:实验关键步骤或结果截图。实验结果
环境搭建: 任务一:开通MapReduce服务 配置: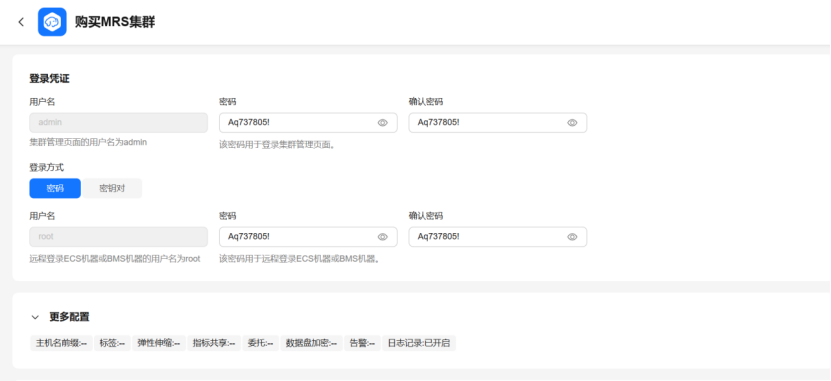
结果:

实时分析开发实战:
任务一:Python脚本生成测试数据
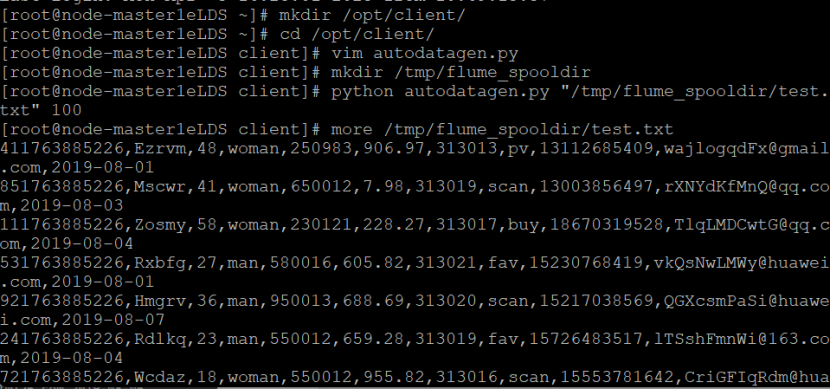
1.进入/opt/client/目录,使用vi命令编写Python脚本:autodatagen.py,执行脚本测试
结果:
任务二:配置Kafka
1.使用source命令进行环境变量的设置使得相关命令可用。
source /opt/Bigdata/client/bigdata_env
2.在kafka中创建topic
执行如下命令创建topic(--bootstrap-server个人IP)。
kafka-topics.sh --create --topic fludesc --partitions 1 --replication-factor 1 --bootstrap-server 192.174.2.105:9092
3.查看topic信息
kafka-topics.sh --list --bootstrap-server 192.174.2.105:9092
结果:

任务三: 安装Flume客户端
执行以下命令重启Flume的服务。
cd /opt/FlumeClient/fusioninsight-flume-1.11.0
sh bin/flume-manage.sh restart
结果:

任务四:配置Flume采集数据
1,在conf目录下编辑文件properties.properties
vim conf/properties.properties
2.进入Python脚本所在目录,执行python脚本,再生成一份数据。
cd /opt/client/
python autodatagen.py "/tmp/flume_spooldir/test.txt" 100
查看原窗口,可以看到已经消费出了数据:
结果:左边为旧窗口,右边为新窗口
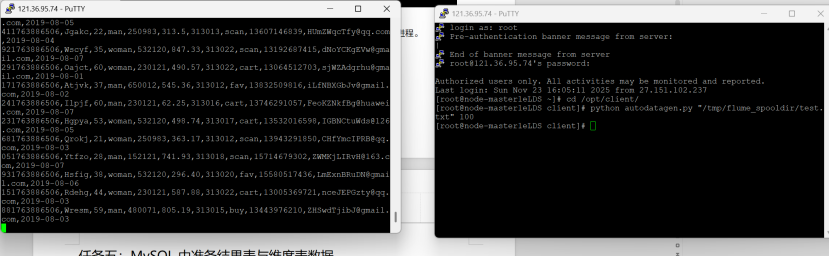
实验心得
1.出的很好下次别出了
2.好繁复的内容,有种让人找不到报错的美感(这里对华为云实验,不是这个)。
代码文件:https://gitee.com/liu-yi-huang/data_project/tree/master/作业4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号