


【线程理论】
1 1.什么是线程? 2 进程:资源单位,仅仅是在内存空间中开辟一块独立的空间 3 线程:程序执行单位(真正被CPU执行的其实是进程里面的线程,线程指的就是代码的执行过程,执行代码中所需要使用到的资源都找所在的进程索要) 4 (每一个进程自带一个线程) 5 6 2.为什么要有线程 7 开设进程: 8 1.申请内存空间 耗资源 9 2.“拷贝代码” 耗资源 10 开线程: 11 一个进程内可以开设多个线程,在用一个进程内开设多个线程无需再次申请内存空间及靠欸代码的操作 12 总结:开设线程比开设进程的开销小,同一个进程下的多个线程数据是共享的
3.进程之间和线程之间是合作还是竞争?
进程是开辟出的独立的内存地址 ---> 抢资源 (内存、硬盘、网络 ... ) ---> 对于进程与进程之间来说 竞争
线程是开设在进程内部 --> 共享一块资源 ----> 对于线程来说是合作
4.什么是多线程
多线程指的是
在一个进程中开启多个线程
简单的讲:如果多个任务共用一块地址空间,那么必须在一个进程内开启多个线程。
多线程共享一个进程的地址空间
线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用
若多个线程都是cpu密集型的,那么并不能获得性能上的增强
但是如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而会加快程序执行的速度。
在多cpu系统中,为了最大限度的利用多核,可以开启多个线程,比开进程开销要小的多。(这一条并不适用于Python)
【创建线程的两种方式】
1 第一种: 2 3 def task(name): 4 print('%s is running' % name) 5 time.sleep(2) 6 print('%s is over' % name) 7 8 9 # 开启线程不需要在main下面执行代码,直接书写就可以 10 t = Thread(target=task, args=('egon',)) 11 t.start() # 创建线程的开销非常小,几乎是代码一执行线程就已经创建好啦 12 print('主') 13 14 15 ================================================ 16 第二种: 17 18 from threading import Thread 19 import time 20 21 22 # (类继承) 23 class MyThead(Thread): 24 def __init__(self, name): 25 # 重写别人的方法,又不知道别人的方法里有啥,就调用父类的方法 26 super().__init__() 27 self.name = name 28 29 def run(self): 30 print('%s is running' % self.name) 31 time.sleep(1) 32 print('小可爱') 33 34 35 if __name__ == '__main__': 36 t = MyThead('egon') 37 t.start() 38 print('主') 39 这行代码可能在线程开始之前、之中或之后打印,取决于操作系统的线程调度 40 ================= 41 先运行running,再运行主
。
。
【TCP服务端实现并发】
1 服务端 2 3 import socket 4 from threading import Thread 5 from multiprocessing import Process 6 7 ''' 8 服务端: 9 1.要有固定的IP和PORT 10 2.24小时不断提供服务 11 3.能够支持并发 12 ''' 13 server = socket.socket() # 括号内不加参数默认就是TCP协议 14 server.bind(('127.0.0.1', 8080)) 15 server.listen(5) 16 17 18 # 将服务的代码单独封装成一个函数 19 def talk(conn): 20 # 通信循环 21 while True: 22 try: 23 data = conn.recv(1024) 24 if len(data) == 0: break 25 print(data.decode('utf-8')) 26 conn.send(data.upper()) 27 except ConnectionResetError as e: 28 print(e) 29 break 30 conn.close() 31 32 33 # 链接循环 34 while True: 35 conn, addr = server.accept() 36 # # 叫其他人来服务客户 37 t = Thread(target=talk, args=(conn,)) 38 t.start() # 启动线程,实现并发 39 40 41 ================================================ 42 客户端 43 44 import socket 45 46 client = socket.socket() 47 client.connect(('127.0.0.1',8080)) 48 while True: 49 client.send(b'hello world') 50 data = client.recv(1024) 51 print(data.decode('utf-8'))
。
。
【join 方法】
1 from threading import Thread 2 import time 3 4 5 def task(name): 6 print('%s is running' % name) 7 time.sleep(1) 8 print('%s is over' % name) 9 10 11 if __name__ == '__main__': 12 t = Thread(target=task, args=('egon',)) 13 t.start() 14 # 想等到子线程运行完毕在运行 15 t.join() 16 print('主')
。
。
【线程的诸多特性】
1.线程的join方法,主线程代码等待子线程代码运行结束再往下运行!!! (和线程的join方法特性一样)
2.同一个进程内多个线程数据共享
3.current_thread().name # 查看进程下的线程名
4.active_count() # 查看进程下的线程数
1 from threading import Thread 2 import time 3 4 # ========================验证同一个进程下的多个线程数据共享 5 money = 100 6 7 8 def task(): 9 global money 10 money = 666 11 12 13 if __name__ == '__main__': 14 t = Thread(target=task) 15 t.start() 16 # t.join() 17 print(money) # 666 18 19 20 ------------------------------------------ 21 同一个进程内多个线程数据共享,所以子线程将主线程里面的全局变量money的值改了, 22 主线程与子线程都在一个进程里面,都在一个内存空间内。
。
。
【线程对象及其他方法】
1 # 线程对象及其他方法 2 import os, time 3 from threading import Thread, active_count, current_thread 4 5 6 def task(): 7 print('hello world', os.getpid()) 8 print('hello', current_thread().name) # 获取线程名字,Thread-1 9 10 11 if __name__ == '__main__': 12 t = Thread(target=task) 13 t.start() 14 print('主', os.getpid()) # 两个进程号一样,证明两个线程在同一个进程下 15 print('主线程名字', current_thread().name) # MainThread 16 print('主', active_count()) # 统计当前正在活跃的线程数 17 18 19 --------------------------------------------------------------------------------- 20 active_count:统计当前正在活跃的线程数 21 22 current_thread().name获取线程名字
。
。
【守护线程】
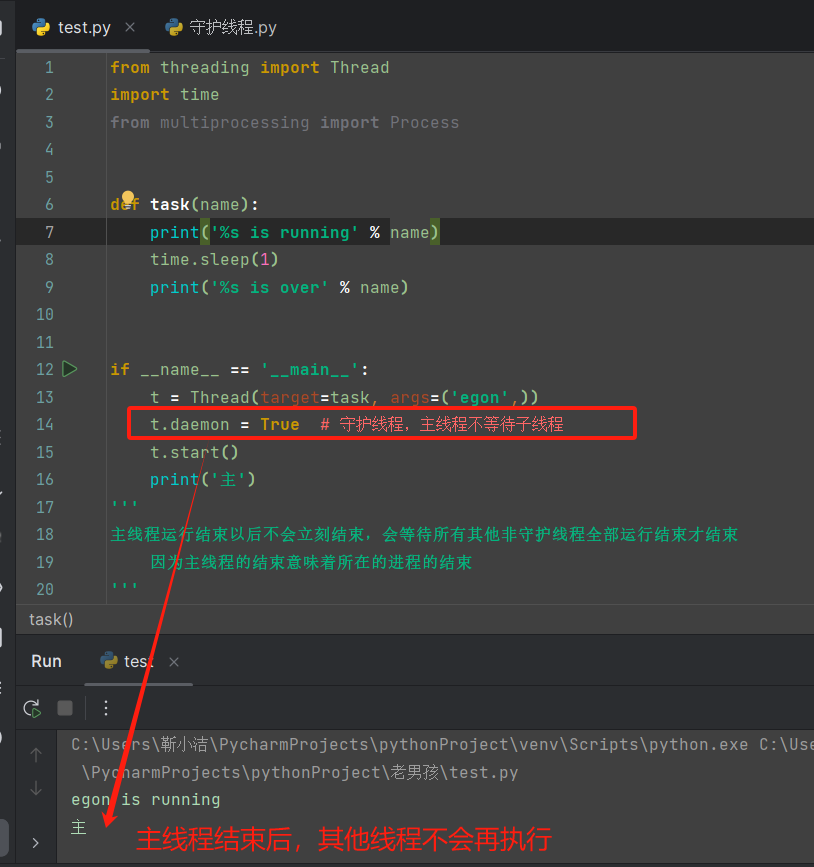
。
。
【线程互斥锁】
1 from threading import Thread, Lock 2 import time 3 4 money = 100 5 # 给一把锁,防止数据错乱 6 mutex = Lock() 7 8 9 def task(): 10 global money 11 # 让大家抢锁 12 mutex.acquire() 13 tmp = money # 先获取到money 14 time.sleep(0.1) 15 money = tmp - 1 16 mutex.release() 17 18 19 if __name__ == '__main__': 20 t_list = [] # 为了保证100个线程都能打印完 21 for i in range(100): 22 t = Thread(target=task) 23 t.start() 24 t_list.append(t) 25 26 for t in t_list: 27 t.join() 28 print(money)
# 加锁,将并发变成串行
。
。
【GIL锁】
1 1 GIL:Global Interpreter Lock又称全局解释器锁 2 2 保证了cpython进程中得每个线程必须获得这把锁才能执行,不获得不能执行 3 3 使得在同一进程内任何时刻仅有一个线程在执行 4 4 gil锁只针对于cpython解释器----》目前基本都是在用cpython解释器 5 5 针对不同的数据类型,需要加不同的锁处理 6 7 --------不是一个好的东西--python多线程是伪多线程-------------- 8 为什么要有gil锁? 9 -垃圾回收是垃圾回收线程,它在执行的时候,其他线程是不能执行的,而限于当时的条件,只有单核cpu, 10 所以作者直接做了个GIL锁,保证一个进程内同一时刻只有一个线程在执行,但是后来随着多核机器的出现,就导致cpython解释器开启了多线程不能利用多核优势 11 12 13 重点: 14 1.GIL不是python的特点而是cPython解释器的特点 15 2.GIL是保证解释器级别的数据的安全 16 3.GIL会导致同一个进程下的多个线程的无法同时执行,即无法利用多核优势 17 4.针对不同的数据还需要加不同的锁处理 18 5.解释型语言的通病:同一个进程下多个线程无法利用多核优势
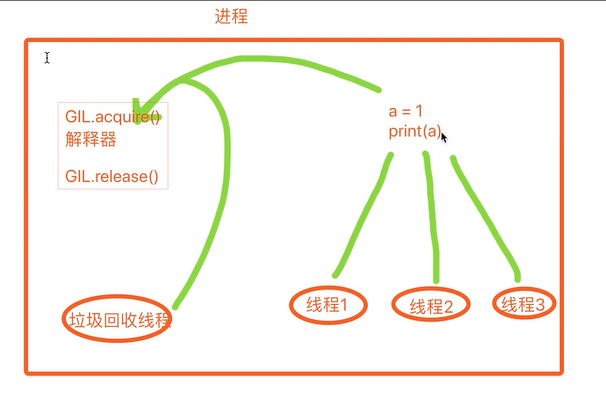
【GIL锁与普通互斥锁的区别】
1 # =======================验证GIL会导致同一个进程下的多个线程的无法同时执行,即无法利用多核优势 2 from threading import Thread, Lock 3 import time 4 5 money = 100 6 mutex = Lock() 7 8 9 def task(): 10 global money 11 mutex.acquire() 12 # 方式一: 13 # with mutex: 14 # tmp = money # 先获取到money 15 # time.sleep(0.1) # 没有这一步,结果是0 16 # money = tmp - 1 17 # 方式二: 18 tmp = money # 先获取到money 19 time.sleep(0.1) 20 money = tmp - 1 21 mutex.release() 22 23 24 if __name__ == '__main__': 25 t_list = [] # 为了保证100个线程都能打印完 26 for i in range(100): 27 t = Thread(target=task) 28 t.start() 29 t_list.append(t) 30 31 for t in t_list: 32 t.join() 33 print(money) 34 ''' 35 100个线程起起来之后,要先去抢GIL 36 我进入IO GIL自动释放,但是我手上还有一个自己的互斥锁 37 其他线程虽然抢到了GIL,但是没抢到互斥锁 38 最终GIL还是回到了你的手上,你去操作数据 39 ''' 40 41 42 ============================================== 43 44 # ================验证同一个进程下的多线程无法利用多核优势,是不是就没有用了?============== 45 ''' 46 要看具体情况: 47 单核:四个任务(IO密集型\计算密集型) 48 多核:四个任务(IO密集型\计算密集型) 49 50 # 计算密集型 每个任务都需要10s 51 单核: 52 多进程:额外的消耗资源 53 多线程:减少开销 54 多核: 55 多进程:额外的消耗资源 10+(总耗时) 56 多线程:减少开销 40+ 57 58 # IO密集型 每个任务都需要10s 59 多核: 60 多进程:相对浪费资源 61 多线程:更加节省资源 62 ''' 63 64 # 代码验证上述问题 65 # 计算密集型(进程胜出) 66 from threading import Thread 67 import time, os 68 from multiprocessing import Process 69 70 71 def work(): 72 res = 1 73 for i in range(1000000): 74 res += i + 1 75 76 77 if __name__ == '__main__': 78 l = [] 79 print(os.cpu_count()) # 获取当前计算机CPU个数 80 start_time = time.time() 81 for i in range(12): 82 # p = Process(target=work) # 1.08400297164917 83 t = Thread(target=work) # 1.3991684913635254 84 t.start() 85 # p.start() 86 # l.append(p) 87 l.append(t) 88 for p in l: 89 p.join() 90 print(time.time() - start_time) 91 92 ================================================ 93 # ====================IO密集型(多线程胜出) 94 def work(): 95 time.sleep(1) 96 97 98 if __name__ == '__main__': 99 l = [] 100 print(os.cpu_count()) # 获取当前计算机CPU个数 101 start_time = time.time() 102 for i in range(400): 103 # p = Process(target=work) # 24.686311721801758 104 t = Thread(target=work) # 1.0838360786437988 105 t.start() 106 # p.start() 107 # l.append(p) 108 l.append(t) 109 for p in l: 110 p.join() 111 print(time.time() - start_time) 112 113 114 115 116 # 总结:多线程和多进程都有各自的优势,以后我们可以在多进程下面再开设多线程,这样的话可以利用多核也可以节省资源消耗

 浙公网安备 33010602011771号
浙公网安备 33010602011771号