计算字符串长度
计算字符个数
问题描述
JavaScript中,可以通过访问字符串的length属性来获得其长度,但对于多字节字符如中文,日文和韩文等,length并不能准确地返回字符串中的字符数目。
方法
//Array.from(string).length;
"𠮷".length; //2,与预期不符
Array.from("𠮷").length; //1
说明
为什么使用字符串的length属性来返回字符串长度会与预期不符呢?
这与JavaScript采用的编码方式有关。JavaScript采用的编码方式是UTF-16.
UTF-16编码介于UTF-32与UTF-8之间,同时结合了定长和变长两种编码方法的特点。
它的编码规则很简单:基本平面的字符占用2个字节,辅助平面的字符占用4个字节。也就是说,UTF-16的编码长度要么是2个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF)。

如何判断我们遇到的字符是双字节的还是4字节的并且进行正确的解读呢?这是因为在基本平面内,从U+D800到U+DFFF是一个空段,即这些码点不对应任何字符。因此,这个空段可以用来映射辅助平面的字符。
具体来说,辅助平面可以表示220个字符,也就是说,对应这些字符至少需要20个二进制位。UTF-16将这20位拆成两半,前10位映射在U+D800到U+DBFF(空间大小210),称为高位(H),后10位映射在U+DC00到U+DFFF(空间大小210),称为低位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示。

所以,当我们遇到两个字节,发现它的码点在U+D800到U+DBFF之间,就可以断定,紧跟在后面的两个字节的码点,应该在U+DC00到U+DFFF之间,这四个字节必须放在一起解读。
Unicode转换成UTF-16的计算:
Unicode码点转成UTF-16的时候,首先区分这是基本平面字符,还是辅助平面字符。如果是前者,直接将码点转为对应的十六进制形式,长度为两字节。
U+597D = 0x597D
如果是辅助平面字符,Unicode 3.0版给出了转码公式。
H = Math.floor((c-0x10000) / 0x400)+0xD800
L = (c - 0x10000) % 0x400 + 0xDC00
为什么在计算高位的时候要用c-0x10000呢?
因为范围。Unicode的最大码元是0x10FFFF,有21位有效数字,如果不减去0x10000,就不能保证辅助平面的空间大小为220。
回到"𠮷"字,《汉典》中的解释如下:
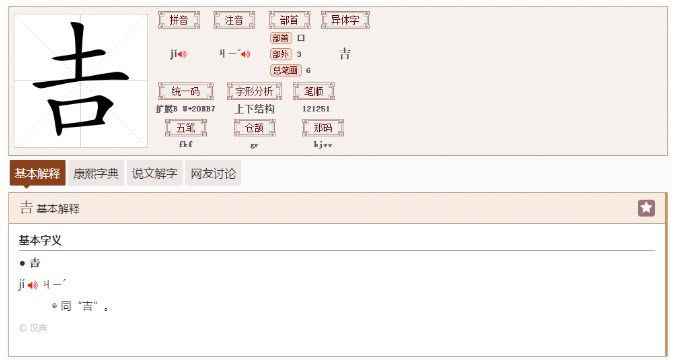
"𠮷"的unicode码位是0x20BB7,按照上面的转换方式可以得到其UTF-16编码为:
\uD842\uDFB7
恰好是两个编码单元(16位),所以length返回的是2.
英文字符,数字等都是16位的,但像中文等就有可能出现4个字节的码位,所以获取字符串长度的最保险的方法是:
Array.from(string).length;
感谢阅读!
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号