开放性实验——web安全研究与实践(1)
二、学习内容
1.Web的概念:
Web(World Wide Web)即全球广域网,也称为万维网,它是一种基于超文本和HTTP的、全球性的、动态交互的、跨平台的分布式图形信息系统。是建立在Internet上的一种网络服务,为浏览者在Internet上查找和浏览信息提供了图形化的、易于访问的直观界面,其中的文档及超级链接将Internet上的信息节点组织成一个互为关联的网状结构。
(1)基于超文本和HTTP的:超文本指超链接文本,可以连接到其他文本上,HTTP是协议。超文本是存放在互联网上的电子资源,HTTP控制着资源在互联网中的利用。客户端和服务端在HTTP协议下通过“三次握手”建立连通关系,服务端将资源分包随响应报文一起返回到客户端。
(2)全球性的:万维网有世界上所有的主机组成,哪怕相隔大洋的两端,一样可以获取到彼此的信息,这是一种跨越空间的信息交流。网民们可以在网上发布一些信息,也可以获取一些信息,这些信息可以是来自世界各地,呈现一种全球互通的状态。
(3)动态交互的:Web的交互性首先表现在它的超链接上,用户的浏览顺序和所到站点完全由他自己决定。另外通过FORM的形式可以从服务器方获得动态的信息。用户通过填写FORM可以向服务器提交请求,服务器可以根据用户的请求返回相应信息。
首部字段Form用来告知服务器使用用户代理的用户的电子邮件地址。通常,其目的就是为了显示搜索引擎等用户代理的负责人的电子邮件联系方式。
(4)跨平台的:无论用户的系统平台是什么,你都可以通过Internet访问WWW。浏览WWW对系统平台没有什么限制。无论从Windows平台、UNIX平台、Macintosh等平台我们都可以访问WWW。对WWW的访问通过一种叫做浏览器(browser)的软件实现。如Mozilla的Firefox、Google的Chrome、Microsoft的Internet Explorer等。
(5)分布式:大量的图形、音频和视频信息会占用相当大的磁盘空间,我们甚至无法预知信息的多少。对于Web没有必要把所有信息都放在一起,信息可以放在不同的站点上,只需要在浏览器中指明这个站点就可以了。在物理上并不一定在一个站点的信息在逻辑上一体化,从用户来看这些信息是一体的。
这就好像是在饭堂打菜,你向阿姨要了几样菜,但这些菜不都是在当前的窗口前放着的,于是阿姨就需要到别的窗口前去拿菜,把你想要的菜都装完了,就回到原来的窗口递给你,而你是不需要跟着跑去其他窗口的。这里的“菜”就好比用户想要获取的信息资源,而不同的窗口面前代表着不同的站点,用户当前访问的地址就是你排队的窗口。
(6)动态的:由于各Web站点的信息包含站点本身的信息,信息的提供者可以经常对站上的信息进行更新。如某个协议的发展状况,公司的广告等等。一般各信息站点都尽量保证信息的时间性。所以Web站点上的信息是动态的、经常更新的,这一点是由信息的提供者保证的。建设动态网站需要PHP语言的支持。
(7)图形信息系统:Web 非常流行的一个很重要的原因就在于它可以在一页上同时显示色彩丰富的图形和文本的性能。在Web之前Internet上的信息只有文本形式。Web可以提供将图形、音频、视频信息集合于一体的特性。这些图形信息有赖于网页设计的“三驾马车”——HTML,CSS,JavaScript。
2.架构:
(1)客户机-服务器(C\S)架构:服务器-客户机,即Client-Server(C/S)结构。C/S结构通常采取两层结构。服务器负责数据的管理,客户机负责完成与用户的交互任务。客户机通过局域网与服务器相连,接受用户的请求,并通过网络向服务器提出请求,对数据库进行操作。服务器接受客户机的请求,将数据提交给客户机,客户机将数据进行计算并将结果呈现给用户。
在电脑上安装的应用(客户端软件,因此依赖于操作系统,不同的操作系统下的客户端实现代码会不一样)就是C\S结构中的客户机一方,这是直接与应用服务器对接,在客户端的申请可以直接送到服务器端,并接受来自服务器的应答。例如,我们打开腾讯视频客户端,在搜索框输入《黑客帝国》,如果腾讯视频的应用服务器上可以调用该资源,则会返回到客户端。这是与单一服务者的直接对接。
(2)B/S结构(Browser/Server,浏览器/服务器模式):是WEB兴起后的一种网络结构模式,WEB浏览器是客户端最主要的应用软件。这种模式统一了客户端,将系统功能实现的核心部分集中到服务器上,简化了系统的开发、维护和使用。客户机上只要安装一个浏览器,如Netscape Navigator或Internet Explorer,服务器安装SQL Server、Oracle、MYSQL等数据库。浏览器通过Web Server 同数据库进行数据交互。
简单地说,就是哪怕你不安装腾讯视频客户端软件,你也一样可以在线在腾讯视频网站上观看视频(但很多的视频网站都会鼓励用户下载客户端,毕竟这样面对的用户更加固定,也有利于增强用户粘度),而这时你与腾讯视频应用服务器的交互是通过浏览器建立的,其中资源的传输就涉及到OSI模型和HTTP等协议了。
3.同源策略:
(1)同源策略(Same origin policy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。
(2)同源策略,它是由Netscape提出的一个著名的安全策略。所有支持JavaScript 的浏览器都会使用这个策略。所谓同源是指,域名,协议,端口相同。当一个浏览器的两个tab页中分别打开来 百度和谷歌的页面当浏览器的百度tab页执行一个脚本的时候会检查这个脚本是属于哪个页面的,即检查是否同源,只有和百度同源的脚本才会被执行。如果非同源,那么在请求数据时,浏览器会在控制台中报一个异常,提示拒绝访问。同源策略是浏览器的行为,是为了保护本地数据不被JavaScript代码获取回来的数据污染,因此拦截的是客户端发出的请求回来的数据接收,即请求发送了,服务器响应了,但是无法被浏览器接收。
也就是说不让脚本作用在别的网页上,如果有恶意脚本想在某银行页面获取用户账号密码,根据同源策略,这是不被允许的。以网上的一个例子作为说明:
http://ismyweb/evilscript.html
<!DOCTYPE html>
<html>
<head><title>test same origin policy</title></head>
<body>
<iframe id="test" src="http://127.0.0.1/test2.html"></iframe>
<script type="text/javascript">
document.getElementById("test").contentDocument.body.innerHTML = "write somthing";
</script>
<p>I am evilscript</p>
</body>
</html>
http://127.0.0.1/test2.html
<html>
<head><title>test same origin policy</title></head>
<body>
Testing.
</body>
</html>
test2.html页面(复制,一份放在ismyweb文件夹下,一份放在localhost中),127.0.0.1是另外一个服务器(即localhost)。
首先访问的是http://127.0.0.1/test2.html

接着访问http://ismyweb.com/evilscript.html,其中:
由首部字段referer可知服务器请求的原始资源的URI是evilscript.html,GET方法是用来请求访问已被URI识别的资源。端口默认是80,同源:
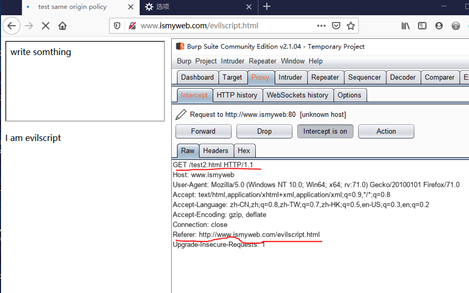
同源,因此脚本
document.getElementById("test").contentDocument.body.innerHTML = "write somthing"; 可以作用在该页面上。
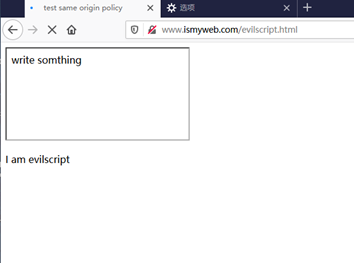
利用brupsuit抓包,可以发现,这会先执行脚本
document.getElementById("test").contentDocument.body.innerHTML = "write somthing";
然后在载入ismyweb里的test2.html
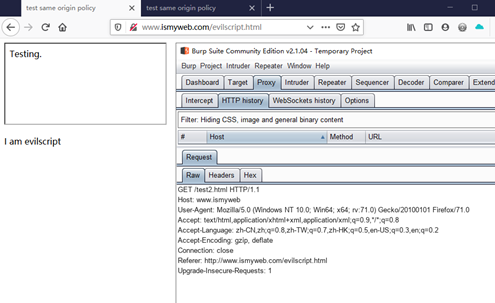
这一次访问127.0.0.1上的test2.html,这一次evilscript.html的脚本无法起作用了
4.web应用工作机理:
(1)静态页面获取:
①假如用户要访问的是index.html文件,输入网址为:http://www.ismyweb/index.html于是通过浏览器向服务器发出请求(GET方法)——
GET /index.html HTTP/1.1
HOST:www.ismyweb.com
②该服务器目录下存放着html文件index,响应请求,返回该文件
③浏览器接收到index.html,经过解释展现在用户面前
(2)动态页面获取:
①动态页面文件一般以php格式存放在服务器之中的
②用户通过浏览器申请php文件
③服务器查询该文件,然后将php文件委托给PHP应用服务器逐条解析并翻译成HTML静态代码,如果php动态语言脚本文件中含有对数据库数据的访问,如影像视频等,则需要连接MySQL,并通过标准SQL语句操作数据库,嵌入在HTML静态代码中,然后交给服务器响应给客户端浏览器
④浏览器收到web服务器的响应,接收服务器端下载的HTML静态代码,同时逐条解释,输出图形用户界面
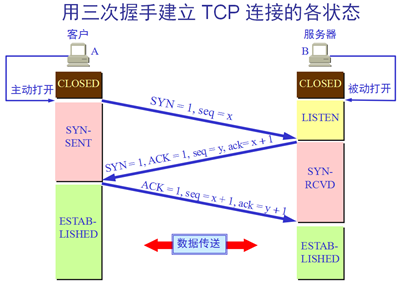
5.wireshark嗅探三次握手过程
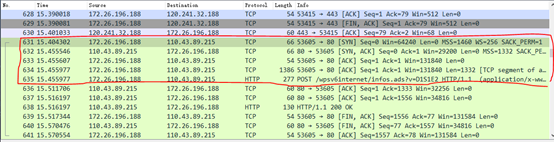
访问 粤港澳大湾区高校在线开放课程联盟
建立连接后,返回的HTTP报文里有着该网站的网址:
[Full request URI: http://www.gdhkmooc.com/portal
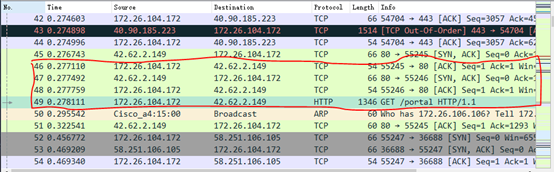
源主机向目的主机发送请求:本地浏览器向该网站发送[SYN]包,
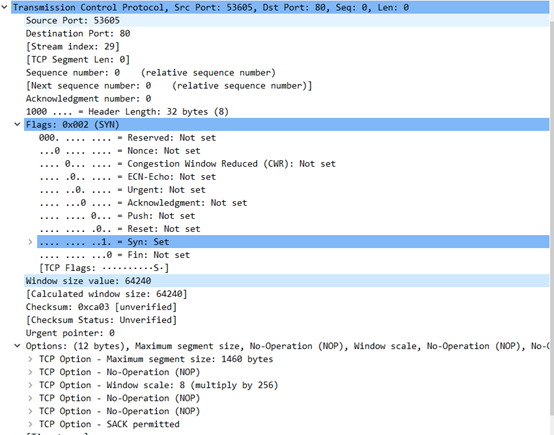
• 源端口号(Source Port):53605
• 目的端口号(Destination Port):HTTP(80)
• 序列号(Sequence number,缩写Seq):0(源主机选择0作为起始序列号,不固定,由申请建立连接的主机确定)
• ACK:0
• 报头长度(Header Length):32字节
• 标志位(Flags):SYN,只有SYN设为1,而ACK(Acknowledge):Not set
• 窗口大小(Window size value):64240字节
• 选项字段(Options):12字节
目的主机返回确认信号:ACK包[SYN,ACK]
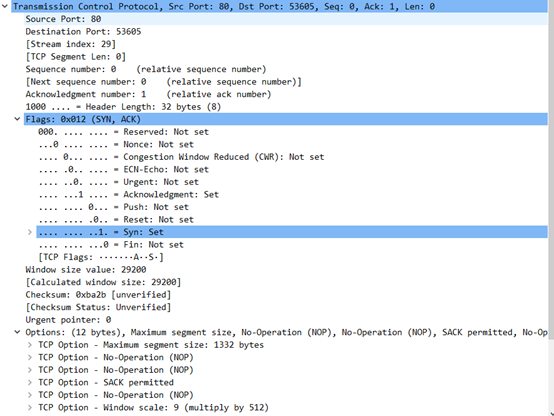
• 源端口号:HTTP(80)
• 目的主机端口号:53605 与上一个包的信息刚好相反,说明这次是服务器向本地客户机返回应答包
• 序列号(Seq):0(目的主机选择0作为起始序列号)
• ACK:1
• 报头长度:32字节
• 标志位:SYN,ACK。SYN=1,ACK=1,确认允许建立连接
• 窗口大小:29200字节
• 选项字段:12字节
源主机再次返回确认信息,并可以携带数据
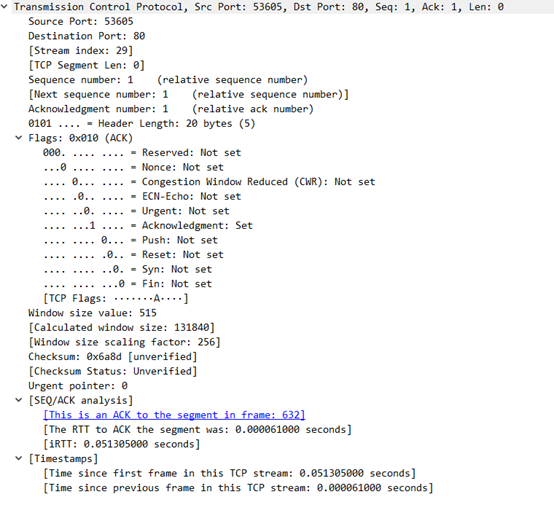
源端口号:53605
目的主机端口号:HTTP(80,HTTP协议的默认端口,TCP是443)
序列号:1
ACK:1
报头长度:20字节
标志位:ACK。SYN=0,ACK=1
窗口大小:515字节
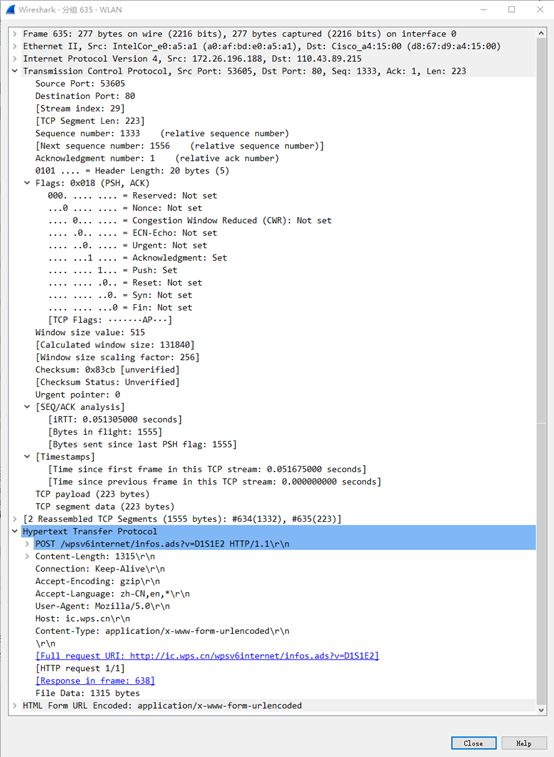
建立连接后返回了HTTP报文,报文上附有URI,正是本地主机申请访问的网页
6.Cookie:
有时也用其复数形式 Cookies。类型为“小型文本文件”,是某些网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息。
Cookie 并不是它的原意“甜饼”的意思, 而是一个保存在客户机中的简单的文本文件, 这个文件与特定的 Web 文档关联在一起, 保存了该客户机访问这个Web 文档时的信息, 当客户机再次访问这个 Web 文档时这些信息可供该文档使用。由于“Cookie”具有可以保存在客户机上的神奇特性, 因此它可以帮助我们实现记录用户个人信息的功能, 而这一切都不必使用复杂的CGI等程序。
cookie的存在弥补了HTTP这个无状态协议所带来的不便的。
关于HTTP的无状态性:A与服务器连接结束后,A再次向服务器提出申请,则它们又需要经过三次握手认证来建立连接,HTTP协议不会记忆之前是否连接过,每一次连接都按照新的连接来处理。Cookie的存在可以避免繁复的认证。
二、收获
1.了解到了很多关于web的基础知识。
2.学会利用身边的一切资源去寻找答案,互联网,书籍等等。
3.有目的的学习使得我的效率大大提高。
4.在学习过程中享受到求知的快乐,动手验证增添了我的学习热情。
三、遇到的问题及解决之道
1.不会使用工具去理解探索一些概念,如wireshark,brupsuit。解决方法:上网查资料,借鉴前人的经验;阅读有关该工具的技术实践书籍,理解其功能
2.不会搭建服务器。解决方法:在网上了解到了一下工具,像我现在用的phpstdio,一开始我是不懂得用的,后来在看过一些书后,了解到服务器的概念,撇开性能,一台普通电脑也是可以充当一台简单服务器的,而只需要建立一个资源文件夹,文件夹内的文件就可以在同一台电脑的浏览器上访问了,这在一定程度上模仿了web应用的工作机理。
四、目前存在的问题及难点
1.如果要探索web安全攻击原理和漏洞分析,以xss为例,在自己电脑上搭建的简单服务器是不太可行的,我考虑着是否应该租用一个服务器,但这样一来就意味着我要自己写网站,而xss攻击涉及到的内容包括HTML,Javascript,PHP,SQL语言等,中间者我都还在基本语法学习层面上,并未学到更深的阶段,SQL更不用说了。而如果借用他人的网站(这是目前来说效率最高的了),我现在还没有方向。
2.尽管学习了JavaScript的基本语法,但尚未达到能够熟悉JavaScript/Ajax编程的程度,且尚未了解到Ajax的用途。
五、下一步学习计划
1.学习Ajax技术特点与应用
2.阅读课外的书籍《web安全深度剖析》《白帽子讲web安全》《XSS跨站脚本攻击剖析与防御》,理解常见web安全攻击原理,针对性探索XSS攻击
3.搭建实验环境,验证xss攻击过程,针对每一例可能的XSS攻击,记录其利用的漏洞,整理
4.针对记录设计防御措施,前后对照
5.完成最终的实验报告
六、目标
1.掌握至少一种web攻击的完整知识,包括原理、攻击过程、防御及其应用
2.熟练掌握实验过程中使用到的工具和语言
3.为练习CTF的关于web方面的题目打好基础
感谢阅读!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号