

mysql高阶语句及存储过程
目录
一、算排名
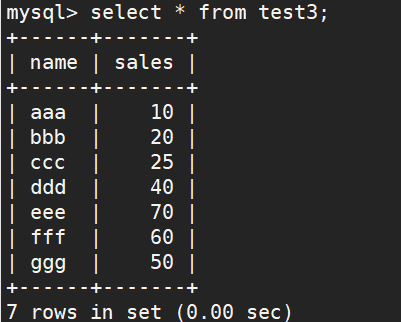
表格自我连接,然后将结果依序列出,算出每一行之前(包括哪一行本身)有多少行数
#统计排名字段的值比本身的值小的以及排名字段和其他字段都相同的数量,比如aaa为6+1=7
select A1.Name, A1.Sales,count(A2.Sales) Rank from test3 A1, test3 A2 where A2.Sales > A1.Sales or (A2.Sales = A1.Sales and A2.Name >= A1.Name) GROUP BY A1.Name,A1.Sales ORDER BY rank;
二、算中位数
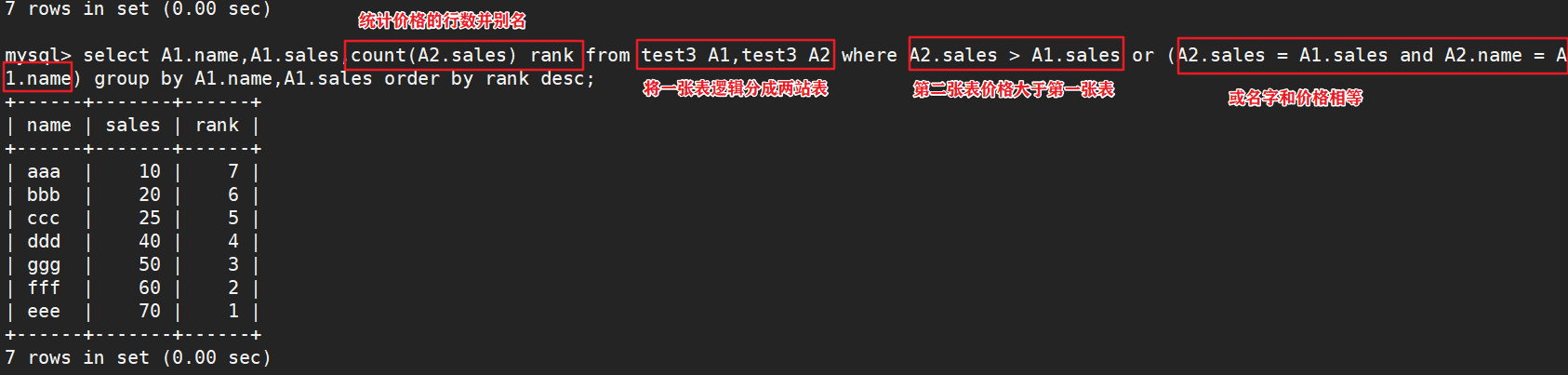
#先将排名表创建一个视图
create view v_zw as select A1.Name, A1.Sales,count(A2.Sales) Rank from test3 A1, test3 A2 where A2.Sales > A1.Sales or (A2.Sales = A1.Sales and A2.Name >= A1.Name) GROUP BY A1.Name,A1.Sales ORDER BY rank;
#集合函数算出中位数
select name,sales 'zw.sales' from v_zw where rank=(select (count(rank)+1) div 2 from v_zw);

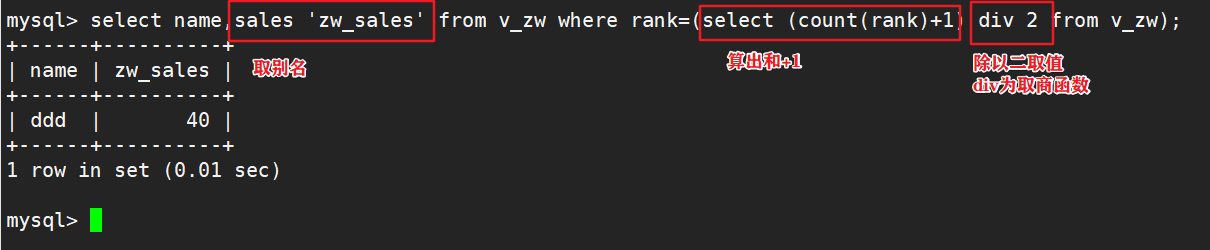
三、算累计总计
select A1.Name, A1.Sales, SUM(A2.Sales) test3 ,count(A2.Sales) Rank from test3 A1,test3 A2 where A2.Sales > A1.Sales or (A2.Sales = A1.Sales and A2.Name >= A1.Name) GROUP BY A1.Name,A1.Sales ORDER BY rank;
#只要添加一个sum函数即可,就能到每行都能累加
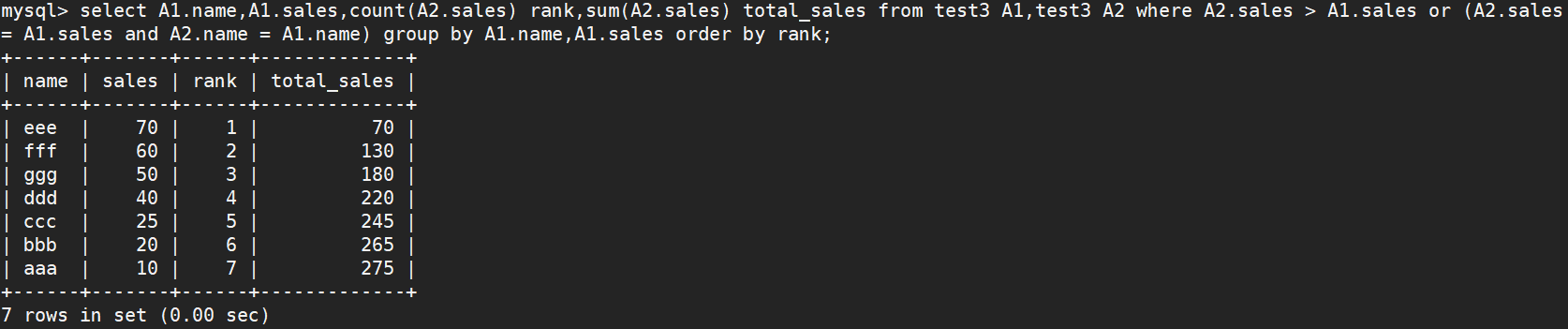
四、算各行份额占总比额的百分比
select A1.Name, A1.Sales, ROUND(A1.Sales/(select sum(Sales) from test3)*100,2) || '%' Per_Sales l,count(A2.Sales) Rank from test3 A1, test3 A2 where A2.Sales > A1.Sales or (A2.Sales = A1.Sales and A2.Name >= A1.Name) GROUP BY A1.Name,A1.Sales ORDER BY rank;

五、算各行份额占当前行累加总份额的百分比
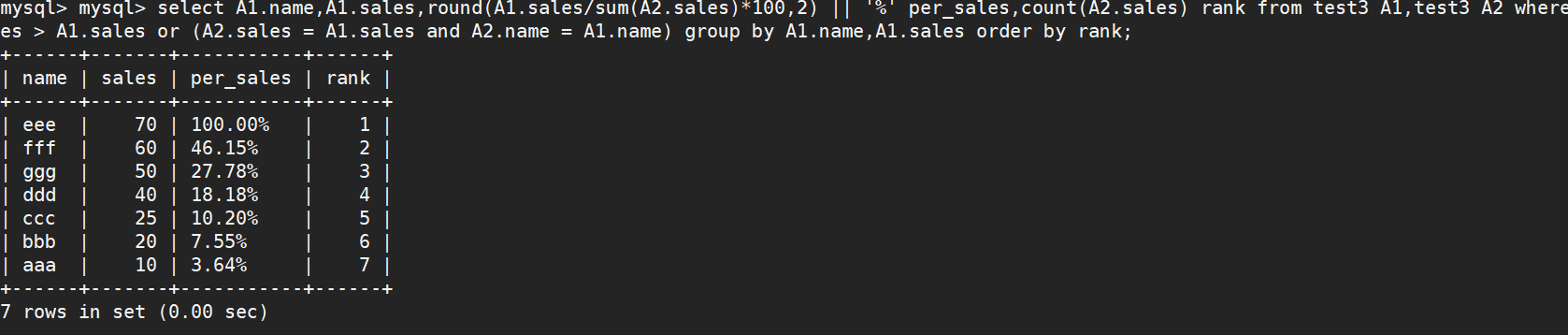
select A1.Name, A1.Sales, ROUND(A1.Sales/(select sum(A2.Sales) from test3)*100,2) || '%' Per_Sales l,count(A2.Sales) Rank from test3 A1, test3 A2 where A2.Sales > A1.Sales or (A2.Sales = A1.Sales and A2.Name >= A1.Name) GROUP BY A1.Name,A1.Sales ORDER BY rank;
六、空值(null)和无值('')
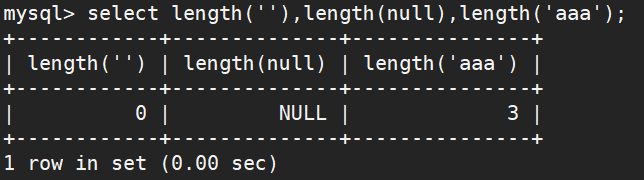
空值长度为0,不占空间
NULL值的长度为null,占用空间
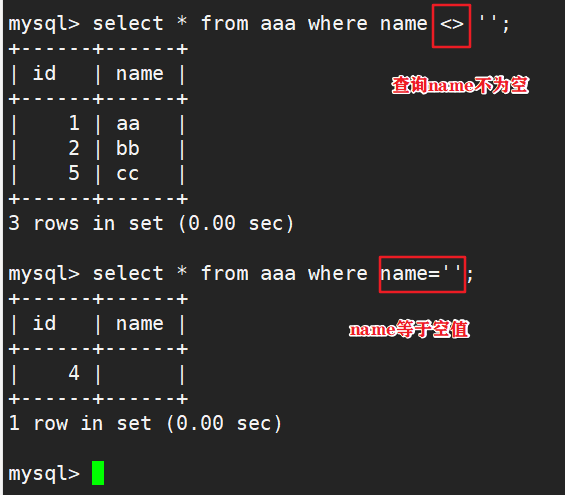
is null 无法判断空值
空值使用“=”或者“<>”来处理
count()计算时,NULL会被忽略,空值会加入计算

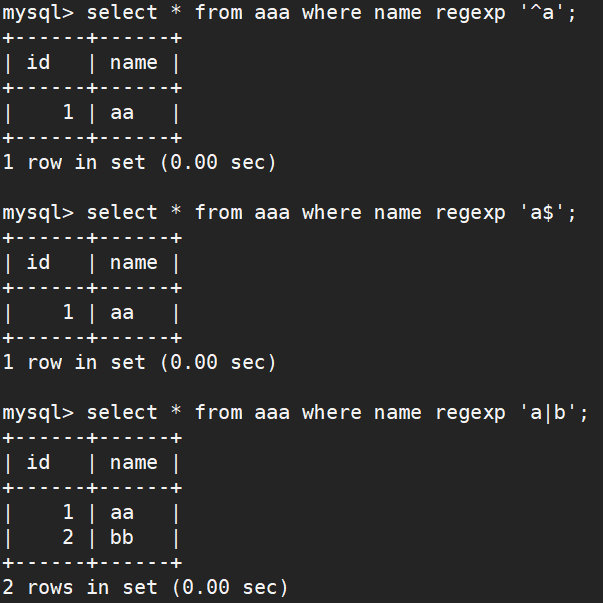
七、正则表达式
| 正则表达式 | 说明 |
|---|---|
| ^ | 匹配文本的开始字符 |
| $ | 匹配文本的结束字符 |
| . | 匹配任何单个字符 |
| * | 匹配零个或多个在它前面的字符 |
| + | 匹配前面的字符1次或多次 |
| 字符串 | 匹配包含指定的字符串 |
| p1 | p2 |
| […] | 匹配字符集合中的任意一个字符 |
| [^…] | 匹配不在括号中的任何字符 |
| 匹配前面的字符串n次 | |
| 匹配前面的字符串至少n次,至多m次 |
select 字段 from 表名 where 字段 regexp '正则表达式';
八、存储过程
8.1、存储过程概念
- mysql数据库存储过程是一组为了完成特定功能的sql语句的集合
- 存储过程这个功能是从5.0版本才开始支持的,它可以加快数据库的处理速度,增强数据库在实际应用中的灵活性
- 存储过程中在使用过程中是将常用或者复杂的工作预先使用sql语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可
- 操作数据库的传统sql语句在执行时需要先编译,然后再去执行,跟存储过程一对比,明显存储过程在执行上速度更快,效率更高
8.2、优点
- 执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
- sql语句加上控制语句的集合,灵活性高
- 在服务器端存储,客户端调用时,降低网络负载
- 可多次重复被调用,可随时修改,不影响客户端调用
- 可完成所有的数据库操作,也可控制数据库的信息访问权限
8.3、格式
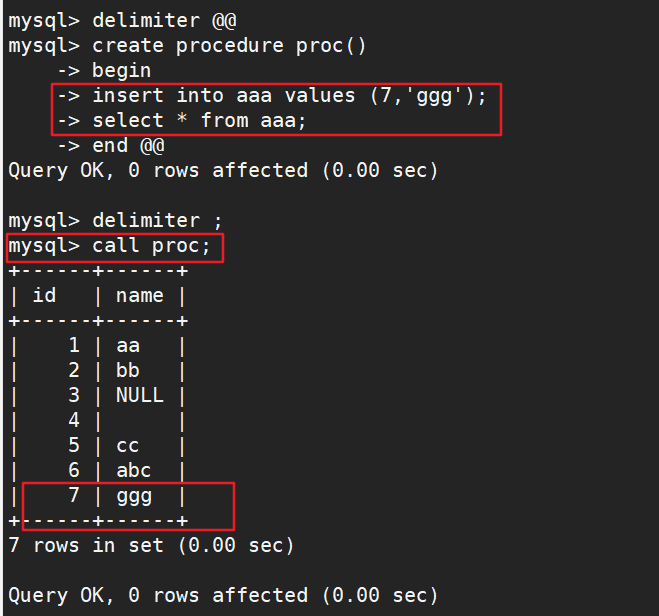
#创建存储过程
delimiter 结束符 #将语句的结束符号从分号;临时修改,以防出问题,可以自定义
create procedure 过程名() #创建存储过程,过程名,括号中不带参数
begin #过程体以关键字BEGIN开始
select * from 表格 where 条件语句; #过程体语句
end 结束符 #过程体以关键字END结尾
delimiter ; #存储过程后结束符换回分号
#调用存储过程
call 过程名;
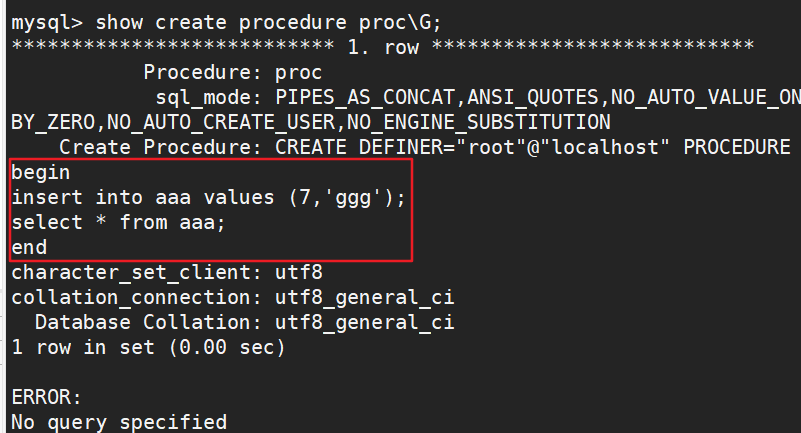
#查看存储过程
show create procedure [数据库.] 存储过程名; #查看某个储存过程的具体信息
show create procedure proc\G;
show procedure status [like '%proc%'] \G;
#删除存储过程
drop procedure if exists 过程名;
#仅在存在删除,不加if exists ,如果不存在,则会报错

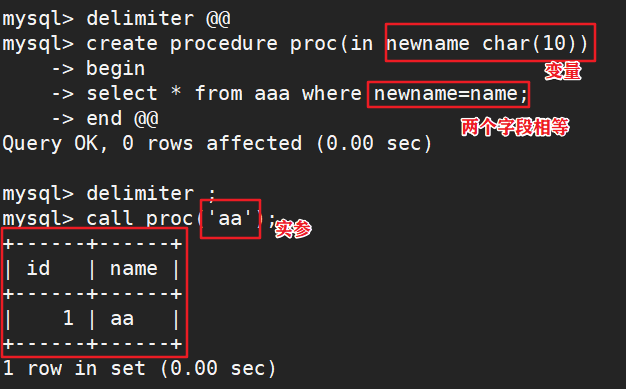
#输入参数:in表示调用者向过程传入值(传入值可以是字面量或变量)
#输出参数:out表示你过程向调用者传出值(可以返回多个值)(传出值只能是变量)
#输入\输出参数:inout,即表示调用者向过程传入值,又表示过程向调用者传入值(只能是变量)
delimiter 结束符
create procedure proc(in 参数 字段类型) #形参
begin
select * from 表格 where 条件语句; #过程体语句
end $$
delimiter ;
call proc('数据'); #实参
8.4、存储过程的控制语句
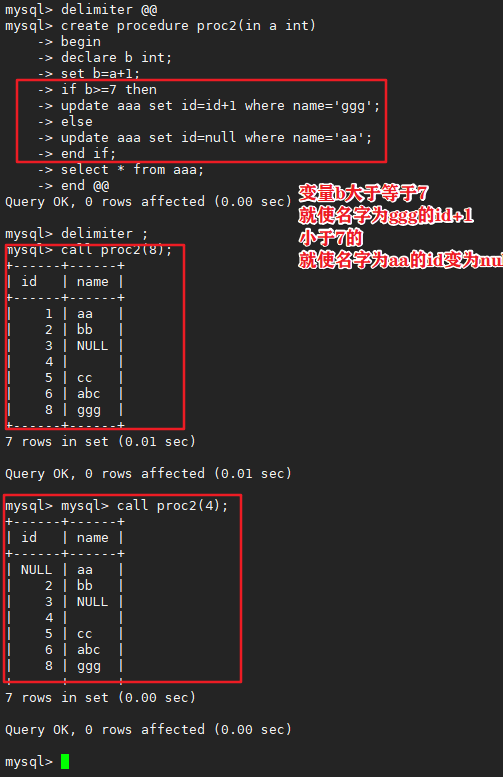
条件语句if...end if
delimiter @@
create procedure proc2(in a int) #参数a
begin
declare b int; #参数b与上面参数a类型一致
set b=a*2; #参数b与参数a之间的条件语句
if b>=25 then
update 表格 set 修改字段数据 where 条件语句;
else
update 表格 set 修改字段数据 where 条件语句;
end if ;
select * from aaa;
end @@
delimiter ;
call proc2 (参数a具体值);
循环语句while...end while
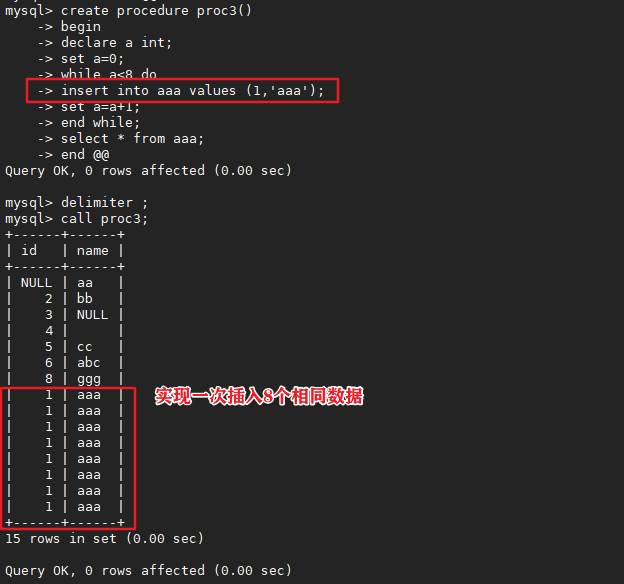
delimiter @@
create procedure proc3()
begin
declare a int;
set a=0;
while a<6 do
update 表格 set 修改字段数据 where 条件语句;
set a=a+1;
end while;
select * from aaa;
end @@
delimiter ;
call proc3;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号