
4.10:Spark之wordcount
〇、概述
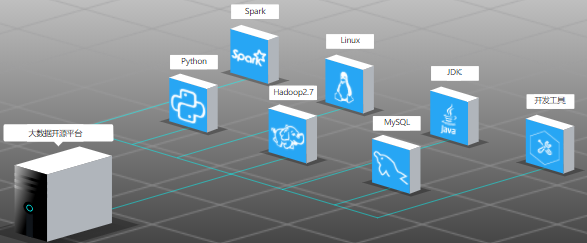
1、拓扑结构
2、目标
使用spark完成计数实验
一、启动环境
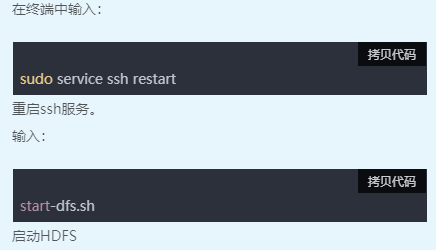
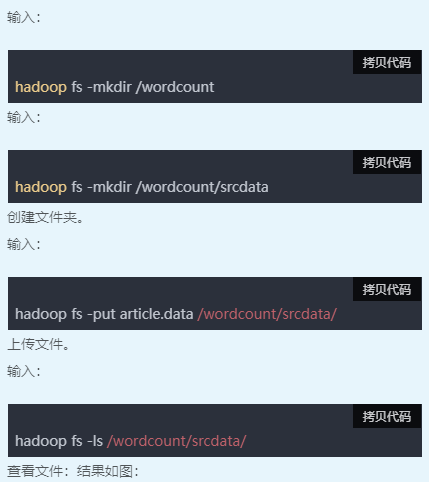
二、新建数据文件

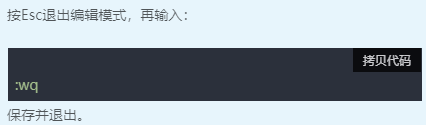
三、查看文件内容

四、启动spark服务
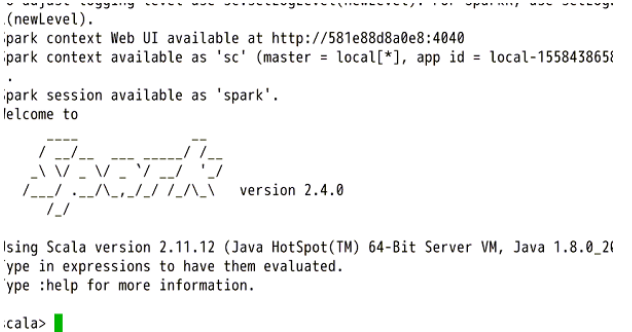
五、编写代码
复制以下代码到shell中(复制后在终端右键->粘贴):
import org.apache.spark.HashPartitioner
import java.io.PrintWriter
import java.io.File
val links = sc.parallelize(List(("A",List("B","C")),("B",List("A","C")),("C",List("A","B","D")),("D",List("C")))).partitionBy(new HashPartitioner(100)).persist()
var ranks=links.mapValues(v=>1.0)
for (i <- 0 until 10) {
val contributions=links.join(ranks).flatMap {
case (pageId,(links,rank)) => links.map(dest=>(dest,rank/links.size))
}
ranks=contributions.reduceByKey((x,y)=>x+y).mapValues(v=>0.15+0.85*v)
}
ranks.sortByKey().collect()
var input = sc.textFile("hdfs://localhost:9000/wordcount/srcdata/article.data")
val writer = new PrintWriter(new File("/home/user/bigdata/spark_output.txt"))
writer.println(input.flatMap(x=>x.split(" ")).countByValue())
writer.close()
input.flatMap(x=>x.split(" ")).countByValue()
之后可以查看输出结果。

本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/16389026.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号