

VMware搭建hadoop伪分布式环境
1.前言
What Is Apache Hadoop?
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
The project includes these modules:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets
2.环境要求
Supported Platforms
-
GNU/Linux is supported as a development and production platform. Hadoop has been demonstrated on GNU/Linux clusters with 2000 nodes.
-
Windows is also a supported platform but the followings steps are for Linux only. To set up Hadoop on Windows, see wiki page.
Required Software
Required software for Linux include:
-
Java™ must be installed. Recommended Java versions are described at HadoopJavaVersions.
-
ssh must be installed and sshd must be running to use the Hadoop scripts that manage remote Hadoop daemons.
Installing Software
If your cluster doesn’t have the requisite software you will need to install it.
For example on Ubuntu Linux:
$ sudo apt-get install ssh $ sudo apt-get install rsync
3.安装模式
4.实验环境
VM:VMware10.0
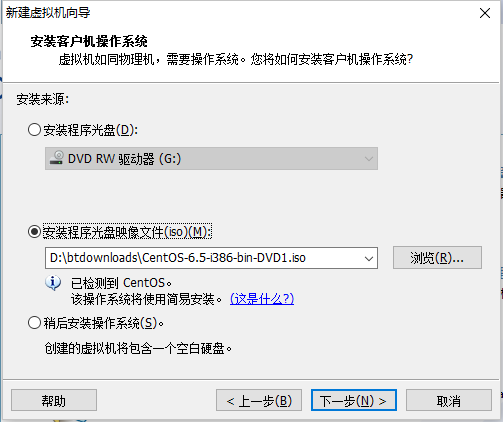
OS:CentOS-6.5-i386-bin-DVD1.iso
jdk: jdk-8u101-linux-i586.rpm
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html
hadoop:hadoop-2.7.3.tar.gz
下载地址:http://hadoop.apache.org/#Download+Hadoop
hadoop节点设计

5.实验过程
5.1 安装VMware10.0

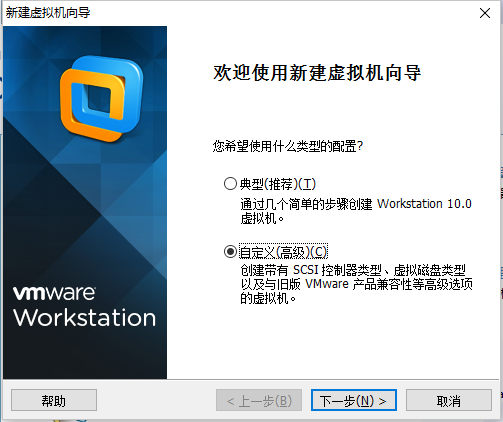
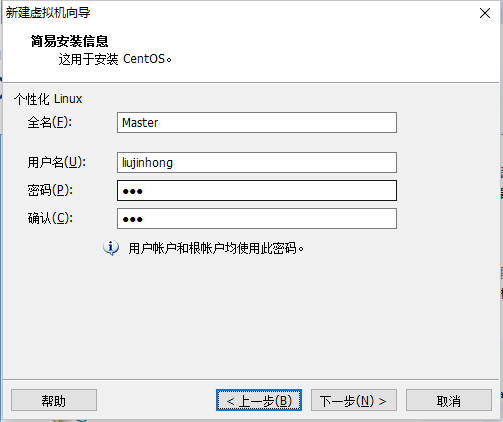
5.2 创建新的虚拟机
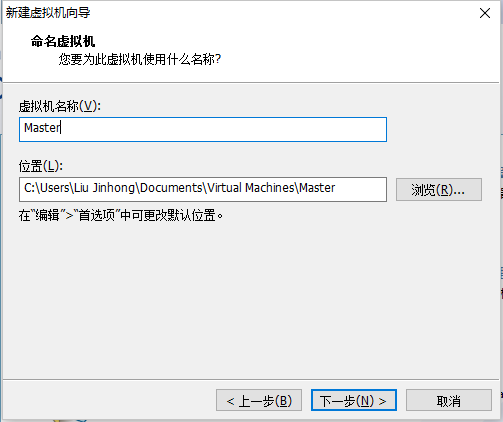
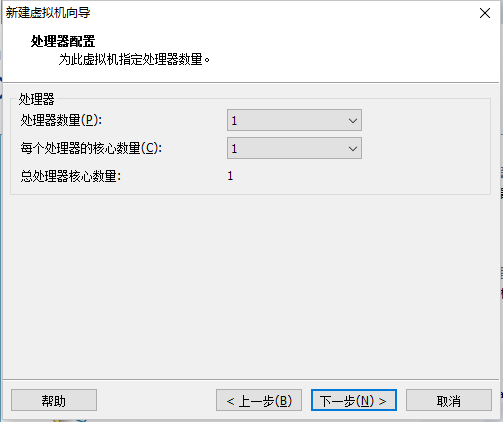

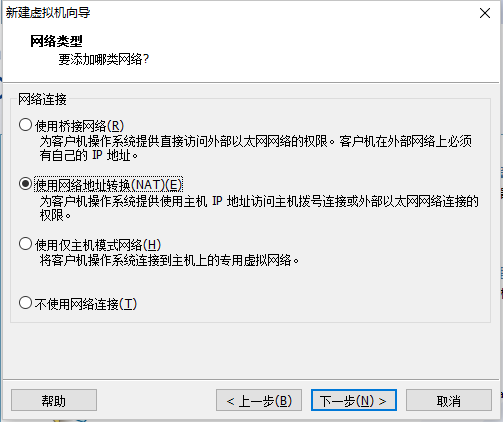

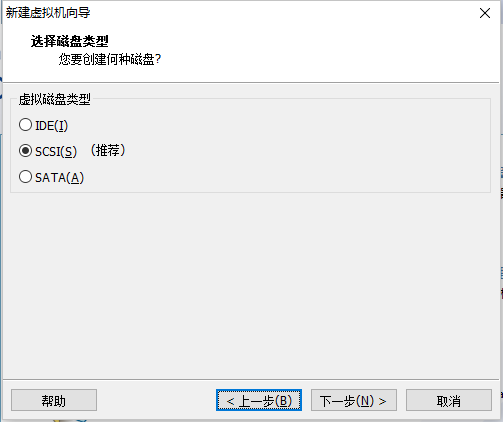
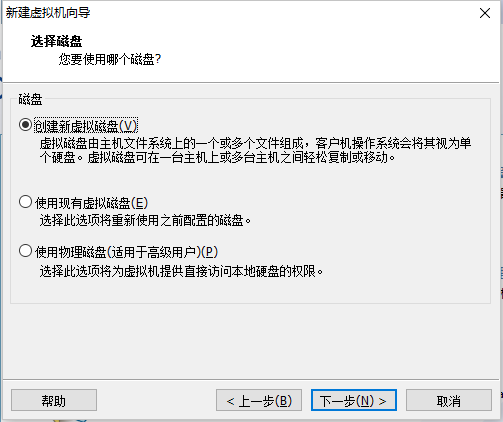
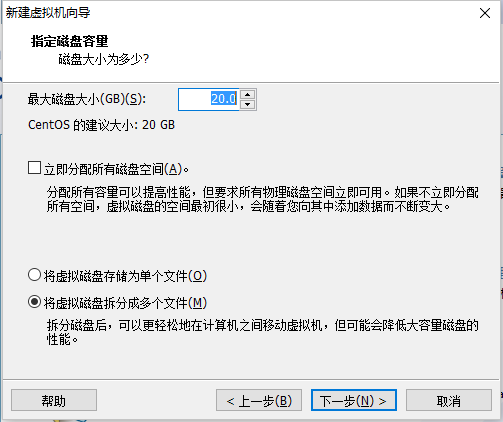


点击完成开始安装即可。
5.4 克隆一台节点
这样我们就有两台主机,一台master,一台slave。
5.5 网络配置
Hadoop集群要按照一开始设计进行配置,我们在
下面的例子我们将以namenode机器为例,即主机名为"namenode",IP为"192.168.36.128"进行一些主机名配置的相关操作。其他的Slave机器以此为依据进行修改。
1)查看当前机器名称
hostname

上图中,用"hostname"查"Master"机器的名字为"namenode",与我们预先规划的一致。
2)修改当前机器的名称
假定我们发现我们的机器的主机名不是我们想要的,通过对"/etc/sysconfig/network"文件修改其中"HOSTNAME"后面的值,改成我们规划的名称。
这个"/etc/sysconfig/network"文件是定义hostname和是否利用网络的不接触网络设备的对系统全体定义的文件。
设定形式:设定值=值
"/etc/sysconfig/network"的设定项目如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号