Go-day04
今日概要:
1.内置函数、递归函数、闭包
2.数组与切片
3.map数据结构
4.package介绍
5.互斥锁和读写锁
一、内置函数
1.close:主要用来关闭channel
2.len:用来求长度,比如string、array、slice、map、channel
3.new:用来分配内存,主要用来分配值类型,比如int,struct返回的是指针
4.make:用来分配内存,主要用来分配引用类型,比如chan,map,slice
5.append:用来追加元素到数组、slice
6.panic和recover:用来做错误处理
new的例子:
package main
import "fmt"
func main() {
var i int
fmt.Println(i)
j := new(int) //值类型分配内存地址
fmt.Println(j) //打印的是内存地址
*j = 100
fmt.Println(*j) //打印指针对应的值
}
/*
0
0xc420014060
100
*/
new和make的区别:

package main
import "fmt"
func mytest(){
a := new([]int) //创建一个容量为0的切片,a为内存地址,当前为nil不能放值
b := make([]int,10)
fmt.Println(a)
fmt.Println(b)
//将切片插入值,a为内存地址只能操作指针
*a = make([]int,5) //通过make初始化容量为5
(*a)[0] = 100 //panic: runtime error: index out of range 因为空切片需要初始化
b[0] = 100
fmt.Println(a)
fmt.Println(b)
}
func main() {
mytest()
}
/*
&[]
[0 0 0 0 0 0 0 0 0 0]
&[100 0 0 0 0]
[100 0 0 0 0 0 0 0 0 0]
*/
内置变量append
数组里append数组可以用数组...添加
目前有用到...的有 函数的可变长参数...,append加数组... 数组设置不想设置容量的时候 var a [...]int
package main
import "fmt"
func main() {
var a []int
a = append(a,20,3,40)
a = append(a,a...) //数组和数组相加可以用数组...
fmt.Println(a)
}
内置变量panic和recover
recover是捕获异常,可以让服务不停止,比如一些异常想报警,但是又保证服务正常运行可以用defer+recover
package main
import (
"time"
_ "fmt"
"errors"
)
func getConfig() (err error){
return errors.New("init config failed!") //创建异常
}
func test(){
/*
//通过recover捕获异常程序不退出
defer func(){
if err := recover(); err != nil{
fmt.Println(err)
}
}()
b := 0
a := 100 / b //异常
fmt.Println(a)
*/
err := getConfig()
if err != nil{
panic(err) //通过panic抛出异常与python中的raise一样
}
return
}
func main() {
for {
test()
time.Sleep(time.Second * 1)
}
}
二、递归函数
go里面的递归函数和python的很像,python支持递归1000层,go支持的远远大于python
设计原则
1.一个大问题能够分解成相似的小问题
2.定义好出口条件
通过递归求阶乘
package main
import "fmt"
//通过递归求阶乘
func calc(n int) int{
if n == 1{
return 1
}
return calc(n-1) *n
}
func main() {
m := calc(5)
fmt.Println(m)
}
/*
120
*/
通过递归求斐波那契
package main
import "fmt"
func fab(n int) int{
if n <= 1{
return 1
}
return fab(n-1) + fab(n-2)
}
func main() {
for i :=0 ; i < 10 ; i++ {
fmt.Println(fab(i))
}
}
/*
1
1
2
3
5
8
13
21
34
55
*/
三、闭包
一个函数和与其相关的引用环境组合而成的实体,相当于闭包里面的变量,所有闭包都能读取
闭包例子一:
package main
import "fmt"
//返回值是一个func函数
func Adder() func (int) int { //类似一个类,x为类变量,修改都生效
var x int
return func(d int) int{//定义了一个匿名函数
x += d
return x
}
}
func main() {
f := Adder()
fmt.Println(f(1))
fmt.Println(f(20))
fmt.Println(f(100))
}
/*
1
21
121
*/
闭包例子二:
定义的时候传入了参数,类似于python里的实例化
package main
import (
"strings"
"fmt"
)
type str func(string) string
func makeSuffix(suffix string) str { //make的时候传入suffix
return func(name string) string{
if strings.HasSuffix(name,suffix) == false{
return name + suffix
}
return name
}
}
func main() {
f1 := makeSuffix(".mp3")
fmt.Println(f1("bgm"))
f2 := makeSuffix(".mp4")
fmt.Println(f2("av"))
}
/*
bgm.mp3
av.mp4
*/
四、数组与切片
数组:
1.数组:是同一种数据类型的固定长度的序列。
2.数组定义:var a [len]int,比如:var a [5]int 一旦定义,长度不能改变
3.长度是数组类型的一部分,因此,var a [5] int和var a [10]int是不同的类型
4.数组可以通过下标进行访问,下标是从0开始,最后一个元素下标是:len-1
5.访问越界,如果下标在数组合法范围之外,则触发访问越界,会panic
6.数组是值类型,因此改变副本的值,不会改变本身的值
定义6的验证:
package main
import "fmt"
func test2(){
var a [10]int //数组是值变量,赋值之后新的改变,老的不会改变
b := a
b[0] = 100
fmt.Println(a) //[0 0 0 0 0]
}
func main() {
test1()
}
/*
[0 0 0 0 0]
*/
变成指针修改当前数据原数据也被修改
package main
import "fmt"
func test3(a *[5]int){ //变成指针就成为引用类型
(*a)[0] = 10
}
func main() {
var a [5]int
test3(&a)
fmt.Println(a)
}
/*
[10 0 0 0 0]
*/
练习:
使用非递归的方式实现斐波那契数列,打印前100个数
package main
import "fmt"
func fab1(n int){
var sli []int64 //声明了一个切片
sli = make([]int64,n)//将切片设定容量
sli[0] = 1
sli[1] = 1
for i :=2 ; i < len(sli);i++{
sli[i] = sli[i-1] + sli[i-2]
}
for _,value := range sli{ //通过for,range遍历切片
fmt.Println(value)
}
}
func main() {
fab1(10)
}
/*
1
1
2
3
5
8
13
21
34
55
*/
循环数组的两种方式:
package main
import "fmt"
func test1(){
var a [5]int //定义一个数组
fmt.Println(a)
//循环数组两种方式
//方式一
for i := 0; i < len(a) ; i++{
fmt.Println(a[i])
}
//方式二
for key,value := range a{
fmt.Printf("%d=[%d]\n",key,value)
}
}
func main() {
test1()
}
数组的初始化:
a. var age0 [5]int = [5]int{1,2,3}
b. var age1 = [5]int{1,2,3,4,5}
c. var age2 = […]int{1,2,3,4,5,6} 编译的时候自动求出来长度
d. var str = [5]string{3:”hello world”, 4:”tom”}
多维数组和多维数组遍历
a. var age [5][3]int
b. var f [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}} 定义了一个二维数组
例子:
package main
import "fmt"
//数组的初始化
func testArray(){
var a [5]int = [5]int{1,2,3,4,5}
var a1 = [5]int{2,3,4,5,6}
var a2 = [...]int{1,2,3}
var a3 = [...]string{1:"hello",3:"world"}
fmt.Println(a)
fmt.Println(a1)
fmt.Println(a2)
fmt.Println(a3)
}
//多维数组
func testArray1() {
var a = [2][5]int{{1,2,3,4,5},{6,7,8,9,0}} //第一个是有几个{},第二个是每个{}有几个元素
fmt.Println(a)
var b = [...][5]int{{1,2,3,4,5},{6,7,8,9,0}} //一维可以加...,其他不行
fmt.Println(b)
//多维数组遍历
for row,v := range a{
for col,v1 := range v{
fmt.Printf("row:%d,col:%d,val:%d\t",row,col,v1)
}
fmt.Println()
}
}
func main() {
testArray()
testArray1()
}
/*
[1 2 3 4 5]
[2 3 4 5 6]
[1 2 3]
[ hello world]
*/
切片:
1. 切片:切片是数组的一个引用,因此切片是引用类型
2. 切片的长度可以改变,因此,切片是一个可变的数组
3. 切片遍历方式和数组一样,可以用len()求长度
4.cap可以求出slice最大的容量,0 <= len(slice) <= (array),其中array是slice引用的数组
5. 切片的定义:var 变量名 []类型,比如 var str []string var arr []int
6. 切片初始化:var slice []int = arr[start:end] 包含start到end之间的元素,但不包含end
7. var slice []int = arr[0:end]可以简写为 var slice []int=arr[:end]
8. var slice []int = arr[start:len(arr)] 可以简写为 var slice[]int = arr[start:]
9. var slice []int = arr[0, len(arr)] 可以简写为 var slice[]int = arr[:]
10. 如果要切片最后一个元素去掉,可以这么写: slice = slice[:len(slice)-1]
关于容量详解:
Array_a := [10]byte{'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'}
Slice_a := Array_a[2:5]
上面的代码真实存储方式,cap的容量是截取空间到最后的大小
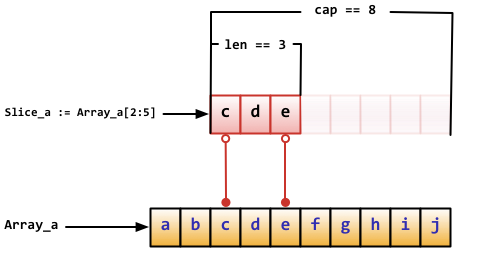
练习:
package main
import "fmt"
func testSlice1() {
//切片是引用类型,传入函数中会改变原有值
var slice []int
var arr [5]int = [5]int{1, 2, 3, 4, 5}
slice = arr[:]
slice = slice[1:]
slice = slice[:len(slice)-1] //刨除最后一个
fmt.Println(slice)
fmt.Println(len(slice))
fmt.Println(cap(slice))
slice = slice[0:1] //切片可以在切片,这样cap容量不变,len会变小
fmt.Println(len(slice))
fmt.Println(cap(slice))
}
func main() {
testSlice1()
}
/*
[2 3 4]
3
4
1
4
*/
切片的内存布局:
切片本质上最底层还是数组,切片只是指针指向切片第一个值的内存地址,如果切片append的容量大于数组容量,底层会重新创建一个数组cap的值是成倍增长的
append函数会改变slice所引用的数组的内容,从而影响到引用同一数组的其它slice。 但当slice中没有剩余空间(即(cap-len) == 0)时,此时将动态分配新的数组空间。返回的slice数组指针将指向这个空间,而原数组的内容将保持不变;其它引用此数组的slice则不受影响。

验证切片的内存地址和原数组切片第一个值的内存地址一致:
package main
import "fmt"
func testArray2(){
var a = [10]int{1,2,3,4}
b := a[1:3]
fmt.Printf("%p\n",b) //验证b切片和数组内存地址一样,证明切片就是指针
fmt.Printf("%p\n",&a[1])//因为从第一个元素切的所以指针指向第一个内存地址
}
func main() {
testArray2()
}
/*
0xc42001a0f8
0xc42001a0f8
*/
通过自定义切片slice模拟切片操作
package main
import "fmt"
type slice struct { //封装成一个结构体
ptr *[100]int
len int
cap int
}
func make1(s slice,cap int) slice{
s.ptr = new([100]int)
s.cap = cap
s.len = 0
return s
}
func modify(s slice){
s.ptr[1] = 1000
}
func testSlice(){
var s1 slice
s1 = make1(s1,10)
s1.ptr[0] = 100
modify(s1)
fmt.Println(s1.ptr)
}
func main() {
testSlice()
}
/*
&[100 1000 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
*/
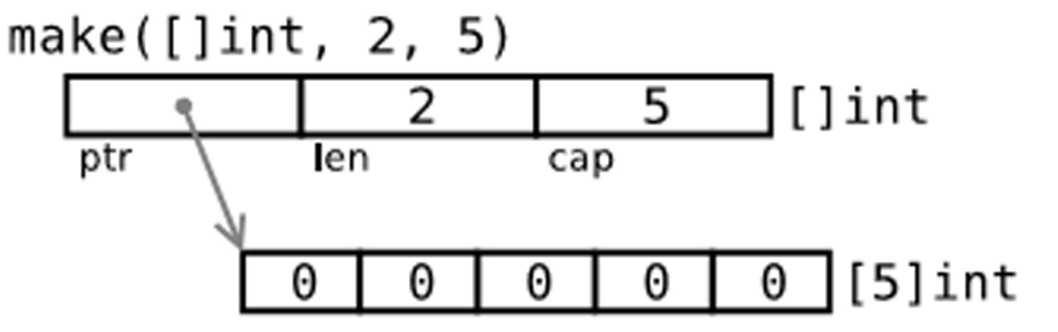
通过make来创建切片
var slice []type = make([]type, len)
slice := make([]type, len)
slice := make([]type, len, cap)
底层实现(生成了一个cap为5的数组,将切片的指针指向数组的第一个值):
用append内置函数操作切片:
slice = append(slice, 10)
var a = []int{1,2,3}
var b = []int{4,5,6}
a = append(a, b…) 切片插入切片的时候用切片名加...
练习:
package main
import "fmt"
func testArray3(){
var arr [5]int = [...]int{1,2,3,4,5}
s := arr[1:3]
fmt.Printf("before:len[%d],cap[%d]\n",len(s),cap(s))
s[1] = 100
fmt.Printf("arr=%p,slice=%p\n",&arr[1],s)
fmt.Println("before append",arr)
s = append(s,10)
s = append(s,10)
s = append(s,10)
fmt.Printf("after:len[%d],cap[%d]\n",len(s),cap(s)) //容量翻倍增加
s = append(s,10)
s = append(s,10)
s[1] = 1000
fmt.Println(s)
fmt.Println("after append",arr) //a的值还会变,只不过没超出之前改的还是原来的内存地址
fmt.Printf("arr=%p,slice=%p\n",&arr[1],s) //切片是可变长的,底层会创建一个新的数组,将指针指向新的数组
}
func main() {
testArray3()
}
/*
before:len[2],cap[4]
arr=0xc42001c098,slice=0xc42001c098
before append [1 2 100 4 5]
after:len[5],cap[8]
[2 1000 10 10 10 10 10]
after append [1 2 100 10 10]
arr=0xc42001c098,slice=0xc420018080
*/
for range切片遍历:
for index, val := range slice {
}
切片resize
var a = []int {1,3,4,5}
b := a[1:2]
b = b[0:3]
切片copy
package main
import "fmt"
func testCopy(){
var a []int = []int{1,2,3,4,5}
b := make([]int,10) //[0,0,0,0,0,0,0,0,0,0]
copy(b,a) //内置方法copy
fmt.Println(b)
}
func main() {
testCopy()
}
/*
[1 2 3 4 5 0 0 0 0 0]
*/
string和slice
string底层就是一个byte的数组,因此,也可以进行切片操作
string的底层布局
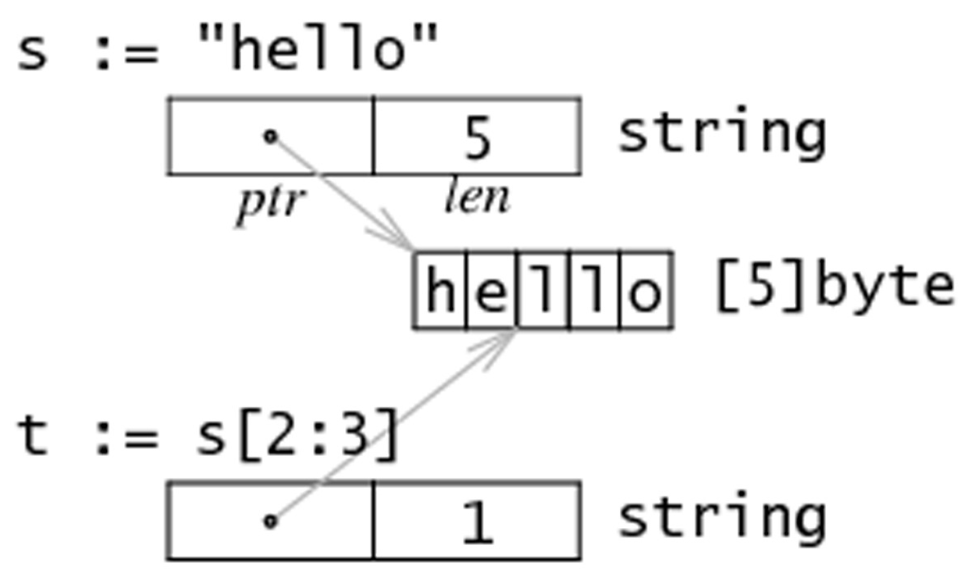
如何改变string中的字符值?
string本身是不可变的,因此要改变string中字符,需要如下操作:
package main
import "fmt"
func testModifyString(){
var a string = "我hello world"
b := []rune(a) //有中文的时候需要通过字符数组更改,强制转为数组
b[0] = '1'
fmt.Println(string(b))
}
func main() {
testModifyString()
}
slice的排序和查找操作:
排序操作主要都在 sort包中,导入就可以使用了
sort.Ints对整数进行排序, sort.Strings对字符串进行排序, sort.Float64s对浮点数进行排序.
sort.SearchInts(a []int, b int) 从数组a中查找b,前提是a必须有序
sort.SearchFloats(a []float64, b float64) 从数组a中查找b,前提是a必须有序
sort.SearchStrings(a []string, b string) 从数组a中查找b,前提是a必须有序
练习:
package main
import (
"sort"
"fmt"
)
func testIntSort(){
var a = [...]int{22,33,1,3,4} //数组是不能排序的,因为他是值类型
sort.Ints(a[:]) //将传入的值变为切片
fmt.Println(a)
}
func testStringSort(){
var a = [...]string{"aa","ccc","bbb","ffff"}
sort.Strings(a[:])
fmt.Println(a)
}
func testFloatSort(){
var a = [...]float64{0.38,0.02,0.01,0.44}
sort.Float64s(a[:])
fmt.Println(a)
}
func testIntSearch(){
var a = [...]int{22,33,1,3,4}
sort.Ints(a[:])
index := sort.SearchInts(a[:],22) //即便你不排序,默认也会排序,但是值会混乱
fmt.Println(index)
}
func main() {
testIntSort()
testStringSort()
testFloatSort()
testIntSearch()
}
/*
[1 3 4 22 33]
[aa bbb ccc ffff]
[0.01 0.02 0.38 0.44]
3
*/
注:从Go1.2开始slice支持了三个参数的slice,之前我们一直采用这种方式在slice或者array基础上来获取一个slice
var array [10]int slice := array[2:4]
这个例子里面slice的容量是8,新版本里面可以指定这个容量
slice = array[2:4:7] 第三位是容量
上面这个的容量就是7-2,即5。这样这个产生的新的slice就没办法访问最后的三个元素。
如果slice是这样的形式array[:i:j],即第一个参数为空,默认值就是0。
五、map(类似python的dict)
key-value的数据结构,又叫字典或关联数组
a.声明
声明是不会分配内存的,初始化需要make
var map1 map[keytype]valuetype
var a map[string]string
var a map[string]int
var a map[int]string
var a map[string]map[string]string
b.map的相关操作
var a map[string]string = map[string]string{“hello”: “world”} 声明加赋值
a = make(map[string]string, 10) 初始化map
a[“hello”] = “world” 插入
val, ok := a[“hello”] 查找2个返回值,第一个是值,第二个为是否查到
for k, v := range a { 遍历map
fmt.Println(k,v)
}
delete(a, “hello”) 删除map中的key
len(a) 求map长度
例子:声明初始化和make初始化
package main
import "fmt"
func testMap(){
//声明初始化
var a map[string]string = map[string]string{
"asdas":"asdsdasd",
}
//make初始化
//a := make(map[string]string,10)
a["abc"] = "cde"
fmt.Println(a)
}
func main() {
testMap()
}
map是引用类型:
func modify(a map[string]int) {
a[“one”] = 134 //原来的map也会改变
}
slice里面放map
items := make([]map[int][int], 5)
for I := 0; I < 5; i++ {
items[i] = make(map[int][int])
}
练习:
package main
import "fmt"
func testMap(){
//声明初始化
var a map[string]string = map[string]string{
"asdas":"asdsdasd",
}
//make初始化
//a := make(map[string]string,10)
a["abc"] = "cde"
fmt.Println(a)
}
//多维数组
func testMap2(){
//因为有2层数组,需要初始化两次,才能使用,map,chan,slice都需要初始化,声明为nil
a := make(map[string]map[string]string,100)
a["key1"] = make(map[string]string,10)
a["key1"]["key2"] = "val1"
a["key1"]["key3"] = "val2"
a["key1"]["key4"] = "val3"
a["key1"]["key5"] = "val4"
fmt.Println(a)
}
func modify2 (a map[string]map[string]string){
//查找
_, ok := a["zhangsan"] //固定写法,第一个为值,第二个为bool
if !ok {
a["zhangsan"] = make(map[string]string) //判断zhangsan是否存在,不存在就创建zhangsan与对应都map
}
/* 等价写法
if a["zhangsan"] == nil{
a["zhangsan"] = make(map[string]string)
}
*/
a["zhangsan"]["nickname"] = "pangpang"
a["zhangsan"]["age"] = "18"
return
}
//多维数组做用户信息保存
func testMap3(){
a := make(map[string]map[string]string,100)
modify2(a)
fmt.Println(a)
}
func trans(a map[string]map[string]string){
//遍历map
for k,v := range a{
fmt.Println(k)
for k1,v1 := range v{
fmt.Println("\t",k1,v1)
}
}
}
//多维数组一些操作
func testMap4(){
//遍历map
a := make(map[string]map[string]string,100)
a["key1"] = make(map[string]string,10)
a["key1"]["key2"] = "val1"
a["key1"]["key3"] = "val2"
a["key1"]["key4"] = "val3"
a["key1"]["key5"] = "val4"
a["key2"] = make(map[string]string,10)
a["key2"]["key2"] = "val1"
a["key2"]["key3"] = "val2"
trans(a)
//删除map中key,map要全部清空for循环,或者重新make下
delete(a,"key1")
trans(a)
//求长度
fmt.Println(len(a))
}
func testMap5(){
var a []map[int]int
a = make([]map[int]int,5)
if a[0] == nil{ //默认只声明的map,或者slice都是nil
a[0] = make(map[int]int)
}
a[0][10] = 100
fmt.Println(a)
}
func main() {
//testMap()
//testMap2()
//testMap3()
//testMap4()
testMap5()
}
map的排序
a. 先获取所有key,把key进行排序
b. 按照排序好的key,进行遍历
package main
import (
"fmt"
"sort"
)
func testMapSort(){
//保证排序正常
var a map[int]int
a = make(map[int]int,5)
a[0] = 1
a[2] = 3
a[3] = 4
a[10] =100
fmt.Println(a)
var keys []int
for k, _ := range a{
keys = append(keys,k) //append会直接增加不需要make
}
sort.Ints(keys)
for _,v := range keys{
fmt.Println(a[v])
}
}
func main() {
testMapSort()
}
map的反转
a. 初始化一个新map,把key、value互换即可
package main
import (
"fmt"
)
func testMapReverse(){
//反转要新生成一个map,需要注意字符类型
var a map[string]int
a = make(map[string]int,5)
var b map[int]string
b = make(map[int]string,5)
a["aaa"] = 1
a["bbb"] = 3
for k,v := range a{
b[v] = k
}
fmt.Println(b)
}
func main() {
testMapReverse()
}
六、go中的sync包
a. import(“sync”)
b. 互斥锁, var lock sync.Mutex
c. 读写锁, var rwlock sync.RWMutex
读写锁适用范围:读多写少的场景,读写锁是互斥锁性能的100多倍
在读写锁机制下,允许同时有多个读者读访问共享资源,只有写者才需要独占资源。相比互斥机制,读写机制由于允许多个读者同时读访问共享资源,进一步提高了多线程的并发度。
go build --race 可以检查代码里是不是有重复修改数据的点
互斥锁例子:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var lock sync.Mutex //互斥锁
func testMutx(){
//go build --race 查看有没有竞争关系,编译后执行返回
//互斥锁同一时间只有一个执行
var a map[int]int
a = make(map[int]int,100)
a[0] = 1
a[1] = 2
a[2] = 3
a[3] = 4
for i := 0; i < 50 ; i++{
go func(b map[int]int){
lock.Lock() //多个goroutine同时修改同一份数据需要互斥锁
b[0] = rand.Intn(100)
lock.Unlock()
}(a)
}
lock.Lock()
fmt.Println(a)
lock.Unlock()
time.Sleep(time.Second * 1)
}
func main() {
testMutx()
}
读写锁例子:
sync/atomic 这个方法保证是原子操作(串行)
package main
import (
"sync"
//"math/rand"
"fmt"
"sync/atomic"
"time"
)
var lock sync.Mutex
var rwlock sync.RWMutex
//读写锁适用于读多写少的场景
//设置3秒,读写锁执行22万次,互斥锁执行2292次
//go get xx下载第三方包,默认会下载到gopath的src下
func testRwlock(){
var a map[int]int
a = make(map[int]int)
var count int32
a[0] = 10
a[1] = 10
a[2] = 10
a[3] = 10
a[4] = 10
for i := 0; i < 2 ; i++{
go func(b map[int]int){
//lock.Lock()
rwlock.Lock()
//b[0] = rand.Intn(100)
time.Sleep(3 * time.Millisecond)
rwlock.Unlock()
lock.Unlock()
}(a)
}
for i := 0; i < 100 ; i++{
go func(b map[int]int){
//lock.Lock()
for {
//lock.Lock()
rwlock.RLock()
//fmt.Println(a)
time.Sleep(time.Millisecond)
rwlock.RUnlock()
//lock.Unlock()
atomic.AddInt32(&count,1) //atomic原子操作,相当于串行
}
}(a)
}
time.Sleep(time.Second * 3)
fmt.Println(atomic.LoadInt32(&count)) //原子操作
}
func main() {
testRwlock()
}
练习
实现一个冒泡排序:
冒泡排序定义:
package main
import "fmt"
//切片是变长,数组是固定长度
//冒泡循环两层循环,第二个每次都从后往前确定一个值
func bsSort(a []int){
for i := 0;i < len(a);i++{
//每个元素执行一个冒泡
for j := 1; j < len(a) - i;j++{
if (a[j] < a[j-1]){ //当前值 小于 上一个值就交换位置
a[j],a[j-1] = a[j-1],a[j]
}
fmt.Println(a)
}
}
}
func main() {
slice := []int{8,7,5,4,3,10,15} //切片
bsSort(slice)
fmt.Println("finally: ",slice)
}
/*
[7 8 5 4 3 10 15]
[7 5 8 4 3 10 15]
[7 5 4 8 3 10 15]
[7 5 4 3 8 10 15]
[7 5 4 3 8 10 15]
[7 5 4 3 8 10 15]
[5 7 4 3 8 10 15]
[5 4 7 3 8 10 15]
[5 4 3 7 8 10 15]
[5 4 3 7 8 10 15]
[5 4 3 7 8 10 15]
[4 5 3 7 8 10 15]
[4 3 5 7 8 10 15]
[4 3 5 7 8 10 15]
[4 3 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
finally: [3 4 5 7 8 10 15]
*/
python实现一个冒泡排序:
L = [3, 5, 6, 7, 8, 1, 2]
for i in range(len(L)-1):
for j in range(len(L)-1-i):
if L[j] >L[j+1]:
L[j], L[j+1] = L[j+1], L[j]
print(L)
实现一个选择排序(从小到大)
package main
import "fmt"
//选择排序
func selectSort(a []int){
//先选出最小的放到最左面,在一次选择
for i := 0;i < len(a);i++{ //循环整个序列
var min int = i
for j:= i + 1; j < len(a);j++{ //循环从1:最后的序列
if (a[min] > a[j]){ //a[min] > a[j] m为当前值 大于下一个值
min = j
}
fmt.Println(a)
}
a[i],a[min] = a[min],a[i] //选出来的最小值和当前值交换
}
}
func main() {
slice := []int{8,7,5,4,3,10,15} //切片
selectSort(slice)
fmt.Println("finally: ",slice)
}
/*
[8 7 5 4 3 10 15]
[8 7 5 4 3 10 15]
[8 7 5 4 3 10 15]
[8 7 5 4 3 10 15]
[8 7 5 4 3 10 15]
[8 7 5 4 3 10 15]
[3 7 5 4 8 10 15]
[3 7 5 4 8 10 15]
[3 7 5 4 8 10 15]
[3 7 5 4 8 10 15]
[3 7 5 4 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
[3 4 5 7 8 10 15]
finally: [3 4 5 7 8 10 15]
*/
实现一个插入排序(从小到大)
package main
import "fmt"
//插入排序 从一个有序的列表里把一个元素插入进去
func insertSort(a []int){ //一个数组是有序的,另外一个数组是无序的,无序的要去有序里比大小
for i := 1;i < len(a);i++{ //这是遍历无序的列表
for j := i; j > 0 ;j--{ //这是遍历有序的列表 进行比较插入,无序列表越来越少 ,有序的列表是插入形式,依次增加
if (a[j] > a[j-1]){ //当前值 大于下一个值就终止
break
}
a[j],a[j-1] = a[j-1],a[j]
fmt.Println(a)
}
}
}
func main() {
slice := []int{8,7,5,4,3,10,15} //切片
insertSort(slice)
fmt.Println("finally: ",slice)
}
/*
7 8 5 4 3 10 15]
[7 5 8 4 3 10 15]
[5 7 8 4 3 10 15]
[5 7 4 8 3 10 15]
[5 4 7 8 3 10 15]
[4 5 7 8 3 10 15]
[4 5 7 3 8 10 15]
[4 5 3 7 8 10 15]
[4 3 5 7 8 10 15]
[3 4 5 7 8 10 15]
finally: [3 4 5 7 8 10 15]
*/
实现一个快速排序(从小到大)
package main
import "fmt"
//快速排序
func qSort(a []int,left,right int){
//选中一个值左面的比他小,右面的比他大
if left >= right{ //判断传入是否合法
return
}
val := a[left]
k := left
for i := left + 1 ; i <= right;i++{ //循环当前序列,即使被切割也是切割序列
if a[i] < val{//val是中间值,如果比val小就要放到val的左面
a[k] = a[i] //将小的数与中间值的位置交换
a[i] = a[k+1]//在将小的位置,与k的下一位交换
a[k+1] = val //将k+1的位置赋值给中间值
k++ //最终更换了一个位置所以要+1
}
}
//a[k] = val
qSort(a,left,k-1) //在左面再次排序
qSort(a,k+1,right)//右面再次排序递归
}
func main() {
slice := []int{8,7,5,4,3,10,15,20,2} //切片
qSort(slice,0,len(slice)-1)
fmt.Println("finally: ",slice)
}
/*
finally: [2 3 4 5 7 8 10 15 20]
*/
补充:
1、有些时候需要进行多个赋值操作,由于Go里面没有,操作符,那么可以使用平行赋值i, j = i+1, j-1
2、关于Slice定义:
当切片的索引范围大于len() 但是小于cap()的值,会读取原数组的 隐藏值进行填充
package main
import "fmt"
func printSlice(v []int){
fmt.Printf("slice is %v , len=(%d),cap=(%d)",v,len(v),cap(v) )
}
func main(){
a := []int{1,2,3,4,5,6,7,8,9}
printSlice(a)
b := a[2:6]
printSlice(b)
fmt.Println("before slice is\n",b)
c := b[4:6]
printSlice(c)
fmt.Println("after slice is\n",c)
}
"""
slice is [1 2 3 4 5 6 7 8 9] , len=(9),cap=(9)
slice is [3 4 5 6] , len=(4),cap=(7)
before slice is [3 4 5 6]
slice is [7 8] , len=(2),cap=(3)
after slice is [7 8] 正常应该认为是7 但是有隐藏值 8,9,10
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号