

python中pandas包的基本用法
001、 读取数据,并显示数据的维度
[root@PC1 test]# ls a.out test.py [root@PC1 test]# cat a.out ## 测试数据 id pos gpos p1 ihh1 . 7111 0.007111 0.139456 0.00604659 . 7148 0.007148 0.146259 0.00731674 . 7174 0.007174 0.0578231 0.00910391 . 8957 0.008957 0.0408163 0.0100898 . 9009 0.009009 0.0340136 0.0103555 . 9011 0.009011 0.0510204 0.01051 . 9013 0.009013 0.047619 0.0105104 . 9021 0.009021 0.047619 0.0105104 . 9026 0.009026 0.0578231 0.0104484 . 9034 0.009034 0.0442177 0.0107721 [root@PC1 test]# cat test.py ## 测试程序 #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd ## 导入pandas模块库 dat = pd.read_csv("a.out", sep = "\t") ## 读取数据 print(dat.shape) ## 输出数据维度 [root@PC1 test]# python test.py ## 执行程序 (10, 5) [root@PC1 test]# wc -l a.out 11 a.out
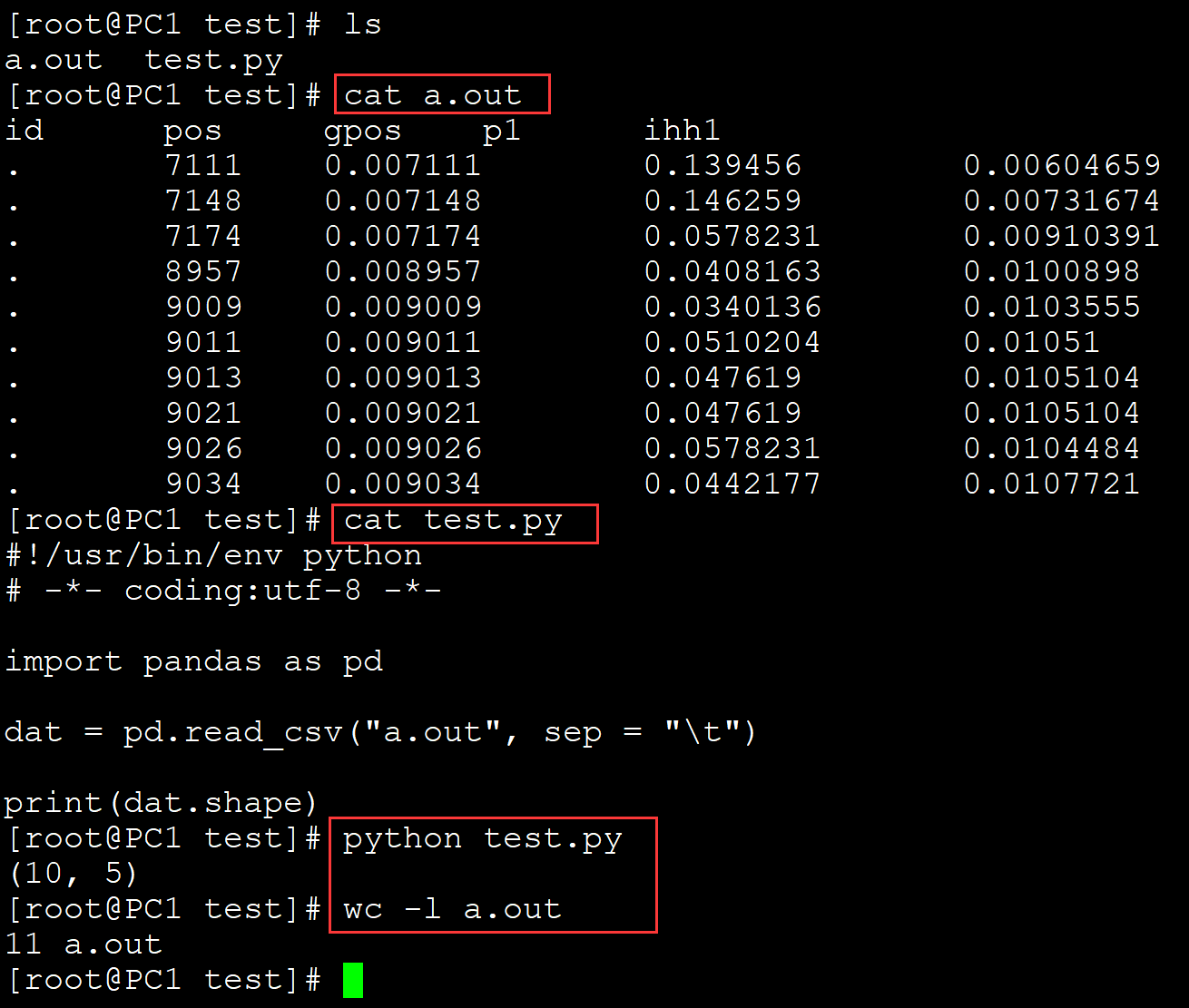
002、查看数据的前几行
[root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.head()) ## 查看文件的前几行,默认是5行 [root@PC1 test]# python test.py id pos gpos p1 ihh1 0 . 7111 0.007111 0.139456 0.006047 1 . 7148 0.007148 0.146259 0.007317 2 . 7174 0.007174 0.057823 0.009104 3 . 8957 0.008957 0.040816 0.010090 4 . 9009 0.009009 0.034014 0.010356
。
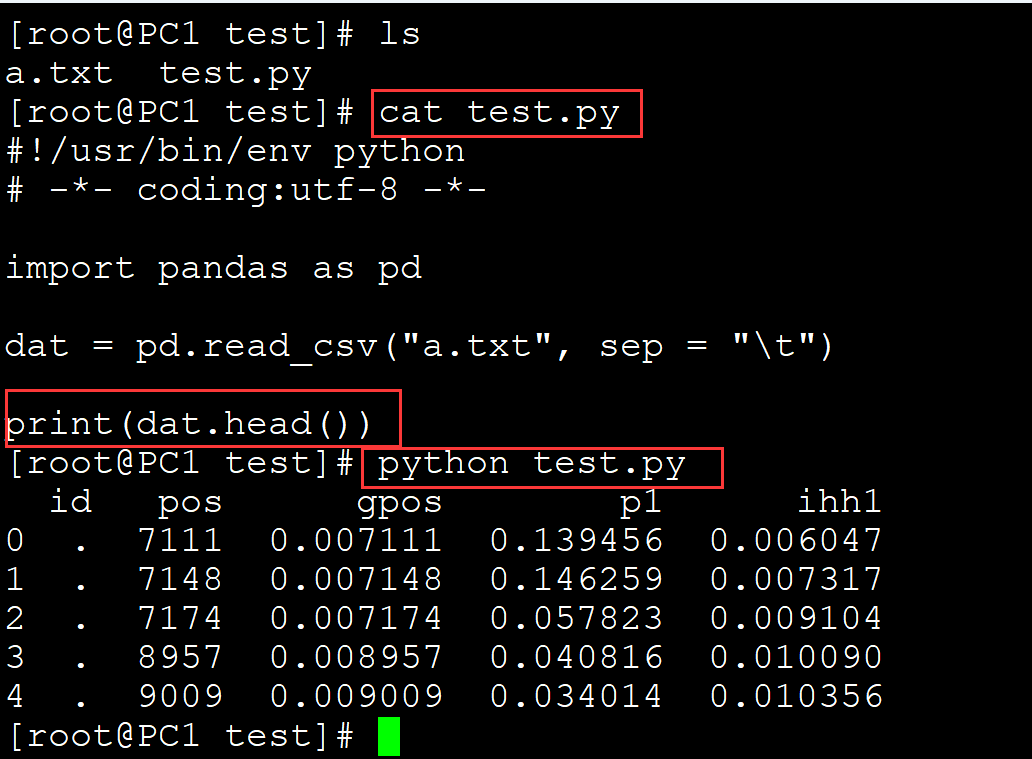
自定义行数:
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.head(3)) ## 可以自定义行数 [root@PC1 test]# python test.py id pos gpos p1 ihh1 0 . 7111 0.007111 0.139456 0.006047 1 . 7148 0.007148 0.146259 0.007317 2 . 7174 0.007174 0.057823 0.009104
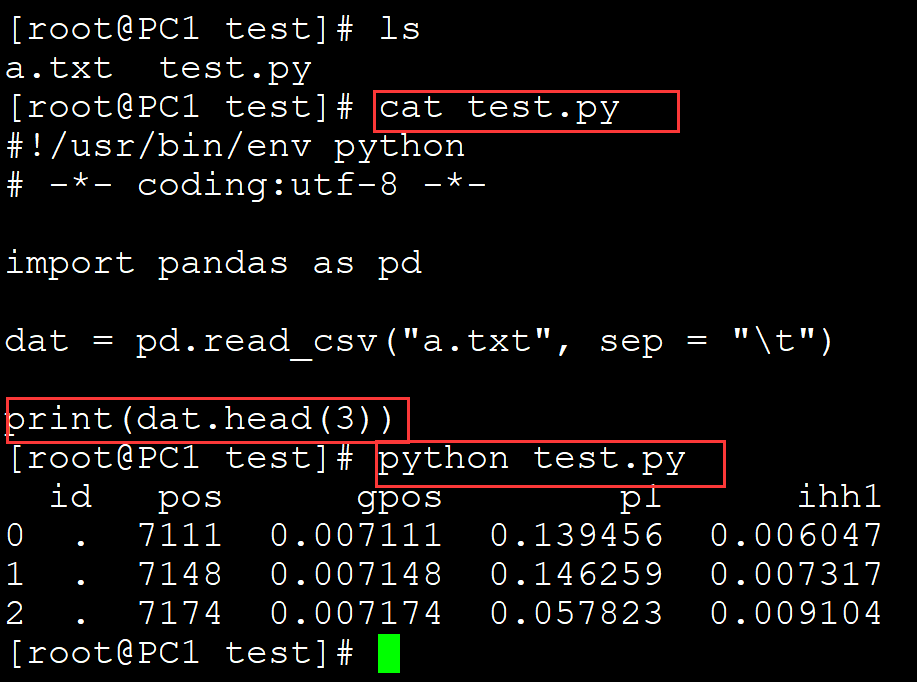
查看最后几行:
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.tail()) [root@PC1 test]# python test.py id pos gpos p1 ihh1 5 . 9011 0.009011 0.051020 0.010510 6 . 9013 0.009013 0.047619 0.010510 7 . 9021 0.009021 0.047619 0.010510 8 . 9026 0.009026 0.057823 0.010448 9 . 9034 0.009034 0.044218 0.010772
。
003、查看info信息
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.info()) ## 查看infor信息 [root@PC1 test]# python test.py <class 'pandas.core.frame.DataFrame'> ## class RangeIndex: 10 entries, 0 to 9 ## 索引 Data columns (total 5 columns): ## 列数 # Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 10 non-null object ## 第一列表示索引, 第二列表示列明, 第三列表示每列非空的内容, 第四列表示数据类型 1 pos 10 non-null int64 2 gpos 10 non-null float64 3 p1 10 non-null float64 4 ihh1 10 non-null float64 dtypes: float64(3), int64(1), object(1) memory usage: 528.0+ bytes None
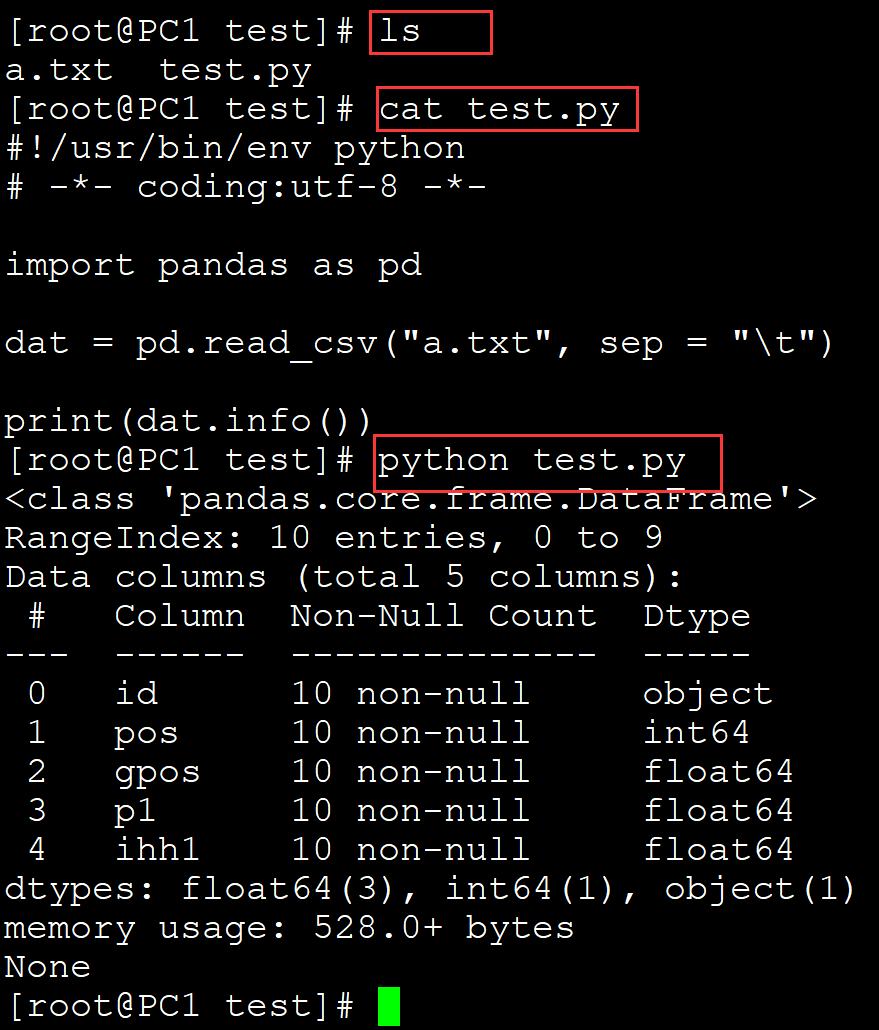
。
004、输出描述性统计
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -* import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.describe()) [root@PC1 test]# python test.py pos gpos p1 ihh1 count 10.000000 10.000000 10.000000 10.000000 mean 8450.400000 0.008450 0.066667 0.009566 std 901.627689 0.000902 0.040823 0.001615 min 7111.000000 0.007111 0.034014 0.006047 25% 7619.750000 0.007620 0.045068 0.009350 50% 9010.000000 0.009010 0.049320 0.010402 75% 9019.000000 0.009019 0.057823 0.010510 max 9034.000000 0.009034 0.146259 0.010772
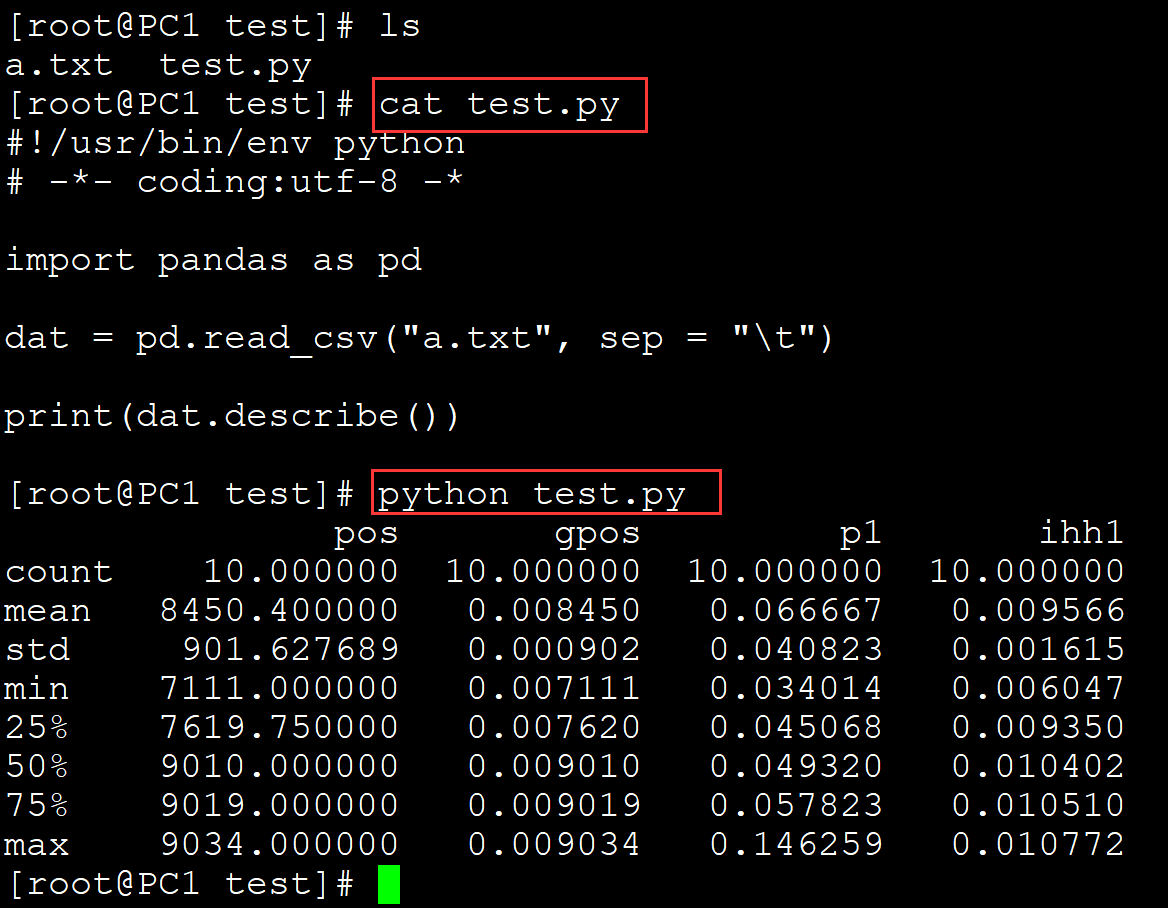
。
005、输出列名
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -* import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.columns) ## 输出列名 [root@PC1 test]# python test.py Index(['id', 'pos', 'gpos', 'p1', 'ihh1'], dtype='object')
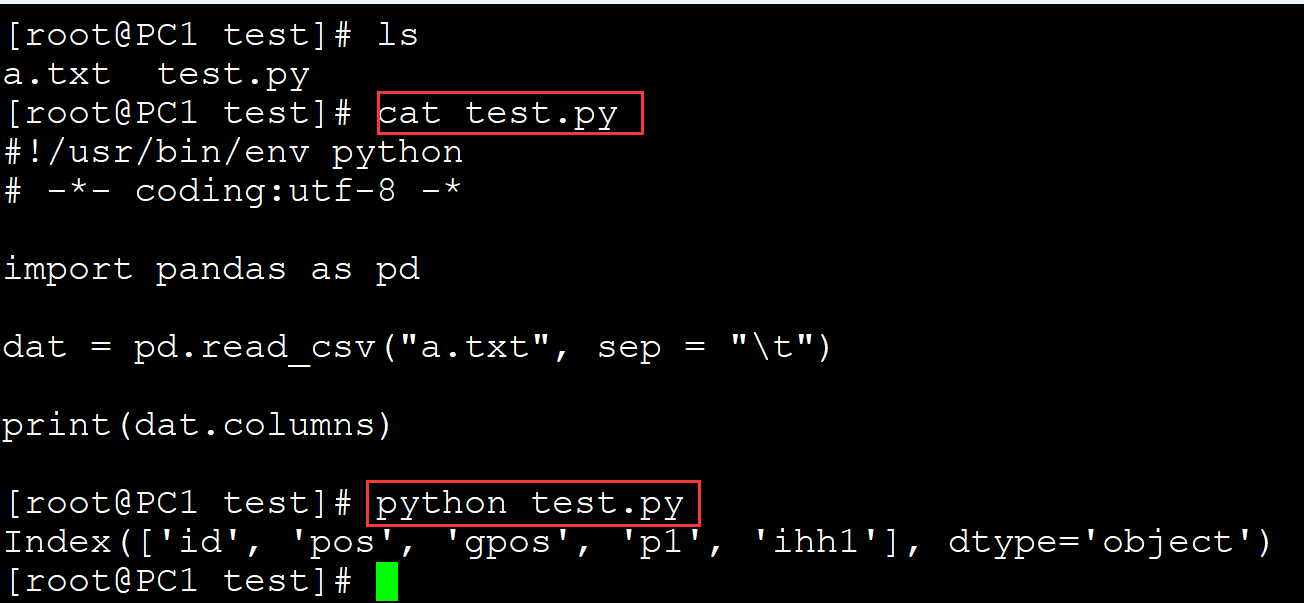
。
006、输出每列的数据类型
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -* import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.dtypes) [root@PC1 test]# python test.py id object pos int64 gpos float64 p1 float64 ihh1 float64 dtype: object
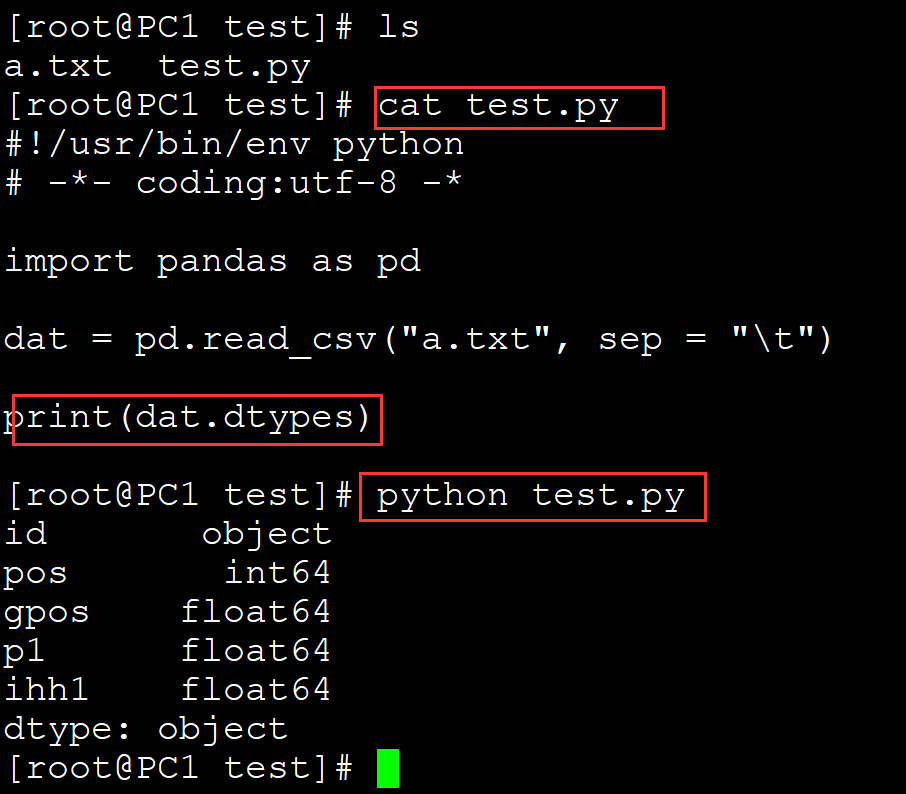
007、输出单列
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat["gpos"]) ## 输出gpos列 [root@PC1 test]# python test.py 0 0.007111 1 0.007148 2 0.007174 3 0.008957 4 0.009009 5 0.009011 6 0.009013 7 0.009021 8 0.009026 9 0.009034 Name: gpos, dtype: float64
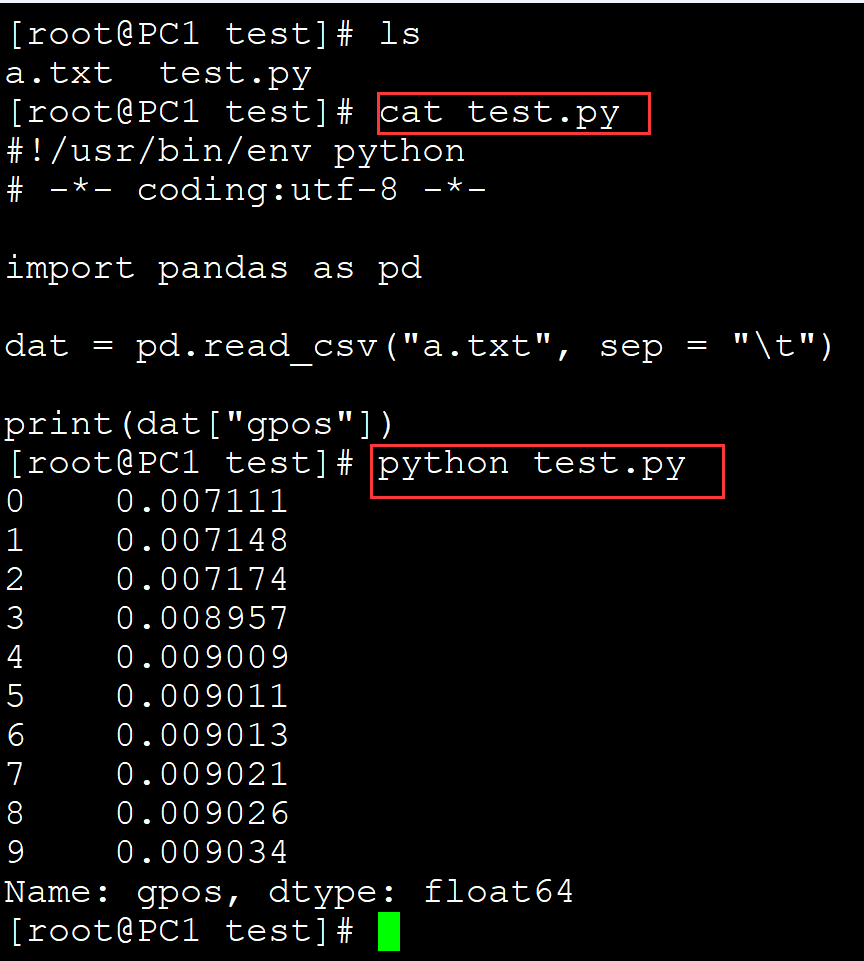
输出多列:
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat[["pos", "gpos"]]) ## 输出多列 [root@PC1 test]# python test.py pos gpos 0 7111 0.007111 1 7148 0.007148 2 7174 0.007174 3 8957 0.008957 4 9009 0.009009 5 9011 0.009011 6 9013 0.009013 7 9021 0.009021 8 9026 0.009026 9 9034 0.009034
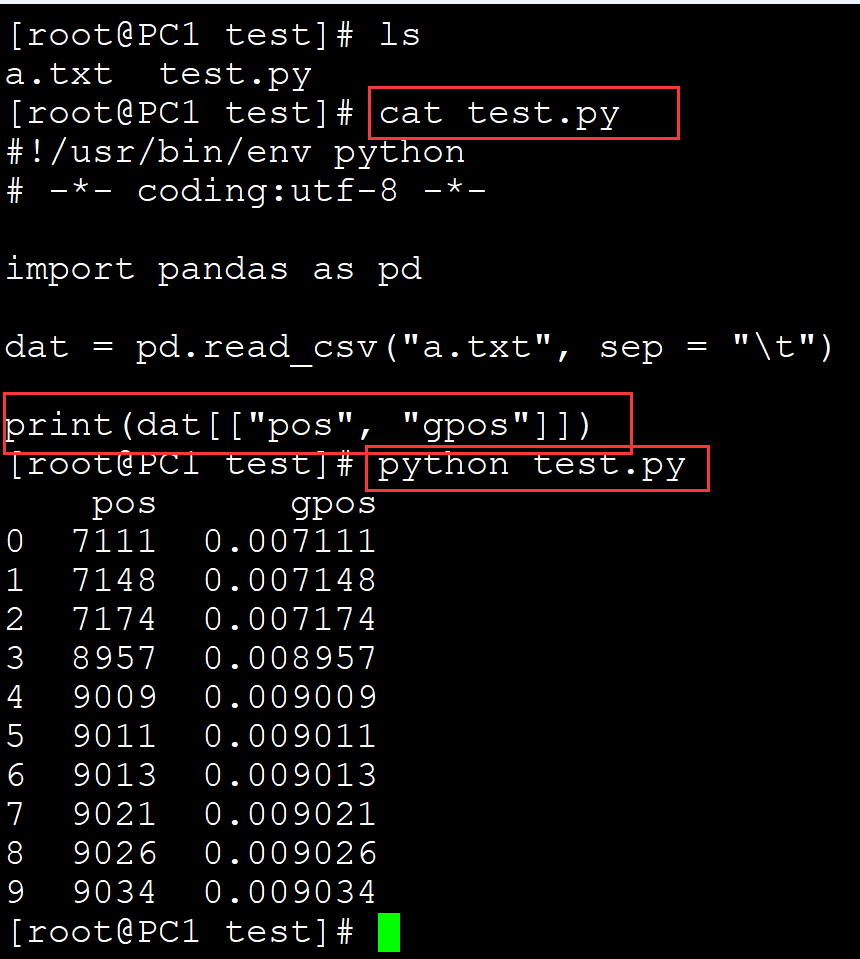
008、输出行
输出0行:
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.loc[0]) ## 输出零行 [root@PC1 test]# python test.py id . pos 7111 gpos 0.007111 p1 0.139456 ihh1 0.006047 Name: 0, dtype: object
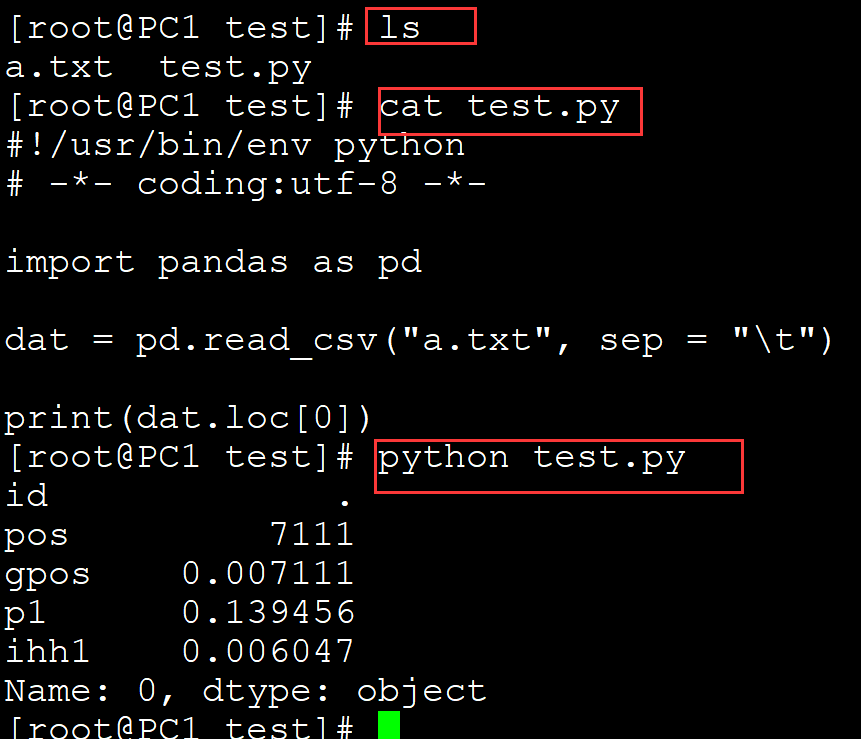
输出前几行:
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.loc[0:2]) ## 输出索引为0-2的行 [root@PC1 test]# python test.py id pos gpos p1 ihh1 0 . 7111 0.007111 0.139456 0.006047 1 . 7148 0.007148 0.146259 0.007317 2 . 7174 0.007174 0.057823 0.009104
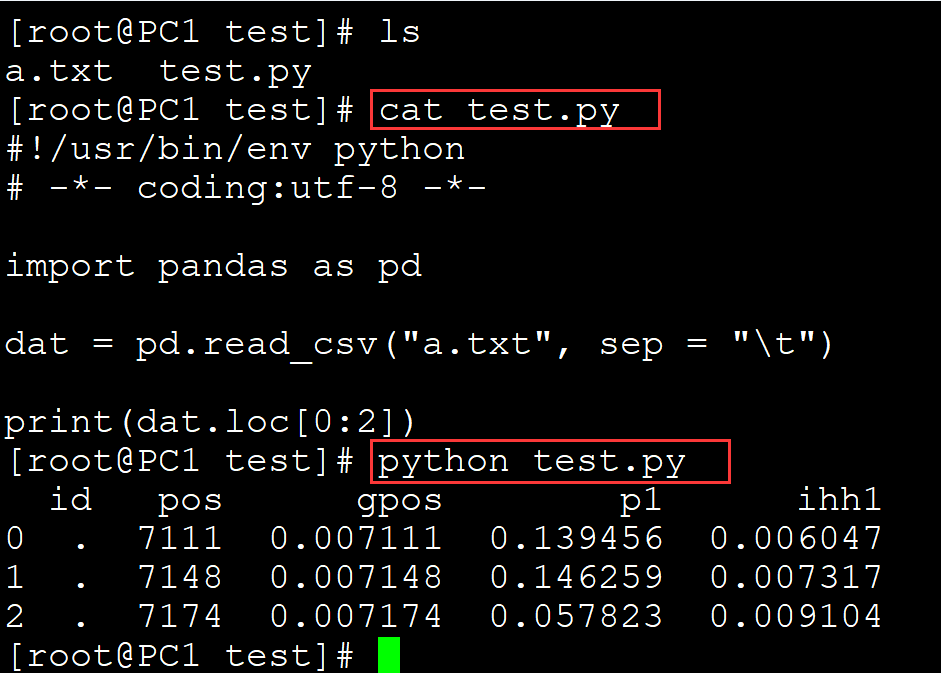
。
指定部分行:
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.loc[3:5]) ## 指定部分行 [root@PC1 test]# python test.py id pos gpos p1 ihh1 3 . 8957 0.008957 0.040816 0.010090 4 . 9009 0.009009 0.034014 0.010356 5 . 9011 0.009011 0.051020 0.010510
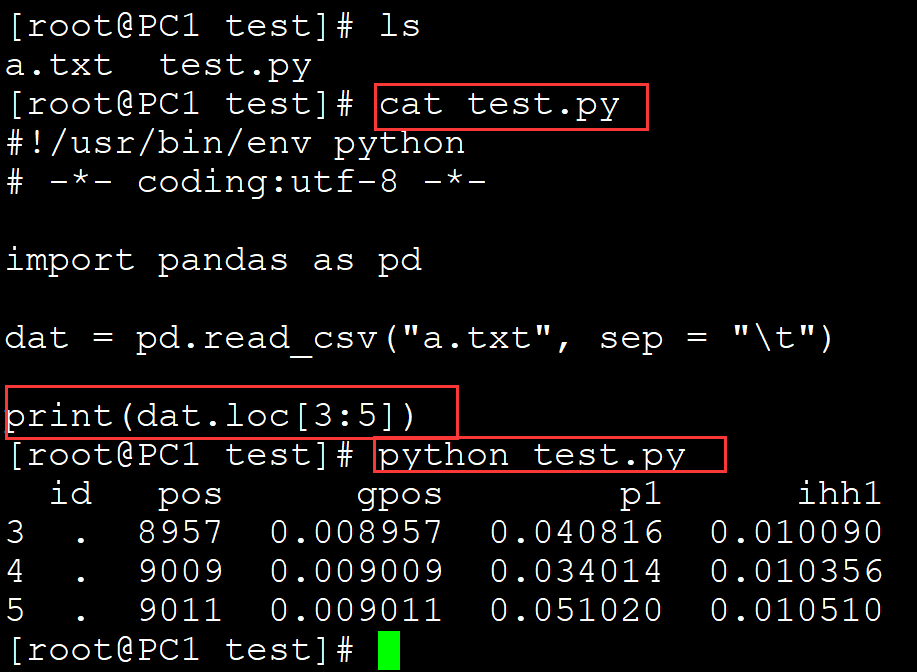
009、 同时抽取行和列
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.iloc[0:3, 1:3]) ## 同时抽取行和列 [root@PC1 test]# python test.py pos gpos 0 7111 0.007111 1 7148 0.007148 2 7174 0.007174
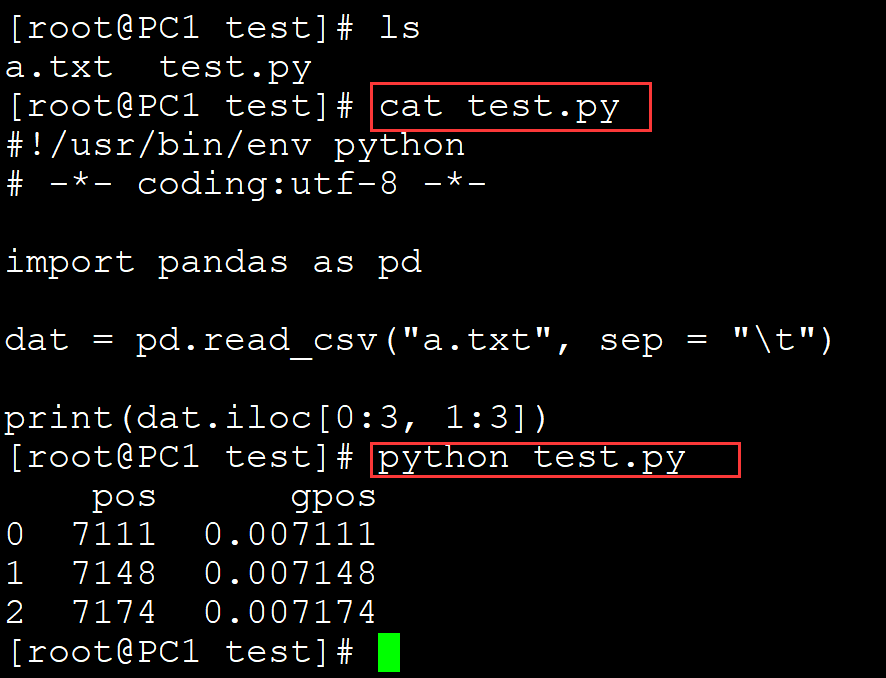
。
010、根据某一列的条件筛选数据
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat[dat["pos"] > 8000]) ## 根据某一列的条件筛选数据 [root@PC1 test]# python test.py id pos gpos p1 ihh1 3 . 8957 0.008957 0.040816 0.010090 4 . 9009 0.009009 0.034014 0.010356 5 . 9011 0.009011 0.051020 0.010510 6 . 9013 0.009013 0.047619 0.010510 7 . 9021 0.009021 0.047619 0.010510 8 . 9026 0.009026 0.057823 0.010448 9 . 9034 0.009034 0.044218 0.010772
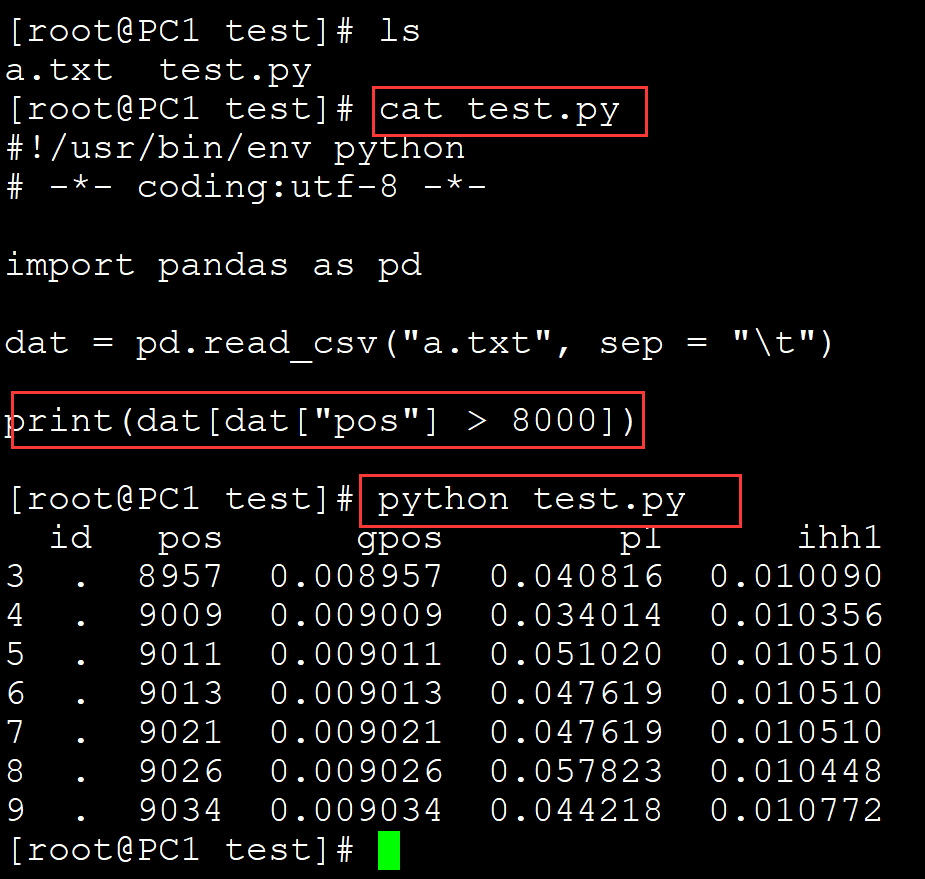
多条件筛选:
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat[(dat["pos"] > 8000) & (dat["pos"] < 9010)]) ## 多条件筛选 [root@PC1 test]# python test.py id pos gpos p1 ihh1 3 . 8957 0.008957 0.040816 0.010090 4 . 9009 0.009009 0.034014 0.010356
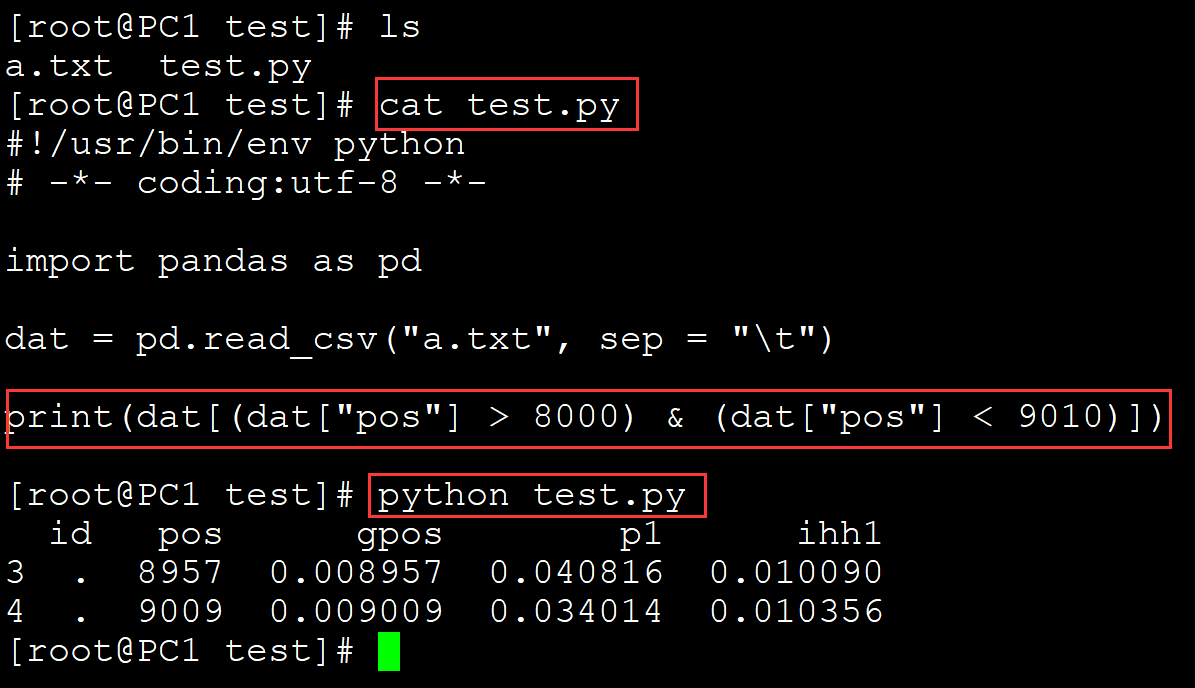
。
011、按照某一列排序:
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep = "\t") print(dat.sort_values("pos", ascending=False)) ## dui pos列,按照降序进行排列 [root@PC1 test]# python test.py id pos gpos p1 ihh1 9 . 9034 0.009034 0.044218 0.010772 8 . 9026 0.009026 0.057823 0.010448 7 . 9021 0.009021 0.047619 0.010510 6 . 9013 0.009013 0.047619 0.010510 5 . 9011 0.009011 0.051020 0.010510 4 . 9009 0.009009 0.034014 0.010356 3 . 8957 0.008957 0.040816 0.010090 2 . 7174 0.007174 0.057823 0.009104 1 . 7148 0.007148 0.146259 0.007317 0 . 7111 0.007111 0.139456 0.006047
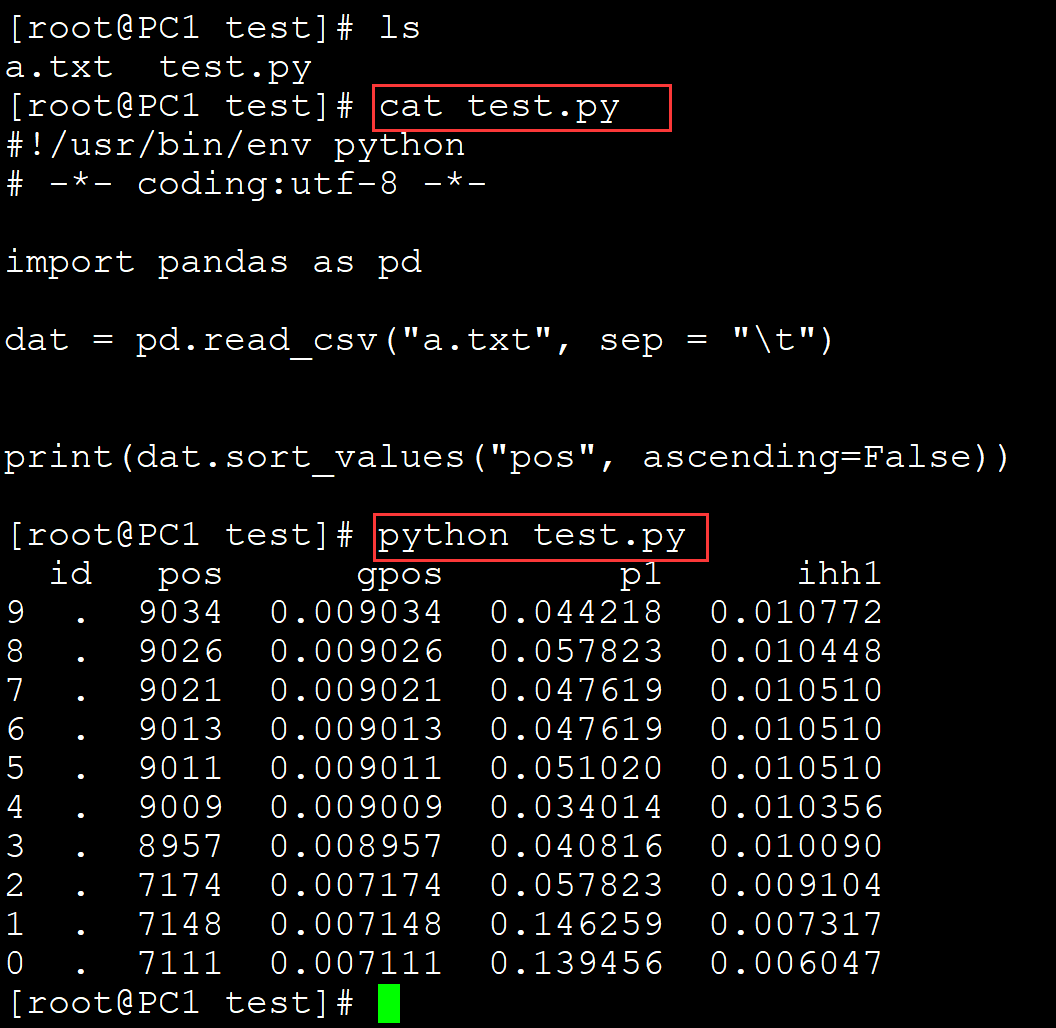
。
012、增加新列
[root@PC1 test]# ls a.txt test.py [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat = pd.read_csv("a.txt", sep="\t") dat['new_pos'] = dat['pos'] * 2 ## 增加新列 dat.to_csv("b.txt", sep="\t", index=False) [root@PC1 test]# python test.py [root@PC1 test]# ls a.txt b.txt test.py [root@PC1 test]# cat b.txt id pos gpos p1 ihh1 new_pos . 7111 0.007111 0.139456 0.00604659 14222 . 7148 0.007148 0.146259 0.00731674 14296 . 7174 0.007174 0.0578231 0.00910391 14348 . 8957 0.008957 0.0408163 0.0100898 17914 . 9009 0.009009 0.0340136 0.0103555 18018 . 9011 0.009011 0.0510204 0.01051 18022 . 9013 0.009013 0.047619 0.0105104 18026 . 9021 0.009021 0.047619 0.0105104 18042 . 9026 0.009026 0.0578231 0.0104484 18052 . 9034 0.009034 0.0442177 0.0107721 18068
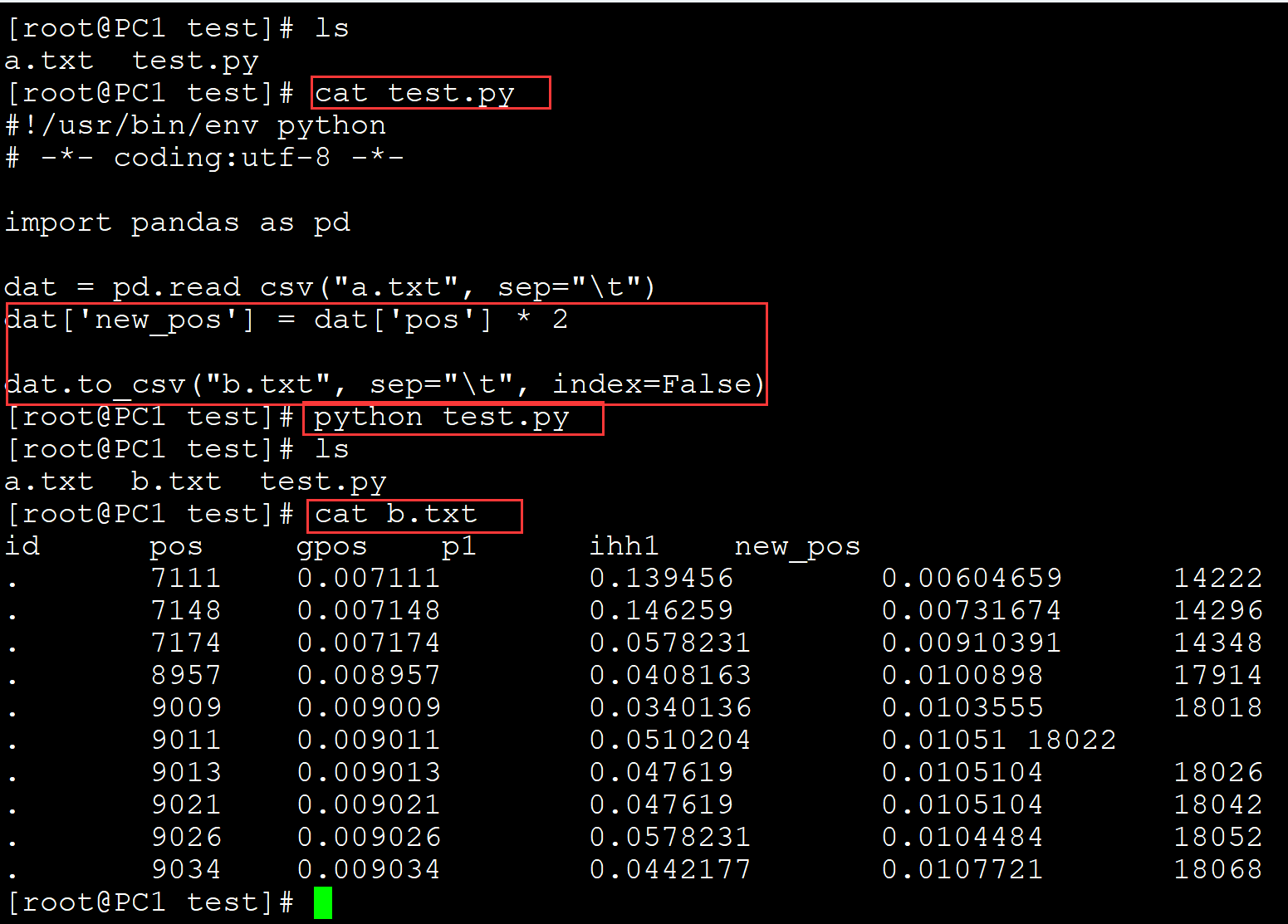
。
013、数据按照列进行合并
[root@PC1 test]# ls a.txt b.txt test.py [root@PC1 test]# cat a.txt id pos gpos p1 ihh1 . 7111 0.007111 0.139456 0.00604659 . 7148 0.007148 0.146259 0.00731674 . 7174 0.007174 0.0578231 0.00910391 . 8957 0.008957 0.0408163 0.0100898 . 9009 0.009009 0.0340136 0.0103555 [root@PC1 test]# cat b.txt 1c 2c 3c 4c 5c 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [root@PC1 test]# cat test.py #!/usr/bin/env python # -*- coding:utf-8 -*- import pandas as pd dat1 = pd.read_csv("a.txt", sep = "\t") dat2 = pd.read_csv("b.txt", sep = "\t") dat3 = pd.concat([dat1, dat2], axis=1) ## 数据按照列进行合并 dat3.to_csv("c.txt", sep="\t", index=False) [root@PC1 test]# python test.py [root@PC1 test]# cat c.txt id pos gpos p1 ihh1 1c 2c 3c 4c 5c . 7111 0.007111 0.139456 0.00604659 1 2 3 4 5 . 7148 0.007148 0.146259 0.00731674 6 7 8 9 10 . 7174 0.007174 0.0578231 0.00910391 11 12 13 14 15 . 8957 0.008957 0.0408163 0.0100898 16 17 18 19 20 . 9009 0.009009 0.0340136 0.0103555 21 22 23 24 25
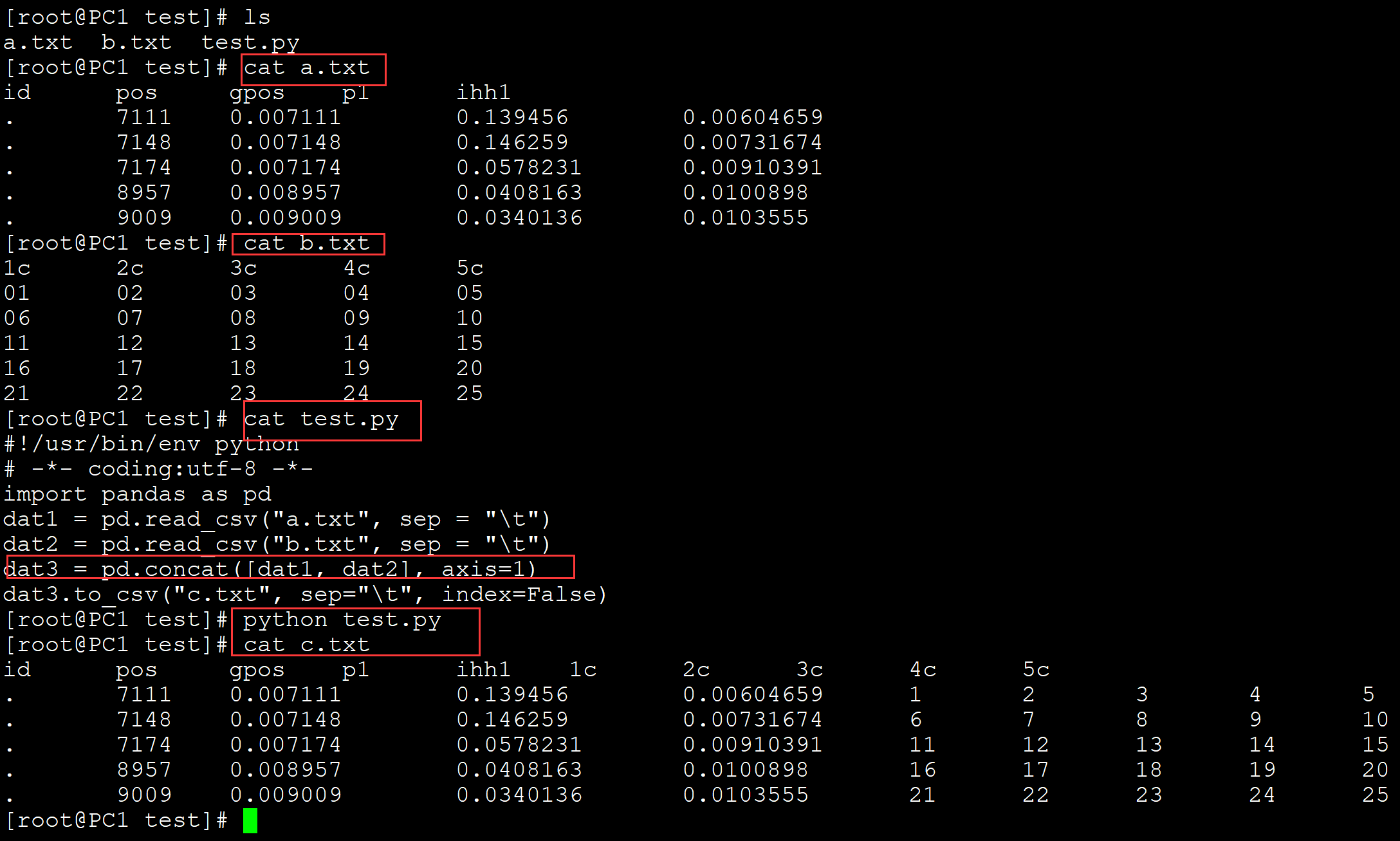
。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号