

linux 中实现一列数据等长分组并命名
001、split实现
a、
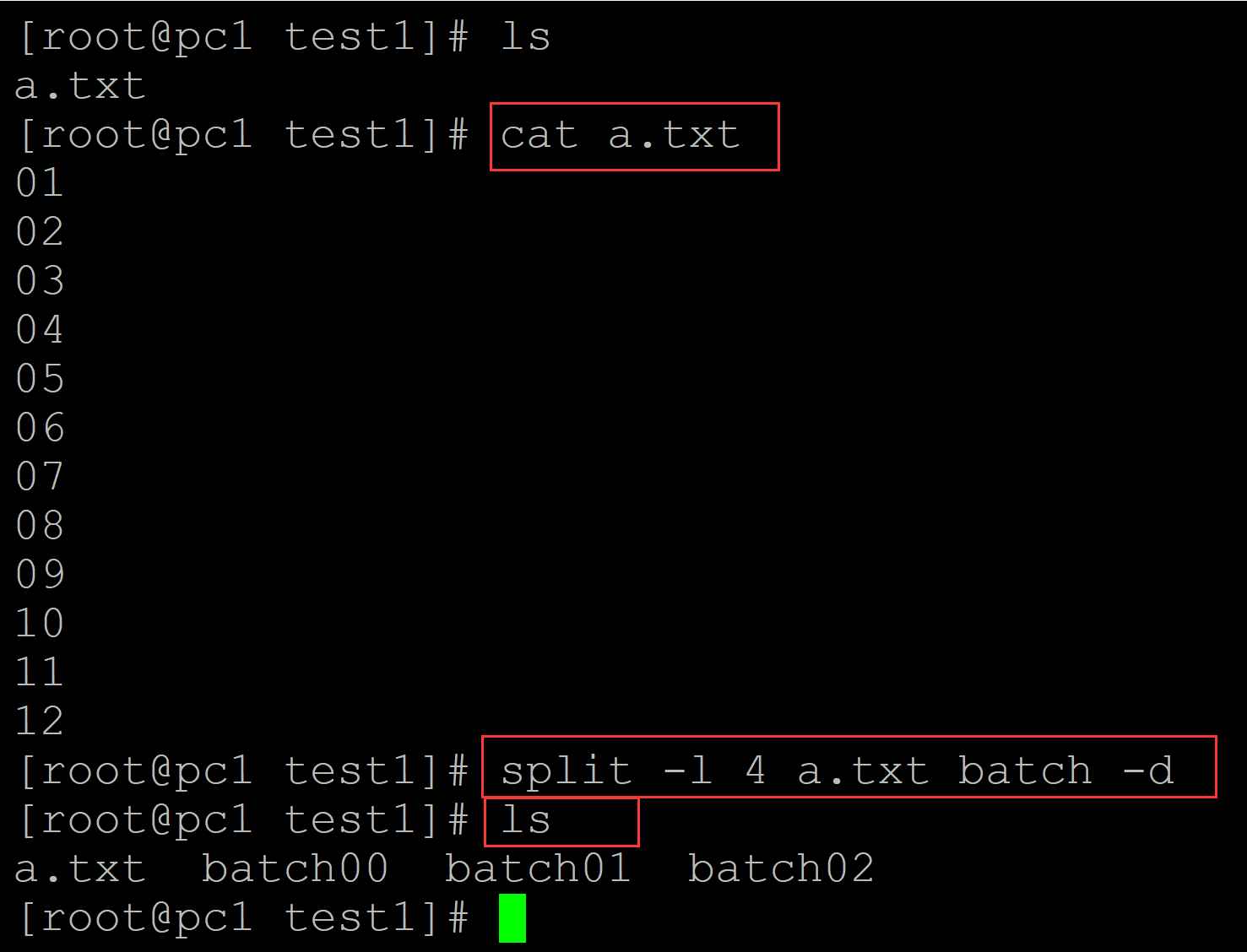
[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试文件 01 02 03 04 05 06 07 08 09 10 11 12 [root@pc1 test1]# split -l 4 a.txt batch -d ## split -l指定每个文件的行数, batch为前缀,-d参数表示按数字递增 [root@pc1 test1]# ls a.txt batch00 batch01 batch02
b、
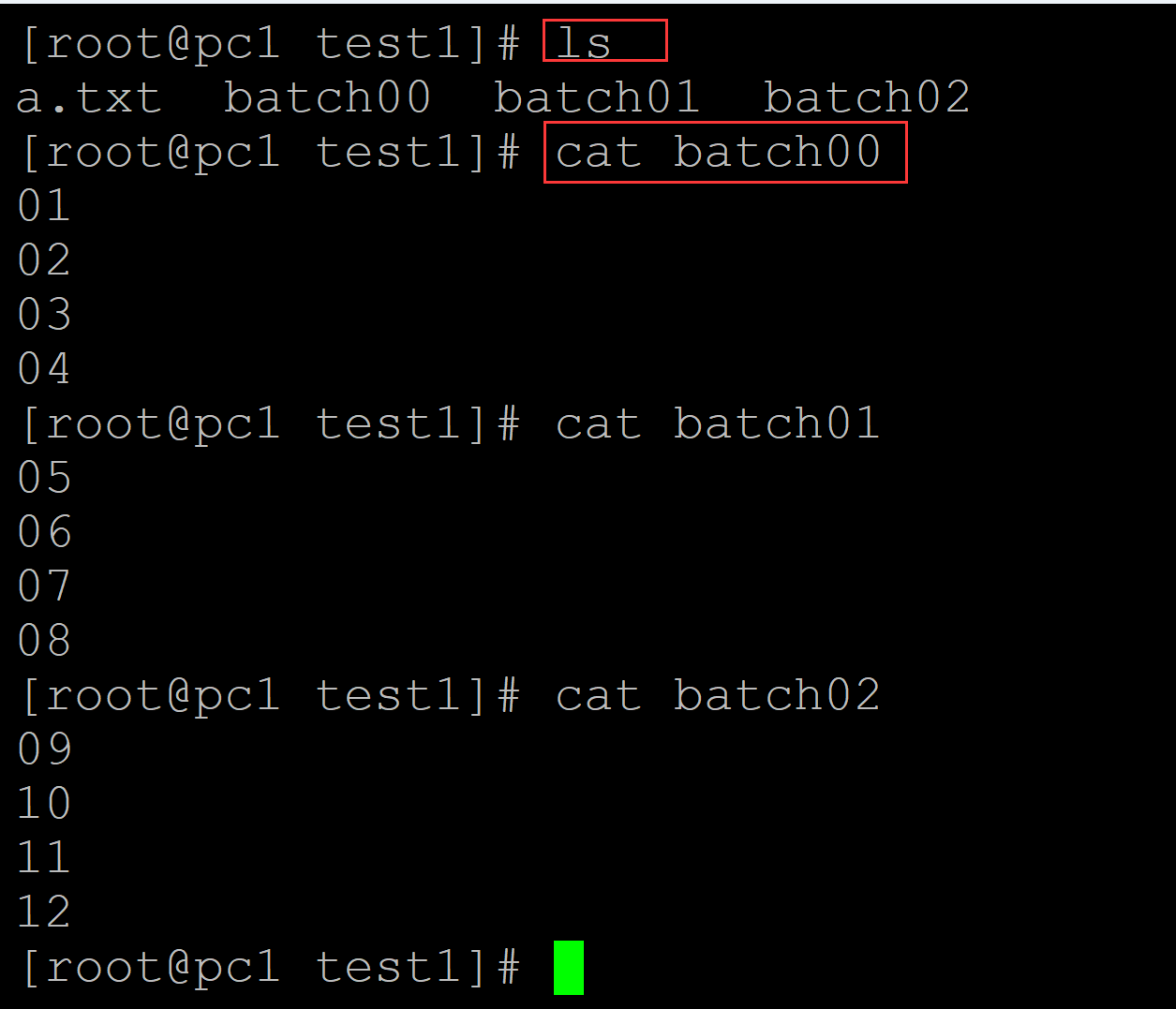
[root@pc1 test1]# ls a.txt batch00 batch01 batch02 [root@pc1 test1]# cat batch00 ## 结果文件 01 02 03 04 [root@pc1 test1]# cat batch01 05 06 07 08 [root@pc1 test1]# cat batch02 09 10 11 12
c、重命名
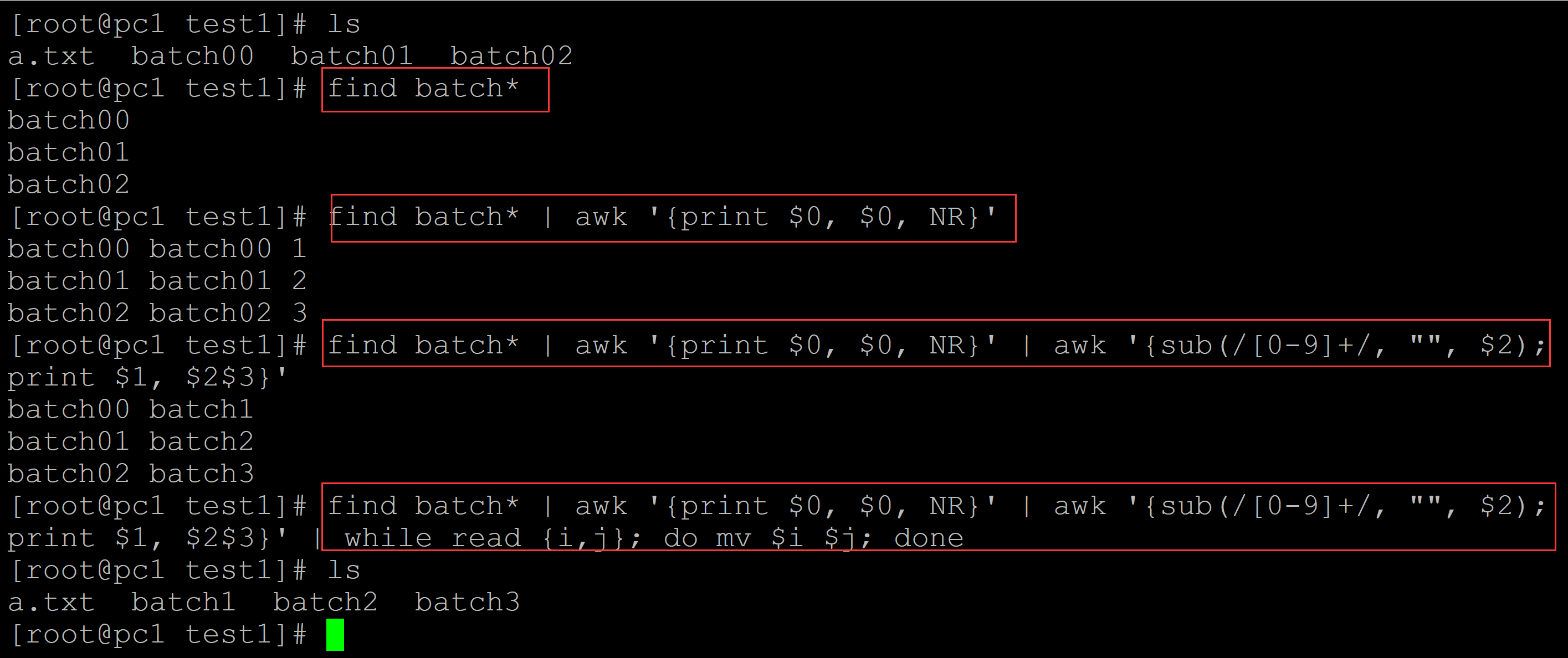
[root@pc1 test1]# ls a.txt batch00 batch01 batch02 [root@pc1 test1]# find batch* batch00 batch01 batch02 [root@pc1 test1]# find batch* | awk '{print $0, $0, NR}' batch00 batch00 1 batch01 batch01 2 batch02 batch02 3 [root@pc1 test1]# find batch* | awk '{print $0, $0, NR}' | awk '{sub(/[0-9]+/, "", $2); print $1, $2$3}' batch00 batch1 batch01 batch2 batch02 batch3 ## 按照正常数字逻辑重命名 [root@pc1 test1]# find batch* | awk '{print $0, $0, NR}' | awk '{sub(/[0-9]+/, "", $2); print $1, $2$3}' | while read {i,j}; do mv $i $j; done [root@pc1 test1]# ls a.txt batch1 batch2 batch3
002、sed实现
a、
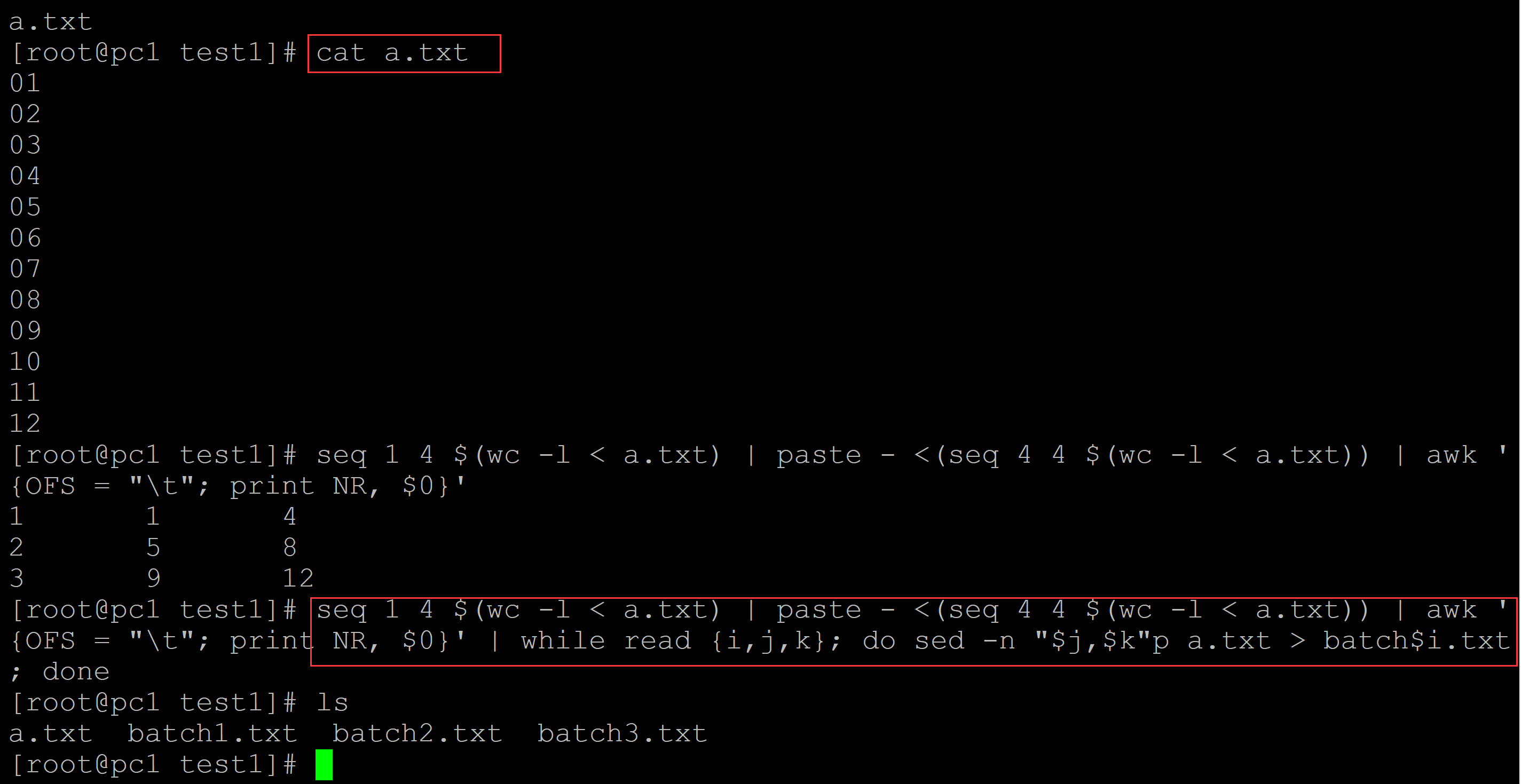
[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试数据 01 02 03 04 05 06 07 08 09 10 11 12 [root@pc1 test1]# seq 1 4 $(wc -l < a.txt) | paste - <(seq 4 4 $(wc -l < a.txt)) | awk '{OFS = "\t"; print NR, $0}' 1 1 4 2 5 8 3 9 12 [root@pc1 test1]# seq 1 4 $(wc -l < a.txt) | paste - <(seq 4 4 $(wc -l < a.txt)) | awk '{OFS = "\t"; print NR, $0}' | while read {i,j,k}; do sed -n "$j,$k"p a.txt > batch$i.txt; done [root@pc1 test1]# ls a.txt batch1.txt batch2.txt batch3.txt
[root@pc1 test1]# ls a.txt batch1.txt batch2.txt batch3.txt [root@pc1 test1]# cat batch1.txt ## 结果文件 01 02 03 04 [root@pc1 test1]# cat batch2.txt 05 06 07 08 [root@pc1 test1]# cat batch3.txt 09 10 11 12
。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号